

文章目录
简介
今天学长向大家介绍NLP基础
NLP:词向量Skip-gram word2vec
毕设帮助,开题指导,资料分享,疑问解答(见文末)
0 前言
今天,学长给大家介绍NLP中应用非常广泛的一个领域,当然这个应用已经很成熟了——文本处理,在文本处理中,其中最为核心的就是Word2vec模型,我们通过text8数据集对word2vec中的Skip-gram进行实战。
1 项目介绍
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。接下来我们就是通过text8数据集进行word2vec中Skip-gram实战。
2 数据集介绍
我们本次项目使用的数据集是text8数据集,这个数据集里包含了大量从维基百科收集到的英文语料,我们可以通过代码下载数据集,下载后的文件被保存在当前目录的text8.txt文件内。当然,为了防止大家网速以及各种原因下载不成功数据集,本人将数据集上传了一份在百度网盘上,大家可以自行下载[验证码:40g3]。由于该数据集特别大,我们可以通过Linux中的查看末尾几行的命令大致看一下相关的数据集内容,命令如下:

; 3 项目实现
3.1 数据预处理
首先导入必要的第三方库
import io
import os
import sys
import requests
from collections import OrderedDict
import math
import random
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Embedding
接下来就是数据预处理,首先,找到一个合适的语料用于训练word2vec模型。前面也说明了:我们选择text8数据集,这个数据集里包含了大量从维基百科收集到的英文语料,我们可以通过如下代码下载数据集,下载后的文件被保存在当前目录的text8.txt文件内。当然,我们也可以直接从本人给的数据集直接导入项目路径即可,具体实现如下:
def download():
corpus_url = "https://dataset.bj.bcebos.com/word2vec/text8.txt"
web_request = requests.get(corpus_url)
corpus = web_request.content
with open("./text8.txt", "wb") as f:
f.write(corpus)
f.close()
download()
接下来,把下载的语料读取到程序里,并打印前800个字符看看语料的样子,代码如下:
def load_text8():
with open("./text8.txt", "r") as f:
corpus = f.read().strip("\n")
f.close()
return corpus
corpus = load_text8()
print(corpus[:800])
打印效果如下:
一般来说,在自然语言处理中,需要先对语料进行切词。对于英文来说,可以比较简单地直接使用空格进行切词,其实也可以用第三方库nltk直接进行切分,为了让大家更好的学习这一块,因此,尽可能的自己写所对应的代码,实现如下:
def data_preprocess(corpus):
corpus = corpus.strip().lower()
corpus = corpus.split(" ")
return corpus
corpus = data_preprocess(corpus)
print(corpus[:50])
打印效果如下:

在经过切词后,需要对语料进行统计,为每个词构造ID。一般来说,可以根据每个词在语料中出现的频次构造ID,频次越高,ID越小,便于对词典进行管理。代码如下:
def build_dict(corpus):
word_freq_dict = dict()
for word in corpus:
if word not in word_freq_dict:
word_freq_dict[word] = 0
word_freq_dict[word] += 1
word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)
word2id_dict = dict()
word2id_freq = dict()
id2word_dict = dict()
for word, freq in word_freq_dict:
curr_id = len(word2id_dict)
word2id_dict[word] = curr_id
word2id_freq[word2id_dict[word]] = freq
id2word_dict[curr_id] = word
return word2id_freq, word2id_dict, id2word_dict
word2id_freq, word2id_dict, id2word_dict = build_dict(corpus)
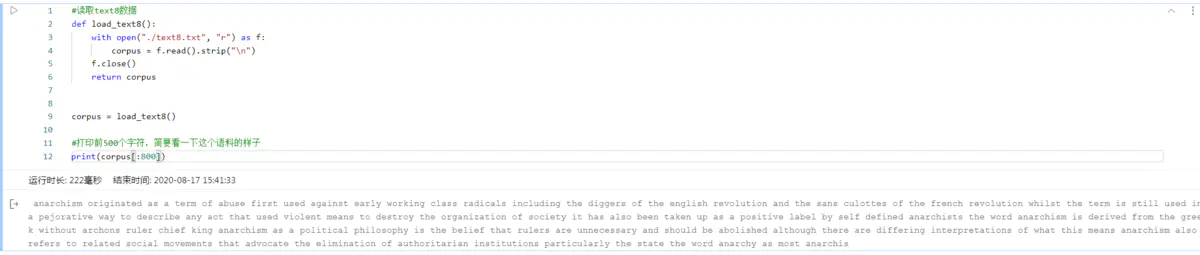
vocab_size = len(word2id_freq)
print("there are totoally %d different words in the corpus" % vocab_size)
for _, (word, word_id) in zip(range(50), word2id_dict.items()):
print("word %s, its id %d, its word freq %d" % (word, word_id, word2id_freq[word_id]))
打印效果如下:
得到word2id词典后,我们还需要进一步处理原始语料,把每个词替换成对应的ID,便于神经网络进行处理,代码如下:
def convert_corpus_to_id(corpus, word2id_dict):
corpus = [word2id_dict[word] for word in corpus]
return corpus
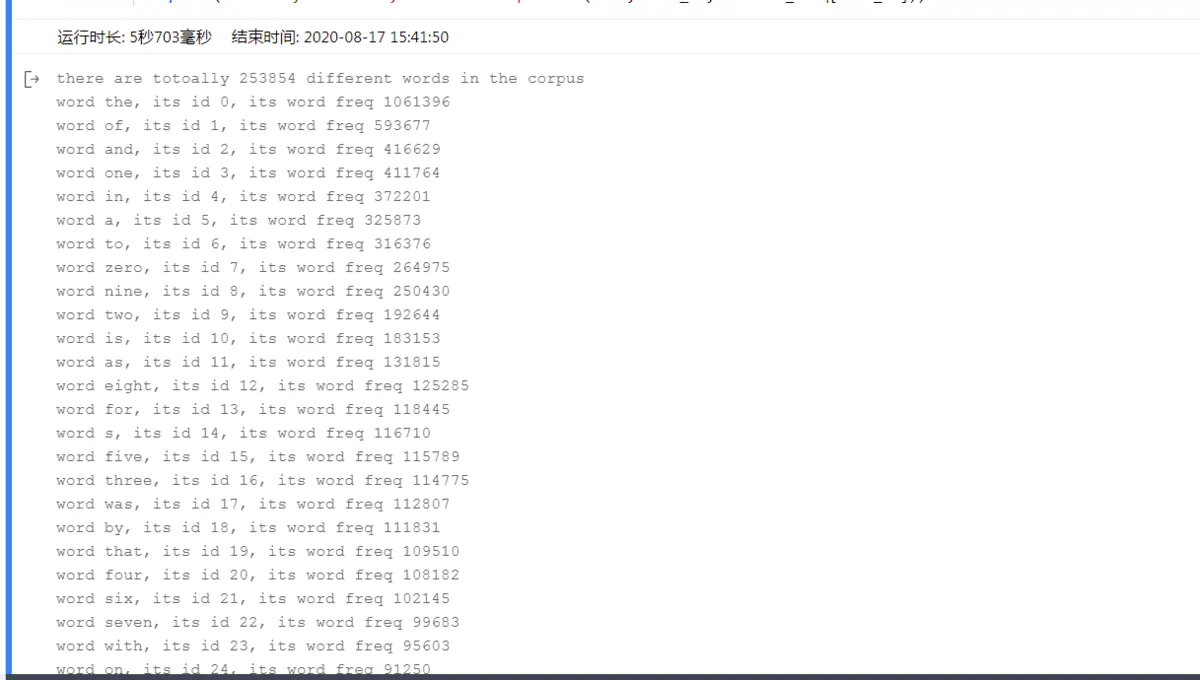
corpus = convert_corpus_to_id(corpus, word2id_dict)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
打印结果如下:

接下来,需要使用二次采样法处理原始文本。二次采样法的主要思想是降低高频词在语料中出现的频次,降低的方法是将随机将高频的次抛弃,频率越高,被抛弃的概率就越高,频率越低,被抛弃的概率就越低,这样像标点符号或冠词这样的高频词就会被抛弃,从而优化整个词表的词向量训练效果,代码如下:
def subsampling(corpus, word2id_freq):
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
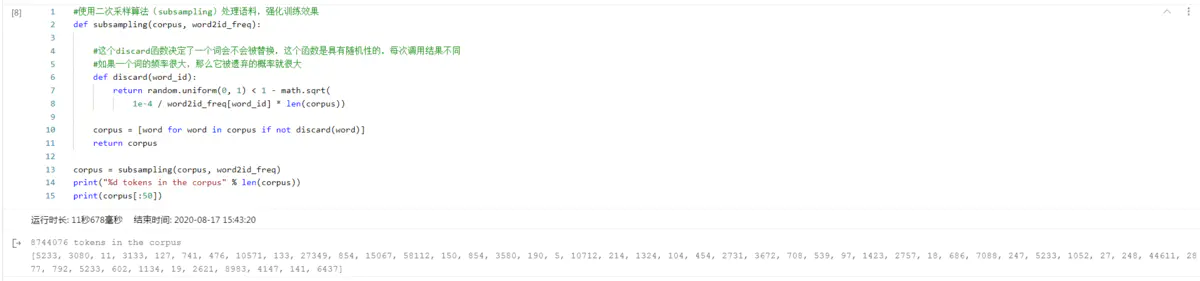
corpus = subsampling(corpus, word2id_freq)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
打印结果如下:
在完成语料数据预处理之后,需要构造训练数据。根据上面的描述,我们需要使用一个滑动窗口对语料从左到右扫描,在每个窗口内,中心词需要预测它的上下文,并形成训练数据。在实际操作中,由于词表往往很大(50000,100000等),对大词表的一些矩阵运算(如softmax)需要消耗巨大的资源,因此可以通过负采样的方式模拟softmax的结果,代码实现如下。
- 给定一个中心词和一个需要预测的上下文词,把这个上下文词作为正样本。
- 通过词表随机采样的方式,选择若干个负样本。
- 把一个大规模分类问题转化为一个2分类问题,通过这种方式优化计算速度。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size = 3,
negative_sample_num = 6):
dataset = []
center_word_idx=0
while center_word_idx < len(corpus):
window_size = random.randint(1, max_window_size)
positive_word = corpus[center_word_idx]
context_word_range = (max(0, center_word_idx - window_size), min(len(corpus) - 1, center_word_idx + window_size))
context_word_candidates = [corpus[idx] for idx in range(context_word_range[0], context_word_range[1]+1) if idx != center_word_idx]
for context_word in context_word_candidates:
dataset.append((context_word, positive_word, 1))
i = 0
while i < negative_sample_num:
negative_word_candidate = random.randint(0, vocab_size-1)
if negative_word_candidate is not positive_word:
dataset.append((context_word, negative_word_candidate, 0))
i += 1
center_word_idx = min(len(corpus) - 1, center_word_idx + window_size)
if center_word_idx == (len(corpus) - 1):
center_word_idx += 1
if center_word_idx % 100000 == 0:
print(center_word_idx)
return dataset
dataset = build_data(corpus, word2id_dict, word2id_freq)
for _, (context_word, target_word, label) in zip(range(50), dataset):
print("center_word %s, target %s, label %d" % (id2word_dict[context_word],
id2word_dict[target_word], label))
打印结果如下

训练数据准备好后,把训练数据都组装成mini-batch,并准备输入到网络中进行训练,代码如下:
def build_batch(dataset, batch_size, epoch_num):
center_word_batch = []
target_word_batch = []
label_batch = []
for epoch in range(epoch_num):
random.shuffle(dataset)
for center_word, target_word, label in dataset:
center_word_batch.append([center_word])
target_word_batch.append([target_word])
label_batch.append(label)
if len(center_word_batch) == batch_size:
yield np.array(center_word_batch).astype("int64"), \
np.array(target_word_batch).astype("int64"), \
np.array(label_batch).astype("float32")
center_word_batch = []
target_word_batch = []
label_batch = []
if len(center_word_batch) > 0:
yield np.array(center_word_batch).astype("int64"), \
np.array(target_word_batch).astype("int64"), \
np.array(label_batch).astype("float32")
3.2 配置网络
定义skip-gram的网络结构,用于模型训练。在飞桨动态图中,对于任意网络,都需要定义一个继承自fluid.dygraph.Layer的类来搭建网络结构、参数等数据的声明。同时需要在forward函数中定义网络的计算逻辑。值得注意的是,我们仅需要定义网络的前向计算逻辑,飞桨会自动完成神经网络的反向计算,实现如下:
class SkipGram(fluid.dygraph.Layer):
def __init__(self, vocab_size, embedding_size, init_scale=0.1):
super(SkipGram, self).__init__()
self.vocab_size = vocab_size
self.embedding_size = embedding_size
self.embedding = Embedding(
size=[self.vocab_size, self.embedding_size],
dtype='float32',
param_attr=fluid.ParamAttr(
name='embedding_para',
initializer=fluid.initializer.UniformInitializer(
low=-0.5/embedding_size, high=0.5/embedding_size)))
self.embedding_out = Embedding(
size=[self.vocab_size, self.embedding_size],
dtype='float32',
param_attr=fluid.ParamAttr(
name='embedding_out_para',
initializer=fluid.initializer.UniformInitializer(
low=-0.5/embedding_size, high=0.5/embedding_size)))
def forward(self, center_words, target_words, label):
center_words_emb = self.embedding(center_words)
target_words_emb = self.embedding_out(target_words)
word_sim = fluid.layers.elementwise_mul(center_words_emb, target_words_emb)
word_sim = fluid.layers.reduce_sum(word_sim, dim = -1)
word_sim = fluid.layers.reshape(word_sim, shape=[-1])
pred = fluid.layers.sigmoid(word_sim)
loss = fluid.layers.sigmoid_cross_entropy_with_logits(word_sim, label)
loss = fluid.layers.reduce_mean(loss)
return pred, loss
3.3 网络训练
完成网络定义后,就可以启动模型训练。我们定义每隔100步打印一次Loss,以确保当前的网络是正常收敛的。同时,我们每隔1000步观察一下skip-gram计算出来的同义词(使用 embedding的乘积),可视化网络训练效果,不过需要特别说明的是: 本次训练没有设置相应的暂停程序,需要我们在训练到差不多的准确度的时候就得手动停下来,否则会出现内存溢出的错误,这点需要我们特别的注意!!!! ,经过自己的经验,不过至少得训练差不多40万步左右才能看出效果,具体代码如下:
batch_size = 256
epoch_num = 10
embedding_size = 200
step = 0
learning_rate = 0.0002
def get_cos(query1_token, query2_token, embed):
W = embed
x = W[word2id_dict[query1_token]]
y = W[word2id_dict[query2_token]]
cos = np.dot(x, y) / np.sqrt(np.sum(y * y) * np.sum(x * x) + 1e-9)
flat = cos.flatten()
print("单词1 %s 和单词2 %s 的cos结果为 %f" %(query1_token, query2_token, cos))
with fluid.dygraph.guard(fluid.CUDAPlace(0)):
skip_gram_model = SkipGram(vocab_size, embedding_size)
adam = fluid.optimizer.AdamOptimizer(learning_rate=learning_rate, parameter_list=skip_gram_model.parameters())
for center_words, target_words, label in build_batch(
dataset, batch_size, epoch_num):
center_words_var = fluid.dygraph.to_variable(center_words)
target_words_var = fluid.dygraph.to_variable(target_words)
label_var = fluid.dygraph.to_variable(label)
pred, loss = skip_gram_model(
center_words_var, target_words_var, label_var)
loss.backward()
adam.minimize(loss)
skip_gram_model.clear_gradients()
step += 1
if step % 100 == 0:
print("step %d, loss %.3f" % (step, loss.numpy()[0]))
if step % 2000 == 0:
embedding_matrix = skip_gram_model.embedding.weight.numpy()
np.save("./embedding", embedding_matrix)
get_cos("king","queen",embedding_matrix)
get_cos("she","her",embedding_matrix)
get_cos("topic","theme",embedding_matrix)
get_cos("woman","game",embedding_matrix)
get_cos("one","name",embedding_matrix)
训练过程如下:
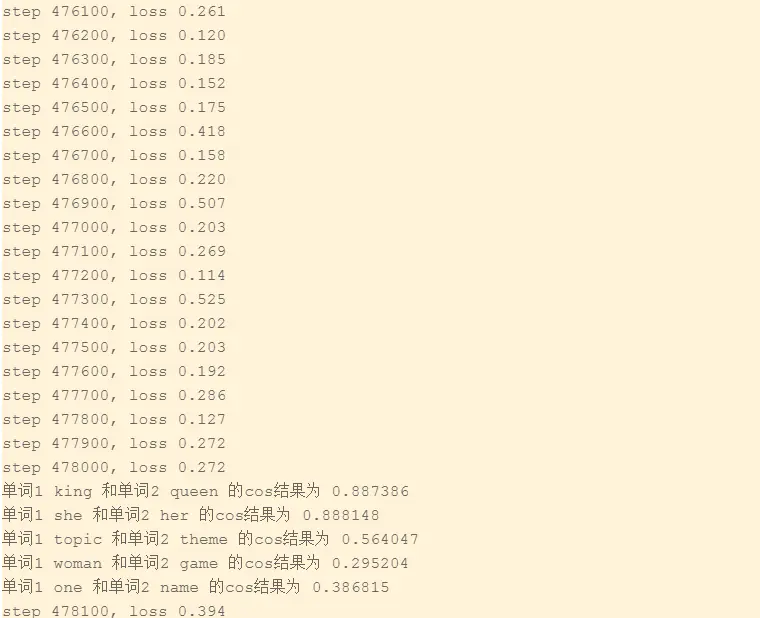
从上面的训练的过程可以看出,当我们随着训练步数的不断增加,其训练的结果不断趋于稳定,这里很明显看出前三对单词的相似度还是挺好的,符合我们的预期,之所以第三对的相似度如此低,是因为训练语料还是不够大,训练的效果不是太好导致其出现在原文的次数较少,需要说明的是:本项目是用的余弦相似度进行计算的。另外的一个原因就是theme和topic本来的意思也比较远,我们可以用金山词霸查这两个词的意思:

具体的意思如下:

3.4 模型评估
我们用余弦相似度计算评价词向量结果,具体实现如下:
def get_cos(query1_token, query2_token, embed):
W = embed
x = W[word2id_dict[query1_token]]
y = W[word2id_dict[query2_token]]
cos = np.dot(x, y) / np.sqrt(np.sum(y * y) * np.sum(x * x) + 1e-9)
flat = cos.flatten()
print("单词1 %s 和单词2 %s 的cos结果为 %f" %(query1_token, query2_token, cos) )
embedding_matrix = np.load('embedding.npy')
get_cos("king","queen",embedding_matrix)
get_cos("she","her",embedding_matrix)
get_cos("topic","theme",embedding_matrix)
get_cos("woman","game",embedding_matrix)
get_cos("one","name",embedding_matrix)
预测结果如下
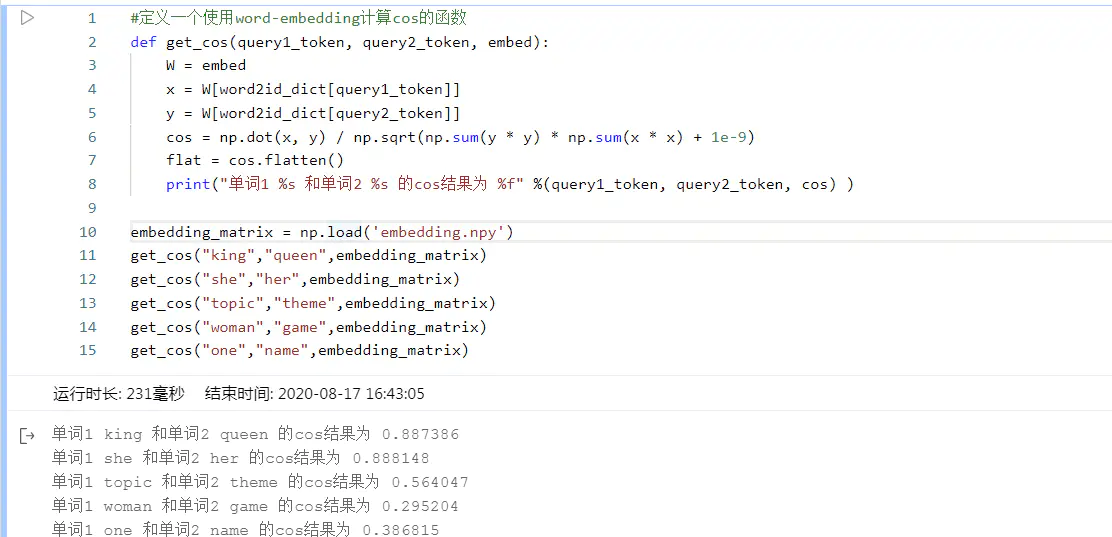
训练的结果还是挺满意的,不过这里需要提醒大家的就是前面也提到过这个问题:那就是第三组单词的相似度较低,原因也从客观以及主观给大家分析了,需要大家留意一下,因此有相对低的结果也很正常。
到此为止,学长的本次项目讲解到此结束。
4 最后-毕设帮助
Original: https://blog.csdn.net/HUXINY/article/details/121816109
Author: DanCheng-studio
Title: 毕业设计 – NLP:词向量Skip-gram word2vec
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531377/
转载文章受原作者版权保护。转载请注明原作者出处!