

前言
Maixhub 提供模型训练功能和模型分享功能, 只需要准备好需要训练的数据集, 不需要搭建训练环境和代码, 上传训练数据即可快速训练出模型
目前 Maixhub 支持分类模型 和 目标检测模型的训练。
你需要做的:
1.确定目标, 是分类还是检测
2.根据使用说明制作符合要求的数据集
3.上传数据集等待云端自动训练
4.训练完成, 结果会通过邮件进行通知, 不管是成功还是失败,都会有邮件通知,里面有详细的任务信息和结果文件
Maixhub 模型训练平台使用说明
Ⅰ.功能介绍
Maixhub 模型训练平台帮助大家快速训练想要的 AI模型, 不需要任何训练环境搭建和代码运行, 只需要选择训练类型,上传(标注)数据集, Maixhub就会自动进行训练,并将结果通过邮件发送给您。
生成的模型提供给 MaixPy 使用,一个运行在一不到¥100算力却1TOPS的开发板上的开发套件, 使用Mcropython语法编写程序
目前提供两种训练: 目标分类与 目标检测
目标分类: 识别图片所属的种类, 比如图中是苹果还是杯子, 没有坐标。 如下图,识别到了苹果,是苹果的概率为0.8


目标检测: 检测图片中物体的位置, 并且输出这个物体的坐标和物体大小(即框出认识的物体)。 如下图, 识别到了苹果, 并且框出了位置, 是苹果的概率为0.8

; Ⅱ.确定方案
1)首先确定要训练哪种模型
在上面支持的模型中选择一个,如果不需要检测物体坐标, 用目标分类, 需要坐标则目标检测,
即:
需要坐标不需要坐标目标分类目标检测
两者处理数据要做的工作和格式都不一样, 后者会复杂很多。
第一次使用强烈建议先使用目标分类成功走一遍流程。
2)确定分类。 包括分类数量, 具体分类
比如这里以识别红色小球和玩具为例:

所以共两个分类: ball 和 toy, 我们也称之为标签(label),
注意!!! 分类名(标签/label)只能使用英文字符和下划线。
; 3)确定分辨率
图片的分辨率也十分重要,不管是在采集、训练,还是使用时, 都需要十分注意, 稍不注意,模型可能就无法使用或者识别精度低。
以下为Maixhub目前支持的分辨率,其它分辨率将会训练失败(使用推荐分辨率识别准确率更高):
目标分类: 224×224(推荐)
目标检测: 224×224(推荐), 240×240
4)确定采集数据集(这里就是所有图片的统称)数量
即确定好每个分类的图片数量,方便后面采集图片快速准确进行,
另外也要满足 Maixhub 的要求:
目标分类: 每类图片数量不低于40张,比如采集 200 张。
目标检测: 每类图片数量不低于100张, 比如采集200张。
5)注意
最后上传的zip文件不能超过20MiB
Ⅲ.采集照片
确定了方案,就可以采集照片了, 目标是采集目标分辨率的照片, 以下都以224×224为例, 将他们按照目录进行分类收集, 比如 采集整理好的目录结构:
|—-ball
| |
| —0.jpg
| |
| —1.jpg
| |
| —2.jpg
|—-toy
|
—0.jpg
|
—1.jpg
采集照片有以下几种方式:
- 使用开发板采集到SD卡, 直接采集成需要的分辨率 (推荐)。
- 手机拍照, 然后使用预处理工具处理成需要的分辨率, 注意, 处理完后一定要手动检查数据是否符合要求, 不然可能影响训练精准度。
- 使用现成的图片, 使用预处理工具处理成需要的分辨率, 注意, 处理完后一定要手动检查数据是否符合要求, 不然可能影响训练精准度。
1)使用开发板进行数据采集
- 使用 这个脚本进行采集图片。
- 按照图片采集脚本使用说明 采集图片到SD卡。
- 将SD卡中的图片拷贝到电脑, 整理成上面的目录结构, 所有图片的分辨率为224×224。
- 注意 SD卡需要硬件支持SPI通信, 并使用MBR(msdos)分区方案,并格式化为FAT32格式。
2)使用其它图片
整理成上面的目录结构, 最后所有图片分辨率已经是224×224, 如果不是, 后面还需要处理。
Ⅳ.预处理数据集为目标分辨率
- 如果所有图片已经都是224×224的分辨率,本步骤跳过。
- 如果有图片不是224×224, 那么需要先把所有图片处理成224×224, 稍后Maixhub会推出预处理工具。
Ⅴ.标注数据集
目标分类目标检测不需要标注数据集需要标注数据集
所以做目标分类项目请跳至 下一标题 VI 打包数据集。
对于目标检测要注意, 一定要先保证分辨率正确, 再标注。
标注有以下两种工具:
vott与 labelimg 点击下载链接开始下载,所需积分/C币: 0。
vott 使用方法:
- 创建项目, 这里比较麻烦的就是数据输入输出文件夹需要创建一个连接(connection)
- 然后左边导出设置, 选择TFRecord格式
- 标注数据
- 标注完成后需要手动点击导出按钮来导出TFRecord文件
- 结果文件目录结构, 注意tf_label_map.pbtxt是必须的,vott自动生成的, 不要手动修改
datasets
|
|—0.tfrecord
|—1.tfrecord
|—2.tfrecord
—tf_label_map.pbtxt
; labelimg使用方法
如下图, 选择图片目录, 以及存放(输出)目录,(左边PascalVOC格式不要改动)按下W按键后, 用鼠标框出图片中的物体, 并且给它给一个标签, 这里使用了ball作为标签(一张图中可以有多个物体)

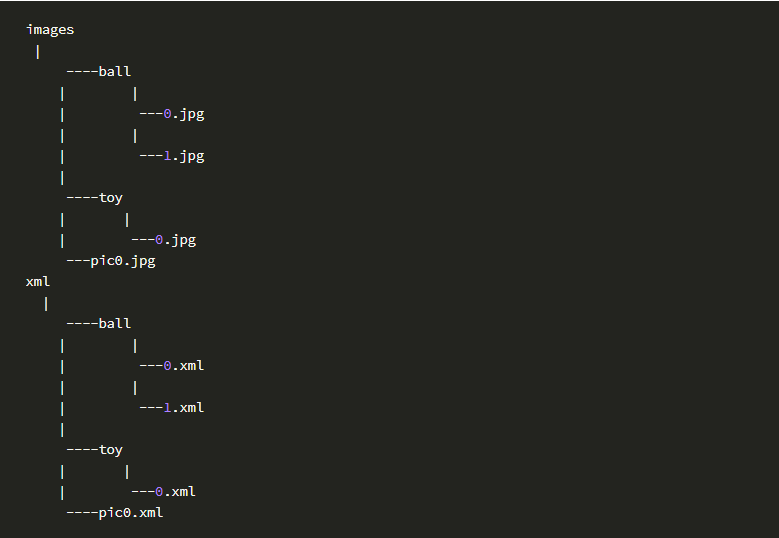
保存后会生成xml格式的文件(即PascalVOC格式),每张图对应一个xml文件
结果文件: 完成后目录结构和文件如下:

或者两级目录
Ⅵ. 打包数据集
注意:将前面处理好的数据集进行打包, 使用 zip压缩,暂不支持其它格式, 而且文件不要超过 20MiB
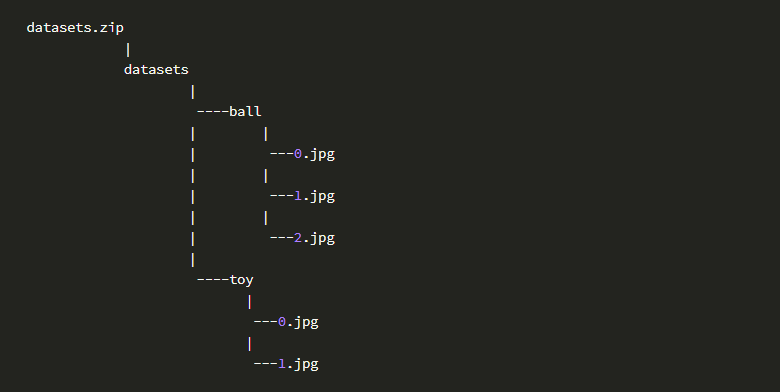
1)目标分类
对目标分类而言:一个文件夹一个分类, 分类名(标签/label)就是文件夹名,
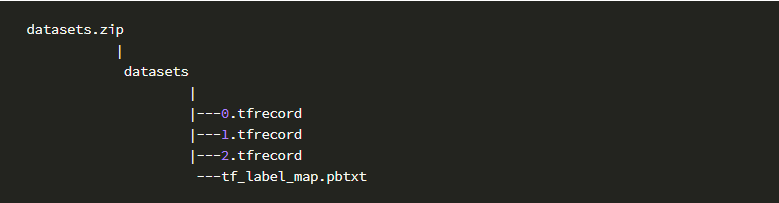
; 2)目标检测
a) vott的输出zip文件结构:
b) labelimg 的输出zip文件结构:
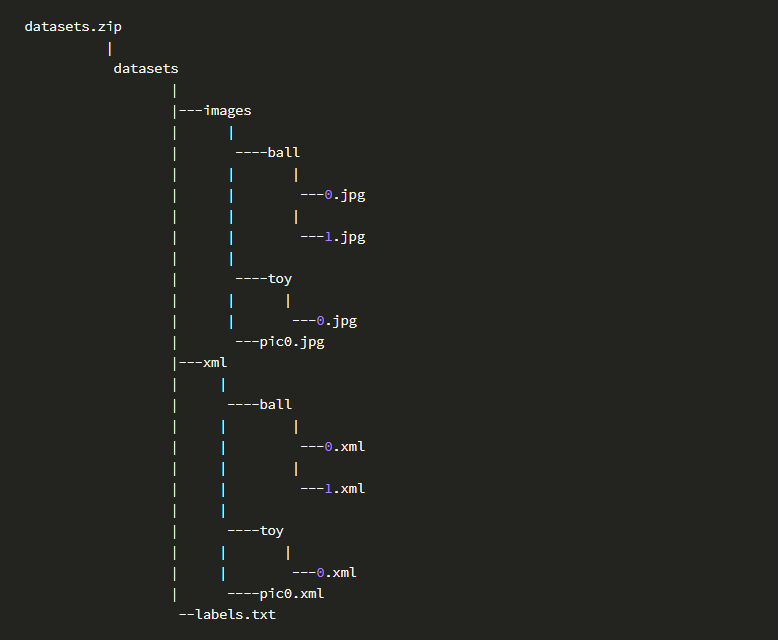
新建了一个labels.txt, 输入标记的标签, 每行一个, 比如这里:

这是必须的, 否则数据无效,然后目录结构如下:

或者两级输出:
Ⅶ.上传数据集进行训练
在线训练需要到 Maix Hub站 创建训练任务,接着
- 选择训练类型
- 填写邮箱地址, 用于接收结果, 包括成功(模型等文件) 和 失败 (失败原因)结果
- 如果要求填写机器码(不要求则跳过此步骤):
- 警告: 由于需要进行模型加密,运行key_gen.bin 将永远关闭 JTAG端口,并写入一次性 AES KEY,请确认对自己开发没有影响再进行烧录。(如果不使用JTAG调试开发或者仅使用MaixPy开发不影响)
- 获取机器码,参考Maix Bit K210人脸识别(内有获取机器码步骤)内容中的第一步。
- 上传打包好的zip格式的数据集
- 点击创建训练任务
Ⅷ. 训练结果及使用方法
训练结果(成功或者失败) 会发送到邮箱。 是一个zip压缩文件, 解压后仔细阅读README.txt,使用了中英文对使用方法进行了说明。默认是在有最新版固件1的情况下, 将结果文件全部拷贝到SD卡根目录, 断电插入开发板, 然后上电就可以运行了,如果需要将模型放到flash, 烧录方法参考MaixPy教程。
Original: https://blog.csdn.net/csdn_rp/article/details/119910963
Author: Z变换
Title: Maix Bit K210在线训练模型【保姆级教程】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530101/
转载文章受原作者版权保护。转载请注明原作者出处!