

句法分析(Constituency Parsing)是NLP领域非常重要、也是相对基础的解析任务。
句法分析的任务,就是解析出句子中的短语结构、短语之间的层次句法关系。
通过Stanford提供的CoreNLP,很容易实现句法分析。比如下面这句话:
which province is jack and john electorated in?
首先,我们可以通过斯坦福提供的在线网站 http://corenlp.run/ 对这句话进行解析,如下:


点击Submit后,可以constituency parse的结果:
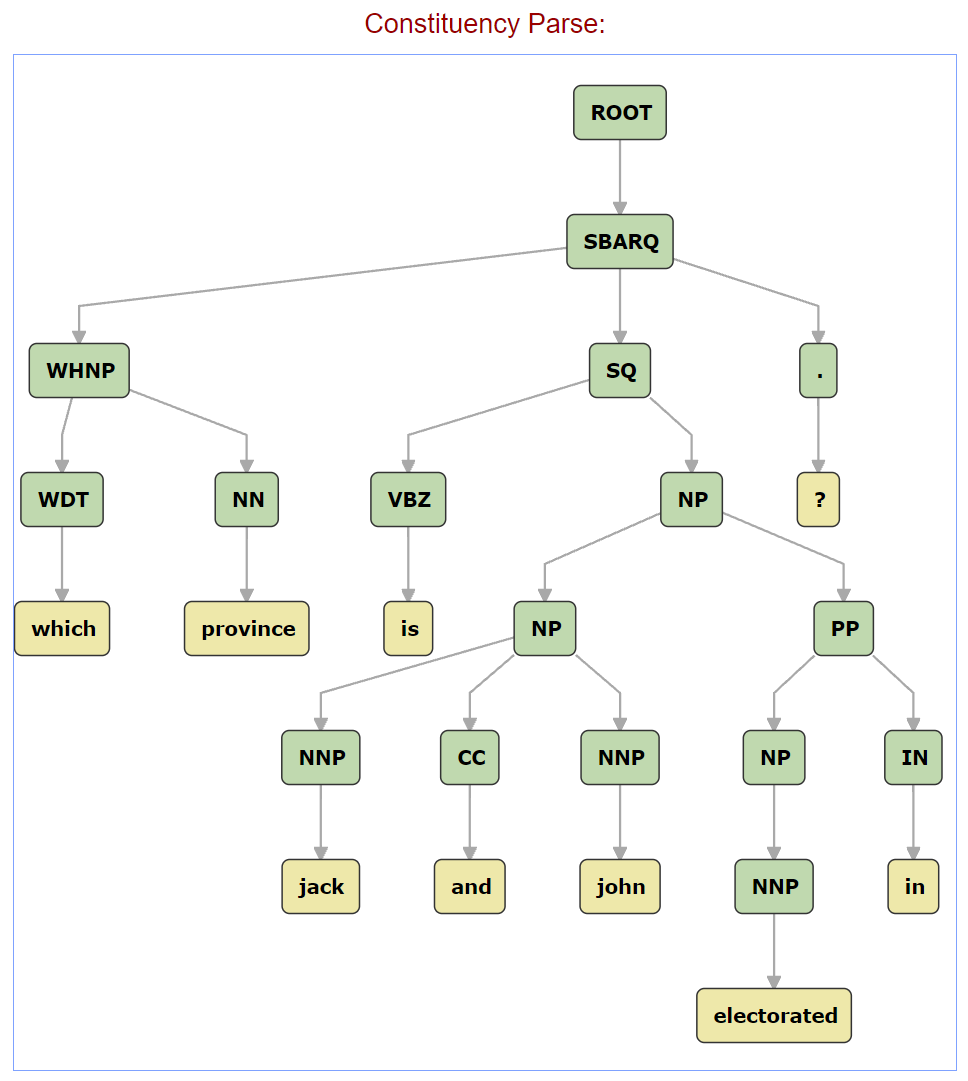
那么,如何通过代码来实现呢?StanfordCoreNLP获取句法解析树的Java代码如下:
class NLPUtils{
private static Properties properties = new Properties();
private static StanfordCoreNLP pipeline;
static{
init();
}
/**
* 成分分析、语法分析
* @param singleNL
*/
public static void constituencyAnalysis(String singleNL){
if (StringUtils.isBlank(singleNL)){
return;
}
CoreDocument document = getCoreDocument(singleNL);
CoreSentence sentence = document.sentences().get(0);
Tree constituencyParse = sentence.constituencyParse();
System.out.println(constituencyParse);
}
/**
* 获取 NL 的 CoreDocument 对象
*
* @param NL
* @return
*/
public static CoreDocument getCoreDocument(String NL) {
return pipeline.processToCoreDocument(NL);
}
/*
* 初始化
* */
private static void init() {
properties.setProperty("annotators", "tokenize,ssplit,pos,lemma,ner,depparse,parse");
properties.setProperty("ner.additional.regexner.ignorecase", "true");
properties.setProperty("ner.applyNumericClassifiers", "true");
properties.setProperty("ner.buildEntityMentions", "true");
properties.setProperty("ner.useNERSpecificTokenization", "true");
pipeline = new StanfordCoreNLP(properties);
}
public static void main(String[] args) {
String singleNL = "which province is jack and john electorated in ?";
constituencyAnalysis(NL);
}
}
上面的代码执行结果如下:
(ROOT (SBARQ (WHNP (WDT which) (NN province)) (SQ (VBZ is) (NP (NP (NNP jack) (CC and) (NNP john)) (PP (NP (NNP electorated)) (IN in)))) (. ?)))
有兴趣的朋友可以通过代码将上面的结果转化为多叉树的结构。
【提示】
通过CoreSentence.constituencyParse()获取到解析树后,再去获取到它的iterator:
Iterator iterator = constituencyParseTree.stream().iterator();
while (iterator.hasNext()){
Tree next = iterator.next();
System.out.println(next);
System.out.println(next.numChildren());
}
}
输入结果如下,将输入结果同文章开头的图进行比较,便可以得到一些思路:
(ROOT (SBARQ (WHNP (WDT which) (NN province)) (SQ (VBZ is) (NP (NP (NNP jack) (CC and) (NNP john)) (PP (NP (NNP electorated)) (IN in)))) (. ?)))
1
(SBARQ (WHNP (WDT which) (NN province)) (SQ (VBZ is) (NP (NP (NNP jack) (CC and) (NNP john)) (PP (NP (NNP electorated)) (IN in)))) (. ?))
3
(WHNP (WDT which) (NN province))
2
(WDT which)
1
which
0
(NN province)
1
province
0
(SQ (VBZ is) (NP (NP (NNP jack) (CC and) (NNP john)) (PP (NP (NNP electorated)) (IN in))))
2
(VBZ is)
1
is
0
(NP (NP (NNP jack) (CC and) (NNP john)) (PP (NP (NNP electorated)) (IN in)))
2
(NP (NNP jack) (CC and) (NNP john))
3
(NNP jack)
1
jack
0
(CC and)
1
and
0
(NNP john)
1
john
0
(PP (NP (NNP electorated)) (IN in))
2
(NP (NNP electorated))
1
(NNP electorated)
1
electorated
0
(IN in)
1
in
0
(. ?)
1
?
0
Original: https://blog.csdn.net/Elliot_Elliot/article/details/121505923
Author: 进击的Coder*
Title: #保姆级# StanfordCoreNLP — 句法分析 + 可视化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531151/
转载文章受原作者版权保护。转载请注明原作者出处!