

我之前做实体标注项目使用过 标注精灵、 BRAT、 YEDDA、 DeepDive等标注工具,这些工具虽然可以满足实体标注需求,但安装过程复杂、英文界面、有时会有卡顿,对标注人员都很不友好。
而我目前要做的任务需要 能同时对数据进行实体标注和文本分类标注,以上提到的工具都很难满足,分开标注效率又太低。于是我找到了 rasa-nlu-trainer标注工具, 免费、无需安装、无需注册、操作快捷且能同时标注,真是神器!今天就分享给大家。
1 进入标注工具
地址: https://rasahq.github.io/rasa-nlu-trainer,大家直接复制链接就可进入, 无需注册登录,十分方便,进入网页后可看到示例:


intent列是为文本进行分类标注,点开最左端的小加号后可为句子中的实体进行标注。
接下来为大家示范从导入数据到导出标注数据的整个过程,前方高能!
; 2 导入待标注数据
此工具要求的导入文件格式为 josn,我们可直接点击网页右上角 Download进行下载,查看需要的数据格式(为方便演示,我只截取了两条)。

可以看到它是字典嵌套列表的格式,我们主要构造红框内的内容,然后将外层字典的关键字加上即可。
以下为制作数据集的模板,大家可直接复制使用:
第一步
将待标注数据整理成一个列表(也可由txt直接构造,本文以列表做示范):
moive = ['扬名立万很好看。',
'沙丘差评!',
'疯狂的石头太好看啦!',
'我和我的父辈还行吧',
'长津湖666']
第二步
编写函数将其转换为固定的传入格式:
def listToJosn(li):
result = []
for text in li:
item = {
'text': text,
'intent':'',
'entities': []
}
result.append(item)
dic = {"rasa_nlu_data":
{"common_examples": result}}
return dic
res = listToJosn(moive)
res
第三步
然后结果转为 josn文件:
import json
with open("a.json", "w") as f:
f.write(json.dumps(res, ensure_ascii=False, indent=4))
打开查看当前目录下的 a.josn文件,已经转换成功:

第四步
点击界面右上角 Click to Upload上传文件:

显示5条数据已经上传成功!

; 3 文本分类标注
- 可自定义标签名称
- 已定义的名称在下次标注时可自动弹出,操作方便快捷
我们定义1为好评,2为差评,3为中性。界面简洁,操作快捷,演示如下:

- 还可以对文本进行关键字筛选。比如我们将带有”好看”的文本筛出,可对这类句子统一标注。

同样的,也可以对标签进行筛选。将
标签1的样本进行筛选查看。

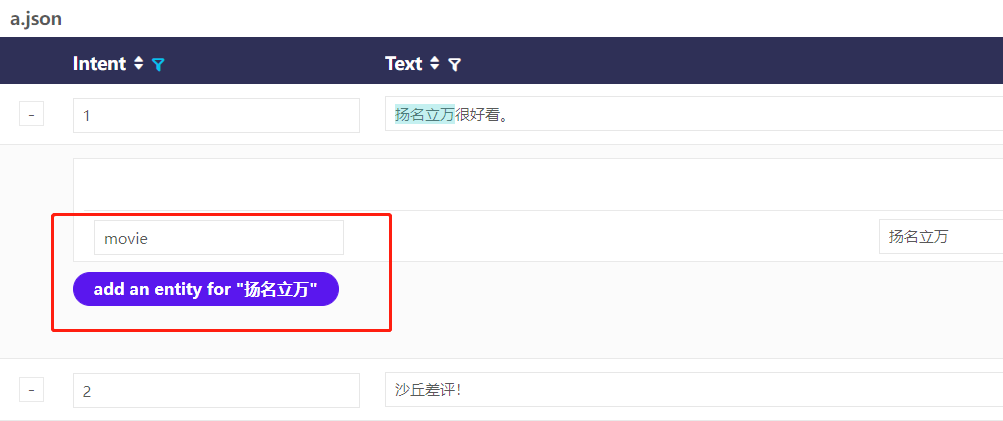
4 实体识别标注
- 实体标注可以与文本标注同时进行
- 可以自定义标注类型,已定义的标签在下次标注时可自动弹出方便选择
- 可以实体重叠标注。比如我们不仅需要对”疯狂的石头”进行标注,也要对”石头”也进行标注:
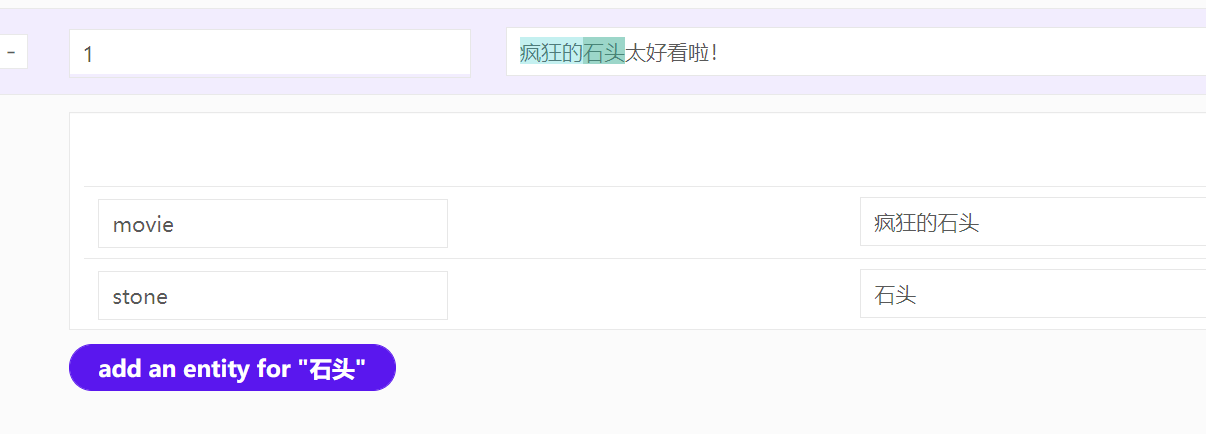
最后标注完,标注的实体有一个底色:

; 5 对结果进行导出
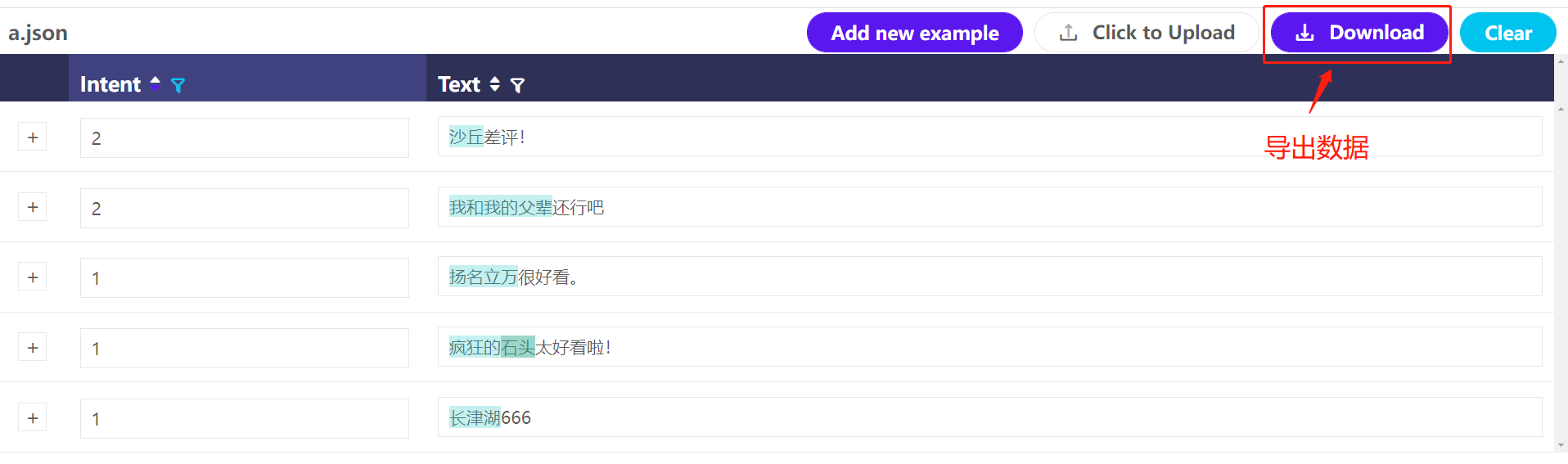
标注完成后,直接按右上角的 download就可以将文件进行导出。

导出结果中
text为原数据, intent中为文本标签, entities中为实体标签及标签在句子的索引,非常全面!
之后我们使用 Python将其改造成模型适用的数据集,就可以进行训练啦。
6 赶紧试试吧!
rasa-nlu-trainer界面简易但不失功能性,可以同时对数据进行文本与实体标签的标注,操作简单实用,是我用过标注工具中最好用的一款,强烈安利给大家!
Original: https://blog.csdn.net/Antai_ZHU/article/details/121919384
Author: 有温度的算法
Title: NLP标注神器:可同时对文本与实体进行标注
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530418/
转载文章受原作者版权保护。转载请注明原作者出处!