

之前用统计的方法(TFIDF理解和应用)做了一个计算单词 TFIDF的任务,这次用机器学习的思路。
1 思路
1.1 随机初始化
随机初始化每个词的 TDIDF值,全部分别存到 w_en和 w_de中。
1.2 定义loss函数
读入每一句,根据 w_en、 w_de计算每一句所构成单词的英、德 TFIDF值的和。根据标签,如果这句话是英语,但是结果 score_de大于 score_en,说明需要调参。
因此定义损失函数: loss = score_de - score_en(对德语来 loss = score_en - score_de)。
1.3 调整参数
调整参数的原理就是调整后的值 = 当前值 – 学习率 * loss在该点的梯度值。
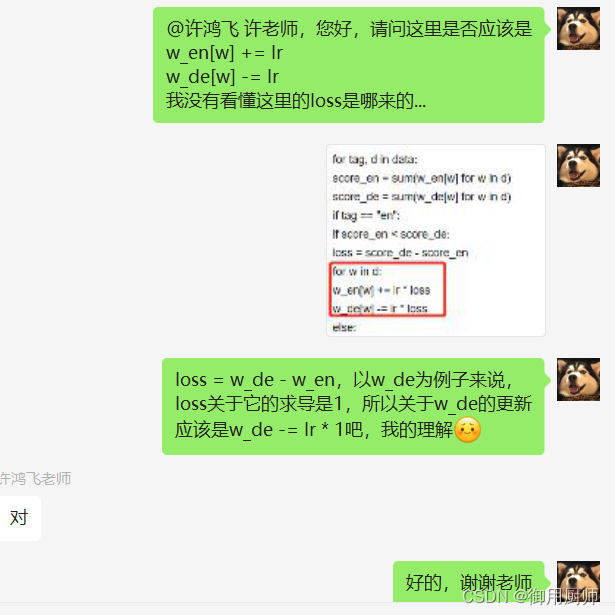
对标签是英语的句子来说: loss = sum(w_de) - sum(w_en)。
loss关于每一个 w_de的求导为 1,所以更新时 w_de[w] -= lr。同理, w_en[w] += lr。
附上我咨询老师的截图:

; 2 注意事项
2.1 set()的使用、add()方法
vocab = set()
if word and (word not in vocab):
vocab.add(word)
2.2 shuffle
我最初的思路是先对英语语料的全部做一遍,再对德语语料的全部做一遍,许老师说这样容易造成数据走向一边倒的情况,所以最好是一句英语一句德语,这种方法应该叫做 shuffle(可以参考机器学习,深度学习模型训练阶段的Shuffle重要么?为什么?)。
使用的是 yield关键字和 next()方法:(可以先参考python中yield的用法详解——最简单,最清晰的解释)
def reader(srcf, tag):
with open(srcf, "rb") as frd:
for line in frd:
tmp = line.strip()
if tmp:
tmp = tmp.decode("utf-8")
yield tmp, tag
r_en = reader(f_path2, "en")
while True:
try:
line_en, t_en = next(r_en)
except:
line_en = None
2.3 初始化经验
根据经验,初始化范围一般是 random.uniform(-sqrt(1/len(vocab)), sqrt(1/len(vocab)))。
其中, uniform是均匀分布。
2.4 声明global
在函数中不声明函数全局变量可能会有问题,最好声明 global。(我每次都忘…)
3 代码
from math import sqrt
from random import uniform
path1 = "data/corpus.tc.de"
path2 = "data/corpus.tc.en"
test1 = "data/tiny_de.txt"
test2 = "data/tiny_en.txt"
path3 = "TFIDF 2/result_de_2.txt"
path4 = "TFIDF 2/result_en_2.txt"
vocab = set()
w_en = {}
w_de = {}
def build_vocab(srcf):
global vocab
with open(srcf, "rb") as frd:
for line in frd:
tmp = line.strip()
if tmp:
tmp = tmp.decode("utf-8")
for word in tmp.split():
if word and (word not in vocab):
vocab.add(word)
def random_vocab():
rang = sqrt(1 / len(vocab))
r_en = {w: uniform(-rang, rang) for w in vocab}
r_de = {w: uniform(-rang, rang) for w in vocab}
return r_en, r_de
def reader(srcf, tag):
with open(srcf, "rb") as frd:
for line in frd:
tmp = line.strip()
if tmp:
tmp = tmp.decode("utf-8")
yield tmp, tag
def handle(line, tag):
global w_en
global w_de
line = line.split()
lr = 1e-3
score_en = sum(w_en[w] for w in line)
score_de = sum(w_de[w] for w in line)
if tag == "en":
if score_en < score_de:
for w in line:
w_en[w] += lr
w_de[w] -= lr
if tag == "de":
if score_de < score_en:
for w in line:
w_en[w] -= lr
w_de[w] += lr
def sf_handle(f_path1, f_path2):
r_de = reader(f_path1, "de")
r_en = reader(f_path2, "en")
while True:
try:
line_en, t_en = next(r_en)
except:
line_en = None
if line_en is not None:
handle(line_en, t_en)
try:
line_de, t_de = next(r_de)
except:
line_de = None
if line_de is not None:
handle(line_de, t_de)
if (line_en is None) and (line_de is None):
break
def save(fname, obj):
with open(fname, "wb") as fwrt:
fwrt.write(repr(obj).encode("utf-8"))
if __name__ == '__main__':
build_vocab(path1)
build_vocab(path2)
w_en, w_de = random_vocab()
sf_handle(path1, path2)
save(path3, w_de)
save(path4, w_en)
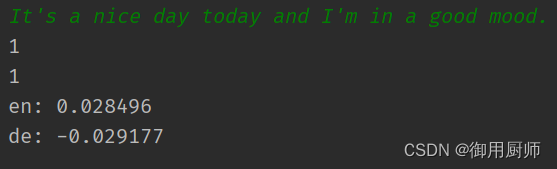
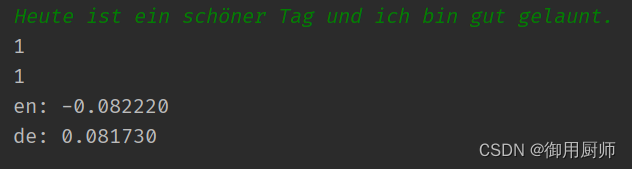
4 结果
结果还行。
Original: https://blog.csdn.net/qq_45520647/article/details/124459653
Author: 御用厨师
Title: 用机器学习的思路训练单词的TFIDF值
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531303/
转载文章受原作者版权保护。转载请注明原作者出处!