



目前的深度学习主要分为以下几个领域:
; 图像领域(CV)
representative task
图像分类
目标检测,目标跟踪,动作检测
实例分割
超分辨率(去马赛克)
去雾去雪
3D重建
风格迁移
OCR(光学字符识别)
自然语言处理(NLP)
文本分类
文本标签
实体抽取
句法依存
语义消歧
情感分析
机器翻译
自然语言理解(NLU)
观点分析
意图提取/识别
智能对话
生成任务
多模态(multimodal)
其他:语音识别(AVR)
针对这些领域以及其子任务,在深度学习蓬勃发展的前30几年(1987-2018)其主导的模型主要以3大家族为代表,分别为CNN和RNN和ANN模型族,

在很长一段时间里,三个家族都是在各自的领域进行深耕,互不打扰,比如CNN是图像(cv)领域的王者,RNN则是NLP和ASR的扛鼎,而这一切的基础,则是ANN,即人工神经网络的崛起。
在其后的一段时间,虽然这些模型之间有过一些有限的交流,比如用于处理文本的TEXT-CNN,处理图像的LSTM等,但是并没有质的飞跃。人工智能的各个领域就像拼图的碎片一样散落在各处,同时,这些模型的弊端也渐渐的显露出来,比如RNN的梯度消失问题,无法捕获长依赖的特征,CNN无法捕获局部与整体的关系等等,
虽然后面也有很多的工作致力于解决这些问题,例如,针对RNN无法建模长序列信息的问题,LSTM提出了门控机制,针对CNN的问题,提出了FPN,多维度多尺度地捕获特征,但是以上这些措施都只是缓解了问题而已,并没有真正解决这类问题。但是一个模型的出现改变了一切,他就是Transformer,Transformer 完全抛弃了传统的 CNN 和 RNN,整个网络结构完全由注意力机制组成,这种改变所带来的效果提升也是颠覆性的。
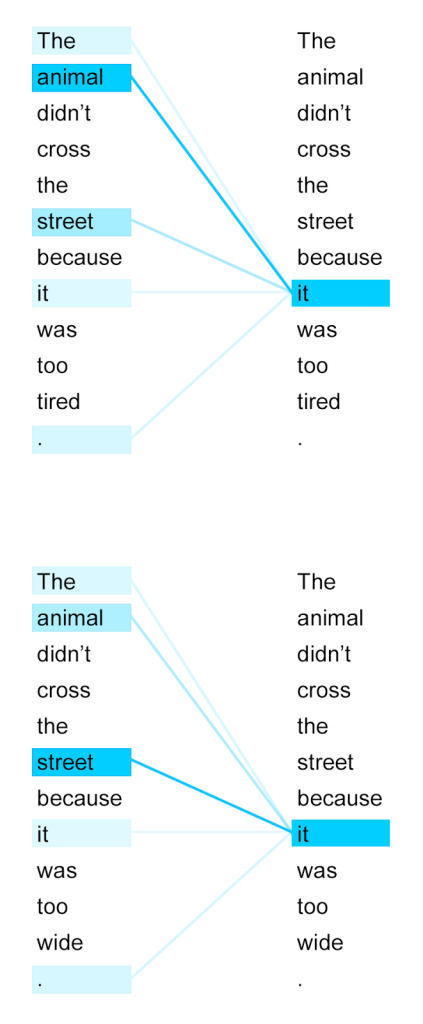
注意力机制的出现彻底解决了如何使用神经网络”记忆力差”这一问题,并且开创了一种新的深度学习范式,被称作”预训练 + fine-tuning”的模式,通过这一模式,它能够训练出更加通用的模型,再根据不同的下游任务进行微调来提高性能,这是认为是一种目前最有可能通向GAI(通用人工智能)的路径。
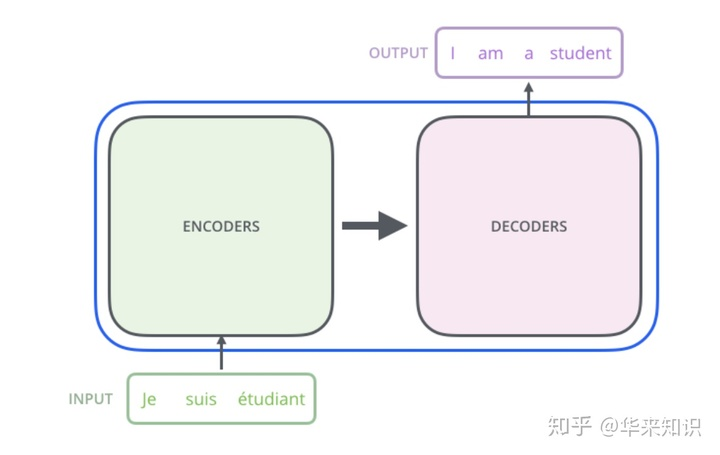
Transformer最先是在NLP领域被发明,它最先被应用在了机器翻译上,并取得了当年的SOTA(sate of the art),随后更是诞生出了当前最流行的自然语言处理模型:BERT,

但是它惊人的地方在于,它不止可以用来处理文本问题,这两年的一些研究发现,它甚至还可以用来做视觉任务,并且效果不亚于甚至强于CNN,甚至在其他的领域诸如图数据(GNN图神经网络,化学分子构型,蛋白质折叠方式),它都相当的有竞争力甚至是目前的最优解。
所以Transformer被认为是在未来20年里最有可能打破”深度学习模态壁垒”的模型,它的意义就像是大统一理论之于物理学一般,它有可能让目前人工智能真正实现和人一样学习物理世界方法,即从不同的模态(例如图像,文字,声音,抽象法则,图)中融合学习,进而产生更高级的思维活动(甚者还能生产表情包。。。)

(由AI生成的表情包)
本次我们参加了,是由交通银行举办的世界人工智能大赛中的手写汉字OCR任务,在这次的比赛中我们就使用到了Transformer,不过是用来处理视觉任务的,叫做视觉Transformer(VIT),它的方法也是相当的简单粗暴,就是将图片当作句子一样看待,将图像分成一个个小的patch,再输入进模型中。我们之前采用的方案是CNN+RNN的模型,准确率只有25%,
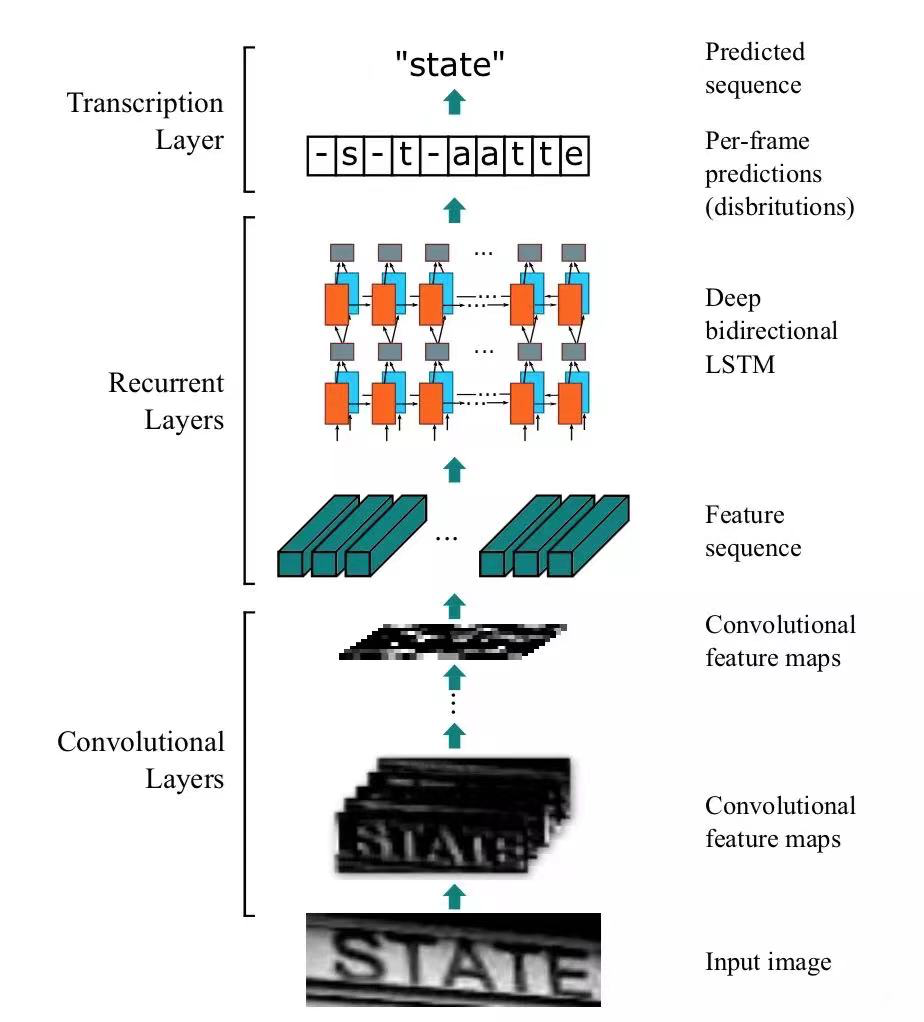
但是VIT的准确率却有90%,当然这距离第一名的准确率还尚有差距,但这是在我们的模型只用了不到50M的数据进行训练而且没有使用数据增强以及其他的微调技巧的前提下。
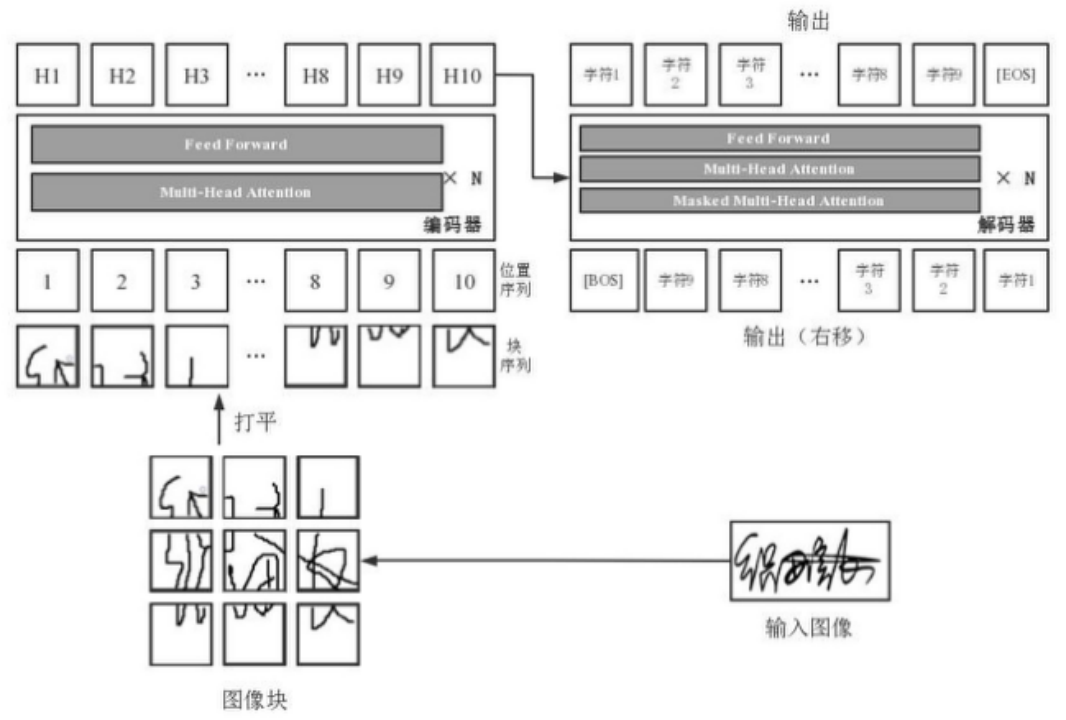
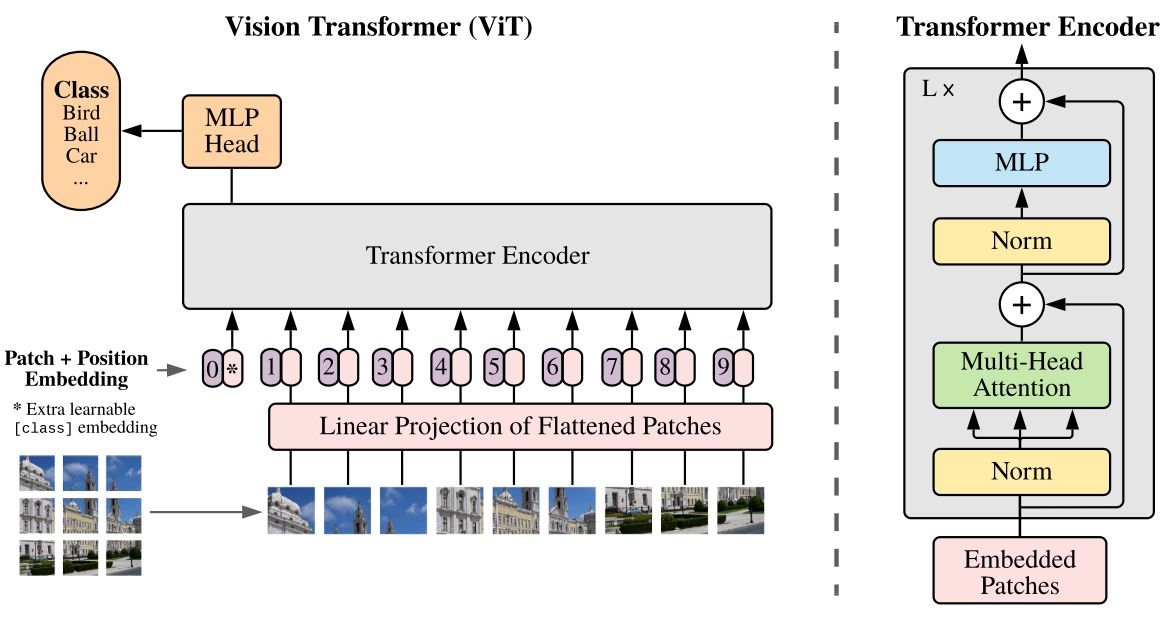
那么为什么这个模型这么强大呢,有一个重点在于预训练,人们很早就意识到人的学习方式是一种基于大样本的无监督或者自监督学习,举个例子,”问:酸菜鱼的配料有鱼和什么?”,在看到这句话的时候,人类不会从头的去学习什么是鱼,什么是酸菜鱼,而是人的大脑里已经有了一种能力,一看到酸菜,就能想到鱼,我们需要机器也具备这种联想能力,但是这并不用靠监督的模式实现,并不需要你明确的告诉模型,酸菜鱼是用鱼和酸菜做的,如果这样做的话,世界上的组合是无穷的,你不可能每一条知识都告诉模型,人的学习也是一样的,更多的是靠领悟,而这个领悟是没有正确的信息输入的,就像一个很老练的厨师,你让他做一道大家从未做过的菜,他总能做的比一个菜鸟厨师好。这就是预训练。
在NLP领域,一般是将语句转化为向量来进行处理,被叫做词向量,这些词向量就在巨量的文本数据中进行了预训练,它能让那些有相关性的词语在向量空间中考的更加紧密一个近点的例子:”king – man + women = queen”但是这种词向量是静态的,它无法随着任务的不同的在改变,也就意味着不管在什么文本里,在模型认为”king – man + women 永远等于 queen”,这显然是不对的,所以BERT出现了,它完全由Transformer所组成,它的词向量是动态的,这导致了在工业界,不管对什么任务,什么领域,只需要在其他人预训练过的bert模型上进行微调即可,再也不必为了不同的任务去设计不同的模型。

当然这也导致现在许多的研究者的能力下降(笑)
; 如何入门深度学习
- 机器学习
- 代码
- 关注前沿
- 参加比赛
Original: https://blog.csdn.net/weixin_43966900/article/details/121633112
Author: YuCong Wang
Title: 深度学习前沿技术摘要
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531245/
转载文章受原作者版权保护。转载请注明原作者出处!