

目录
- 小样本学习few-shot learning, 旨在通过少量样本学习泛化能力强的模型。应用场景:标注数据成本高、推荐系统的冷启动、新药发现等。
- 小样本学习 方法有很多,从处理对象分类:利用先验知识增强现有数据、模型结构设计、算法(本文就是算法中的基于预训练的方式)
- 小样本学习的 发展历程,传统方法、深度学习时代、预训练时代标准微调范式、预训练时代微调新范式prompt tuning。
- 权威语言理解评测基准数据集GLUE榜单前五十,都是使用的预训练+标准微调范式。标准微调范式在数据密集场景大获成功。但是 标准微调范式在小样本场景下非常容易过拟合(参数量远远大于样本量)
- 预训练时代的微调新范式Prompt tuning:三大典型算法PET、P-Tuning、EFL。与标准微调范式不同点就是, 人工给预训练模型提示,然后把知识导出来。
- PET:利用先验知识人工定义模板,将目标分类任务转化为完形填空然后微调MLM任务参数,模板给预训练模型很多提示,就能做更精准的预测。随着样本量减少,PET的效果明显好于标准微调范式。但是模板不同对模型最终准确率影响很大, 自定义模板导致可能无法全局最优。
- P-Tuning克服PET的缺点,不再手动构建模板,而是使用可学习的向量做为伪模板。效果比PET更好, 可以全局优化,可以缓解人工模板的不稳定性。但是对于 超多分类任务场景预测难度大,也不适用于 蕴含任务(判断两句话的逻辑关系)。蕴含任务无法构造模板,构造出来的模板不符合自然语言习惯,预训练模型学得是符合自然语言习惯的内容,预测的时候mask掉的确实句子间的逻辑关系让预训练模型预测,属于强人所难了。
- EFL:把所有任务转化为二分类蕴含任务,这也大大降低了预测难度,也使预测精读提高了。 效果相比于PET和标准微调范式更好。有一个 tips就是 负样本数量很重要, 应当设置为总样本数量的一半,此时模型效果最好。效果很好也能做蕴含任务了,但是因为每个样本都要做一次预测所以 复杂度增加了。
- PaddleNLP内置了 R-drop API,这显著提升了模型效果。其核心思想是: 通过隐式数据增强(前向网络的随机dropout)引入KL距离约束(尽可能相似)来提升模型效果。加上R-drop之后GLUE、fewCLUE得分提高明显。 三行代码调用内置R-drop:
- 调用PaddleNLP内置的R-droploss然后实现
- 把模型喂进去,得到一个新的输出、
- 让增强后的隐式样本计算R-droploss
- 如果数据足够多的话,还是标准的好吗?也不一定, 有模板的话有针对性,可能效果更好
一、小样本学习FSL背景介绍
1.1 定义
- Few-shot learning旨在通过 少量样本学习泛化能力强的模型
- 怎么算少?每个类下仅有4/8/16个训练样本
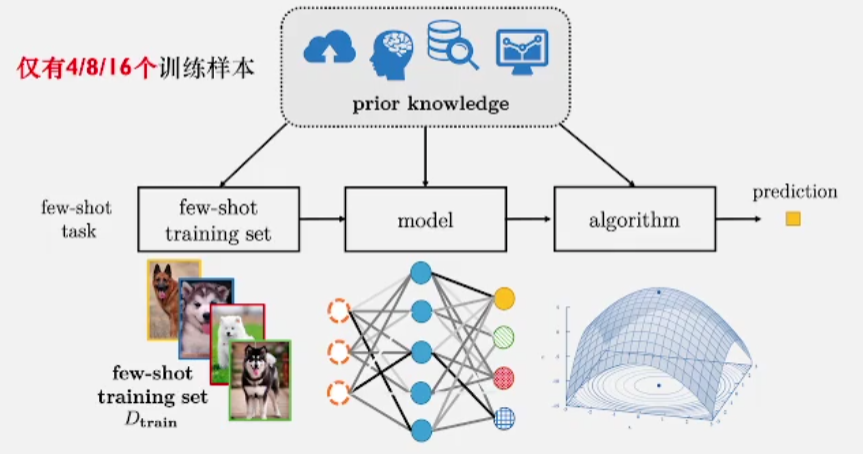

1.2 小样本学习为什么重要
- 标准的监督机器学习中所需要的标注数据量是非常大的,一般都要成千上万的规模。但是对人类来说,人类是通过少量的样本学习的。

- 专业知识才能标注,成本也非常高;冷启动:在没有用户数据的时候如何推荐,试探性的推荐然后根据反馈来进一步推荐;新药发现:需要做实验,需要专业性,成本高。

- 如果能做到小样本学习,就能免去数据标注,节省标注成本,降本增效
1.3 小样本学习的发展历程
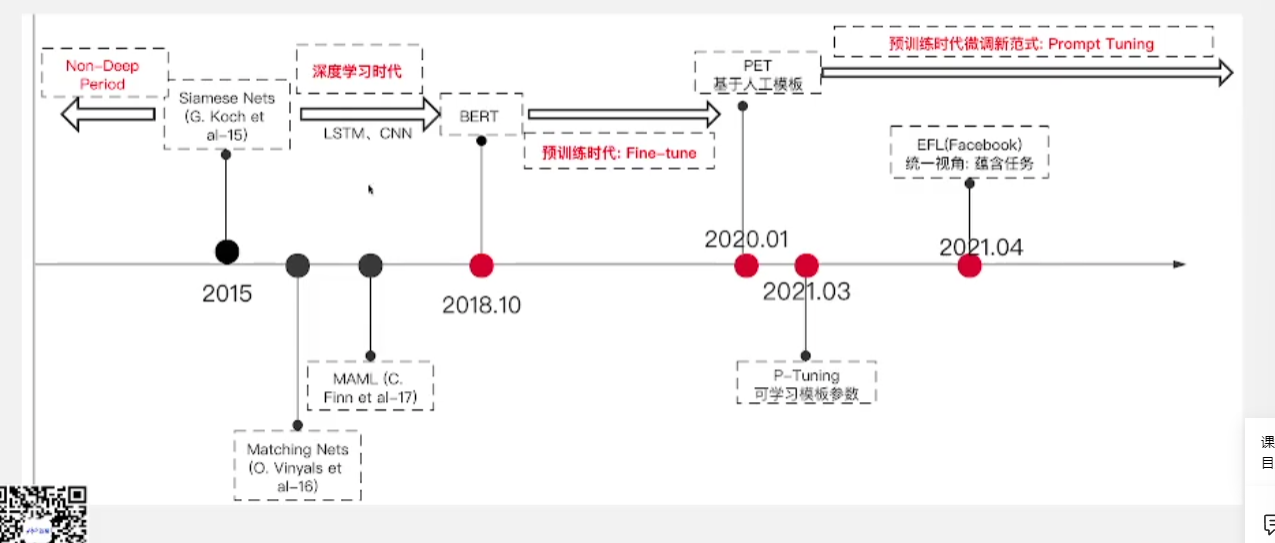
- 传统方法
- 15年之后逐渐步入 深度学习的时代,这个阶段的主流方法是用传统的神经网络、深度学习的模型来做小样本学习的任务
- 2018的10月,bert发布之后就进入了 预训练时代Fine-tuning,预训练+微调
- 2020PET诞生,进入 *预训练时代微调新范式prompt tuning
1.4 小样本学习方法分类

- 从处理对象来分类小样本学习方法可以分为三类
- 数据角度,就是怎样用先验的知识增强现有的数据,增加数据,让效果更好
- 模型,模型结构的设计和筛选
- 算法,传统和 *基于预训练的方式
二、预训练时代的微调新范式:三大典型算法
2.1 预训练时代的标准范式:NLP进入预训练时代
- 2018bert发布以来,就诞生了很多的预训练模型,基于预训练模型的Fine-tuning范式成为了NLP各个任务的标准的解决方案。标准的Fine-tuning范式,就是在预训练模型的基础上接一个任务层的网络(如:做分类任务,就接一个分类层)
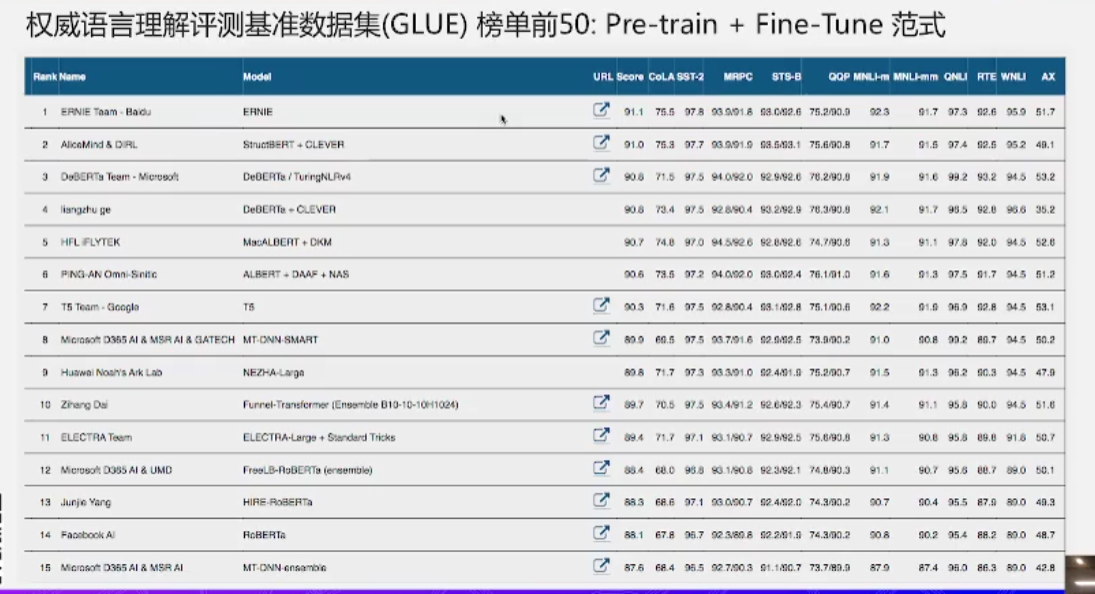
- 标准的Fine-tuning范式在数据密集场景大获成功,既然这么好,为什么要迁移到新范式呢?
2.2 既然这么好,为什么要迁移到新范式呢?
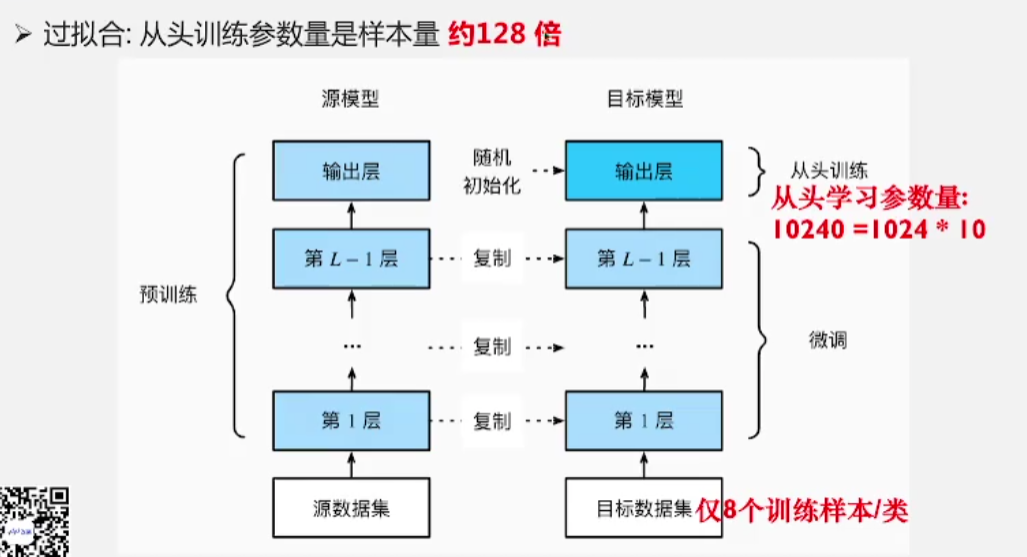
- 标准微调范式在小样本效果差, 为什么会效果差?因为 标准微调范式在小样本场景下非常容易过拟合。
- 如图,左边是预训练好的模型参数,右边是具体的下游任务我们要做微调,会先把参数复制过来,然后在顶层接一个具体任务所需要的层(参数是随机初始化的)
- 假如现在做十分类任务,使用的预训练模型是BERTLARGE,其隐层向量维度是1024。至此下游任务的网络需要从头学习的参数量就是1024*10,但是在小样本学习场景下,我们的数据中每个类只有8个训练样本,那么我们要从头训练的参数量时样本量的约128倍
- 当参数量远远大于样本量的时候,模型就会非常容易过拟合,导致效果很差
2.3 预训练时代的微调新范式:Prompt tuning
prompt tuning范式在小样本学习大放异彩,三大代表算法:PET、P-Tuning、EFL
prompt tuning的思想:将预训练模型中的知识挖掘出来并利用好,人工给预训练模型一些 提示,然后把知识导出来
2.3.1 PET:基于人工模板释放预训练模型潜力

- 利用先验知识人工定义模板,将目标分类任务转化为完形填空然后微调MLM任务参数
- 将模板与原始文本拼在一起输入预训练模型,预训练模型会对模板中的mask做预测,得到一个label
- 这个PET模板给了预训练模型很多提示,就能做更精准的预测
1 PET的效果
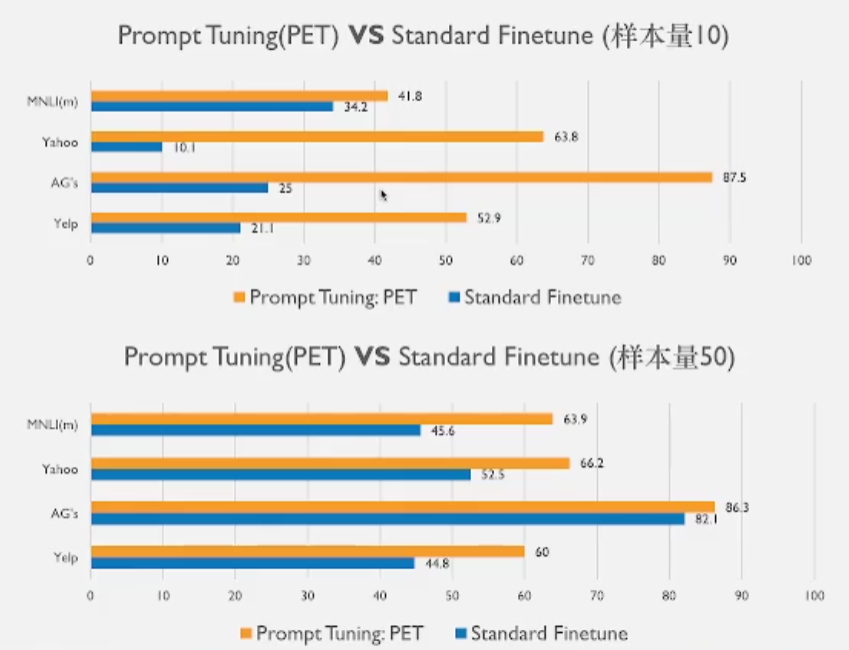
- 可以看到随着样本量的减少,PET的效果明显好于标准微调范式
2 PET的优点

3 PET的缺点

- 模板不同对模型最终的准确率影响非常大
- 因为自定义模板所以也无法全局最优化
2.3.2 P-Tuning:连续空间可学习模板

- 很好的解决了PET的缺点,使用可学习的向量作为”伪”模板,不再手动构建模板
- 用特殊字符代替自然语言,特殊字符可以自由学习,再接上原始输入
1 P-Tuning与PET的效果对比
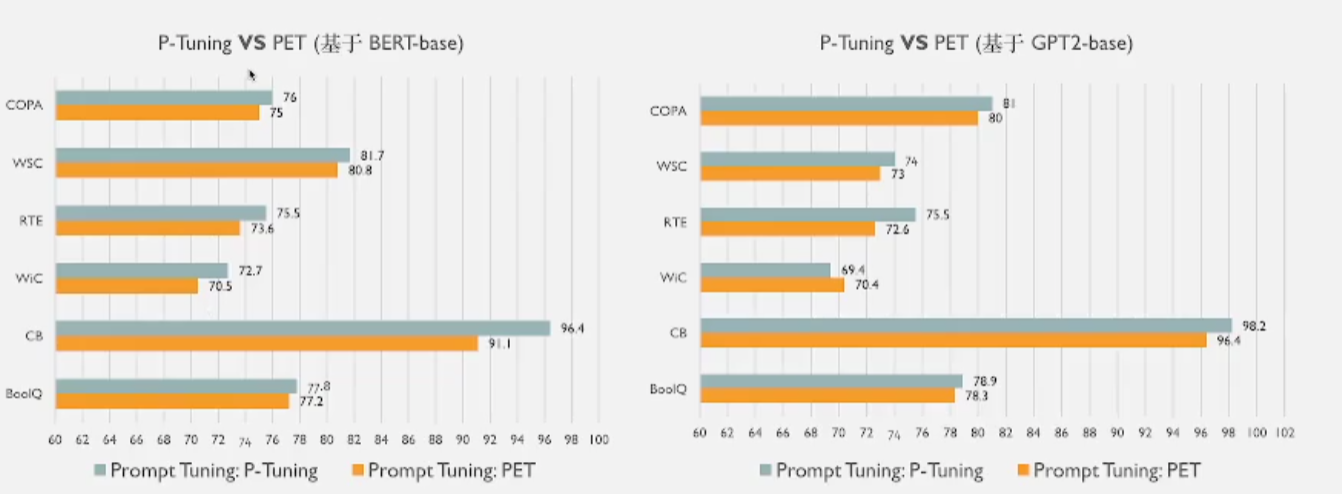
- 基于bertbase和gpt2-base,都可以看到P-Tuning的效果更好
2 P-Tuning优点

3 P-Tuning缺点

- 蕴含任务:给定两句话,让模型判断两句话的逻辑关系,矛盾或者蕴含或者中立

- 预训练模型学习的都是符合自然语言习惯的内容,现在在mask处加上了蕴含或者矛盾,不符合自然语言习惯,让预训练模型去预测,属于强人所难了
2.3.3 EFL:所有任务转化为蕴含任务

- 解决了pet和ptuning的缺点,通过把所有目标任务转化为二分类蕴含任务
- 多分类任务转化为二分类,大大降低了预测难度
1 EFL PET 标准微调范式的效果对比
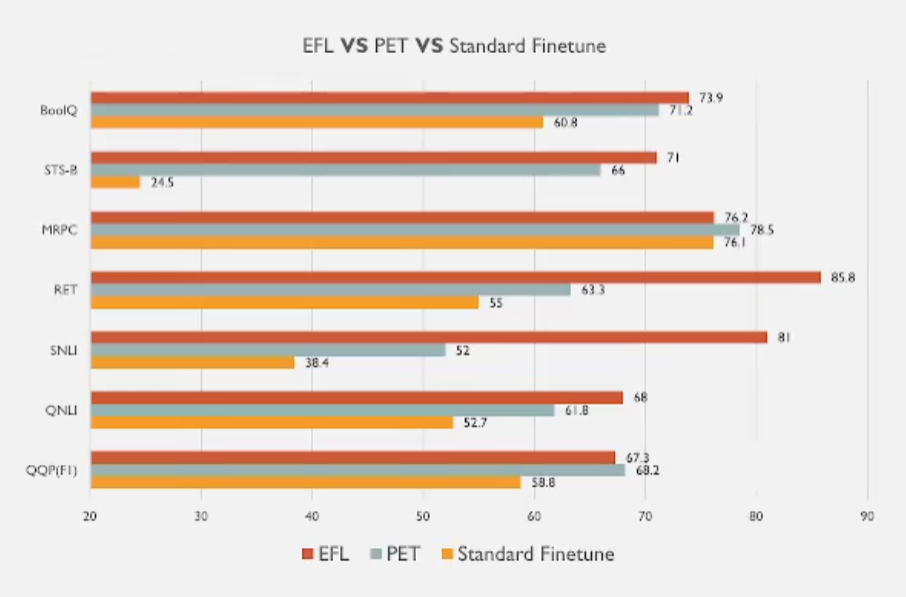
- EFL算法效果非常好
2 EFL算法的优点
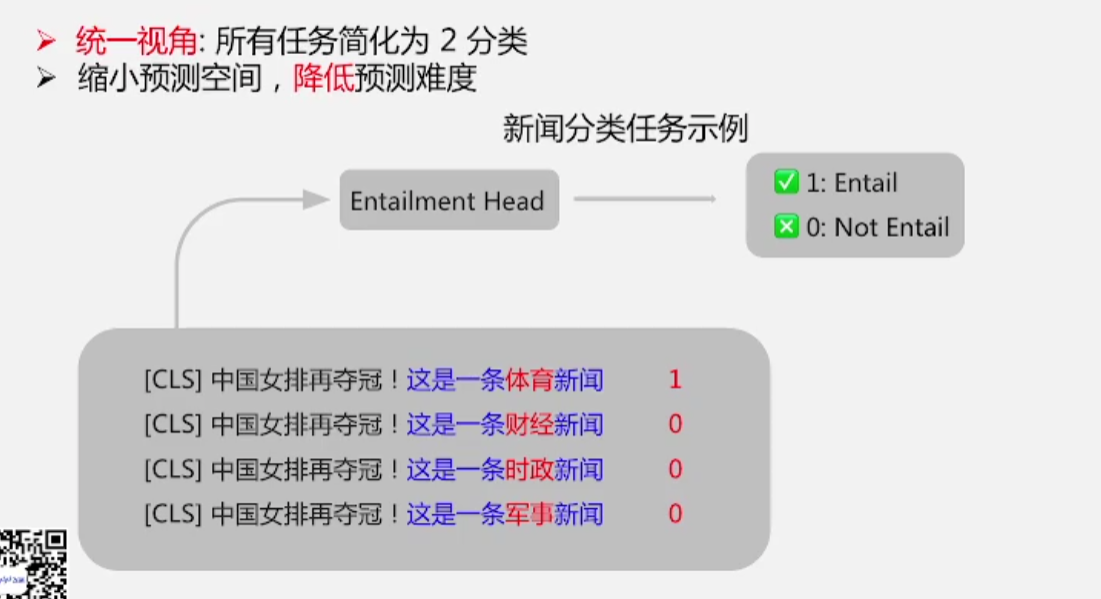
- 预测难度降低了,预测精度就提高了
3 EFL tips:负样本数量很重要
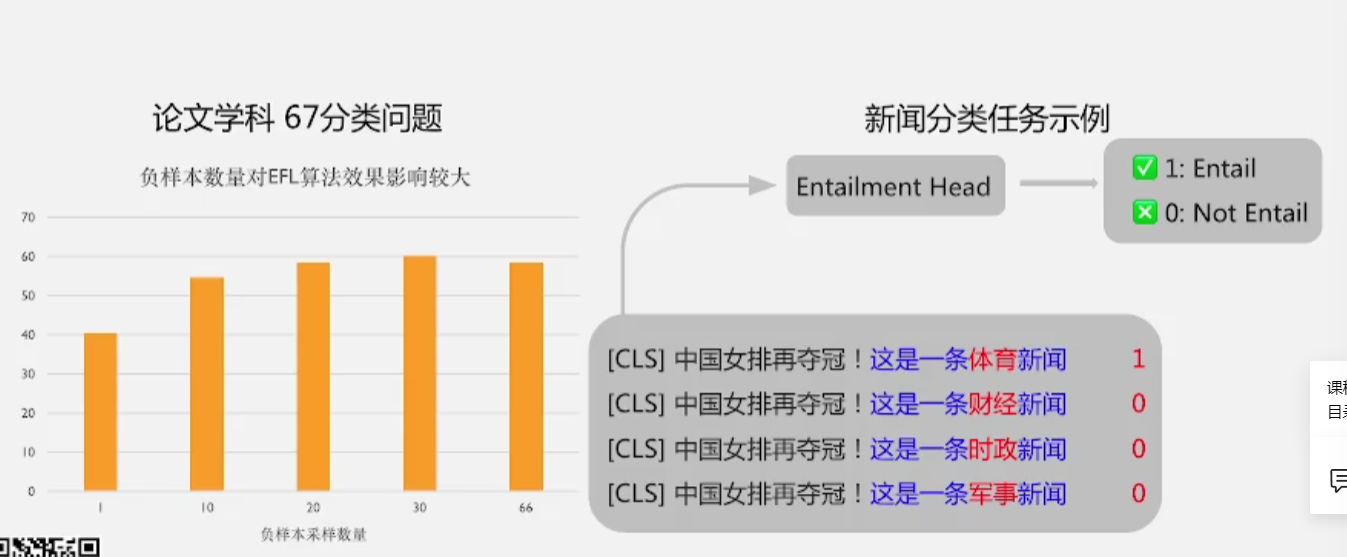
- 论文学科是一个67分类问题,按照EFL算法,可以构造66个负样本
- 横轴是负样本采样数量,纵轴是准确率,随着负样本数量增加,模型效果在增加
- 一般情况下负样本的数量设置为总样本数量的一半,此时模型效果最优
4 EFL缺点:增加预测复杂度
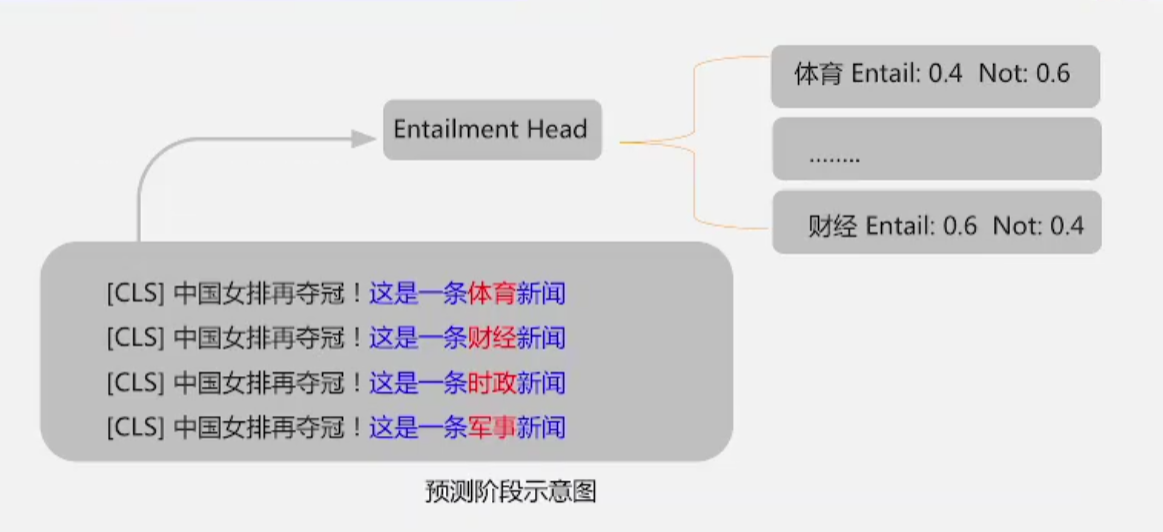
- 增加了预测阶段的复杂度:本来模型在预测阶段只需要做一次预测,现在用EFL,有多少类别就要做多少次预测
- 每一个样本都要预测
三、PaddleNLP小样本学习特色能力
3.1 特色一,内置R-Drop API显著提升模型效果
3.1.1 R-drop的核心思想

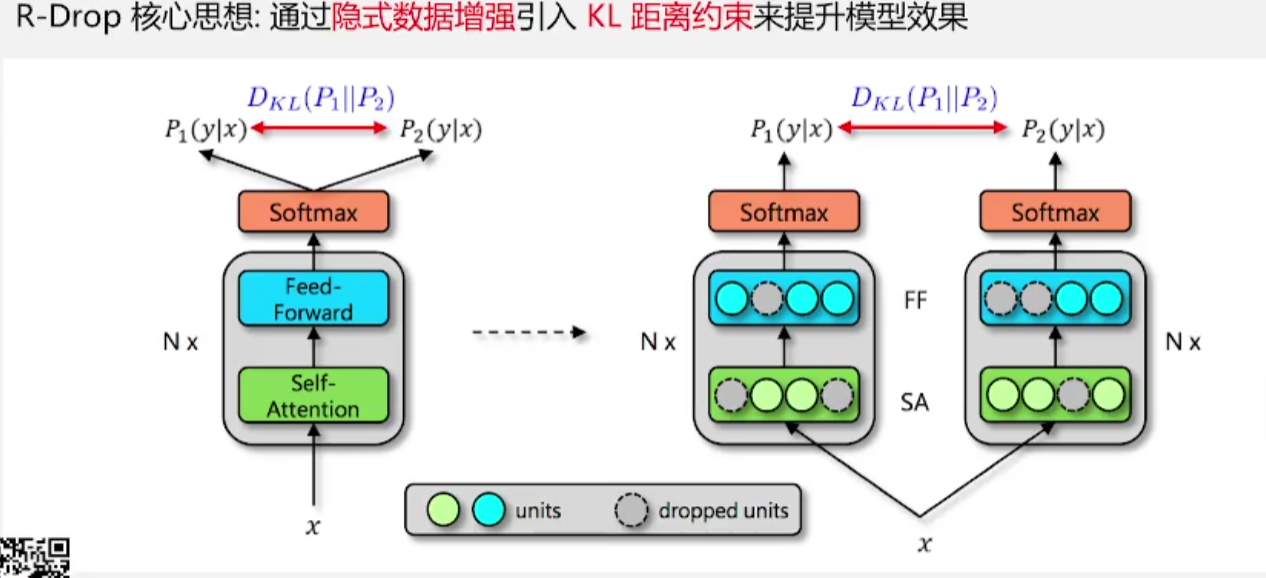
- 数据进入前向网络后得到的向量,由于前向网络中存在的随机dropout,输出的向量每次不同,就是隐式数据增强
- R-drop又通过KL距离约束使输出的向量尽可能的相似,数据增强无疑是会增加模型效果的
3.1.2 R-drop的效果
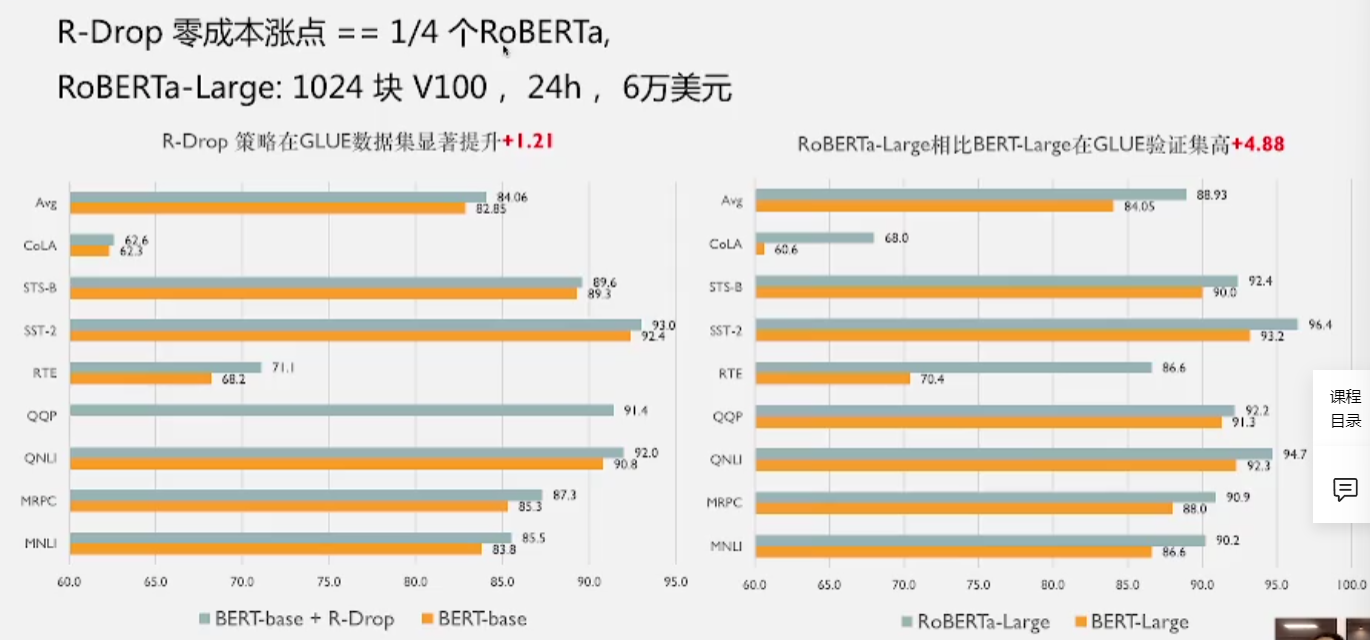
- 模型效果一般就是在这个权威的数据集上做评测
- 加上R-drop之后的得分提升显著
- 对比右表是说明,roberta的效果提升非常昂贵且困难,而R-drop就调用一下api效果就能提升四分之一个roberta

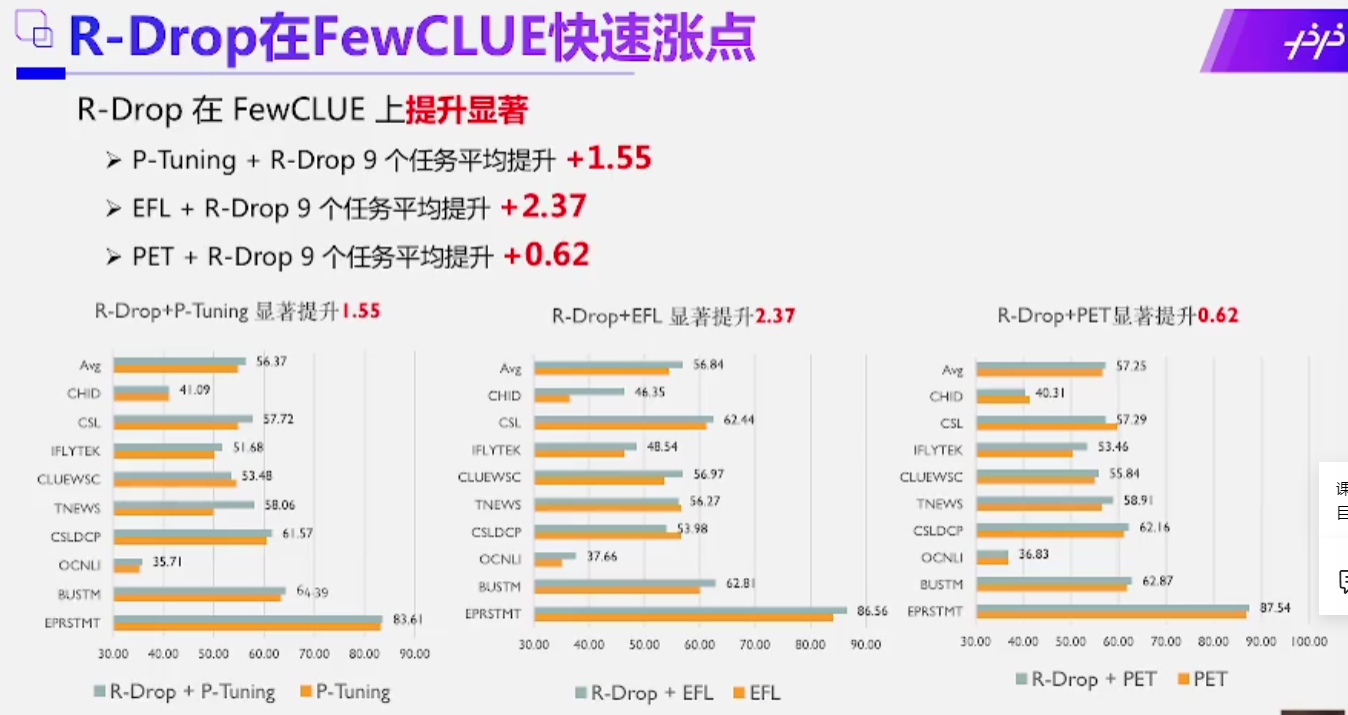
- pet P-Tuning EFL这三个算法分别加入R-drop策略之后,也看到效果的显著提升

- 调用PaddleNLP内置的R-droploss然后实现
- 把模型喂进去,得到一个新的输出
- 让增强后的隐式样本计算R-droploss

四、基于情感分类任务各范式效果对比
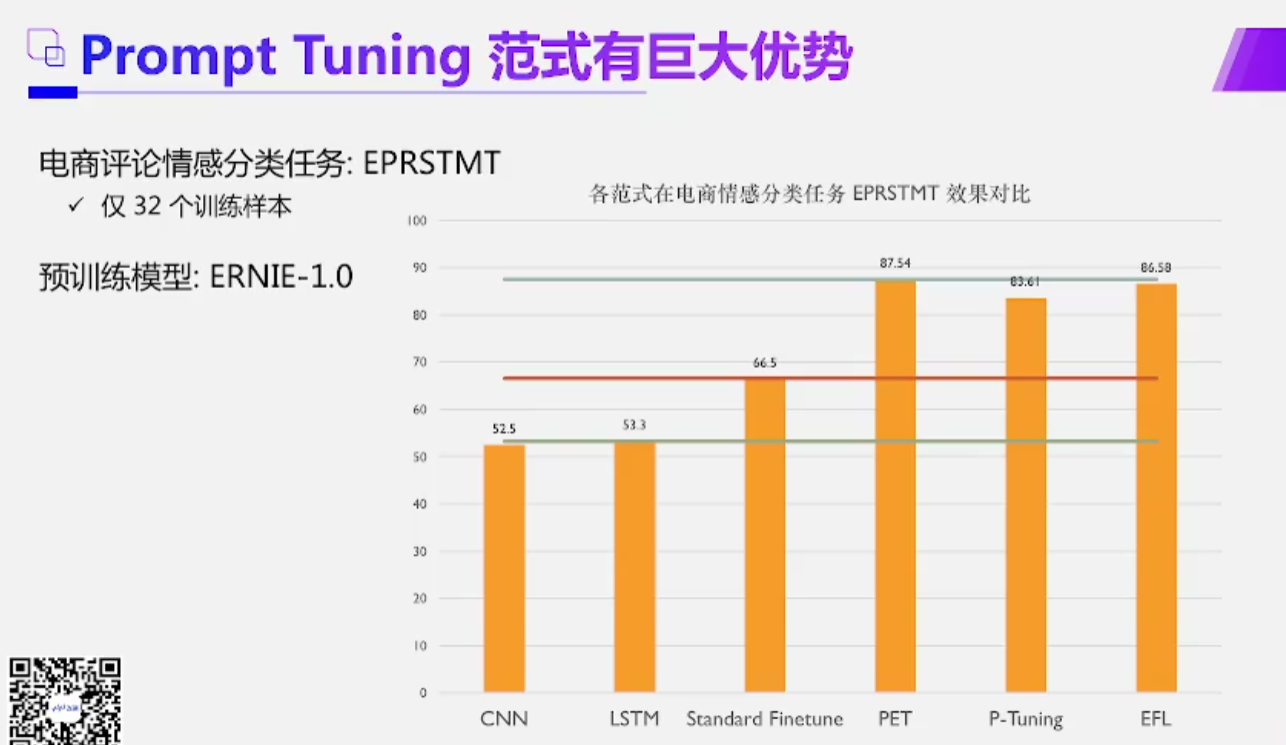
- 电商评论情感分类任务,这个小样本任务只有32个训练样本,每个类别有16个训练样本
- 预训练模型用ERNIE-1.0
- 分别对比了传统算法,也对比了标准微调算法,以及新范式三个算法的效果
- 在情感分类任务上几乎有20个点提升

Original: https://blog.csdn.net/qq_42030496/article/details/122563730
Author: 云淡风轻__
Title: AI快车道PaddleNLP系列直播课3|自然语言处理中的小样本学习
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531347/
转载文章受原作者版权保护。转载请注明原作者出处!