

文章目录
1 前言


模型名:BiLSTM-CRF
论文参考:
Bidirectional LSTM-CRF Models for Sequence Tagging
Neural Architectures for Named Entity Recognition
使用数据集:
https://www.datafountain.cn/competitions/529/ranking
Tips:文章可能存在一些漏洞,欢迎留言指出
; 2 数据准备
导包、路径、超参数、预设常量
import pandas as pd
import torch
import pickle
import os
from torch import optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from bilstm_crf import BiLSTM_CRF, NerDataset, NerDatasetTest
from sklearn.metrics import f1_score
TRAIN_PATH = './dataset/train_data_public.csv'
TEST_PATH = './dataset/test_public.csv'
VOCAB_PATH = './data/vocab.txt'
WORD2INDEX_PATH = './data/word2index.pkl'
MODEL_PATH = './model/bilstm_crf.pkl'
MAX_LEN = 60
BATCH_SIZE = 8
EMBEDDING_DIM = 120
HIDDEN_DIM = 12
EPOCH = 5
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
tag2index = {
"O": 0,
"B-BANK": 1, "I-BANK": 2,
"B-PRODUCT": 3, "I-PRODUCT": 4,
"B-COMMENTS_N": 5, "I-COMMENTS_N": 6,
"B-COMMENTS_ADJ": 7, "I-COMMENTS_ADJ": 8
}
unk_flag = '[UNK]'
pad_flag = '[PAD]'
start_flag = '[STA]'
end_flag = '[END]'
生成word2index字典、加载数据集
def create_word2index():
if not os.path.exists(WORD2INDEX_PATH):
word2index = dict()
with open(VOCAB_PATH, 'r', encoding='utf8') as f:
for word in f.readlines():
word2index[word.strip()] = len(word2index) + 1
with open(WORD2INDEX_PATH, 'wb') as f:
pickle.dump(word2index, f)
def data_prepare():
train_dataset = pd.read_csv(TRAIN_PATH, encoding='utf8')
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
return train_dataset, test_dataset
3 数据处理
文本、标签转换为索引(训练集)
流程:
( 1 )提取预设标签索引 ( 2 )初步生成文本对应的索引,需要在头和尾分别加入 s t a r t i n d e x 和 e n d i n d e x ,初步生成标签对应的索引,同理,在头和尾加入 0 ( 3 )对文本和标签索引按照长度执行操作:低于 m a x l e n 则填充,超过 m a x l e n 则截断 ( 4 )根据 t e x t i n d e x 生成 m a s k ( 5 )将每一个 r o w 的 t e x t i n d e x 、 t a g i n d e x 、 m a s k 加入到对应的 l i s t 中 ( 6 )将 t e x t s 、 t a g s 、 m a s k s 转化为 t e n s o r 格式 \textcolor{purple}{ (1)提取预设标签索引\ (2)初步生成文本对应的索引,需要在头和尾分别加入start_index和end_index,初步生成标签对应的索引,同理,在头和尾加入0\ (3)对文本和标签索引按照长度执行操作:低于max_len则填充,超过max_len则截断\ (4)根据text_index生成mask\ (5)将每一个row的text_index、tag_index、mask加入到对应的list中\ (6)将texts、tags、masks转化为tensor格式 }(1 )提取预设标签索引(2 )初步生成文本对应的索引,需要在头和尾分别加入s t a r t i n d e x 和e n d i n d e x ,初步生成标签对应的索引,同理,在头和尾加入0 (3 )对文本和标签索引按照长度执行操作:低于ma x l e n 则填充,超过ma x l e n 则截断(4 )根据t e x t i n d e x 生成ma s k (5 )将每一个ro w 的t e x t i n d e x 、t a g i n d e x 、ma s k 加入到对应的l i s t 中(6 )将t e x t s 、t a g s 、ma s k s 转化为t e n sor 格式
def text_tag_to_index(dataset, word2index):
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, tags, masks = [], [], []
n_rows = len(dataset)
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
tag = dataset.iloc[row, 2]
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
tag_index = [0] + [tag2index.get(t) for t in tag.split()] + [0]
if len(text_index) < MAX_LEN:
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
tag_index += pad_len * [0]
elif len(text_index) > MAX_LEN:
text_index = text_index[:MAX_LEN - 1] + [end_index]
tag_index = tag_index[:MAX_LEN - 1] + [0]
def _pad2mask(t):
return 0 if t == pad_index else 1
mask = [_pad2mask(t) for t in text_index]
texts.append(text_index)
tags.append(tag_index)
masks.append(mask)
texts = torch.LongTensor(texts)
tags = torch.LongTensor(tags)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, tags, masks
文本转换为索引(测试集)
测试集同上,没有标签
def text_to_index(dataset, word2index):
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, masks = [], []
n_rows = len(dataset)
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
if len(text_index) < MAX_LEN:
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
elif len(text_index) > MAX_LEN:
text_index = text_index[:MAX_LEN - 1] + [end_index]
def _pad2mask(t):
return 0 if t == pad_index else 1
mask = [_pad2mask(t) for t in text_index]
masks.append(mask)
texts.append(text_index)
texts = torch.LongTensor(texts)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, masks
4 模型
条件随机场部分使用了 t o r c h c r f 包 针对训练集,返回 l o s s 和 p r e d i c t i o n s 针对测试集,由于没有 t a g s ,因此只需返回 p r e d i c t i o n s \textcolor{blue}{ 条件随机场部分使用了torchcrf包\ 针对训练集,返回loss和predictions\ 针对测试集,由于没有tags,因此只需返回predictions }条件随机场部分使用了t orc h cr f 包针对训练集,返回l oss 和p re d i c t i o n s 针对测试集,由于没有t a g s ,因此只需返回p re d i c t i o n s
代码:
import torch
from torch import nn
from torch.utils.data import Dataset
from torchcrf import CRF
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag2index, embedding_dim, hidden_size, padding_idx, device):
super(BiLSTM_CRF, self).__init__()
self.vocab_size = vocab_size
self.tag2index = tag2index
self.tagset_size = len(tag2index)
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.padding_index = padding_idx
self.device = device
self.embed = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim, padding_idx=padding_idx)
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, num_layers=1, bidirectional=True)
self.dense = nn.Linear(in_features=hidden_size * 2, out_features=self.tagset_size)
self.crf = CRF(num_tags=self.tagset_size)
self.hidden = None
def forward(self, texts, tags=None, masks=None):
x = self.embed(texts).permute(1, 0, 2)
self.hidden = (torch.randn(2, x.size(1), self.hidden_size).to(self.device),
torch.randn(2, x.size(1), self.hidden_size).to(self.device))
out, self.hidden = self.lstm(x, self.hidden)
lstm_feats = self.dense(out)
if tags is not None:
tags = tags.permute(1, 0)
if masks is not None:
masks = masks.permute(1, 0)
if tags is not None:
loss = self.neg_log_likelihood(lstm_feats, tags, masks, 'mean')
predictions = self.crf.decode(emissions=lstm_feats, mask=masks)
return loss, predictions
else:
predictions = self.crf.decode(emissions=lstm_feats, mask=masks)
return predictions
def neg_log_likelihood(self, emissions, tags=None, mask=None, reduction=None):
return -1 * self.crf(emissions=emissions, tags=tags, mask=mask, reduction=reduction)
class NerDataset(Dataset):
def __init__(self, texts, tags, masks):
super(NerDataset, self).__init__()
self.texts = texts
self.tags = tags
self.masks = masks
def __getitem__(self, index):
return {
"texts": self.texts[index],
"tags": self.tags[index] if self.tags is not None else None,
"masks": self.masks[index]
}
def __len__(self):
return len(self.texts)
class NerDatasetTest(Dataset):
def __init__(self, texts, masks):
super(NerDatasetTest, self).__init__()
self.texts = texts
self.masks = masks
def __getitem__(self, index):
return {
"texts": self.texts[index],
"masks": self.masks[index]
}
def __len__(self):
return len(self.texts)
前向传播分析:
(1)初始:
texts:[batch, seq_len] tags:[batch, seq_len] masks:[batch, seq_len]
(2)经过embed层:
x:[seq_len, batch, embedding_dim]
(3)经过lstm层:
out:[seq_len, batch, num_directions * hidden_size]
self.hidden:[num_directions , batch, hidden_size]
(4)经过dense层:
lstm_feats:[seq_len, batch, tagset_size]
(5)经过CRF层:
loss:负对数似然函数计算出来,是一个值
predictions:第一个维度是batch,第二个维度由传入的masks决定
Dataset
分别建立了训练集的NerDataset和测试集的NerDatasetTest
5 模型训练
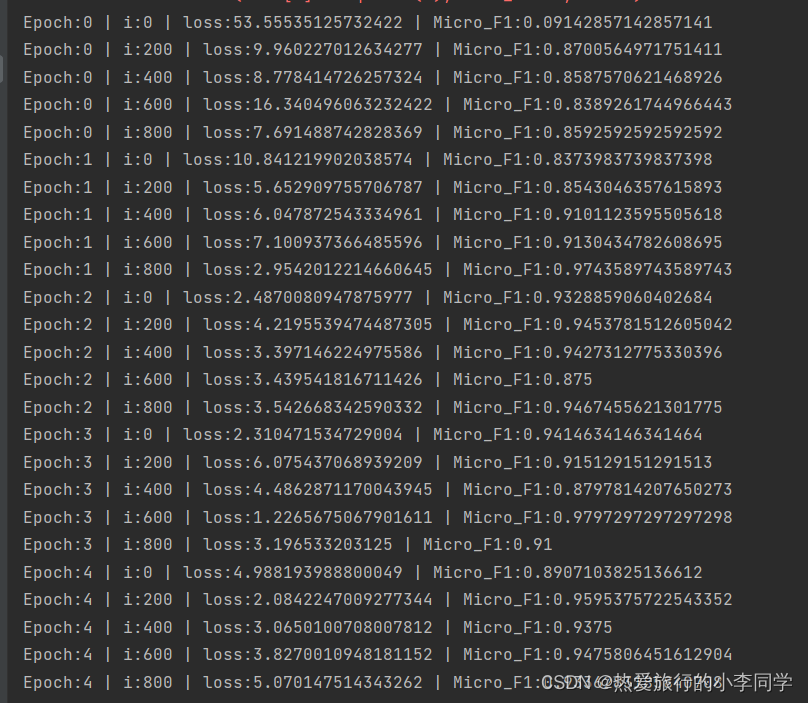
训练集传入模型返回loss和predictions,每隔200个iter输出损失值和微平均f1值
def train(train_dataloader, model, optimizer, epoch):
for i, batch_data in enumerate(train_dataloader):
texts = batch_data['texts'].to(DEVICE)
tags = batch_data['tags'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
loss, predictions = model(texts, tags, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 200 == 0:
micro_f1 = get_f1_score(tags, masks, predictions)
print(f'Epoch:{epoch} | i:{i} | loss:{loss.item()} | Micro_F1:{micro_f1}')
6 NER效果评估
计算micro f1值,用list.count()函数求得了原始的tag长度,也就是未被mask的长度,去掉头和尾,也就是每一个tags[index]和predictions[index]最多有m a x _ l e n − 2 \textcolor{red}{\ max_len-2}ma x _l e n −2个数据,这里对于为58个数据。按照列表切片并拼接起来,得到final_tags和final_predictions,最后调用s k l e a r n . m e t r i c s . f 1 _ s c o r e ( ) \textcolor{red} {sklearn.metrics.f1_score()}s k l e a r n .m e t r i cs .f 1_score ()函数计算micro_f1值
def get_f1_score(tags, masks, predictions):
final_tags = []
final_predictions = []
tags = tags.to('cpu').data.numpy().tolist()
masks = masks.to('cpu').data.numpy().tolist()
for index in range(BATCH_SIZE):
length = masks[index].count(1)
final_tags += tags[index][1:length - 1]
final_predictions += predictions[index][1:length - 1]
f1 = f1_score(final_tags, final_predictions, average='micro')
return f1
6 训练集流水线
代码:
def execute():
train_dataset, test_dataset = data_prepare()
create_word2index()
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
texts, tags, masks = text_tag_to_index(train_dataset, word2index)
train_dataset = NerDataset(texts, tags, masks)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
print(f"GPU_NAME:{torch.cuda.get_device_name()} | Memory_Allocated:{torch.cuda.memory_allocated()}")
for i in range(EPOCH):
train(train_dataloader, model, optimizer, i)
torch.save(model.state_dict(), MODEL_PATH)
效果:
7 测试集流水线
流程:
(1)加载数据集
(2)加载word2index文件
(3)文本转化为索引,并生成masks
(4)装载测试集
(5)构建模型,装载预训练模型
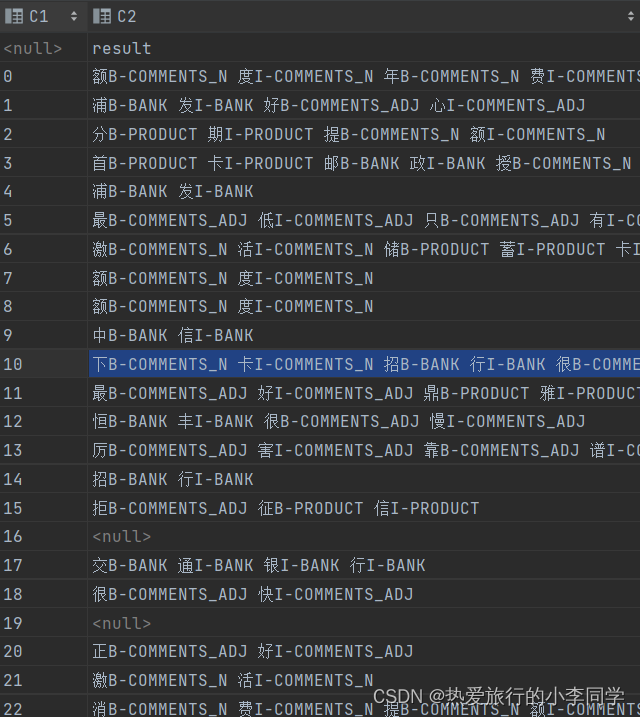
(6)模型预测
(7)将预测结果转化为文本形式过程中,需要将迭代器中每一个predictions去掉头和尾
(8)生成csc文件
代码:
def test():
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
texts, masks = text_to_index(test_dataset, word2index)
dataset_test = NerDatasetTest(texts, masks)
test_dataloader = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=False)
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
model.load_state_dict(torch.load(MODEL_PATH))
model.eval()
predictions_list = []
for i, batch_data in enumerate(test_dataloader):
texts = batch_data['texts'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
predictions = model(texts, None, masks)
predictions_list.extend(predictions)
print(len(predictions_list))
print(len(test_dataset['text']))
entity_tag_list = []
index2tag = {v: k for k, v in tag2index.items()}
for i, (text, predictions) in enumerate(zip(test_dataset['text'], predictions_list)):
predictions.pop()
predictions.pop(0)
text_entity_tag = []
for c, t in zip(text, predictions):
if t != 0:
text_entity_tag.append(c + index2tag[t])
entity_tag_list.append(" ".join(text_entity_tag))
print(len(entity_tag_list))
result_df = pd.DataFrame(data=entity_tag_list, columns=['result'])
result_df.to_csv('./data/result_df.csv')
效果:
8 完整代码
study_bilstm_crf.py
import numpy as np
import pandas as pd
import torch
import time
import pickle
import os
from torch import optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from bilstm_crf import BiLSTM_CRF, NerDataset, NerDatasetTest
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.metrics import f1_score
TRAIN_PATH = './dataset/train_data_public.csv'
TEST_PATH = './dataset/test_public.csv'
VOCAB_PATH = './data/vocab.txt'
WORD2INDEX_PATH = './data/word2index.pkl'
MODEL_PATH = './model/bilstm_crf.pkl'
MAX_LEN = 60
BATCH_SIZE = 8
EMBEDDING_DIM = 120
HIDDEN_DIM = 12
EPOCH = 5
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
tag2index = {
"O": 0,
"B-BANK": 1, "I-BANK": 2,
"B-PRODUCT": 3, "I-PRODUCT": 4,
"B-COMMENTS_N": 5, "I-COMMENTS_N": 6,
"B-COMMENTS_ADJ": 7, "I-COMMENTS_ADJ": 8
}
unk_flag = '[UNK]'
pad_flag = '[PAD]'
start_flag = '[STA]'
end_flag = '[END]'
def create_word2index():
if not os.path.exists(WORD2INDEX_PATH):
word2index = dict()
with open(VOCAB_PATH, 'r', encoding='utf8') as f:
for word in f.readlines():
word2index[word.strip()] = len(word2index) + 1
with open(WORD2INDEX_PATH, 'wb') as f:
pickle.dump(word2index, f)
def data_prepare():
train_dataset = pd.read_csv(TRAIN_PATH, encoding='utf8')
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
return train_dataset, test_dataset
def text_tag_to_index(dataset, word2index):
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, tags, masks = [], [], []
n_rows = len(dataset)
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
tag = dataset.iloc[row, 2]
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
tag_index = [0] + [tag2index.get(t) for t in tag.split()] + [0]
if len(text_index) < MAX_LEN:
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
tag_index += pad_len * [0]
elif len(text_index) > MAX_LEN:
text_index = text_index[:MAX_LEN - 1] + [end_index]
tag_index = tag_index[:MAX_LEN - 1] + [0]
def _pad2mask(t):
return 0 if t == pad_index else 1
mask = [_pad2mask(t) for t in text_index]
texts.append(text_index)
tags.append(tag_index)
masks.append(mask)
texts = torch.LongTensor(texts)
tags = torch.LongTensor(tags)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, tags, masks
def text_to_index(dataset, word2index):
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, masks = [], []
n_rows = len(dataset)
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
if len(text_index) < MAX_LEN:
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
elif len(text_index) > MAX_LEN:
text_index = text_index[:MAX_LEN - 1] + [end_index]
def _pad2mask(t):
return 0 if t == pad_index else 1
mask = [_pad2mask(t) for t in text_index]
masks.append(mask)
texts.append(text_index)
texts = torch.LongTensor(texts)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, masks
def train(train_dataloader, model, optimizer, epoch):
for i, batch_data in enumerate(train_dataloader):
texts = batch_data['texts'].to(DEVICE)
tags = batch_data['tags'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
loss, predictions = model(texts, tags, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 200 == 0:
micro_f1 = get_f1_score(tags, masks, predictions)
print(f'Epoch:{epoch} | i:{i} | loss:{loss.item()} | Micro_F1:{micro_f1}')
def get_f1_score(tags, masks, predictions):
final_tags = []
final_predictions = []
tags = tags.to('cpu').data.numpy().tolist()
masks = masks.to('cpu').data.numpy().tolist()
for index in range(BATCH_SIZE):
length = masks[index].count(1)
final_tags += tags[index][1:length - 1]
final_predictions += predictions[index][1:length - 1]
f1 = f1_score(final_tags, final_predictions, average='micro')
return f1
def execute():
train_dataset, test_dataset = data_prepare()
create_word2index()
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
texts, tags, masks = text_tag_to_index(train_dataset, word2index)
train_dataset = NerDataset(texts, tags, masks)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
print(f"GPU_NAME:{torch.cuda.get_device_name()} | Memory_Allocated:{torch.cuda.memory_allocated()}")
for i in range(EPOCH):
train(train_dataloader, model, optimizer, i)
torch.save(model.state_dict(), MODEL_PATH)
def test():
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
texts, masks = text_to_index(test_dataset, word2index)
dataset_test = NerDatasetTest(texts, masks)
test_dataloader = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=False)
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
model.load_state_dict(torch.load(MODEL_PATH))
model.eval()
predictions_list = []
for i, batch_data in enumerate(test_dataloader):
texts = batch_data['texts'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
predictions = model(texts, None, masks)
predictions_list.extend(predictions)
print(len(predictions_list))
print(len(test_dataset['text']))
entity_tag_list = []
index2tag = {v: k for k, v in tag2index.items()}
for i, (text, predictions) in enumerate(zip(test_dataset['text'], predictions_list)):
predictions.pop()
predictions.pop(0)
text_entity_tag = []
for c, t in zip(text, predictions):
if t != 0:
text_entity_tag.append(c + index2tag[t])
entity_tag_list.append(" ".join(text_entity_tag))
print(len(entity_tag_list))
result_df = pd.DataFrame(data=entity_tag_list, columns=['result'])
result_df.to_csv('./data/result_df.csv')
if __name__ == '__main__':
execute()
Original: https://blog.csdn.net/m0_46275020/article/details/126586912
Author: 热爱旅行的小李同学
Title: 猿创征文|信息抽取(1)——pytorch实现BiLSTM-CRF模型进行实体抽取
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531355/
转载文章受原作者版权保护。转载请注明原作者出处!