

2021SC@SDUSC
目录
2021SC@SDUSC
normal_bert.py 代码分析
代码输入包含七个部分,分别为
input_ids,input_mask,segment_ids,masked_lm_positions,mask_lm_ids,masked_lm_weights,next_sentence_labels.
input_ids:表示tokens的ids
input_mask:表示哪些是input,哪些是padding.len(input_ids)个1,后面继续补0.对于mask的词,主要占了全部vocabulary的15%左右,在代码中对于每个词80%replace with [mask],10% keep original,10% replace with random word.超过了mask的词数,则终止.
segment_ids:第一个句子到[SEP]为0,后面为1.主要是对输入进行区分,判断输入的两个句子.
masked_lm_positions:表示句子中mask的token的position.
mask_lm_ids:表示句子中mask的token的id.
masked_lm_weights:表示句子中mask的token的权重.
next_sentence_labels:表示两个句子是不是相连的.
代码示例
class ClassificationBert(nn.Module):
def __init__(self, num_labels=2):
super(ClassificationBert, self).__init__()
加载预训练bert模型
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.linear = nn.Sequential(nn.Linear(768, 128),
nn.Tanh(),
nn.Linear(128, num_labels))
python中torch.nn解析
torch.nn是专门为神经网络设计的模块化接口。nn构建于autograd之上,可以用来定义和运行神经网络。
nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
定义自已的网络:
需要继承nn.Module类,并实现forward方法。
一般把网络中具有可学习参数的层放在构造函数__init__()中,
不具有可学习参数的层(如ReLU)可放在构造函数中,也可不放在构造函数中(而在forward中使用nn.functional来代替)
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。
在forward函数中可以使用任何Variable支持的函数,毕竟在整个pytorch构建的图中,是Variable在流动。还可以使用if,for,print,log等python语法.
编码输入文本
def forward(self, x, length=256):
# Encode input text
all_hidden, pooler = self.bert(x)
使用linear layer(线性)层进行预测
pooled_output = torch.mean(all_hidden, 1)
predict = self.linear(pooled_output)
return predict
实验结果
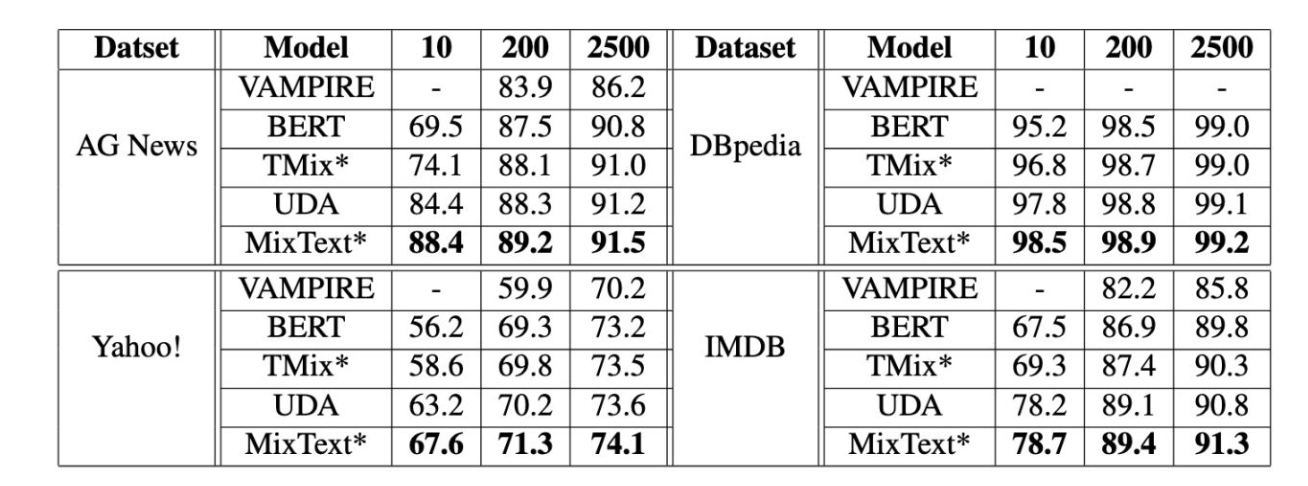

结果表明,Tmix的效果好于Bert,尤其当分类在10种的时候,MixText效果是最好的,因为MixText不仅合成了无标签数据,并且利用了有标签数据和无标签数据的隐含的关系,而且可以对无标签数据进行猜测标签,通过对数据增强和原始文件的权重平均。
无标签数据量对结果产生的影响,无标签数据越多,模型越准确。
学期学习总结
在本学期选择了该项目进行学习后,对自然语言处理方面有了更加深入的了解,从一开始读文章晦涩难懂,到最后查找资料逐步有了新的认识,逐渐学会了研究新项目,学习新知识的方法,现对相关领域的基础知识进行学习和弥补,再对某一部分深入了解的东西进行看网课,看其他的博客进行学习,并总结出其中的重点,主要代码以及其实现方式,可以自己手写进行练习。对任务中需要深入学习的模型和算法,进行每周的总结,虽然总结距离准确严谨还不够,但每次的总结都能有一些收获。与小组一起合作,互相讲自己负责的部分,最终对半监督文本分类的项目有了更进一步的了解。
Original: https://blog.csdn.net/m0_52073096/article/details/122153321
Author: IT_BD_Zhang
Title: 半监督文本分类学习代码展示及最终总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531077/
转载文章受原作者版权保护。转载请注明原作者出处!