

基于spacy以及tf-idf向量化文本
第一题
问题:根据tf-idf的计算方法编写一个自定义的计算tf-idf的方法(推荐包装成函数或者类)
封装成函数的代码如下:
def tf_idf(fenci,stop_words,tongci):
result2 = []
for i in range(len(data)):
res = []
for j in tongci[i].keys():
outdic = {}
tf = tongci[i][str(j)]/len(fenci[i])
idf = math.log(len(stop_words)/(tongci[i][str(j)]+1))
tfidf = tf*idf
outdic = {j:tfidf}
res.append(outdic)
sorted_word = sorted(res, key=lambda r: next(iter(r.values())),reverse=1)
result2.append(sorted_word)
return result2
这里要介绍一下 TF、 IDF的含义:
TF(Term Frequency)表示一个词在文档中出现的词频。
TF = (某个词语在文档中出现的次数)/ (文档中词语的总数)
在此次作业当中tongci[i][‘str(j)’]表示的是去掉停用词之后,该词在该篇新闻文本中出现的次数,而len(fenci[i])表示的是该篇新闻的总长度。 TF公式表示如下:
T F i j = n i j ∑ k n k j TF_{ij } = \frac{n_{ij}}{\sum_{k}n_{kj}}T F i j =∑k n k j n i j
IDF(反向文档频率) 用于表示 单词在文档中的重要性。通过计算包含某个词语的文档数文档总数比的倒数文档总数除以包
含该单词的文档数量),然后再取对数,可以量化 该单词在所有文
档中的常见程度
IDF(t) = lg(文档的总数量/存在某个词语的文档总量)
本次作业的文档的总数量一共是85,所以直接用len(stop_words)的长度,存在某个词语的文档总量是tongci[i][str(j)]+1,其中为了避免除以0值实现不了,所以加上1。 IDF的公式表示如下:
I D F i = l o g ∣ D ∣ 1 + ∣ j : t i ϵ d j ∣ IDF_{i} = log\frac{|D|}{1+|j:t_{i} \epsilon d_{j}|}I D F i =l o g 1 +∣j :t i ϵd j ∣∣D ∣
TF-IDF倾向于过滤掉常见的词语,保留重要的词语
T F − I D F = T F ∗ I D F TF-IDF = TF*IDF T F −I D F =T F ∗I D F
第二题
使用文本数据的test.txt(每一行为一条新闻数据),使用spacy(数据预处理)和自定义的tf-idf函数(词袋模型)句向量化(输出结果可以自定义结构,但需要在pdf中进行说明),并输出成resut.txt提交。
实现代码
import spacy
import math
from collections import Counter
def read(path):
f = open(path,encoding="utf8")
data = []
for line in f.readlines():
data.append(line)
return data
def spacy_text(data):
spacy_en = spacy.load('zh_core_web_sm')
result = []
for i in data:
result.append(spacy_en(i))
fenci = []
for j in range(len(result)):
result1 = []
for i in result[j]:
result1.append(i.text)
fenci.append(result1)
stop_words = []
for i in range(len(fenci)):
result3 = []
for j in fenci[i]:
words = spacy_en.vocab[j]
if words.is_stop == False:
result3.append(j)
stop_words.append(result3)
tongci = []
for i in range(len(stop_words)):
count = Counter(stop_words[i])
tongci.append(count)
return fenci,stop_words,tongci
def tf_idf(fenci,stop_words,tongci):
result2 = []
for i in range(len(data)):
res = []
for j in tongci[i].keys():
outdic = {}
tf = tongci[i][str(j)]/len(fenci[i])
idf = math.log(len(stop_words)/(tongci[i][str(j)]+1))
tfidf = tf*idf
outdic = {j:tfidf}
res.append(outdic)
sorted_word = sorted(res, key=lambda r: next(iter(r.values())),reverse=1)
result2.append(sorted_word)
return result2
if __name__ == '__main__':
path = "E://大三下//自然语言处理//作业//第四章nlp作业//test.txt"
data = read(path)
fenci,stop_words,tongci = spacy_text(data)
result2 = tf_idf(fenci,stop_words,tongci)
for i in range(len(result2 )):
with open("E://大三下//自然语言处理//code//resut.txt",'a',encoding='utf8') as f:
f.write(str(result2 [i]))
f.close()
本次作业一共对85个新闻内容利用spacy(数据预处理)和tf-idf函数向量化,每一行是一条新闻内容。所以在对数据进行读入的时候就将其保存为列表的形式,后续的分词以及去除停用词,都要将每个新闻的词语分隔开,这样才会更好的判断该新闻的关键词。所以使用嵌套列表的形式,将85个新闻文本分隔开。
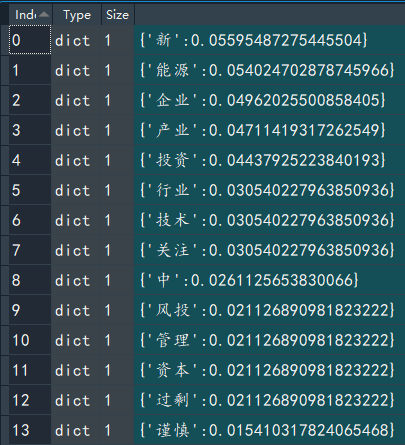
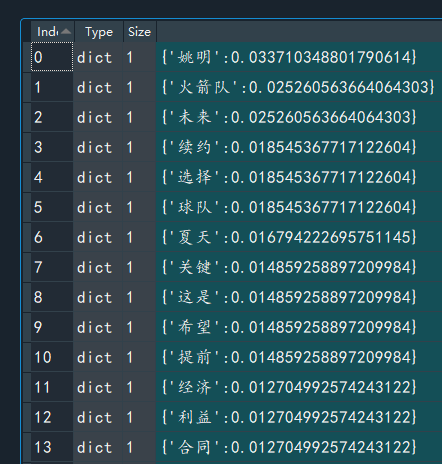
我们以第一个和第二个新闻文本为例,其最后计算得到的tf-idf的值,经过排序结果如下图所示:
第一个新闻文档:

第六十个新闻文档:
最后输出的txt文件有点杂,只可以根据代码找到新闻的长度来确定一则新闻tf-idf值的范围。
参考文献:
1、https://www.cnblogs.com/panchuangai/archive/2020/09/17/13688528.html
2、https://zhuanlan.zhihu.com/p/70314114
Original: https://blog.csdn.net/qq_47712110/article/details/123764154
Author: Love. Rover
Title: nlp第四章作业
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530113/
转载文章受原作者版权保护。转载请注明原作者出处!