

本文转载自公众号 ” 夕小瑶的卖萌屋“,专业带逛互联网算法圈的神操作
—–》我是传送门
关注后,回复以下口令:
回复【789】 :领取深度学习全栈手册(含NLP、CV海量综述、必刷论文解读)
回复【入群】:加入卖萌屋深度学习/NLP/CV/搜广推等方向的技术交流与内推社群(大V、顶会审稿人云集)
回复【0511】:领取算法岗面试手册(刷offer神器)
回复【0424】:领取刷论文神器(挖掘每日、每月必刷重磅论文)
文 | 小轶
今天给大家介绍一篇 ACL’22 的论文,来自清华大学刘知远老师组。本文解决的问题是 如何在预训练语言模型中引入任务所需的实体知识。此前常见的解决方法大致可以分为两种。
一种是在领域相关的语料上再做 further pretraining,比如 BioBERT。这种方法的缺点主要在于需要大量的额外训练,V100 上的训练时长可达数千小时。
另一种是直接引入知识图谱,比如 ERNIE。本文则认为:使得预训练模型具备实体知识,可以不完全依赖于引入外部知识图谱。已经有许多相关工作证明 预训练模型自身就具备存储知识的能力,我们需要的只是一种 调用出模型知识存储的方法。于是本文就提出了一种轻量的方法 PELT,能够非常简单有效的达到引入实体知识的效果。
论文标题:
A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models
论文链接:
https://arxiv.org/pdf/2202.13392.pdf
代码链接:
https://github.com/thunlp/PELT


本文方法的核心在于 如何获取一个好的实体嵌入(entity embedding),使得这个中包含该实体必要的相关知识。获得实体嵌入后,在下游任务使用预训练模型时,只需要在输入中该实体出现的位置加入其相应的 embedding,即可达到引入相关知识的效果。
接下来我们逐步看一下,本文的方法是如何构造实体嵌入的,以及如何在使用预训练模型时加入实体嵌入。最后,简单从理论角度分析一下本文方法的合理性。
构建实体嵌入
假定我们需要在某个下游任务使用某个预训练语言模型,而该下游任务中可能会出现一些其所在领域所特有的实体。我们当前的目标就是:为这些实体构建一个高质量的实体嵌入。
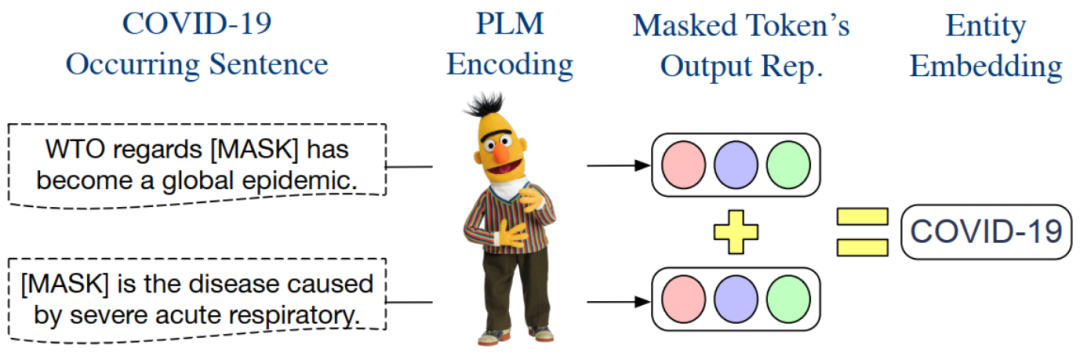
▲PELT 构建实体嵌入信息的过程
本文获取实体嵌入的方法非常简单。上图以实体 COVID-19 为例,说明了构建其嵌入的过程:
- 找到语料库中 所有出现 COVID-19 的句子集合 (这个语料库是 domain-specific 的)
- 把这些句子中出现 COVID-19 的位置 MASK 掉。
- 保留预训练语言模型把 MASK 位置对应的 output 表示向量,记为 ()
- 最后得到 实体嵌入表示如下:
其中, 是一个常数。原文中说,这个常数 具体取什么值对于结果影响不大(” has little effect on the input feature of the encoder in use“)。
实际操作时,作者将所有实体嵌入的长度都设置为,即。然后在实验中,尝试了多个 的值(=1,2,..,10),看哪一个在下游任务上效果好就用哪个。
在预训练模型中融入实体知识
接下来的问题就是,在得到实体嵌入后,在预训练模型做下游任务时使用它。方法也非常简单。
加入某个样本输入中出现了实体。还是假设该实体为 COVID-19,然后原始输入样本为:
Most people with COVID-19 have a dry…
在本文所提出的方法中,我们只需要在那个实体后面 加个括号,括号中重复一遍该实体。
Most people with COVID-19( COVID-19) have a dry…
在映射到 embedding layer 的时候,不在括号里的实体 _COVID-19_采用普通的 词嵌入处理方式(切成 subword,然后映射到预训练模型所学的 word embedding);而括号中的实体 COVID-19 则 映射为相应的实体嵌入。
方法合理性的理论支持
原文有从理论分析的角度解释所提出方法的合理性。整个证明过程也比较简单,可以一看(不过我其实还没太想清楚这个证明过程是否足够完善…)。
假设我们把某个实体加入了预训练模型的原有词表中。如果我们用预训练任务 MLM 来学习它的实体嵌入 ,它的损失函数如下所示:
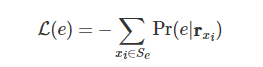
其中,是语料库中所有出现该实体的句子, 为实体被 MASK 后对应位置的输出表示向量。这个公式可以进一步展开,变为:
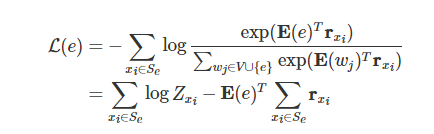
其中,。
然后我们分析一下减号前后的两项。前一项中的 是对项求和,所以实体嵌入的变化对前一项的值影响很小,可以将这一项视作一个常数。因此,如果要让损失 尽可能小,我们 只需要让后一项为一个尽量大的正数就行了。于是我们可以将设置为:
其中, 是一个常数。这样就能使得后一项始终是一个正数。至于 ,具体取什么值,原文里的说法是:由于输入给 Transformer 编码器时会过一层 layer normalization,所以||的长度变化影响不大。所以作者就直接把||当做超参数来处理了。

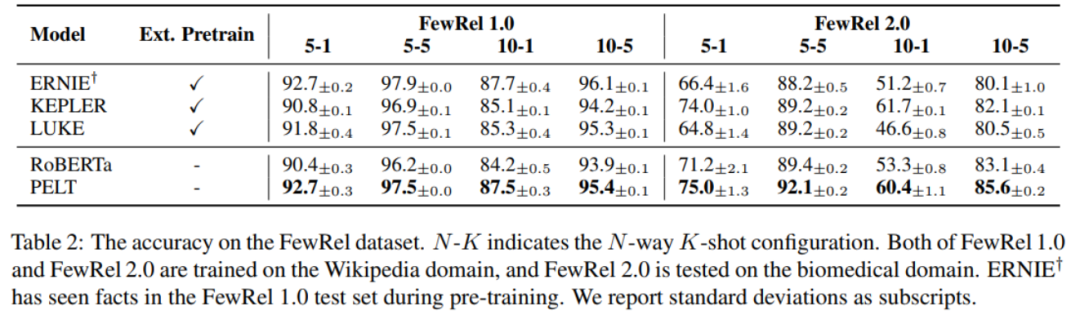
比较表格最后两行可以看到,在 RoBERTa 上采用了本文方法后,获得了非常明显的提升。另外,和第一行的 ERNIE 相比,在一个数据集上效果相当,在另一个数据集上本文方法明显占优。值得注意的是,ERNIE 在模型使用时是引入外部知识图谱的,而本文方法没有。

本文提出了一种非常简单有效的方法,使得预训练模型中融入实体知识。并且,相关代码已经开源,大家不妨一试。
本文转载自公众号 ” 夕小瑶的卖萌屋“,专业带逛互联网算法圈的神操作
—–》我是传送门
关注后,回复以下口令:
回复【789】 :领取深度学习全栈手册(含NLP、CV海量综述、必刷论文解读)
回复【入群】:加入卖萌屋深度学习/NLP/CV/搜广推等方向的技术交流与内推社群(大V、顶会审稿人云集)
回复【0511】:领取算法岗面试手册(刷offer神器)
回复【0424】:领取刷论文神器(挖掘每日、每月必刷重磅论文)
是小轶,不是小秩!更不要叫小铁!高冷的形象是需要大家共同维护的!作为成熟的大人,正在勤俭节约、兢兢业业,为成为一名合格的(但是仍然发量充足的)PhD而努力着。日常沉迷对话系统。说不定,正在和你对话的,并不是不是真正的小轶哦(!?)
“高冷?那是站在冰箱顶端的意思啦。” ——白鹡鸰
作品推荐:

1.
2.
3.
加入卖萌屋NLP、CV与搜推广与求职讨论群
后台回复关键词【 顶会】
获取ACL、CIKM等各大顶会论文集!Original: https://blog.csdn.net/xixiaoyaoww/article/details/124013531
Author: 夕小瑶
Title: 预训练模型对实体的表示能力差?一个简单有效的解法来了(开源)


原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530161/
转载文章受原作者版权保护。转载请注明原作者出处!