

摘要
MLM模型约定俗成按照15%的比例mask,主要基于两点:更多的mask比例对于学习更好的表征不能提供足够的上下文信息,较小的mask比例又增加模型训练的难度。诧异的是,我们研究发现对输入tokens 进行40%的mask要比15%的效果更好,而且80%的mask仍然能保留下游微调任务的大部分性能。我们从消融实验研究发现,增加mask比例,有两点显著的影响,1)更大比例的输入tokens被盖住了,降低了上下文的长度,增加了学习任务的困难程度;2)模型要做更多的预测,这对训练时有利的。我们研究发现,更大的模型,尤其是更高mask比例的模型,对于更困难的任务有更好的性能。我们同样将我们的研究发现应用在更复杂的mask策略上,如:span mask、PMI mask和严格的80%-10%-10%的bert mask,我们发现在更高的mask比例上用统一的[MASK]替换策略是比较有优势的。我们的研究成果有助于更好的理解MLM模型,且针对高效预训练模型指出了一条新路径。
1 引言
预训练模型已经应用在很多NLP场景,用海量文本数据训练的大的语言模型能够对语言进行丰富且多样的表征。对比在文本序列中预测下一个token的自回归模型,像bert这类MLM 通常基于保留的上下文去预测token的mask子集,由于双向特性,这类模型是更有效的。
这样限定了模型只能从15%的被mask掉的tokens中学习,这种策略反映了这样一种假设,即更多的mask,model无法学到很好的表征,且这种认识在bert研究者当中普遍存在。另外,15%的mask策略已经被视为一种更高效训练语言模型的约束。
在我们的工作中,我们有一个针对高效预训练的惊奇发现,相较于默认的15%,用40-50%的mask比例,在下游任务上可以取得更好的性能。表1列举了用15%, 40%和80%的mask的模型在下游任务性能的例子。用80%的比例,大多数上下文被盖住了,模型仍然可以学到不错的表征,对比15%的mask比例,保留了95%的性能。这个发现挑战了我们对于mask比例的直觉,且带来了一个问题,多大的mask比例对模型是有益的?
为了研究这个问题,我们提出对mask比例分解为两个因子:破坏率,即有多少token被mask掉了?预测率,即模型需要预测多少个token?在mlm中,破坏率、预测率和mask比例相同。然而,这两个因子有相反的影响,更高的预测率可以带来更多的预测信号,这对于模型训练是有益的;更高的破坏率,意味着更少的上下文信息,对于学习任务有更大的挑战性。为了单独研究这两个因子,我们设计了消融实验来区分预测率和破坏率。我们证实了,更高的预测率对模型是有益的,更高的破坏率对模型是不利的。更高的预测率带来的收益是否超过更高的破坏率所带来的损失决定了模型在更高的mask上是否有更好的性能。举例来说,我们发现更大的模型拥有更强的能力来处理更高的破坏率,表现出一个更有的mask比例。
受研究结果的启示,我们也考虑了将更大的mask比例用在较复杂的mask策略上,如:span mask、PMI mask。这些方法显示了在15% mask的比例上,用简单统一的mask策略表现较好。
然而,我们发现针对复杂的mask策略,在它们各自最优的mask比例上,统一的mask策略是更有优势的。我们关于预测率和破坏率的框架还验证了bert中基于原始和随机token的策略【80%-10%-10%】,我们发现没有这两个策略时,模型性能更好。
我们根据探讨较高的mask比例是如何在预训练中发挥作用的得出结论,在MLM中,采用较高的mask比例可以带来较好的性能,尤其是在受限资源条件下。从输入中移除token,将预测率和破坏率解耦,这两个方向的工作有加速模型训练的潜力。
总体上,我们的研究结论如下:
- 用更高的mask比例可以成功地训练MLM模型。例如,相比15%的比例,40%的mask策略在一个大的高效的训练模型上效果更佳。
- 我们提出了将mask比例解耦为预测率和破坏率,两个相对的因子分别影响模型的训练信号和任务难度。我们用这个框架发现了一个大的模型有一个更高的mask比例,仅仅用【MASK】策略也优于【80%-10%-10%】的策略。
- 我们验证了,对比其他高级的mask方法,用更高的统一的mask策略更有优势,尤其是在span mask和PMI mask上。
2 背景
今天,预训练模型是NLP任务的核心,通过一个语言模型目标函数,利用大量的未标记数据训练的transformer模型,它们的上下文表征结果已经广泛应用在下游微调任务中了。
预训练模型的目标函数主要有两类:1)自回归语言模型,通过上文预测下一个token的方式来训练模型:


这里,C是预训练语料,x是C中的样本序列。2)分解噪声自编码模型,这类模型通过还原被破坏的序列来训练。特别地,MLMs mask掉一部分tokens,通过保留的上下文来预测这些tokens:
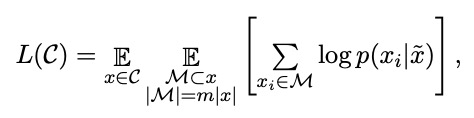
这里,m表示从原始句子x中mask掉的比例,通常15%,用打乱的文本
来预测被mask掉的token M。
不同的mask策略可以生成不同的mask样本M,从输入tokens中按照均匀分布随机采样;采样连续的文本片段;基于点互信息采样单词和片段等。这些高级采样策略妨碍了模型基于统一的mask策略探索浅层局部线索,表现出了高效的预训练效果。
MLMS可以双向编码,自回归语言模型仅能看到过去的,因此,MLMs已经被研究表明,在针对下游任务学习上下文表示时,效果更好。MLMS在计算成本上有显著的提升,因为它只需要计算15%的token,而自回归模型需要预测每一个token。本文,我们聚焦在MLMs上,研究mask比例对比提升预训练模型效率上的影响。
3 实验设计
在这个研究上,我们在最近的高效的预训练技巧上创建了大多数的实验:24h bert设计,达到bert-base的性能,使用这个模型可以有6倍的效率提升。因为我们这篇研究的一个主要目标是提高预训练模型的训练效率,我们相信我们的结合训练设计的研究结论可以带来一个总体的更好的方法。我们掌握了较好的mask比例和策略取决于训练设计,因此,我们也尝试采用roberta的训练技巧训练更长时间,同样发现我们的结论是站得住脚的。
Izsak等人通过设计一个更大的模型,更大的学习速率,更大的batch size,更短的文本长度,更少的训练轮数,使得模型训练更快。对比24hbert,我们做了一些简单的改动:1)我们采取了roberta的tokenzer,它在之前的实验中表现不错。2)替代bert 80%-10%-10%的策略,我们采取全部[MASK]的策略,在5.3章节,我们详细讨论不同的mask策略的影响。我们也取消了NSP任务,但这种被发现是会降低模型性能的。我们还展示了详细的预训练的超参数,作为对比其他预训练模型的设计技巧。
我们在GLUE和SQuAD下游任务上评估模型性能,我们用了三个随机种子和网格搜索来微调模型,以获得更可靠的结果。
4 mask比例应该超过15%

我们惊奇地发现,高达50%的mask比例甚至可以取得更好的结果,对比15%的默认mask。40%的mask总体上可以获得最好的下游任务性能,尽管不同的任务,最优的mask比例有差异。我们的研究结果表明,对于预训练语言模型,15%的mask比例限制是不必要的。对于用高效的预训练技巧设计的大模型来说,较好的mask比例为40%。为了进一步对比15%和40%的mask差异,我们列出了GLUE上的测试结果。用图说明了不同的训练步数,下游任务时如何变化的。

表格2进一步验证了40%的mask比15%的有显著的提升,在SQuAD任务上,大约有2个点的提升。我们也可以看出,在整个训练过程中,40%的mask始终优于15%的mask。
为了进一步理解,我们画出了不同mask比例的例子,还有验证集和下游任务的性能。我们可以看到,超过40%的mask比例会导致较大的上下文破坏程度,即便是对人来说,也难以重构。当mask比例为80%时,大部分上下文信息丢失了,上下文困惑度极其高,超过1000。然而,40%的mask要优于15%。80%的比例,对比15%的mask比例,仍然保留了95%的性能。
这改变了我们对于MLM模型是怎么工作的以及训练一个好的预训练模型到底需要学习context的理解。我们假设,越高的mask比例越不可能重构句子,但模型仍然可以学到不错的语义表征。
5 理解 mask 比例
在这个章节,我们通过两个视角来理解mask rate是如何影响MLM的训练过程的:任务难度和优化。在这个框架下,我们进一步探讨了mask rate、model size、不同破坏策略之间的关系,以及它们对于下游任务的影响。
5.1 当做破坏率和预测率的mask
我们从两个预训练问题上区分mask rate:破坏率
和准确率,是从输入序列中丢掉的tokens比例,通常用【MASK】替代。是需要模型预测的tokens的比例,计算每一个token的交叉熵损失。
在公式1中,
控制多少内容被破坏了,控制多少内容需要预测,这两个比例都与mask rate有关,即:,但是他们对表征质量有不同的影响。
控制任务难度。在预训练过程中,MLM尝试在被破坏掉的文本中学习一个条件概率分布
.如果token被破坏率较大的话,那只能用较少的上下文tokens来预测被mask的token,使得预测变难,且有更大的不确定性。
影响模型优化。预测更多的tokens意味着模型可以学到更多的训练信号,所以较高的预测率能提升模型的性能。从另一个角度来看,在被mask的token上的每一个次预测都会带来梯度损失,损失的梯度的平均值被用来优化模型的权重。对更多预测token的平均和增加batch-size有相似的作用,都对预训练模型有利。
实验。在MLM中预训练中,
始终存在。为了分别研究,对下游任务的影响,我们设计了简单的消融实验来解耦和:
-
如果
<,我们mask掉的token,只在上做预测,这很容易实现,且没有额外的损失。例如,with mcorr = 40% and mpred = 20%, we mask 40% and only predict on a subset of 20% tokens.
-
如果
> ,我们重复每个序列次,且在不同的序列上对token的差集进行mask。例如,with mcorr = 20% and mpred = 40%, for each sentence, we do twice 20% masking on different tokens and predict on all the masked tokens—this leads to a 20% corruption but a 40% prediction on each sequence。注意,消融实验我们使用次,因为对每个序列,我们需要多次传递,实践中效率并不高。
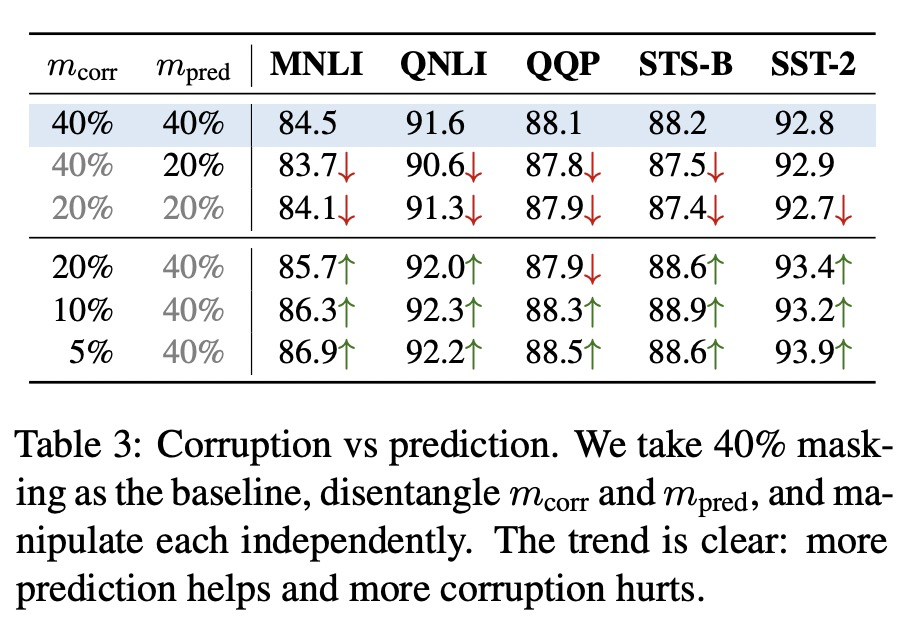
表3展示了消融实验的结果,我们可以看到:1)固定40%的
,将从40%降低到20%会导致下游任务效果的整体降低,表明越高的预测率可以带来更好的性能;2) 固定40%的,将从40%降低到20%会导致下游任务效果的整体提升,表明越低的破坏率更易于模型的学习;尽管我们发现,将从10%降低到5%所带来性能提升小于从40%降低到20%,表明降低仅仅有一个微不足道的收益。3)对比20%和40%的结果,我们可以看到增加预测数量所带来的收益提升超过破坏所带来的收益降低,可以带来更好的性能。
消融实验表明,当我们调整mask比例时,预测率和破坏率同步被调整,这可以带来正反面的影响。最终结果由哪一方有更大的权重决定。如果提高预测率所带来的收益可以超过增加破坏率所带来的损害,那模型可以从更高的mask rate上获益。许多因素可以影响这个平衡,接下来,我们研究模型尺寸。
5.2 大模型倾向于更高的mask比例
鉴于任务的困难程度,我们假设较大的模型可以从更好的mask比例中获益。的确,我们发现更大的模型可以支配更高的mask比例。图3说明了在large(354M paras),base(124M paras),medium(51M paras)模型上,mask比例的影响。我们发现在高效的预训练策略上,平均来看,
large模型在40%处,为较优的mask比例,base按medium模型大概为20%。清洗地表明,较大的模型有较高的mask比例。正如5.1中所述的一样,如果由增加破坏率所带来的损害小于由更高预测率所带来的收益,那更高的mask比例对模型是有益的。我们假设更大的模型有能力更好地处理困难任务,且受较高破坏率的影响较小,因此这些模型有一个更高的较优mask比例。
这正好契合了我们高效训练模型的目标,LI等研究表明用较少的步数训练一个大模型,比用更长时间训练一个小模型更有效,因为计算成本可以用模型快速收敛来抵消。

5.3 揭秘80-10-10法则
Devlin等人提出10%的[MASK]用原词替换【保持不变】,10%的[MASK]的用随机词替换。从那之后,80-10-10法则被广泛应用在几乎所有的预训练模型中。这个动机是由于遮盖住token之后,预训练任务和下游任务会有一些不匹配,用原词或随机词替换后,可以缓解两者之间的gap。基于这个考虑,遮盖住更多的tokens(如40%)会进一步增加这个差异,然而我们却得到了更好的下游任务。这就引出了一个问题,我们是否还应该坚持80-10-10法则?首先,我们回顾80-10-10法则下的两种替换策略,并将其和我们的预测率和破坏率的研究框剪联系起来。
相同token预测。
预测相同token很容易,模型可以简单地从输入复制到输出。相同token的损失非常小,这个只是被当做目标函数的一个辅助正则项,这确保了token信息可以从emdedding层传播到最后一层。因此,相同token预测既不能被算作破坏率,也不能被算作准确率,它没有破坏输入,对学习的贡献也微乎其微。
随机token破坏。随机字符替换即增加了破坏率,也增加了预测率,因为输入被打乱了,预测任务也不可小觑。事实上,我们发现随机替换的token的损失函数略高于用[mask]替换,因为1)模型需要判断所有来自输入端的token信息是否是破坏过的,2)对于输入端token变化较大的,模型需要准确预测。
消融实验。我们使用40%的mask比例,且仅用[MASK]替换作为baseline,除此之外,又增加了三组模型。
- +5% same:我们mask了40%,但是预测45%。像上面说得,增加一些相同的token,不改变准确率和破坏率。
2.”w/ 5% random”:mask了35%,随机替换了另外的5%,总共预测40%。
3.”80-10-10″:bert策略,注意在这个模型中,由于相同10%的相同token,破坏率和预测率均等于36%。

我们结果在表4.我们可以发现,相同和随机mask策略都会退化模型在下游任务上的性能。80-10-10策略比统一用[MASK]效果还差。研究结果表明,在微调这种范式中,模型可以快速学习完整的,未被破坏的句子,不管使用什么破坏策略。就我们的结果而言,在MLM中,我们建议只用【MASK】策略。
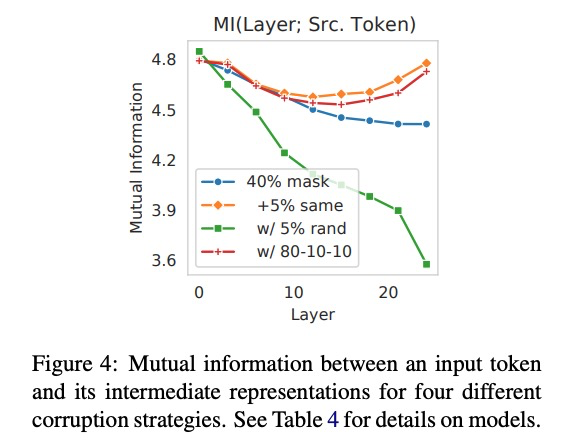
信息流。为了可视化破坏策略的影响,我们借鉴了Voita的分析思路:计算输入token和中间态表征的互信息。图4说明了每个模型对比从上下文学习在初始化阶段从源token所丢失的信息。使用相同token策略,在预训练模型中的最后几层会带来一个重构阶段,由于源token的信息已经蕴含在上下文中。然而,第二阶段用相同token做预测的消融实验未呈现出来,【MASK】只用来传播上下文特征,不参与重构阶段。一个结果是:用相同的token策略时,输入token的信息很容易被抽取出来。
6 在更好的mask比例上,统一的mask更有优势
Devlin和Liu用均匀采样选择token进行采样。后续的工作表明使用更复杂的mask策略,如span masking 和PMI,在下游任务上效果更优。使用高级mask的争论在于统一的mask策略可以根据局部优化最小化目标函数。一个例子,给出[MASK] kong,模型很容易用上下文推断为[Hong],之前的研究用固定的15%的mask策略,这带出了这个问题:之前的结论是否仍然站得住脚。
为了理解mask策略和mask比例之间的内在联系,我们在不同的mask比例下尝试了不同的mask策略,发现在最优mask比例时,用统一的mask策略对比其他复杂的mask策略表现更好或持平。
图5说明了mask比例从15%到40%变化时,统一mask、片段mask和PMI mask的结果。我们可以看出:1)所有的mask策略,最优的mask比例都高于15%;2)片段mask 和PMI mask的最优mask比例低于统一mask;3)当所有mask策略都取得最优mask比例时,统一mask策略对比其他mask策略,效果更好或相当。

为了理解mask策略和mask比例之间的关系,我们认为,更高的统一的mask策略潜在增加了高度相似token被mask掉的机会,这会稍微减少被mask的token数量,强制增加模型的鲁棒性。我们注意到,对于统一的mask策略,使用更高的mask比例,出乎意料地超出了PMI mask的性能。通过在语料上采样mask,我们计算了概率,在图6,发现mask比例从15%增加到40%时,有一个8倍的提升。同样,更高的mask比例也使得mask片段更长。这个例子说明了,对比使用复杂的mask策略,增加mask比例同样可以提升模型的性能。

7 讨论和未来工作
其他语言的mask比例
处理上下文和mask分离
解耦破坏率和准确率
8 结论
这篇论文中,我们对MLMs中的mask比例进行了全面的研究,发现在下游任务上,40%的比例优于15%。通过解耦为破坏率和预测率,我们对mask比例有了更深入的理解,较大的模型可以从更大的mask比例中获益。我们也解释了80-10-10的法则并不是必须的,在更大的mask比例上,统一的mask策略对比复杂的mask策略,如span mask会更有优势。基于这个发现,我们讨论了未来使用更高的mask比例高效训练模型的方向。
9 致谢
感谢普林斯顿大学NLP组成员的讨论和反馈。该研究获得了普林斯顿研究生奖学金的支持,同时也得到了谷歌科研基金的支持。
Original: https://blog.csdn.net/qq_32275289/article/details/123063204
Author: NLP_wendi
Title: MLM模型中,是否应该按15%的比例mask?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530917/
转载文章受原作者版权保护。转载请注明原作者出处!