

文章目录
NLP文本生成的评价指标有什么?
NLP文本生成任务的评价指标有哪些?怎么判断模型好坏呢?如何解读指标的意义?例如,机器翻译任务,使用机器学习的方法生成文本的翻译之后,需要评价模型翻译的性能,这就要用到一些机器翻译评价指标。今天具体介绍常见的几个指标:BLEU,ROUGE,METEOR.
1. BLEU
评估标准:BLEU (Bilingual Evaluation Understudy)——越大越好
核心思想:比较候选译文和参考译文里的 n-gram 的重合程度, 重合程度越高就认为译文质量越高。unigram用于衡量单词翻译的准确性,高阶n-gram用于衡量句子翻译的流畅性。
计算方法,如下所示,通常取N=1~4,再加权平均。BLEU在语料库层级上匹配表现较好,但随着N增加,在句子层级上匹配越来越差。BLEU对长度比较敏感。


其中,
- P n P_n P n 指 n-gram 的精确率。
- W n W_n W n 指 n-gram 的权重。
- B P BP B P 是惩罚因子。
- l r lr l r指参考译文长度。
- l c lc l c指候选译文长度。
一个例子:假设机器翻译的译文C和一个参考翻译S1如下:
C: a cat is on the table
S1: there is a cat on the table
则可以计算出 1-gram,2-gram,… 的精确率:

直接这样子计算 Precision 会存在一些问题,例如:
C: there there there there there
S1: there is a cat on the table
这时候机器翻译的结果明显是不正确的,但是其 1-gram 的 Precision 为1,因此 BLEU 一般会使用 修正的方法。给定参考译文S 1 , S 2 , . . . , S m S_1,S_2, …,S_m S 1 ,S 2 ,…,S m ,可以计算C C C里面 n 元组的 Precision,计算公式如下:

Python的自然语言工具包NLTK提供BLEU的实现,通过与参考文本对比,评估生成的文本。
-
NLTK提供了sentence_bleu()函数, 用于根据一个或多个参考语句来评估候选语句.
-
NLTK 还提供了corpus_bleu()的函数来计算多个句子 (如段落或文档) 的 BLEU 分数.
-
NLTK 还提供了modified_precision()函数计算修正的n-gram精确度。
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['the', 'fast', 'brown', 'fox', 'jumped', 'over', 'the', 'sleepy', 'dog']
score = sentence_bleu(reference, candidate)
print(score)
references = [[['this', 'is', 'a', 'test'], ['this', 'is' 'test']]]
candidates = [['this', 'is', 'a', 'test']]
score = corpus_bleu(references, candidates)
print(score)
2. ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)专注于 召回率(关注有多少个参考译句中的 n- gram出现在了输出之中)而非精度(候选译文中的n-gram有没有在参考译文中出现过)。可以阅读Chin-Yew Lin的论文《ROUGE: A Package for Automatic Evaluation of Summaries》。
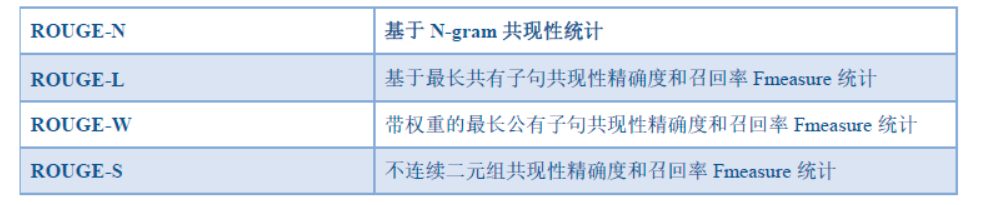
; 2.1 ROUGE-N (将BLEU的精确率优化为召回率)
评估标准:计算ROUGE-1和ROUGE-2的F1-score,越大越好。

公式的分母是统计在参考译文中 N-gram 的个数,而分子是统计参考译文与机器译文共有的 N-gram 个数。
一个例子,分别计算ROUGE-1 和 ROUGE-2 分数如下:
C: a cat is on the table
S1: there is a cat on the table

如果给定多个参考译文S i S_i S i ,Chin-Yew Lin 论文也给出了一种计算方法,假设有 M 个译文 S 1 , S 2 , . . . , S m S_1,S_2, …,S_m S 1 ,S 2 ,…,S m 。ROUGE-N 会分别计算机器译文和这些参考译文的 ROUGE-N 分数,并取其最大值,公式如下。这个方法也可以用于 ROUGE-L,ROUGE-W 和 ROUGE-S。

2.2 ROUGE-L (将BLEU的n-gram优化为公共子序列)
评估标准:基于LCS计算F1-score,越大越好。
ROUGE-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文C和参考译文S的最长公共子序列,计算公式如下:
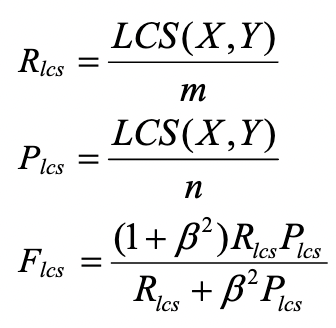
- R L C S R_{LCS}R L C S 表示召回率,而P L C S P_{LCS}P L C S 表示精确率,F L C S F_{LCS}F L C S 就是 ROUGE-L。
- β \beta β用于调节对精确率和召回率的关注度。
- 如果β \beta β 很大,则F L C S F_{LCS}F L C S 会更关注R L C S R_{LCS}R L C S ,P L C S P_{LCS}P L C S 可以忽略不计。

; 2.3 ROUGE-W (ROUGE-W 是 ROUGE-L 的改进版)
评估标准:ROUGE-W基于ROUGE-L添加一个权重,越大越好。
ROUGE-L在计算最长公共子序列时,对于子序列的连续性没有限制,即两个词汇之间可以有任意长度的代沟,但是这不一定是不合理的。考虑下面的例子,X X X表示参考译文,而Y 1 Y_1 Y 1 ,Y 2 Y_2 Y 2 表示两种机器译文。
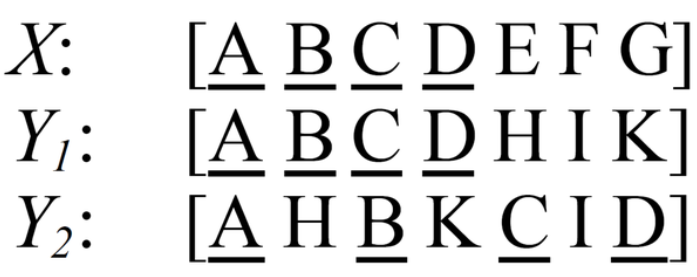
在这个例子中,明显 Y 1 Y_1 Y 1 的翻译质量更高,因为Y 1 Y_1 Y 1 有更多连续匹配的翻译。但是采用 ROUGE-L 计算得到的分数确实一样的,即 R O U G E − L ( X , Y 1 ) = R O U G E − L ( X , Y 2 ) ROUGE-L(X,Y_1)=ROUGE-L(X, Y_2)R O U G E −L (X ,Y 1 )=R O U G E −L (X ,Y 2 )。
因此作者提出了一种 加权最长公共子序列方法 (WLCS),给连续翻译正确的更高的分数。所以ROUGE-W在ROUGE-L的基础上对连续性添加一个权重,可以阅读原论文《ROUGE: A Package for Automatic Evaluation of Summaries》。
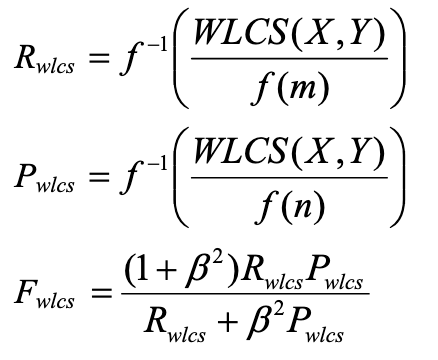
; 2.4 ROUGE-S (Skip-Bigram Co-Occurrence Statistics)
评估标准:基于Skip-gram计算F1-score,越大越好。
ROUGE-S 也是对 N-gram 进行统计,但是其采用的 N-gram 允许” 跳词 (Skip)“,即单词不需要连续出现。skip-bigram是一句话中任意两个有序的词,它们之间可以间隔任意长,基于 skip-bigram的ROUGE-S计算如下:
- ROUGE-S先对生成文本和参考文本中的2-gram进行组合,此时的2-gram不一定是连续的,可以是有间隔的,称为Skip-Bigram;
- 然后计算生成文本中出现在参考文本的Skip-Bigram在参考文本所有Skip-Bigram的比重(即R s k i p 2 R_{skip2}R s k i p 2 );
- 计算参考文本中出现在生成文本的Skip-Bigram在生成文本所有Skip-Bigram的比重(即P s k i p 2 P_{skip2}P s k i p 2 );
- 选择β \beta β计算ROUGE-S。
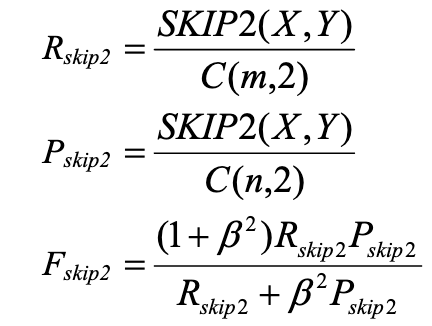
例如句子 “I have a cat” 的 Skip-bigram 包括 (I, have),(I, a),(I, cat),(have, a),(have, cat),(a, cat)。
其中C C C是组合函数,相比与ROUGE-L来说,ROUGE-S能捕捉所有有序的两个词,为了避免匹配一些相隔过长而无意义的词比如”the the”,可以设置最长间隔,此时相应的分母也要按照这个最长距离来计算。
ROUGE指标的计算可以采用rouge工具包自带的功能函数Rouge()。输出结果包括ROUGE-1, ROUGE-2, ROUGE-L的值。
from rouge import Rouge
hypothesis = "the #### transcript is a written version of each day 's cnn student news program use this transcript to he lp students with reading comprehension and vocabulary use the weekly newsquiz to test your knowledge of storie s you saw on cnn student news"
reference = "this page includes the show transcript use the transcript to help students with reading comprehension and vocabulary at the bottom of the page , comment for a chance to be mentioned on cnn student news . you must be a teac her or a student age # # or older to request a mention on the cnn student news roll call . the weekly newsquiz tests students ' knowledge of even ts in the news"
rouge = Rouge()
scores = rouge.get_scores(hypothesis, reference)
3. METEOR
评估标准:设立惩罚因子计算F1-score,越大越好。
METEOR同时考虑了基于整个语料库上的精确率和召回率,考虑了句子流畅性,同义词对语义的影响。缺点和BLEU一样,对长度比较敏感。
METEOR扩展了BLEU有关” 共现“的概念,提出了三个统计共现次数的模块:
- 一是”绝对”模块(”exact” module),即统计待测译文与参考译文中绝对一致单词的共现次数;
- 二是”波特词干”模块(porter stem module),即基于波特词干算法计算待测译文与参考译文中词干相同的词语”变体”的共现次数,如happy和happiness将在此模块中被认定为共现词;
- 三是”WN同义词”模块(WN synonymy module),即基于WordNet词典匹配待测译文与参考译文中的同义词,计入共现次数,如sunlight与sunshine。
METEOR计算方法:设立基于词序变化的惩罚机制,基于共现次数计算召回率、精确率和F值,最后结合惩罚得到METEOR值。
- 计算unigram下的精确率P和召回率R(计算方法与BLEU、ROUGE类似),得到调和均值F值。
- 使用chunk概念计算惩罚因子:候选译文和参考译文能够对齐的、空间排列上连续的单词形成一个 chunk。chunk 的数目越少意味着每个 chunk 的平均长度越长,也就是说候选译文和参考译文的语序越一致。
- METEOR值计算为对应最佳候选译文和参考译文之间的精确率和召回率的调和平均。
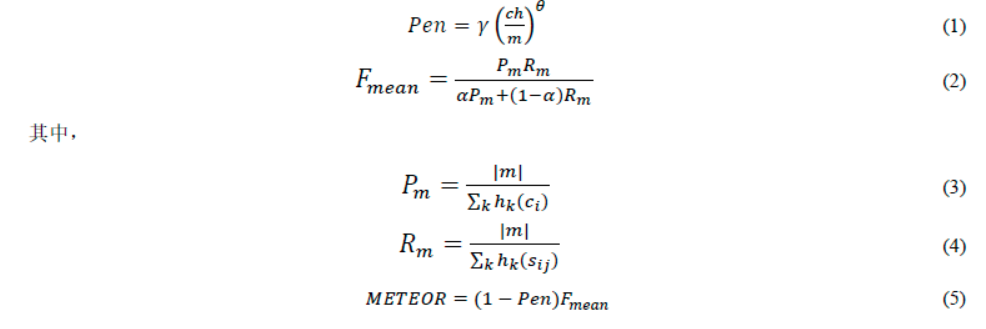
METEOR指标的计算仍然采用NLTK工具包自带的功能函数meteor_score()。
from nltk.translate.meteor_score import meteor_score
reference1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'that', 'ensures', 'that', 'the', 'military', 'will', 'forever', 'heed', 'Party', 'commands']
reference2 = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the', 'army', 'always', 'to', 'heed', 'the', 'directions', 'of', 'the', 'party']
hypothesis1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which', 'ensures', 'that', 'the', 'military', 'always', 'obeys', 'the', 'commands', 'of', 'the', 'party']
score = meteor_score([reference1, reference2], hypothesis1)
print(score)
4. 参考
ROUGE: A Package for Automatic Evaluation of Summaries
《Meteor: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments》
在NLP当中,不同的评价指标,BLEU, METEOR, ROUGE和CIDEr的逻辑意义?
BLEU,ROUGE,METEOR,ROUGE-浅述自然语言处理机器翻译常用评价度量
【NLG】(二)文本生成评价指标—— METEOR原理及代码示例
https://www.nltk.org/api/nltk.translate.meteor_score.html
https://www.nltk.org/api/nltk.translate.bleu_score.html#module-nltk.translate.bleu_score
https://pypi.org/project/rouge/
https://baijiahao.baidu.com/s?id=1655137746278637231&wfr=spider&for=pc
欢迎各位关注我的个人公众号: HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。
Original: https://blog.csdn.net/u012744245/article/details/123589005
Author: 快乐小码农
Title: NLP文本生成的评价指标有什么?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530452/
转载文章受原作者版权保护。转载请注明原作者出处!