

文章目录
- 1、语言模型
* - 1.1、语言模型的概念
- 1.2、语言模型的计算
- 1.3、马尔科夫假设
- 1.4、语言模型评价指标:困惑度(Perplexity)
- 2、文本预处理
* - 2.1、读取数据集
- 2.2、词元化
- 2.3、词表
- 2.4、整合所有的功能
- 3、读取时序数据
* - 3.1、随机采样
- 3.2、相邻采样
- 3.3、操作整合
- 4、循环神经网络
* - 4.1、概念
- 4.2、通过时间反向传播
– - 4.3、应用:基于字符级循环神经网络的语言模型
- 4.4、循环神经网络从零实现
– - 4.5、循环神经网络简洁实现
–
循环神经网络(recurrent neural network, RNN)常用语处理序列数据,如一段文字或者声音、购物或观影的顺序,甚至是图像中的一行或一列像素。因此,循环神经网络有着极为广泛的实际应用,如语言模型、文本分类、机器翻译、语音识别、图像分析和推荐系统等。
如果说卷积神经网络可以有效地处理空间信息,那么循环神经网络则可以更好地处理序列信息。循环神经网络通过引入状态变量存储的信息和当前的输入,从而可以确定当前的输入。
许多使用循环神经网络的例子都是基于文本数据的,因此首先介绍语言模型,然后介绍什么是序列模型以及怎么样对文本数据进行预处理,随后介绍循环神经网络RNN,记忆LSTM,GRU等模型。
1、语言模型
1.1、语言模型的概念
语言模型(language model)是自然语言处理的重要技术。自然语言处理中最常见的数据就是文本数据。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为T T T的文本中的词依次为w 1 , w 2 , ⋯ , w T w_1,w_2,\cdots ,w_T w 1 ,w 2 ,⋯,w T ,那么在离散的时间序列中,w t ( 1 ≤ t ≤ T ) w_t(1\le t \le T)w t (1 ≤t ≤T )可以看作在时间步t t t的输出或者标签。给定一个长度为T T T的序列w 1 , w 2 , ⋯ , w T w_1,w_2,\cdots ,w_T w 1 ,w 2 ,⋯,w T ,语言模型将计算该序列的概率:
P ( w 1 , w 2 , ⋯ , w T ) P(w_1,w_2,\cdots ,w_T)P (w 1 ,w 2 ,⋯,w T )
简单来说,语言模型的概念为:语言模型计算一个句子是句子的概率的模型。(文本序列就是句子喽)
例如下面三句话以及它们是句子的概率分别为
- “博主长得很帅!”:0.8
- “博主长得很一般!”:0.01
- “长博主一般得!”:0.000001
第一句话是句子的概率为0.8,因为这句话即合乎语义又合乎语法,因此这句话是句子的概率很高;第二句话为句子的概率为0.01,这是因为虽然这个句子符合语法但是却不合乎语义,因为构建的语言模型中,”博主”和”一般”出现在一起的概率就很小;而第三句话读都读不同,显然不符合语法,因此是句子的概率极低。
语言模型有很多的用处,它可以用于提升语音识别性能或输入法准确度等。例如,当我们输入”zi ran yu yan chu li”,它所对应的中文可能是”自然语言处理”、”子然语言出力”、”紫然玉言储例”,经过语言模型的判断这三个句子的概率为0.9.,001,0.0001,我们就可以得到是句子概率最高得一句话”自然语言处理”,这也是我们正向得到的。
1.2、语言模型的计算
统计语言模型通过概率来刻画语言模型,假设序列w 1 , w 2 , ⋯ , w T w_1,w_2,\cdots ,w_T w 1 ,w 2 ,⋯,w T 中的每个词是依次生成的,则有:
P ( s ) = P ( w 1 , w 2 , ⋯ , w T ) = ∏ t = 1 T P ( w t ∣ w 1 , ⋯ , w t − 1 ) P(s)=P(w_1,w_2,\cdots ,w_T) = \prod_{t=1}^{T}P(w_t|w_1, \cdots ,w_{t-1})P (s )=P (w 1 ,w 2 ,⋯,w T )=t =1 ∏T P (w t ∣w 1 ,⋯,w t −1 )
例如,一段含有4个词的文本序列的概率为:
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 1 , w 2 , w 3 ) P(w_1,w_2,w_3,w_4)=P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)P(w_4|w_1,w_2,w_3)P (w 1 ,w 2 ,w 3 ,w 4 )=P (w 1 )P (w 2 ∣w 1 )P (w 3 ∣w 1 ,w 2 )P (w 4 ∣w 1 ,w 2 ,w 3 )
为计算语言模型,我们需要计算词的概率,以及一个词在给定前几个词的情况下的条件概率,即语言模型的参数。
词的概率可以通过该词在训练数据集中的相对词频来计算,用语料的频率代替概率(频率学派),即计算词在训练数据集中的出现的次数与训练数据集的总词数之比:
P ( w i ) = c o u n t ( w i ) N P(w_i)=\frac{count(w_i)}{N}P (w i )=N c o u n t (w i )
一个词在给定前几个词的情况下的条件概率也可以通过训练数据集中的相对词频计算,其计算公式为:
P ( w i ∣ w i − 1 ) = P ( w i − 1 , w i ) P ( w i − 1 ) = c o u n t ( w i − 1 , w i ) / N c o u n t ( w i − 1 ) / N = c o u n t ( w i − 1 , w i ) c o u n t ( w i − 1 ) P(w_i|w_{i-1})=\frac{P(w_{i-1},w_i)}{P(w_{i-1})}=\frac{count(w_{i-1},w_i)/N}{count(w_{i-1})/N}=\frac{count(w_{i-1},w_i)}{count(w_{i-1})}P (w i ∣w i −1 )=P (w i −1 )P (w i −1 ,w i )=c o u n t (w i −1 )/N c o u n t (w i −1 ,w i )/N =c o u n t (w i −1 )c o u n t (w i −1 ,w i )
但是只是这样构建语言模型的话,还存在一些问题。例如在下面的例子中,对于一句话s e n t e n c e = { w 1 , w 2 , ⋯ , w n } sentence={w_1,w_2,\cdots,w_n}s e n t e n c e ={w 1 ,w 2 ,⋯,w n }:
当这句话为”张三很帅”的时候,使用语言模型计算它为句子的概率为:P ( 张 三 很 帅 ) = P ( 张 三 ) ∗ P ( 很 ∣ 张 三 ) ∗ P ( 帅 ∣ 张 三 , 很 ) P(张三\; 很\; 帅)=P(张三)P(很|张三)P(帅|张三,很)P (张三很帅)=P (张三)∗P (很∣张三)∗P (帅∣张三,很),由于张三是一个常见的名字,因此在预料中很容易出现,因此通过语言模型可以计算出它的一个概率为P 1 P_1 P 1 。
但对于”张得帅很帅”这句话,它的概率为:P ( 张 得 帅 很 帅 ) = P ( 张 得 帅 ) ∗ P ( 很 ∣ 张 得 帅 ) ∗ P ( 帅 ∣ 张 得 帅 , 很 ) P(张得帅\; 很\; 帅)=P(张得帅)P(很|张得帅)P(帅|张得帅,很)P (张得帅很帅)=P (张得帅)∗P (很∣张得帅)∗P (帅∣张得帅,很),”张得帅”也可能是一个人名,因此”张得帅很帅”也是一句正确的话,但是”张得帅”在语料库中可能就没有出现过,因此P ( 张 得 帅 ) P(张得帅)P (张得帅)的概率为0,那么最终的结果也为0。这显然有些不合理,因为”张得帅很帅”明显是一句话。”张得帅很帅”这句话概率为0的原因是因为有一些词在语料库中没有出现过。
而对于”张三很漂亮”这句话,它的概率为:P ( 张 三 很 漂 亮 ) = P ( 张 三 ) ∗ P ( 很 ∣ 张 三 ) ∗ P ( 漂 亮 ∣ 张 三 , 很 ) P(张三\; 很\; 漂亮)=P(张三)P(很|张三)P(漂亮|张三,很)P (张三很漂亮)=P (张三)∗P (很∣张三)∗P (漂亮∣张三,很),其中”张三”可能是个男生,”张三跟漂亮”在语料库中出现的概率为0,因此总的概率为0。但是这句话中的每一个词的概率都不为0,并且P ( 张 三 ) P(张三)P (张三),P ( 很 ∣ 张 三 ) P(很|张三)P (很∣张三)也都不为0,但是再加一个”漂亮”概率就为0了,这是因为这一句话太长了。
由上面例子可以看出,当一个句子明明就是句子的时候,它为句子的概率可能为0,怎么处理这种情况那?可以使用 统计语言模型中的平滑操作。
统计语言模型中的平滑操作
有一些词或者词组在语料中没有出现过,但是这不能代表它不可能存在。平滑操作就是给那些没有出现过的词或者词组也给一个比较小的概率。平滑操作有很多种。
拉普拉斯平滑(Laplace Smoothing)也称为加1平滑:每个词在原来出现次数的基础上加1,下面是经过拉普拉斯平滑后的计算公式:
P ( w ) = c o u n t ( w ) N ⇒ P ( w ) = c o u n t ( w ) + 1 N + V P(w) = \frac{count(w)}{N} \Rightarrow P(w) = \frac{count(w)+1}{N+V}P (w )=N c o u n t (w )⇒P (w )=N +V c o u n t (w )+1
其中V,加1的词的个数,下面来看一个简单的例子,有三个词A、B、C,每个词的个数分别为0、990、10,在未经过平滑时,每个词的概率为:
A : 0 P ( A ) = 0 / 1000 = 0 B : 990 P ( B ) = 990 / 1000 = 0.99 C : 10 P ( C ) = 10 / 1000 = 0.01 A:0 \; P(A)=0/1000=0 \ B:990 \; P(B)=990/1000=0.99 \ C:10 \:P(C)=10/1000=0.01 A :0 P (A )=0 /1 0 0 0 =0 B :9 9 0 P (B )=9 9 0 /1 0 0 0 =0 .9 9 C :1 0 P (C )=1 0 /1 0 0 0 =0 .0 1
经过平滑之后,每个词的概率为:
A : 1 P ( A ) = 1 / 1003 = 0.001 B : 991 P ( B ) = 991 / 1003 = 0.988 C : 11 P ( C ) = 11 / 1003 = 0.011 A:1 \; P(A)=1/1003=0.001 \ B:991 \; P(B)=991/1003=0.988 \ C:11 \:P(C)=11/1003=0.011 A :1 P (A )=1 /1 0 0 3 =0 .0 0 1 B :9 9 1 P (B )=9 9 1 /1 0 0 3 =0 .9 8 8 C :1 1 P (C )=1 1 /1 0 0 3 =0 .0 1 1
可见之前概率较大的词的概率变小了,概率较小的次的概率变大了。但是平滑操作还存在参数空间过大和数据稀疏严重的问题(空间参数过大导致了数据系数严重的问题),因此可以使用马尔科夫假设来解决此问题。
1.3、马尔科夫假设
当序列长度增加时,计算和存储多个词共同出现的概率的复杂程度会呈指数级增加。因此可以通过马尔科夫假设解决该问题,马尔科夫假设是指下一个词的出现仅依赖于前面的n个词(因为一个词与它间隔很长的词之间的关系可能就不是很大了),即k阶马尔科夫链。如果基于n-1阶马尔科夫链,就可以将语言模型改写为:
P ( s ) = P ( w 1 , w 2 , ⋯ , w n ) ≈ ∏ t = 1 T P ( w t ∣ w t − ( n − 1 ) , ⋯ , w t − 1 ) P(s)=P(w_1,w_2,\cdots ,w_n) \approx \prod_{t=1}^{T}P(w_t|w_{t-(n-1)}, \cdots ,w_{t-1})P (s )=P (w 1 ,w 2 ,⋯,w n )≈t =1 ∏T P (w t ∣w t −(n −1 ),⋯,w t −1 )
以上也叫作n元语法。它是基于n-1阶马尔科夫链的概率语言模型。当n分别为1、2、3和k时,我们将其分别称作一元语法(unigram)、二元语法(bigram)、三元语法(trigram)和k元语法(k-gram)。长度为T的序列w 1 , w 2 , ⋯ , w T w_1,w_2,\cdots ,w_T w 1 ,w 2 ,⋯,w T 在一元语法、二元语法、三元语法和k元语法中的概率分别是:
u n i g r a m : P ( s ) = P ( w 1 ) P ( w 2 ) P ( w 3 ) ⋯ P ( w T ) b i g r a m : P ( s ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 2 ) ⋯ P ( w T ∣ w T − 1 ) t r i g r a m : P ( s ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 w 2 ) ⋯ P ( w T ∣ w T − 2 w T − 1 ) k − g r a m : P ( s ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 w 2 ) ⋯ P ( w T ∣ w T − k + 1 w T − 1 ) unigram:P(s)=P(w_1)P(w_2)P(w_3) \cdots P(w_T)\ bigram:P(s)=P(w_1)P(w_2|w_1)P(w_3|w_2) \cdots P(w_T|w_{T-1})\ trigram:P(s)=P(w_1)P(w_2|w_1)P(w_3|w_1w_2) \cdots P(w_T|w_{T-2}w_{T-1})\ k-gram:P(s)=P(w_1)P(w_2|w_1)P(w_3|w_1w_2) \cdots P(w_T|w_{T-k+1}w_{T-1})\u n i g r a m :P (s )=P (w 1 )P (w 2 )P (w 3 )⋯P (w T )b i g r a m :P (s )=P (w 1 )P (w 2 ∣w 1 )P (w 3 ∣w 2 )⋯P (w T ∣w T −1 )t r i g r a m :P (s )=P (w 1 )P (w 2 ∣w 1 )P (w 3 ∣w 1 w 2 )⋯P (w T ∣w T −2 w T −1 )k −g r a m :P (s )=P (w 1 )P (w 2 ∣w 1 )P (w 3 ∣w 1 w 2 )⋯P (w T ∣w T −k +1 w T −1 )
当n较小时,n元语法往往并不准确。例如,在一元语法中,由3个词组成的句子”你走先”和”你先走”的概率是一样的。然而,当n较大时,n元语法需要计算并存储大量的词频和多词相邻词频。
下面以”我 明天 下午 打 网球”,看一下原始语言模型和经过马尔科夫优化后的语言模型应该怎么计算:
P ( 我 , 明 天 , 下 午 , 打 , 网 球 ) = P ( 我 ) P ( 明 天 ∣ 我 ) P ( 下 午 ∣ 我 , 明 天 ) P ( 打 ∣ 我 , 明 天 , 下 午 ) P ( 网 球 ∣ 我 , 明 天 , 下 午 , 打 ) = P ( 我 ) P ( 明 天 ) P ( 下 午 ) P ( 打 ) P ( 网 球 ) u n i g r a m = P ( 我 ) P ( 明 天 ∣ 我 ) P ( 下 午 ∣ 明 天 ) P ( 打 ∣ 下 午 ) P ( 网 球 ∣ 打 ) b i g r a m = P ( 我 ) P ( 明 天 ∣ 我 ) P ( 下 午 ∣ 我 , 明 天 ) P ( 打 ∣ 明 天 , 下 午 ) P ( 网 球 ∣ 下 午 , 打 ) t r i g r a m P(我,明天,下午,打,网球)\ =P(我)P(明天|我)P(下午|我,明天)P(打|我,明天,下午)P(网球|我,明天,下午,打)\ =P(我)P(明天)P(下午)P(打)P(网球)\; \; \;unigram\ =P(我)P(明天|我)P(下午|明天)P(打|下午)P(网球|打)\; \; \;bigram\ =P(我)P(明天|我)P(下午|我,明天)P(打|明天,下午)P(网球|下午,打)\; \; \;trigram P (我,明天,下午,打,网球)=P (我)P (明天∣我)P (下午∣我,明天)P (打∣我,明天,下午)P (网球∣我,明天,下午,打)=P (我)P (明天)P (下午)P (打)P (网球)u n i g r a m =P (我)P (明天∣我)P (下午∣明天)P (打∣下午)P (网球∣打)b i g r a m =P (我)P (明天∣我)P (下午∣我,明天)P (打∣明天,下午)P (网球∣下午,打)t r i g r a m
1.4、语言模型评价指标:困惑度(Perplexity)
语言模型在实质上是一个多分类问题,语言模型计算一个句子是句子的概率。对于一个句子s,其中有w 1 , w 2 , ⋯ , w n w_1,w_2,\cdots ,w_n w 1 ,w 2 ,⋯,w n 共n个词,它是句子的概率为:
P ( s ) = P ( w 1 , w 2 , ⋯ , w n ) = P ( w 1 ) P ( w 2 ∣ w 1 ) ⋯ P ( w n ∣ w 1 , w 2 ⋯ w n − 1 ) P(s)=P(w_1,w_2, \cdots ,w_n)=P(w_1)P(w_2|w_1) \cdots P(w_n|w_1,w_2 \cdots w_{n-1})P (s )=P (w 1 ,w 2 ,⋯,w n )=P (w 1 )P (w 2 ∣w 1 )⋯P (w n ∣w 1 ,w 2 ⋯w n −1 )
下面就需要计算出每一项的概率,就可以计算出句子s为句子的概率了,那么每一项有怎么计算哪?对于第一项P ( w 1 ) P(w_1)P (w 1 ),计算为对于所有的词w 1 , w 2 , ⋯ w T w_1,w_2,\cdots w_T w 1 ,w 2 ,⋯w T ,w 1 w_1 w 1 出现的概率分布,可以理解为输入为None,标签为w 1 w_1 w 1 ,词表大小的一个多分类问题;对于第二项P ( w 2 ∣ w 1 ) P(w_2|w_1)P (w 2 ∣w 1 )为当输入为w 1 w_1 w 1 ,标签为w 2 w_2 w 2 ;其他项可以依次类推。综上所述,每一项都可以理解为是一个词表大小的多分类问题。
下图为一个基于前馈神经网络的语言模型,它使用前几个词的词向量,并把它们连接在一起,后面接一个隐藏层,然后是一个分类层,分类层就是一个词表大小的分类器。


语言模型的评价指标,就可以使用困惑度来表示,一个句子的困惑度为一个句子的概率开负的n分之一次方,表示为:
P P ( s ) = P ( w 1 , w 2 , ⋯ w n ) − 1 n = 1 P ( w 1 , w 2 , ⋯ , w n ) n PP(s) = P(w_1,w_2,\cdots w_n)^{- \frac{1}{n}}=\sqrt[n]{\frac{1}{P(w_1,w_2,\cdots ,w_n)}}P P (s )=P (w 1 ,w 2 ,⋯w n )−n 1 =n P (w 1 ,w 2 ,⋯,w n )1
句子概率越大,语言模型越好,困惑度越小。
; 2、文本预处理
序列数据存在许多种形式,文本是最常见例子之一。例如,一篇文章可以简单地看作是一串单词序列,甚至是一串字符序列。下面为解析文本的常见处理步骤,这些步骤包括:
- 将文本作为字符串加载到内存中。
- 将字符串查分为词元(如单词和字符)。
- 建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
导入所使用的包:
import collections
import re
from d2l import torch as d2l
2.1、读取数据集
首先,加载H.G.Well的The Time Machine中的文本,这是一个小的语料库,只有30000多个单词。The Time Machine是一本科幻小说,下图为这本小说的前几行的内容,全部的文本有三千多行。

下面的函数将The Time Machine文本数据集读取到由多条文本行组成的列表中,其中每条文本行都是一个字符串。然后忽略了文本中的标点符号和字母大写。
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
with open(d2l.download('time_machine'),'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+',' ',line).strip().lower() for line in lines]
lines = read_time_machine()
print(f'#文本总行数:{len(lines)}')
print(lines[0])
print(lines[10])
#文本总行数:3221
the time machine by h g wells
twinkled and his usually pale face was flushed and animated the
2.2、词元化
下面将文本序列拆分为词元列表,词元是文本的基本单位。下面的 tokenize函数将文本行列表作输入,列表中的每个元素是一个文本序列。函数返回一个由词元列表组成的列表,其中每个词元都是一个字符串。(就是将一句话按照单词或者字母进行拆)
def tokenize(lines, token = 'word'):
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:'+token)
tokens = tokenize(lines)
for i in range(11):
print(tokens[i])
['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
[]
[]
[]
[]
['i']
[]
[]
['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him']
['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
2.3、词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。下面,构建一个字典,通常也叫作词表,用来将字符串类型的词元映射到从0开始的数字索引中。
首先将训练集中所有的文档合并在一起,对它们的唯一词元进行统计,得到的统计结果称之为语料(corpus)。然后根据每个唯一词元的出现频率,为其分配一个数字索引。为降低复杂性,移除很少出现的词元。将语料库中不存在或者已删除的词元映射为一个特殊的未知词元”⟨ u n k ⟩ \langle unk \rangle ⟨u n k ⟩”。增加一个列表,用于保存那些被保留的词元,例如:填充词元(“⟨ p a d ⟩ \langle pad \rangle ⟨p a d ⟩”);序列开始词元(“⟨ b o s ⟩ \langle bos \rangle ⟨b o s ⟩”);序列结束词元(“⟨ e o s ⟩ \langle eos \rangle ⟨e o s ⟩”)。
下面的函数将统计词元的频率,即某个词元在训练集中出现的次数,最后以一个列表的形式返回。
def count_corpus(tokens):
if len(tokens) == 0 or isinstance(tokens[0], list):
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
corpus_num=count_corpus(tokens)
print(corpus_num['the'])
2261
下面定义的 Vocab类,用于构建词表,并支持查询词表长度、通过索引查询词元、词元查询索引的功能。
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
self.idx_to_token = [''] + reserved_tokens
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
下面使用The Time Machine数据集作为语料库来构建词表,然后打印前几个高频词元及其索引。
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])
[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
</unk>
下面就可以将一条文本行转换成一个数字索引列表了。
for i in [0,10]:
print('文本',tokens[i])
print('索引',vocab[tokens[i]])
文本 ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
索引 [1, 19, 50, 40, 2183, 2184, 400]
文本 ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
索引 [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
2.4、整合所有的功能
下面将所有的功能打包到 load_corpus_time_machine含住中,该函数返回corpus(词元索引列表)和vocab(时光机器语料库的词表)。这列做了一些更改
- 为了简化后面章节中的训练,我们使用字符(而不是单词)实现文本词元化;
- The Time Machine数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
def load_corpus_time_machine(max_tokens = -1):
lines = read_time_machine()
tokens = tokenize(lines,'char')
vocab = Vocab(tokens)
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus,vocab
corpus, vocab = load_corpus_time_machine()
print(len(corpus), len(vocab))
print(list(vocab.token_to_idx.items())[:10])
170580 28
[('<unk>', 0), (' ', 1), ('e', 2), ('t', 3), ('a', 4), ('i', 5), ('n', 6), ('o', 7), ('s', 8), ('h', 9)]
</unk>
3、读取时序数据
由于序列数据在本质上是连续的,当序列变得太长而不能被模型一次性处理时,可以通过拆分序列以方便模型的读取。
在训练中需要每次随机读取小批量样本和标签。去卷积神经网络和线性网络的数据集不同的是,时序数据的一个样本通常包含连续的字符。假设时间步数为6,样本序列为6个字符,即’m’,’a’,’c’,’h’,’i’,’n’,该样本的标签序列为这些字符分别在训练集中的下一个字符,即’a’,’c’,’h’,’i’,’n’,’e’。这里有两种方式对时序数据进行采样,分别为随机采样和相邻采样。
3.1、随机采样
在随机采样中,每个样本是原始序列上任意截取的一段序列。相邻的两个随机小批量在原始序列上的位置不一定相邻。下面的代码每次从数据中随机采样一个小批量,其中批量大小 batch_size指小批量的样本数, num_step为每个样本所包含的时间步数。
import random
import torch
import numpy
from d2l import torch as d2l
def seq_data_iter_random(corpus, batch_size, num_steps):
corpus = corpus[random.randint(0,num_steps - 1):]
num_subseqs = (len(corpus) - 1) //num_steps
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
random.shuffle(initial_indices)
def data(pos):
return corpus[pos : pos+num_steps]
num_batches = num_subseqs // batch_size
for i in range(0,batch_size * num_batches,batch_size):
initial_indices_per_batch = initial_indices[i : i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X),torch.tensor(Y)
下面生成一个从0到34的序列。 假设批量大小为2,时间步数为5,这意味着可以生成⌊ ( 35 − 1 ) / 5 = 6 ⌋ \lfloor (35-1)/5=6\rfloor ⌊(3 5 −1 )/5 =6 ⌋个”特征-标签”子序列对。 小批量大小为6,因此只能得到3个小批量。
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size = 2,num_steps=5):
print('X: ',X,'\nY:',Y)
X: tensor([[ 7, 8, 9, 10, 11],
[22, 23, 24, 25, 26]])
Y: tensor([[ 8, 9, 10, 11, 12],
[23, 24, 25, 26, 27]])
X: tensor([[27, 28, 29, 30, 31],
[17, 18, 19, 20, 21]])
Y: tensor([[28, 29, 30, 31, 32],
[18, 19, 20, 21, 22]])
X: tensor([[12, 13, 14, 15, 16],
[ 2, 3, 4, 5, 6]])
Y: tensor([[13, 14, 15, 16, 17],
[ 3, 4, 5, 6, 7]])
3.2、相邻采样
除了对原始序列可以随机抽样外,还可以令相邻的两个随机小批量在原始序列上的位置相邻。这时候就可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,从而使下一个小批量的输出也取决于当前小批量的输入,并如此循环下去。这对实现循环神经网络造成了两方面的影响:
- 在训练模型时,我们只需要在一个迭代周期开始时初始化隐藏状态。
- 在多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度将依赖所有串联起来的小批量序列。
同一迭代周期中,随着迭代次数的增加,梯度的计算开销会越来越大。
def seq_data_iter_sequential(corpus, batch_size, num_steps):
offest = random.randint(0,num_steps)
num_tokens = ((len(corpus) - offest -1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offest:offest + num_tokens])
Ys = torch.tensor(corpus[offest + 1: offest + num_tokens +1])
Xs,Ys = Xs.reshape(batch_size,-1),Ys.reshape(batch_size,-1)
num_batchs = Xs.shape[1] // num_steps
for i in range(0,num_steps * num_batchs,num_steps):
X = Xs[:,i:i + num_steps]
Y = Ys[:,i:i + num_steps]
yield X,Y
基于相同的设置,通过相邻采样读取每个小批量的子序列的特征X和标签Y。 通过将它们打印出来可以发现: 迭代期间来自两个相邻的小批量中的子序列在原始序列中是相邻的。
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
X: tensor([[ 1, 2, 3, 4, 5],
[17, 18, 19, 20, 21]])
Y: tensor([[ 2, 3, 4, 5, 6],
[18, 19, 20, 21, 22]])
X: tensor([[ 6, 7, 8, 9, 10],
[22, 23, 24, 25, 26]])
Y: tensor([[ 7, 8, 9, 10, 11],
[23, 24, 25, 26, 27]])
X: tensor([[11, 12, 13, 14, 15],
[27, 28, 29, 30, 31]])
Y: tensor([[12, 13, 14, 15, 16],
[28, 29, 30, 31, 32]])
3.3、操作整合
现在,我们将上面的两个采样函数包装到一个类中,以便稍后可以将其用作数据迭代器。
class SeqDataLoader:
def __init__(self,batch_size,num_steps,use_random_iter,max_tokens):
if use_random_iter:
self.data_iter_fn = seq_data_iter_random
else:
self.data_iter_fn = seq_data_iter_sequential
self.corpus, self.vocab = load_corpus_time_machine(max_tokens)
self.batch_size,self.num_steps = batch_size,num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus,self.batch_size,self.num_steps)
最后,定义了一个函数load_data_time_machine,它同时返回数据迭代器和词表。
def load_data_time_machine(batch_size,num_steps,use_random_iter = False,max_tokens = 10000):
data_iter = SeqDataLoader(batch_size,num_steps,use_random_iter,max_tokens)
return data_iter,data_iter.vocab
下面对The Time Machine数据集的前45个数据进行迭代读取,批量大小为2,时间步长为10,并输出其对应的字符。
import numpy
iter,vocab = load_data_time_machine(2,10,False,45)
for X,Y in iter:
print('X: ', X, '\nY:', Y)
print('X char:',[vocab.to_tokens(i.numpy().tolist()) for i in X])
print('Y char:',[vocab.to_tokens(i.numpy().tolist()) for i in Y])
X: tensor([[ 1, 13, 4, 15, 9, 5, 6, 2, 1, 21],
[12, 12, 8, 5, 3, 9, 2, 1, 3, 5]])
Y: tensor([[13, 4, 15, 9, 5, 6, 2, 1, 21, 19],
[12, 8, 5, 3, 9, 2, 1, 3, 5, 13]])
X char: [[' ', 'm', 'a', 'c', 'h', 'i', 'n', 'e', ' ', 'b'], ['l', 'l', 's', 'i', 't', 'h', 'e', ' ', 't', 'i']]
Y char: [['m', 'a', 'c', 'h', 'i', 'n', 'e', ' ', 'b', 'y'], ['l', 's', 'i', 't', 'h', 'e', ' ', 't', 'i', 'm']]
4、循环神经网络
4.1、概念
前面介绍的n元语法中,时间步t t t的词w t w_t w t 基于前面所有词的条件概率只考虑了最近时间步的n − 1 n-1 n −1个词。如果要考虑比t − ( n − 1 ) t-(n-1)t −(n −1 )更早时间步的词对w t w_t w t 可能会产生好的影响,这样一来就需要增大n,因此模型的参数的数量将随之呈指数级增长。
下面将介绍循环神经网络(Recurrent Natural Network, RNN)。它并非刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。下面就来看看循环神经网络是什么。
下图为循环神经网络的经典结构,从图中可以看到输入x x x,隐藏层,输出层等,这些与传统神经网络类似,不过自循环W W W是循环神经网络的一大特色。这个自循环可以理解为神经元之间的联系。

其中U U U是输入到隐藏层的权重矩阵,W W W是状态到隐藏层的权重矩阵,s s s为状态,V V V是隐藏层到输出层的权重矩阵,下图为上图展开后的样子,从图中可以看出,它的共享参数方式是各个时间节点对应的W 、 U 、 V W、U、V W 、U 、V都是不变的,这个机制就像卷积神经网络的卷积核机制一样,通过这种方式实现参数共享,同时大大降低参数量。

下面看看循环神经网络的是如何进行计算的。假设X t ∈ R n × d X_t \in R^{n \times d}X t ∈R n ×d是序列中时间步t t t的小批量输入,H t ∈ R n × d H_t \in R^{n \times d}H t ∈R n ×d是该时间步的隐藏变量。与多层感知机不同的是,这里我们保存上一步的隐藏变量H t − 1 H_{t-1}H t −1 ,并引入一个新的权重参数W ∈ R h × h W \in R^{h \times h}W ∈R h ×h,该参数用来描述在当前时间步如何使用上一时间步的隐藏变量。具体说,时间步t t t的隐藏变量的计算由当前时间步的输入和上一时间步的隐藏变量共同决定:
H t = ϕ ( X t U + H t − 1 W + b h ) H_t=\phi(X_tU+H_{t-1}W+b_h)H t =ϕ(X t U +H t −1 W +b h )
输出层的计算为:
O t = H t V + b q O_t=H_tV+b_q O t =H t V +b q
循环神经网络的参数包括输入层权重U U U、隐藏层权重W W W、输出层权重V V V和两个偏置参数b h b_h b h 、b q b_q b q 。在不同的时间步,循环神经网络一直使用这些模型参数。因此循环神经网络模型参数的数量不随时间步的增加而增长。
下图为循环神经网络在3个相邻时间步的计算过程。在时间步t t t,隐藏状态的计算可以看成是将输入X t X_t X t 和前一时间步隐藏状态H t − 1 H_{t-1}H t −1 连接后输入一个激活函数为ϕ \phi ϕ的全连接层,该全连接层的输出就是当前时间步的隐藏状态H t H_t H t 。当前时间步的隐藏状态H t H_t H t 将会参与下一个时间步t + 1 t+1 t +1的隐藏状态H t + 1 H_{t+1}H t +1 的计算,并输入到当前时间步的全连接输出层。

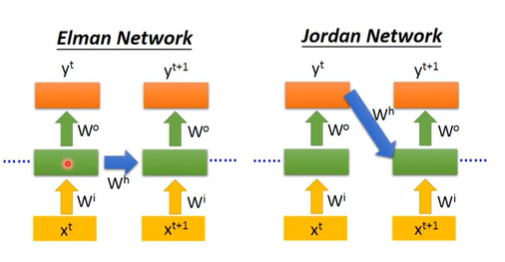
RNN有很多的变形,在上面介绍的网络是Elman Network(下图左边),它是把当前时间节点的隐藏层的值存起来,作为下一个时间节点隐藏层的输入使用;还有一种RNN的结构网络是Jordan Network(下图右边),它是把当前时间节点的输出值作为下一个时间节点隐藏层的输入值。有人说Jordan Network可能会得到更好的性能,因为左边的Elman Network中的隐藏层节点中是没有target的,所以我们不知道隐藏层存的内容是什么,而右图中Jordan Network的输出它是有target的,因此它知道自己应该保存什么信息。但下面的实现中还是使用Elman Network。
; 4.2、通过时间反向传播
下面介绍循环神经网络中梯度计算和存储方法,即通过时间反向传播。
4.2.1、定义模型
为了简单,考虑一个无偏差的循环神经网络,激活函数为恒等映射,设时间步t的输入为单样本x t ∈ R d x_t \in R^d x t ∈R d,标签为y t y_t y t ,那么隐藏状态的表达式为:
h t = U x t + W h t − 1 h_t=Ux_t + Wh_{t-1}h t =U x t +W h t −1
其中U ∈ R h × d U \in R^{h \times d}U ∈R h ×d和W ∈ R h × h W \in R^{h\times h}W ∈R h ×h是输入层和隐藏层权重参数。设输出层权重参数为V ∈ R q × h V \in R^{q\times h}V ∈R q ×h,时间步t t t的输出层变量o t ∈ R q o_t \in R^q o t ∈R q的计算为::
o t = V h t o_t = Vh_t o t =V h t
设时间步t t t的损失函数为l ( o t , y t ) \mathscr l (o_t,y_t)l (o t ,y t )。时间步数为T的损失函数L定义为:
L = 1 T ∑ t = 1 T l ( o t , y t ) L = \frac{1}{T} \sum_{t=1}^T \mathscr l (o_t,y_t)L =T 1 t =1 ∑T l (o t ,y t )
4.2.2、模型计算图
下图为模型计算图,例如时间步3的隐藏状态h 3 h_3 h 3 的计算依赖模型参数U 、 W U、W U 、W、上一时间步隐藏状态h 2 h_2 h 2 以及当前时间步输入x 3 x_3 x 3 。

; 4.2.2、计算
模型的参数是U U U、W W W和V V V。训练模型时需要计算这些参数的梯度∂ L / ∂ U 、 ∂ L / ∂ W \partial L /\partial U、\partial L /\partial W ∂L /∂U 、∂L /∂W和∂ L / ∂ V \partial L /\partial V ∂L /∂V。可以按照计算图中箭头所指的反方向依次计算并存储梯度,下面看看如何进行计算。
输出层梯度
目标函数与各时间步输出层的梯度∂ L / ∂ o t \partial L /\partial {o_t}∂L /∂o t 为:
∂ L ∂ o t = ∂ l ( o t , y t ) T ⋅ ∂ o t \frac{\partial L}{\partial {o_t}} = \frac{\partial {\mathscr l (o_t,y_t)}}{T \cdot \partial o_t}∂o t ∂L =T ⋅∂o t ∂l (o t ,y t )
输出层参数的梯度
下面计算输出层的参数V V V的梯度∂ L / ∂ V \partial L /\partial {V}∂L /∂V。根据计算图L L L通过o 1 , ⋯ o T o_1,\cdots o_T o 1 ,⋯o T 依赖V V V,根据链式法则,计算公式为:
∂ L ∂ V = ∑ t = 1 T ( ∂ L ∂ o t ∂ o t ∂ V ) = ∑ t = 1 T ∂ L ∂ o t h t ⊤ \frac{\partial L}{\partial {V}} = \sum_{t=1}^T(\frac{\partial L}{\partial {o_t}} \frac{\partial {o_t}}{\partial {V}})=\sum_{t=1}^T \frac{\partial L}{\partial {o_t}} h_t^{\top}∂V ∂L =t =1 ∑T (∂o t ∂L ∂V ∂o t )=t =1 ∑T ∂o t ∂L h t ⊤
隐藏状态的梯度
L只通过o T o_T o T 依赖最终时间步T T T的隐藏状态h T h_T h T 。因此目标函数对最终时间步隐藏状态的梯度∂ L / ∂ h T \partial L /\partial {h_T}∂L /∂h T 为:
∂ L ∂ h T = ( ∂ L ∂ o t ∂ o t ∂ h T ) = V ⊤ ∂ L ∂ o T \frac{\partial L}{\partial {h_T}} = (\frac{\partial L}{\partial {o_t}} \frac{\partial {o_t}}{\partial {h_T}})=V^{\top}\frac{\partial L}{\partial {o_T}}∂h T ∂L =(∂o t ∂L ∂h T ∂o t )=V ⊤∂o T ∂L
而对于时间步t < T t \lt T t <T,L L L需要通过h t + 1 h_{t+1}h t +1 和o t o_t o t 依赖h t h_t h t 。根据链式法则,目标函数关于时间步t < T t \lt T t <T的隐藏状态的梯度∂ L / ∂ h t \partial L /\partial {h_t}∂L /∂h t 需要按照时间步从大到小依次计算:
∂ L ∂ h t = ( ∂ L ∂ h t + 1 ∂ h t + 1 ∂ h t ) + ( ∂ L ∂ o t ∂ o t ∂ h t ) = W ⊤ ∂ L ∂ h t + 1 + V ⊤ ∂ L ∂ o t \frac{\partial L}{\partial {h_t}} = (\frac{\partial L}{\partial {h_{t+1}}} \frac{\partial {h_{t+1}}}{\partial {h_t}}) + (\frac{\partial L}{\partial {o_t}} \frac{\partial {o_t}}{\partial {h_t}})=W^{\top}\frac{\partial L}{\partial {h_{t+1}}}+V^{\top}\frac{\partial L}{\partial {o_t}}∂h t ∂L =(∂h t +1 ∂L ∂h t ∂h t +1 )+(∂o t ∂L ∂h t ∂o t )=W ⊤∂h t +1 ∂L +V ⊤∂o t ∂L
将上面的递归公式展开,对于任意时间步1 ⩽ t ⩽ T 1 \leqslant t \leqslant T 1 ⩽t ⩽T,可以得到目标函数有关隐藏状态梯度的通项公式为:
∂ L ∂ h t = ∑ i = t T ( W ⊤ ) T − i V ⊤ ∂ L ∂ o T + t − i \frac{\partial L}{\partial {h_t}} = \sum_{i=t}^T (W^{\top})^{T-i} V^{\top} \frac{\partial L}{\partial {o_{T+t-i}}}∂h t ∂L =i =t ∑T (W ⊤)T −i V ⊤∂o T +t −i ∂L
输入层和隐藏层参数的梯度
由上式的指数项可见,当时间步数T T T较大或者时间步t t t较小时,目标函数有关隐藏状态的梯度容易出现衰减和爆炸。这也会影响其他包含∂ L ∂ h t \frac{\partial L}{\partial {h_t}}∂h t ∂L 项的梯度,例如输入层和隐藏层的参数的梯度∂ L / ∂ U \partial L /\partial {U}∂L /∂U和∂ L / ∂ W \partial L /\partial {W}∂L /∂W。L L L通过h 1 , ⋯ , h T h_1,\cdots ,h_T h 1 ,⋯,h T 依赖这些模型参数,根据链式法则有:
∂ L ∂ U = ∑ i = 1 T ( ∂ L ∂ h t ∂ h t ∂ U ) = ∑ i = 1 T ∂ L ∂ h t x t ⊤ ∂ L ∂ W = ∑ i = 1 T ( ∂ L ∂ h t ∂ h t ∂ W ) = ∑ i = 1 T ∂ L ∂ h t h t − 1 ⊤ \frac{\partial L}{\partial {U}}= \sum_{i=1}^T(\frac{\partial L}{\partial {h_{t}}} \frac{\partial h_t}{\partial {U}})=\sum_{i=1}^T \frac{\partial L}{\partial {h_{t}}}x_t^{\top}\ \frac{\partial L}{\partial {W}}= \sum_{i=1}^T(\frac{\partial L}{\partial {h_{t}}} \frac{\partial h_t}{\partial {W}})=\sum_{i=1}^T \frac{\partial L}{\partial {h_{t}}}h_{t-1}^{\top}∂U ∂L =i =1 ∑T (∂h t ∂L ∂U ∂h t )=i =1 ∑T ∂h t ∂L x t ⊤∂W ∂L =i =1 ∑T (∂h t ∂L ∂W ∂h t )=i =1 ∑T ∂h t ∂L h t −1 ⊤
4.3、应用:基于字符级循环神经网络的语言模型
下面介绍如何使循环神经网络来构建语言模型。设小批量大小为1,批量中的那个文本序为”machine”,下图演示了如何通过基于字符级语言建模的循环神经网络,即使用当前的和先前的字符预测下一个字符。
在训练过程中,我们对每个时间步的输出层的输出进行softmax操作, 然后利用交叉熵损失计算模型输出和标签之间的误差。图中时间步3的输出O 3 O_3 O 3 取决于文本序列”m”、”a”和”c”,由于训练数据中该序列的下一个字符为”h”,因此时间步3的损失将取决于该时间步基于序列”m”、”a”和”c”生成下一个词为”h”的概率。

; 4.4、循环神经网络从零实现
下面将根据对循环神经网络的描述,从头实现循环神经网络实现字符级语言模型。并使用模型在The Time Machine数据集上进行训练,下面使用前面定义的函数读取The Time Machine数据集。
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
%matplotlib inline
batch_size, num_steps = 32,35
train_iter,vocab = load_data_time_machine(batch_size, num_steps)
4.4.1、独热(ont-hot)编码
在处理后的The Time Machine数据集中,将每一个词元表示为一个数字索引,将这些索引直接引入神经网络会使得学习变得困难。因此通常将词元表示为更具表现力的特征向量(如ont-hot、词向量等),这里先介绍最简单的表示 独热编码(ont-hot)。
这本数据集中,独热编码就是将每个所用映射为不同的单位向量:假设不同词元的数目为N N N(len(vocab)),词元索引的范围为0到N − 1 N-1 N −1。如果词元的索引为整数i i i,就创建一个长度为N N N的全0向量,并将第i i i处的元素设置为1。下面将使用 torch.nn.functional.one_hot(tensor, num_classes=- 1)函数演示如何生成独热向量,其参数的含义为:
- tensor (LongTensor):类值。
- num_classes (int):类的总数。如果设置为 -1,则类数将被推断为比输入张量中的最大类值大 1。
F.one_hot(torch.tensor([0,2]),len(vocab))
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]])
我们每次采样的小批量数据形状是二维张量(批量大小,时间步数),下面演示one_hot函数如何将这样的一个小批量数据转换成三维张量,张量的最后一个维度等于词表大小。为便于输入模型,可以转换输入的维度,以便获得形状为(时间步数、批量大小、词表大小)的输出。这样使得能够方便地通过最外层的维度,一步一步更新小批量数据的隐状态( 循环神经网络是根据时间步进行输入的)。
X = torch.arange(10).reshape((2,5))
F.one_hot(X.T,28).shape
torch.Size([5, 2, 28])
4.4.2、初始化模型参数
下面初始化循环神经网络模型的模型参数。隐藏单元数 num_hiddens是一个可调的超参数。当训练语言模型时。输入和输出来自相同的词表,因此他们具有相同的维度,即词表的大小。
因为将索引转为了one-hot编码,因此输入的维度为one-hot编码的长度即词表大小,如果使用其他词向量的方式,就不一定是词表的大小了。隐藏单元数
num_hiddens应该说成隐藏层的特征数量比较好,隐藏单元数是由输入时间步大小决定的哇。
def get_params(vocab_size,num_hiddens,device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape,device=device) * 0.01
W_xh = normal((num_inputs,num_hiddens))
W_hh = normal((num_hiddens,num_hiddens))
b_h = torch.zeros(num_hiddens,device=device)
W_hq = normal((num_hiddens,num_outputs))
b_q = torch.zeros(num_outputs,device=device)
params = [W_xh,W_hh,b_h,W_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
4.4.3、循环神经网络模型
首先定义一个 init_rnn_state函数在初始化时返回隐状态,这个函数返回的是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)
第一个隐状态哇,需要自己初始化哇,这个隐藏单元数应该叫隐藏层的特征数量小比较好
def init_rnn_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device=device),)
下面的rnn函数定义了如何在一个时间步内 计算隐状态和输出。循环神经网络模型通过inputs的最外层的维度实现循环,以便逐时间步更新小批量数据的隐状态H。激活函数选择tanh激活函数。
一个时间步的输入为: 同一时间步的批量大小长度为此表大小的向量,因此为逐时间更新小批量数据的隐状态。
def rnn(inputs,state,params):
W_xh,W_hh,b_h,W_hq,b_q = params
H, = state
outputs = []
for X in inputs:
H = torch.tanh(torch.mm(X,W_xh) + torch.mm(H,W_hh) + b_h)
Y = torch.mm(H,W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,)
定义了所有需要的函数之后,接下来我们创建一个类来包装这些函数, 并存储从零开始实现的循环神经网络模型的参数。
class RNNModelScratch:
def __init__(self,vocab_size,num_hiddens,device,get_params,init_state,forward_fn):
self.vocab_size,self.num_hiddens = vocab_size,num_hiddens
self.params = get_params(vocab_size,num_hiddens,device)
self.init_state,self.forward_fn = init_state,forward_fn
def __call__(self, X,state):
X = F.one_hot(X.T,self.vocab_size).type(torch.float32)
return self.forward_fn(X,state,self.params)
def begin_state(self,batch_size,device):
return self.init_state(batch_size,self.num_hiddens,device)
定义一个使用GPU的函数,如果有GPU设备就使用,如果没有,就使用CPU。
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
下面测试一下定义的循环神经网络,检查其是否具有正确的形状。例如隐状态的维数是否保持不变。
num_hiddens = 512
net = RNNModelScratch(len(vocab),num_hiddens,try_gpu(),get_params,init_rnn_state,rnn)
state = net.begin_state(X.shape[0],d2l.try_gpu())
Y,new_state = net(X.to(d2l.try_gpu()),state)
Y.shape,len(new_state),new_state[0].shape
(torch.Size([10, 28]), 1, torch.Size([2, 512]))
4.4.4、预测
下面定义预测函数用来生成前缀(prefix)之后的新字符,其中前缀是用户提供的包含多个字符的字符串。在循环遍历前缀中的开始字符时,不断将隐状态传递到下一个时间步,但是不产生任何输出,这被称为 预热期。在此期间模型会自我更新,但不会进行预测。预热期结束后,隐状态的值通常比刚开始的初始值更适合预测,从而预测字符并输出它们。
def predict(prefix,num_preds,net,vocab,device):
state = net.begin_state(batch_size = 1,device=device)
outputs = [vocab[prefix[0]]]
get_input = lambda : torch.tensor([outputs[-1]],device=device).reshape((1,1))
for y in prefix[1:]:
_,state = net(get_input(),state)
outputs.append(vocab[y])
for _ in range(num_preds):
y,state = net(get_input(),state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
下面使用predict函数,指定前缀为time traveller,并基于这个前缀生成10个后续字符。由于网络没有训练,会产生很差的结果。
predict('time traveller ', 10, net, vocab, try_gpu())
'time traveller brw brw br'
4.4.5、训练
在训练模型之前,定义一个函数在一个迭代周期内训练模型,它的训练模式与之前的模型的训练方式有以下不同的地方:
- 序列数据的不同采样方法(随机采样和相邻采样)将导致隐状态初始化的差异。
- 在更新模型参数之前使用裁剪梯度。目的是计时训练过程中某个点发生了梯度爆炸,也能保证模型不会发散。
- 使用困惑度来评价模型。这样的度量确保不同长度的序列具有可比性。
下面看看使用随机采样和相邻采样如何初始化隐状态:
相邻采样:
使用相邻采样时,只在每个迭代周期的开始位置初始化隐状态。
原因是下一个小批量数据中的第i i i个子序列样本与当前第i i i个子序列样本相邻,因此当前小批量数据最后一个样本的隐状态,将用于初始化下一个小批量数据的第一个隐状态。这样,存储在隐状态中的历史信息可以在一个迭代周期内流入相邻的子序列。
然而,在任何一点隐状态的计算,都依赖于同一迭代周期中前面所有的小批量数据,这使得梯度计算变得复杂。为了降低计算量,在处理任何一个小批量数据之前,先分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。
随机采样
当使用随机采样时,因为每个样本都是在一个随机位置抽样的,因此需要为每个迭代周期重新初始化隐状态。
下面的函数在一个迭代周期内训练模型:
def train_epoch(net,train_iter,loss,updater,device,use_random_iter):
state,timer = None,d2l.Timer()
metric = d2l.Accumulator(2)
for X,Y in train_iter:
if state is None or use_random_iter:
state = net.begin_state(batch_size = X.shape[0],device=device)
else:
if isinstance(net,nn.Module) and not isinstance(state,tuple):
state.detach_()
else:
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X,y = X.to(device),y.to(device)
y_hat,state = net(X,state)
l = loss(y_hat,y.long()).mean()
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.backward()
updater.step()
else:
l.backward()
updater(batch_size = 1)
metric.add(l * y.numel(),y.numel())
return math.exp(metric[0]/metric[1]),metric[1]/timer.stop()
循环神经网络模型的训练函数既支持从零开始实现, 也可以使用高级API来实现。
def sgd(params,lr,batch_size):
with torch.no_grad():
for param in params:
param -= lr*param.grad / batch_size
param.grad.zero_()
def train(net,train_iter,vocab,lr,num_epochs,device,use_random_iter = False):
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel = 'epoch',ylabel='perplexity',
legend=['train'],xlim=[10,num_epochs])
if isinstance(net,nn.Module):
updater = torch.optim.SGD(net.parameters(),lr)
else:
updater = lambda batch_size:sgd(net.params,lr,batch_size)
predict_ = lambda prefix:predict(prefix,50,net,vocab,device)
for epoch in range(num_epochs):
ppl,speed = train_epoch(net,train_iter,loss,updater,device,use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict_('time traveller'))
animator.add(epoch + 1,[ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict_('time traveller'))
print(predict_('traveller'))
对模型进行训练,并使用训练的模型对”time traveller”和”traveller”两个前缀进行预测。
num_epochs, lr = 500, 1
train(net, train_iter, vocab, lr, num_epochs, try_gpu())
困惑度 1311477198769546752.0, 61831.6 词元/秒 cuda:0
time travelleroleeoleeoleooeeoleeoleooieoleroleoleeoleoleeoieole
travellereooleoleeoleeoieoleeoleeoleeoleeoieoleeoleeoleeole
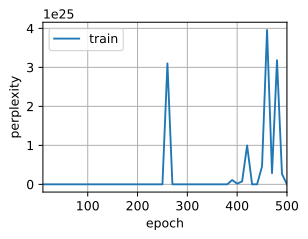
这结果也太差了吧!!!刚开始的时候,训练的损失还是很小的,突然变得很大,又突然变得很小,这也太不稳定了吧,那是什么造成这种原因了呢?
下图为RNN中的损失值随参数变化的图像,从图像中可以看出,变化是非常崎岖的。损失的变化在有些地方是十分的平坦,而有些地方则变得十分陡峭。当在进行梯度下降过程中,如果刚好经过变化比较陡峭的地方,那么损失就会暴增或者暴跌。在比较平坦的地方由于梯度大小比较小,那么学习率较大,然而当经过一个陡峭的地方的时候,来不及调整学习率,一个大的学习率乘以一个大的梯度,那么就会导致参数飞出去了。
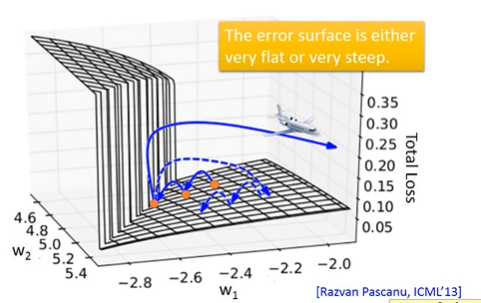
那么怎么解决这个问题哪?一个比较简单的方法是使用 梯度裁剪,就是将梯度固定在某一个范围内。这是以下比较简单的方法,下面介绍一下梯度裁剪。
4.4.6、梯度裁剪
通过我们的分析我们了解到直接训练RNN模型是不可取的,并且通过由前面介绍的反向传播中可知,当T较大时,它可能导致数值不稳定,例如导致梯度爆炸或者梯度消失。因此循环神经网络需要额外的方式来支持稳定训练。
当梯度很大时,优化算法可能无法收敛。因此可以通过降低学习率η \eta η来解决这个问题。但是如果我们很少得到大的梯度,这种做法就很不好。一种流行的替代方法是将梯度g g g投影回给定半径(例如θ \theta θ)的球来裁剪梯度g g g。如以下公式:
g ⟵ m i n ( 1 , θ ∣ ∣ g ∣ ∣ ) g g \longleftarrow min(1, \frac{\theta}{||g||})g g ⟵m i n (1 ,∣∣g ∣∣θ)g
通过这样做,梯度的范数永远不会超过θ \theta θ,并且更新后的梯度完全与g g g的原始方向对齐。它还限制了任何给定小批量诗句对参数向量的影响,这使得模型的稳定性更好。
梯度裁剪提供了一个快速修复梯度爆炸的方法,虽然并不能完全解决问题,但它是众多有效的技术之一。下面定义一个函数来裁剪模型的梯度。
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
下面为添加了梯度参加的训练模型一个迭代周期的代码:
def train_epoch(net,train_iter,loss,updater,device,use_random_iter):
state,timer = None,d2l.Timer()
metric = d2l.Accumulator(2)
for X,Y in train_iter:
if state is None or use_random_iter:
state = net.begin_state(batch_size = X.shape[0],device=device)
else:
if isinstance(net,nn.Module) and not isinstance(state,tuple):
state.detach_()
else:
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X,y = X.to(device),y.to(device)
y_hat,state = net(X,state)
l = loss(y_hat,y.long()).mean()
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net,1)
updater.step()
else:
l.backward()
grad_clipping(net,1)
updater(batch_size = 1)
metric.add(l * y.numel(),y.numel())
return math.exp(metric[0]/metric[1]),metric[1]/timer.stop()
下面定义一个新的模型,再使用添加了梯度参加的模型训练过程对新的模型进行训练。
num_hiddens = 512
net1 = RNNModelScratch(len(vocab),num_hiddens,try_gpu(),get_params,init_rnn_state,rnn)
num_epochs, lr = 500, 1
train(net1, train_iter, vocab, lr, num_epochs, try_gpu())
困惑度 1.0, 57780.6 词元/秒 cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
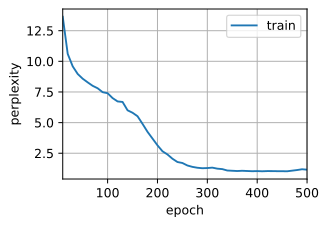
这下训练结果很不错了。。。
下面使用随机抽样方法训练一下模型。
net = RNNModelScratch(len(vocab), num_hiddens, try_gpu(), get_params,
init_rnn_state, rnn)
train(net, train_iter, vocab, lr, num_epochs, try_gpu(),
use_random_iter=True)
困惑度 1.6, 57201.7 词元/秒 cuda:0
time travellerit s against reason said filbywhat very revarthe w
traveller hat nog hat seatl rather a some time brightening
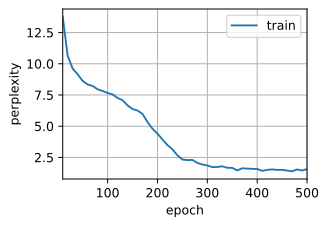
4.4.7、代码整合
下面对从零实现的循环神经网络从数据处理到模型搭建、训练、预测的代码进行整合。
import collections
import re
import random
import numpy
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
with open(d2l.download('time_machine'),'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+',' ',line).strip().lower() for line in lines]
def tokenize(lines, token = 'word'):
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:'+token)
def count_corpus(tokens):
if len(tokens) == 0 or isinstance(tokens[0], list):
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
self.idx_to_token = [''] + reserved_tokens
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
def load_corpus_time_machine(max_tokens = -1):
lines = read_time_machine()
tokens = tokenize(lines,'char')
vocab = Vocab(tokens)
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus,vocab
def seq_data_iter_random(corpus, batch_size, num_steps):
corpus = corpus[random.randint(0, num_steps - 1):]
num_subseqs = (len(corpus) - 1) // num_steps
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
random.shuffle(initial_indices)
def data(pos):
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
def seq_data_iter_sequential(corpus, batch_size, num_steps):
offest = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offest - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offest:offest + num_tokens])
Ys = torch.tensor(corpus[offest + 1: offest + num_tokens + 1])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batchs = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batchs, num_steps):
X = Xs[:, i:i + num_steps]
Y = Ys[:, i:i + num_steps]
yield X, Y
class SeqDataLoader:
def __init__(self,batch_size,num_steps,use_random_iter,max_tokens):
if use_random_iter:
self.data_iter_fn = seq_data_iter_random
else:
self.data_iter_fn = seq_data_iter_sequential
self.corpus, self.vocab = load_corpus_time_machine(max_tokens)
self.batch_size,self.num_steps = batch_size,num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus,self.batch_size,self.num_steps)
def load_data_time_machine(batch_size,num_steps,use_random_iter = False,max_tokens = 10000):
data_iter = SeqDataLoader(batch_size,num_steps,use_random_iter,max_tokens)
return data_iter,data_iter.vocab
def get_params(vocab_size,num_hiddens,device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape,device=device) * 0.01
W_xh = normal((num_inputs,num_hiddens))
W_hh = normal((num_hiddens,num_hiddens))
b_h = torch.zeros(num_hiddens,device=device)
W_hq = normal((num_hiddens,num_outputs))
b_q = torch.zeros(num_outputs,device=device)
params = [W_xh,W_hh,b_h,W_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
def init_rnn_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device=device),)
def rnn(inputs,state,params):
W_xh,W_hh,b_h,W_hq,b_q = params
H, = state
outputs = []
for X in inputs:
H = torch.tanh(torch.mm(X,W_xh) + torch.mm(H,W_hh) + b_h)
Y = torch.mm(H,W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,)
class RNNModelScratch:
def __init__(self,vocab_size,num_hiddens,device,get_params,init_state,forward_fn):
self.vocab_size,self.num_hiddens = vocab_size,num_hiddens
self.params = get_params(vocab_size,num_hiddens,device)
self.init_state,self.forward_fn = init_state,forward_fn
def __call__(self, X,state):
X = F.one_hot(X.T,self.vocab_size).type(torch.float32)
return self.forward_fn(X,state,self.params)
def begin_state(self,batch_size,device):
return self.init_state(batch_size,self.num_hiddens,device)
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def predict(prefix, num_preds, net, vocab, device):
state = net.begin_state(batch_size=1, device=device)
outputs = [vocab[prefix[0]]]
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))
for y in prefix[1:]:
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds):
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: sgd(net.params, lr, batch_size)
predict_ = lambda prefix: predict(prefix, 50, net, vocab, device)
for epoch in range(num_epochs):
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2)
for X, Y in train_iter:
if state is None or use_random_iter:
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
state.detach_()
else:
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
else:
l.backward()
grad_clipping(net, 1)
updater(batch_size=1)
metric.add(l * y.numel(), y.numel())
ppl, speed = math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
if (epoch + 1) % 10 == 0:
print(predict_('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict_('time traveller'))
print(predict_('traveller'))
batch_size, num_steps = 32,35
num_epochs, lr = 500, 1
num_hiddens = 512
train_iter,vocab = load_data_time_machine(batch_size, num_steps)
net = RNNModelScratch(len(vocab),num_hiddens,try_gpu(),get_params,init_rnn_state,rnn)
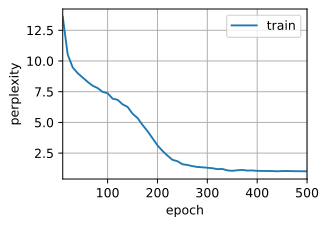
train(net, train_iter, vocab, lr, num_epochs, try_gpu())
困惑度 1.0, 57818.5 词元/秒 cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
4.5、循环神经网络简洁实现
4.5.1、 torch.nn.RNN() 函数
PyTorch中提供了两个实现循环神经网络的方法: torch.nn.RNN()和 torch.nn.RNNCell()。 torch.nn.RNN()的输入是一个序列;而 torch.nn.RNNCell()的输入是一个时间步,因此需要使用循环才能实现对一个序列进行处理的功能。下面主要介绍 torch.nn.RNN()。
torch.nn.RNN()的一般格式为:
torch.nn.RNN(*args, **kwargs)
对于输入序列中的每个元素,每层都计算以下函数:
h t = t a n h ( W i h x t + b i h + W h h h t − 1 + b h h ) h_t = tanh(W_{ih}x_t + b_{ih} + W_{hh}h_{t-1}+b_{hh})h t =t a n h (W i h x t +b i h +W h h h t −1 +b h h )
下面看看该函数中的参数:
input_size:输入x的特征数量hidden_size:隐藏层的特征数量num_layers:RNN层数nonlinearity:指定非线性函数使用tanh还是relu。默认是tanhbias:如果是False,RNN层就不会使用偏置权重,默认是Truebatch_first:如果为True的话,那么输入Tensor的shape应该是(batch,seq,feature),输出也是这样。默认为False,即网络输入为(seq,batch,feature),即序列长度、批次大小、特征维度dropout:如果值非零(参数的取值范围在0-1之间),那么除了最后一层外,其他层的输出都会加上一个dropout层,默认为0bidirectional:如果True,将编程一个双向的RNN,默认为False。
函数 torch.nn.RNN()的输入为特征和隐藏状态,记为( x t , h 0 ) (x_t,h_0)(x t ,h 0 ),输出包括输出特征和输出隐藏状态,记为( o u t p u t t , h n ) (output_t,h_n)(o u t p u t t ,h n )。
下面看看各个的形状是什么样子的:
- 其中输入特征值x t x_t x t 的形状为(seq_len,batch,input_size),这与CNN的输入不一样,CNN的第一个参数为批量大小,而RNN为序列的长度,因为RNN需要一个时间步一个时间步的进行输入。
- h 0 h_0 h 0 的形状为(num_layers * num_directional,batch,hidden_size),其中num_layers为层数,num_directional为方向数,如果取2则表示为双向,取1表示为单向。
- o u t p u t t output_t o u t p u t t 的形状为(seq_len,batch,num_directional * hidden_size)
- h n h_n h n 的形状为(num_layers * num_directional,batch,hidden_size)
4.5.2、RNN简洁实现
下面使用 torch.nn.RNN()函数实现一个简洁版的循环神经网络。其中数据预处理,数据加载,模型训练以及预测还使用上面定义的,本节重点关注如何使用 torch.nn.RNN()搭建循环神经网络。在整合版本中有完整代码。
导入所使用的包并加载The Time Machine数据集:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
定义模型
在定义模型之前,先看看如何使用这个函数,我们构造一个隐藏层特征数量为256的单隐藏层的循环神经网络rnn_layer。而多层就可以理解为一层循环神经网络的输出被下一层作为输入就好了,可以通过参数 num_layers指定。
num_hiddens = 256
rnn_layrer = nn.RNN(len(vocab), num_hiddens)
下面使用张量来初始化隐状态,它的形状是(隐藏层数,批量大小,隐藏单元数)。
state = torch.zeros((1,batch_size,num_hiddens))
state.shape
torch.Size([1, 32, 256])
通过一个隐状态和一个输入,就可以使用更新后的隐状态计算输出。rnn_layer的”输出”(Y)不涉及输出层的计算: 它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
如果得到最终的输出还需要再接线性层
X = torch.rand(size = (num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layrer(X, state)
Y.shape, state_new.shape
(torch.Size([35, 32, 256]), torch.Size([1, 32, 256]))
下面为一个完整的循环神经网络模型定义了一个RNNModel类。 使用 nn.RNN构造的循环神经网络只包含隐藏的循环层,我们还需要创建一个单独的输出层。
class RNNModel(nn.Module):
def __init__(self,vocab_size,num_hiddens,**kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = nn.RNN(vocab_size,num_hiddens)
self.vocab_size = vocab_size
self.num_hiddens = num_hiddens
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens,self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2,self.vocab_size)
def forward(self,inputs,state):
X = F.one_hot(inputs.T.long(),self.vocab_size)
X = X.to(torch.float32)
Y,state = self.rnn(X,state)
output = self.linear(Y.reshape((-1,Y.shape[-1])))
return output,state
def begin_state(self,device,batch_size = 1):
if not isinstance(self.rnn,nn.LSTM):
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size,self.num_hiddens),
device=device)
else:
return (torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size,self.num_hiddens),device=device),
torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size,self.num_hiddens),device=device))
在训练模型之前,基于一个具有随机权重的模型进行预测。
device = try_gpu()
net = RNNModel(vocab_size=len(vocab),num_hiddens=num_hiddens)
net = net.to(device)
predict('time traveller',10,net,vocab,device=device)
'time travellerlzdrlzdrlz'
显然,没有训练过的模型,不可能输出好的结果,下面对模型进行训练,然后再预测。
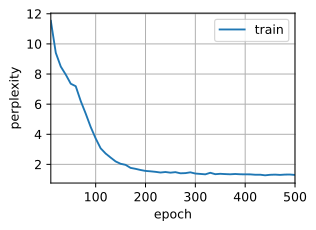
num_epochs,lr = 500,1
train(net,train_iter,vocab,lr,num_epochs,device)
困惑度 1.3, 191189.5 词元/秒 cuda:0
time traveller proceeded anyreal body must hove the of the thing
travelleryor sithisald the ithard asteat lo germabous toven
4.5.3、代码整合
这部分把数据处理、数据加载、模型定义、模型训练都集成在一起。
import collections
import re
import random
import numpy
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
with open(d2l.download('time_machine'),'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+',' ',line).strip().lower() for line in lines]
def tokenize(lines, token = 'word'):
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:'+token)
def count_corpus(tokens):
if len(tokens) == 0 or isinstance(tokens[0], list):
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
self.idx_to_token = [''] + reserved_tokens
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
def load_corpus_time_machine(max_tokens = -1):
lines = read_time_machine()
tokens = tokenize(lines,'char')
vocab = Vocab(tokens)
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus,vocab
def seq_data_iter_random(corpus, batch_size, num_steps):
corpus = corpus[random.randint(0, num_steps - 1):]
num_subseqs = (len(corpus) - 1) // num_steps
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
random.shuffle(initial_indices)
def data(pos):
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
def seq_data_iter_sequential(corpus, batch_size, num_steps):
offest = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offest - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offest:offest + num_tokens])
Ys = torch.tensor(corpus[offest + 1: offest + num_tokens + 1])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batchs = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batchs, num_steps):
X = Xs[:, i:i + num_steps]
Y = Ys[:, i:i + num_steps]
yield X, Y
class SeqDataLoader:
def __init__(self,batch_size,num_steps,use_random_iter,max_tokens):
if use_random_iter:
self.data_iter_fn = seq_data_iter_random
else:
self.data_iter_fn = seq_data_iter_sequential
self.corpus, self.vocab = load_corpus_time_machine(max_tokens)
self.batch_size,self.num_steps = batch_size,num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus,self.batch_size,self.num_steps)
def load_data_time_machine(batch_size,num_steps,use_random_iter = False,max_tokens = 10000):
data_iter = SeqDataLoader(batch_size,num_steps,use_random_iter,max_tokens)
return data_iter,data_iter.vocab
class RNNModel(nn.Module):
def __init__(self,vocab_size,num_hiddens,**kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = nn.RNN(vocab_size,num_hiddens)
self.vocab_size = vocab_size
self.num_hiddens = num_hiddens
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens,self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2,self.vocab_size)
def forward(self,inputs,state):
X = F.one_hot(inputs.T.long(),self.vocab_size)
X = X.to(torch.float32)
Y,state = self.rnn(X,state)
output = self.linear(Y.reshape((-1,Y.shape[-1])))
return output,state
def begin_state(self,device,batch_size = 1):
if not isinstance(self.rnn,nn.LSTM):
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size,self.num_hiddens),
device=device)
else:
return (torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size,self.num_hiddens),device=device),
torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size,self.num_hiddens),device=device))
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def predict(prefix, num_preds, net, vocab, device):
state = net.begin_state(batch_size=1, device=device)
outputs = [vocab[prefix[0]]]
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))
for y in prefix[1:]:
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds):
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
updater = torch.optim.SGD(net.parameters(), lr)
predict_ = lambda prefix: predict(prefix, 50, net, vocab, device)
for epoch in range(num_epochs):
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2)
for X, Y in train_iter:
if state is None or use_random_iter:
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
state.detach_()
else:
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
metric.add(l * y.numel(), y.numel())
ppl, speed = math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
if (epoch + 1) % 10 == 0:
print(predict_('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
下面训练模型
batch_size, num_steps = 32, 35
num_epochs, lr = 500, 1
num_hiddens = 512
train_iter, vocab = load_data_time_machine(batch_size, num_steps)
net = RNNModel(vocab_size=len(vocab),num_hiddens=num_hiddens)
net.to(try_gpu())
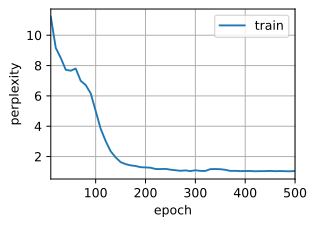
train(net,train_iter,vocab,lr,num_epochs,try_gpu())
困惑度 1.0, 92812.7 词元/秒 cuda:0
下面使用训练好的模型预测一下句子。
predict('you', 22, net, vocab, try_gpu())
'you sure we can move free'
结果是一句话哈哈。
Original: https://blog.csdn.net/tcn760/article/details/124366666
Author: CityD
Title: Chapter7 循环神经网络-1
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530789/
转载文章受原作者版权保护。转载请注明原作者出处!