

文章目录
前言
LSTM的顶顶大名大家应该都听过,针对序列特征,LSTM相比于普通的RNN网络解决了两个棘手的问题,首先是通过门结构避免了梯度消失和梯度爆炸二点问题,然后通过增加一个cell状态捕捉长距离依赖。那么LSTM之后的改进工作呢,一个是简化版的GRU,另一个就是今天我们要讨论的Bi-LSTM网络。
一、命名实体识别-NER
在nlp种有一个任务叫做命名实体识别,简称NER。说的是给模型一句话,如何让模型将话里面的实体标注出来,比如说,人名是一种实体类型,马云则是一个具体的人名实体;地名也可以是一种实体类型,而天安门则是一个具体的地名实体。通常来说,NER会被视为一个多分类任务,一个字要么是某种实体的开头(Begin-label_i),要么是某种实体的中间部分(inside-label_i),要么啥也不是(outside)。
假设总共只有两种实体类型,分别是人名和地名,那么所有字一定属于以下类别:
begin-person, inside-person,begin-location,inside-location,outside
好了,了解了命名实体识别任务,那么现在给出一句话:
我喜欢杰伦
很显然杰伦是人名,将它标注:
我 喜 欢 杰 伦
O, O, O, B-person, I-person
二、LSTM
那么lstm是如何处理这句话的呢?我们以一层LSTM为例,注意这里虽然是多个神经元但是其实是一层,至于一层具体有几个神经元一般来说都是100以上,最好比语料中最长的句子要长。对每一句训练语料,将它们按照句子顺序输入LSTM的单元结构,当语料长度不够LSTM总长度时,后续没有字输入的LSTM单元会相当于输入一个空值。


对于 “我喜欢杰伦” 这句话,首先对第一个LSTM单元输入”我”,那么第一个LSTM单元会对”我”这个词生成的词向量进行一个多分类预测,并将部分有关于”我”这个词的信息告诉下一个LSTM单元。那么来到第二个LSTM单元,首先有输入”喜”字,加上还有上一个LSTM单元传递过来的信息,综合这两个信息再对”喜”字做一个多分类预测。那么整句话都是以上述流程完成的,很nice。
; 三、Bi-LSTM
说到Bi-LSTM是怎么来的,就得回到NER这个任务上来看看:
我们每次都是输入一整句话,对”喜”字进行预测的时候只考虑了上文”我”这个字的特征,但并没有考虑到下文”欢杰伦”的特征,因此造成了一定的特征丢失。
Bi-LSTM有个特别需要注意考虑的地方,因为我们做NER,每次都是对一整句进行预测,所以在任意时刻都可以随时获取上下文的信息。但是如果我们要做一个即时的NER识别,比如说人讲一个字模型就识别一个字,这个时候模型就看不见下文,故不能用Bi-LSTM来做。举个更加恰当的例子,比如说做天气预测,预测今天的天气,显然不能把明天的天气和后天的天气也拿来做特征,因为未来的天气我们还没观测到。但如果说对历史上的一个时间进行天气缺失值填补,是可以同时考虑前后的天气的,因为我们已经观测到了后向的天气特征。
总之,Bi-LSTM能不能用,取决于后向的特征在实际预测过程中我们是不是已经观测到了
下图是Bi-LSTM的一个预测过程,很显然,就是有双倍的LSTM结构,一半做向前的预测,一半做向后的预测,可以同时学习到向前与向后的特征。
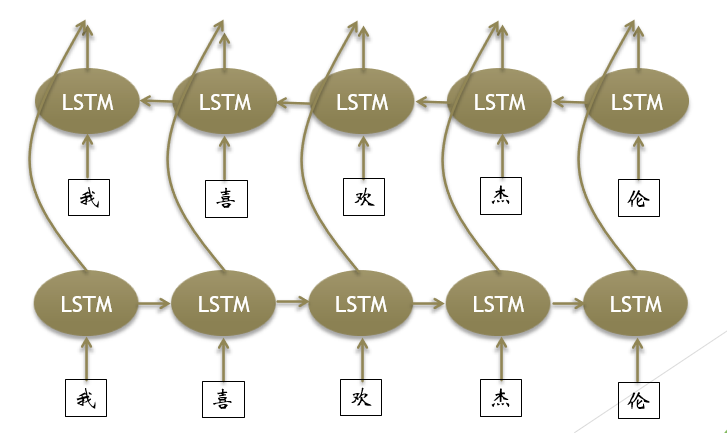
那么Bi-LSTM已经接近完美了吗?NO
问题出在什么地方,且听我一个形象的理解,羽毛球双打!
羽毛球是一个最近哎特别火的项目,实验室的人经常组队出动去体育馆,没场子甚至去市里面。虽然我只跟随着实验室友仔友女们去打过那么一两次,连拍子都是蹭的,但是我对羽毛球的理解,已经到了第五层了。
好了,言归正传,羽毛球双打时,站位很重要,因为场子很大,如果两个人挤在一起显然不好全面的防守,一般来说是一人站偏前场一个站偏后场。
假设:
模型的泛化能力比作两个羽毛球双打队员的组合在一起的综合能力。
前场的运动员代表学习了向前的特征。
后场的运动员代表学习了向后的特征。
那么Bi-LSTM是个什么角色呢,我来给各位分析一下,Bi-LSTM队有两个运动员:
①前场运动员A,从小到大和别人对打前场,三十年专注于前场接球,前场无敌
②后场运动员B,从小到大和别人对打后场,三十年专注于后场接球,后场无敌
下面是A和B的日常训练图:

可见,Bi-LSTM队由一个专注于30年前场和一个专注于30年后场的运动员组合队伍,这个队伍牛吗?当然牛啊,这30年也不是白练的啊。但是呢,是不是还差点什么?还真差了两点!
①A和B没有一起打过配合训练,即A和B配合不一定好。
②A的训练对手只站在前场和他打,他没接过后场的球。同理B没接过前场的球。
把这两点抽象到Bi-LSTM模型,那么这两个缺点分别是:
①向前的特征和向后的特征在训练的过程中互相看不见对方,只是最后做了一个拼接。
②向前的各个神经元在学习过程中其实也可以学习后向的特征,而它只学了向前的特征,所以它可能并不是一个最优的学习结果;向后的各个神经元同理。
关于第①点,其实很好理解了。至于第②点,其实意思和第①点很接近,而且虽然向前的神经元只学习了向前的特征,但是在预测过程中也只会收到来自向前的特征,抽象出来就是羽毛球比赛时,A永远只会接到前场打来的球,即对手的后场不会把球打给A让A接,这比赛是真男人羽毛球赛,前场只打给前场,后场只打给后场欸(指训练过程与预测过程特征提取流程是一致的)。虽然是向前的神经元只学习了向前的特征,在预测的过程中也不会收到向后的特征,但是俗话说得好嘛,知己知彼,百战百胜,我觉得学了向后的特征效果会更好。
总结
下一篇我将会介绍Bert模型,如何用transformer解决以上Bi-LSTM的两个问题!加油!
Original: https://blog.csdn.net/qq_40811682/article/details/122278063
Author: 我是狮子搏兔
Title: LSTM与BiLSTM的抽象理解——羽毛球双打
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530921/
转载文章受原作者版权保护。转载请注明原作者出处!