

1. NLP任务的基本流程


; 1.1 文本预处理
文本清理:去除文本中无效的字符,比如网址、图片地址,无效的字符、空白、乱码等。
标准化:主要是将不同的「形式」统一化。比如英文大小写标准化,数字标准化,英文缩写标准化,日期格式标准化,时间格式标准化,计量单位标准化,标点符号标准化等。
纠错:识别文本中的错误,包括拼写错误、词法错误、句法错误、语义错误等。
改写:包括转换和扩展。转换是将输入的文本或 Query 转换为同等语义的另一种形式,比如拼音(或简拼)转为对应的中文。扩展主要是讲和输入文本相关的内容一并作为输入。常用在搜索领域。
1.2 Tokenizing(分词)
1.3 构造数据
1.4 文本特征
one-hot
TF-IDF
Embedding:
word2vec
它将一个词表示为一个固定维度大小的稠密向量。
通过上下文自动学习到表征向量
模型训练得到结果就是词向量Skip-Gram Model:中心词预测周围词
CBOW:周围词预测中心词
步骤:
1.获取大量文本数据(例如所有维基百科内容)
2.建立一个可以沿文本滑动的窗(例如一个窗里包含三个单词)
3 利用这样的滑动窗就能为训练模型生成大量样本数据。
当这个窗口沿着文本滑动时,我们就能(真实地)生成一套用于模型训练的数据集。
【举例解释word2vec原理】
若一共有5000个单词:
训练目的:能表征5000个单词的5000个向量,这些向量的维度都是 【一个可调整的参数 * 1】(这里设为128),则为128 * 1,我们要得到5000个 128 *1 的向量
注:这个可调整参数 = 我们想定义的维度数,我们想用多少维度的向量去表示每个单词
- 首先,对这5000个单词每个都用 5000 * 1 的向量表示(one-hot编码)
- 输入层到隐藏层:
W为 5000 * 128
h = W转置 * X
128 * 1 = (128 * 5000) * (5000 * 1)注:
若X的第k个位置为0,则 : W的第k行 = h
我们需不断更新W
- 隐藏层到输出层:
W’为128 * 5000
u = W’转置 * h
5000 * 1 = (5000 * 128) * (128 * 1)
此时,对 u(5000*1) 做softmax函数运算, 得到另一个 5000 * 1 的向量, 这5000个数分别对应,5000个单词 ,是输入词X的上下文的概率
【公式解释word2vec】
1 Continuous Bag-of-Word Model
1.1 One word Context
输入一个周围词(one context word),预测一个中心词(one target word)
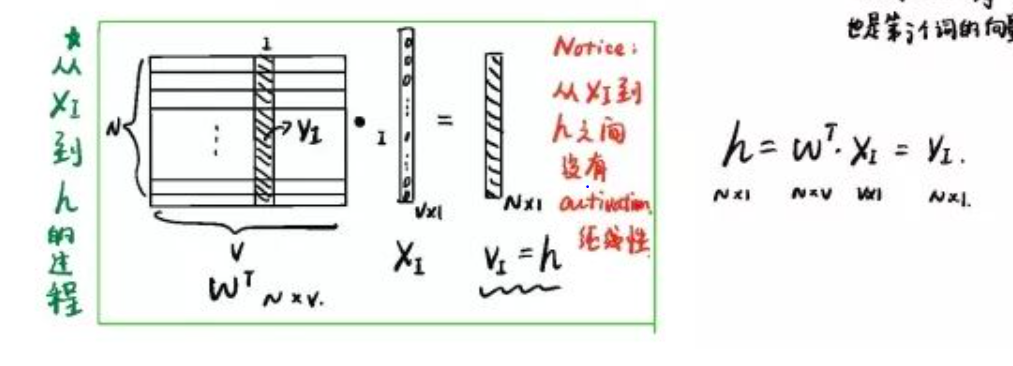
W矩阵的第k行 = h向量 (N维),我们称为 输入向量(input vector)
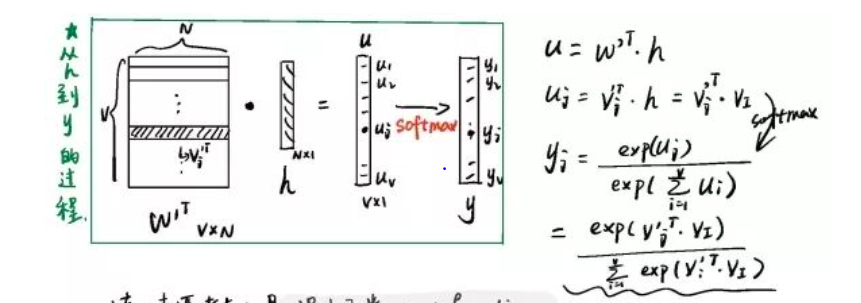
通过权重矩阵W’,我们可以为词表中的每一个单词都计算出一个得分uj
uj = W’矩阵的第j列 * h
我们称W’矩阵的第j列 (N维)为X的 输出向量(output vector)

需要将u->y,转换成能代表概率的表示形式,用到softmax函数
希望y越接近目标词越好,即yi越大越接近于1越好
用交叉熵损失函数计算损失函数,损失函数为- log(yj),我们的目的是让损失函数最小
使用梯度下降法更新W和W’
word2vec Parameter Learning Explained》论文学习笔记
; 基于机器学习的情感分析方法
用 带标签数据训练一个机器学习模型,将情感分析看作一个 二元分类问题。模型训练完成后,将待测试数据输入到训练好的模型中,模型会根据训练好的参数给出待测试数据的标签。
二元分类又称逻辑回归,是将一组样本划分到两个不同类别的分类方式。
二元分类的准确率、精确率、召回率
步骤:
- 文本数据的预处理
分词,
去除停用词(介词、标点符号、虚词…)
标签处理 - 文本到向量空间的转换
VSM:将句子–>模型可识别的内部表现形式
词袋模型
TF-IDF模型
- 分类器的训练
- 对待测文本的预测
Original: https://blog.csdn.net/qq_45416797/article/details/122861428
Author: Peanut今年是冠军
Title: NLP之文本情感分析(word2vec)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530185/
转载文章受原作者版权保护。转载请注明原作者出处!