

刚整理好的论文总结被我学弟一键ctrl+z搞没了,想暴揍他一顿~
熊孩子太皮了!!
还好这只是论文总结……
目录
论文题目:
Bootleg: Chasing the Tail with Self-Supervised Named Entity Disambiguation
代码链接:
Bootleg – Bootleg from HazyResearch
KBQA中使用该方法的论文连接是:
ReTraCk: A Flexible and Efficient Framework for Knowledge Base Question Answering
代码连接:
KC/papers/ReTraCk at main · microsoft/KC · GitHub
现存问题
命名实体消歧(NED)就是将文本提到的实体映射到知识库中的实体,现存挑战是如何消除在训练数据中很少出现的实体(称为tail entities)的歧义。人类会基于实体事实、关系和类型的知识使用推理模式区分不相似的实体。
解决方法
本文引入了BOOTLEG, 一个建立在消除歧义的推理模式上自我监督的NED系统。定义消歧的核心推理模式,创建一个学习步骤使得self-supervised model 学习模式,并展示如何使用弱监督提升训练数据的信号。用一个简单的Transformer架构编码推理模式,BOOTLEG在NED基线上实现了最好的性能。
具体的挑战
Tail Reasoning: 描述这些推理模式并了解它们对 tail 的覆盖情况。
Poor Tail Generalization: 相比一般的类型和关系特征,模型过度依赖有识别力的文本和实体特征。
Underutilized Data: 自监督模型会随着训练数据量的增加而提升。但标准的NED训练数据集中只用到一小部分数据(Wikipedia 数据集中大概有68% 的实体没有标记)。
具体的解决方法
Reasoning Patterns for Disambiguation:我们为NED提供了一套原则性的核心消歧模式——entity memorization, type consistency, KG relation, and type affordance——并在Wikipedia举例说明每个模式的片段中展示了这些模式。
Generalizing Learning to the Tail :数据集中有entity-, type-, and relation- tails,但在tail entities
上,有88%是non-tail types,有90%是non-tail relations。模型需要依赖用来消歧的特定实体以不同的方式平衡这些信号。 相比模型使用标准的正则化技术,本文提出了一个新的 2D regularization scheme连接entity , tail, relation信号并实现了在unseen entities上性能的提升。
Weak Labelling of Data: WikiPedia是高度结构化的,在一个实体的维基百科页面上,大多数句子都是通过代词或替代名称来指代该实体的——我们可以将我们的训练数据弱标记为标记提及。
注:本文将NED的 tail, torso, and head定义为在训练中分别出现少于10次、10到1000次和超过1000次的实体。
1. 四种推理模式
Entity Memorization:与特定实体相关的事实性知识。可以用标准的基于Transformer的语言模型学习该模式。
Type Consistency:文本中的某些文本信号表明集合中的实体类型可能是相似的。
KG Relations:当两个候选实体有一个已知的KG关系时,语篇信号表明这种关系可能存在于句子中。
Type Affffordance:与特定实体类型相关联的文本信号。
2. Bootleg 模型架构
信号编码
entity embedding: 每个实体用唯一的嵌入Ue 表示。
type embedding: 因为一个实体可能有多个类型,所以使用了additive attention。



本文设计了三个模块捕捉设计目标(通过建模文本信号获取推理模式):a phrase memorization module, a co-occurrence memorization module, and a knowledge graph connection module.
P hrase Memorization Module(Phrase2Ent)

Co-occurrence Memorization Module(Ent2Ent)
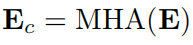
Knowledge Graph (KG) Connection Module(KG2Ent)
基于成对连接特征对实体进行解析。
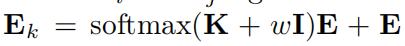
(其中K 表示图的邻接矩阵)
End-to-End
一层BOOTLEG的计算包括:



3. 提升Tail 泛化
Regularization
如果BOOTLEG 利用对流行实体的区别性特征和对稀有实体的一般特征的记忆,我们就可以改善tail 的性能。为了实现这一目标,我们设计了一种针对特定实体嵌入 u 的新正则化方案,该方案具有两个关键特性:它是二维的(相比一维,会加入 masking full embedding ),并且 受欢迎的实体被正则化的程度低于不太受欢迎的实体。
Weakly Supervised Data Labelling
对于弱标记,我们使用两种启发式方法:第一标记是代词,第二标记是实体的可替代名称。
4. 实验部分
本文证实:BOOTLEG
(1) 近似匹配或超过在三个标准的NED benchmarks 上的性能。
(2) 在 tail 上 超过了基于BERT的 NED baseline。
(3) Bootleg学到的推理模式可以通过使用它们进行下游任务的转移。
(4) Bootleg可以通过只学习实体嵌入的一小部分而不牺牲性能实现高效采样。
(5) 了解结构信号和正则化方案对改进 tail 性能的影响。
实验结果

BOOTLEG 错误分析:
① 粒度
② 数值
③ 多跳
④ 准确匹配

Original: https://blog.csdn.net/lft_happiness/article/details/123912209
Author: Toady 元气满满
Title: 实体消歧方法(1)__BOOTLEG
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530971/
转载文章受原作者版权保护。转载请注明原作者出处!