

现在pretrain- fine-tune模式已经成为了去解决NLP任务的常用方法,下面总结了一些常见的pretrain 方法
1. Next Token Predict
下一个token的预测,即给定一部分的seq,然后预测给定的seq的下一个token,AR(AUTO Regress)的模型,预训练的方式都是Next Token Predict,比如ELMO,ULMFIT,GPT,Megatron,Turing NLG,其中GPT,Megatron,Turing NLG使用self-Attention去实现的,但是做attention的时候,使用类似于MASK Multi- Attention方式
2. MLM
MASK Language Model,遮罩语言模型,是指将输入中的一部分的token进行MASK,然后再让模型进行predict,AE(AUTO Encoder)的模型,预训练方式大多都是使用这种方式进行预训练,比如BERT,RoBERT等
3.NSP
NSP:Next Sentence Predict,给定两个句子,让模型去预测这两个句子是否是上下文相连,BERT的另外一种预训练方法就是NSP,但是后来在Robert和XLNET等文章中被证明不是很有用
4. Whole Word Mask(WWM)
在BERT中,做MASK的时候,是随机MASK一些token,但是在WWM,是MASK整个词语,然后再让模型predict出来,例如:我爱中国,在BERT中mask是这样的,我 爱 [MASK] 国,但是在WWM中的mask是这样的,我 爱 [MASK] [MASK]
5. SOP
SOP:Sentence Order Predict,句子顺序预测,将句子的顺序进行打乱,让模型去预测句子的顺序,使得模型可以学习到句子级别的信息,在 ALBERT有使用
6. Name Entity Mask/Phrese Mask/Noun Mask
Name Entity MASK,是在输入中MASK句子中的实体,例如,中国的首都是北京,进行MASK后可能为:中 国 的 首 都 是 [MASK] [MASK],与WWM的不同之处在于,Name Entity MASK被MASK的是实体,而WWM被mask的是词语,而词语不一定是实体,Name Entity Mask在百度出的ERNIE(Enhanced Represent Through Knowledge Integration)论文中有用到
Phrase Mask:对输入的句子中mask整个短语
Noun Mask:对输入的句子中mask句子中的名词
7. Span Mask
Span Mask,对输入句子中的一部分连续的token进行mask,然后让模型预测被mask部分的信息,Span BERT就是运用该方法,如下图所示
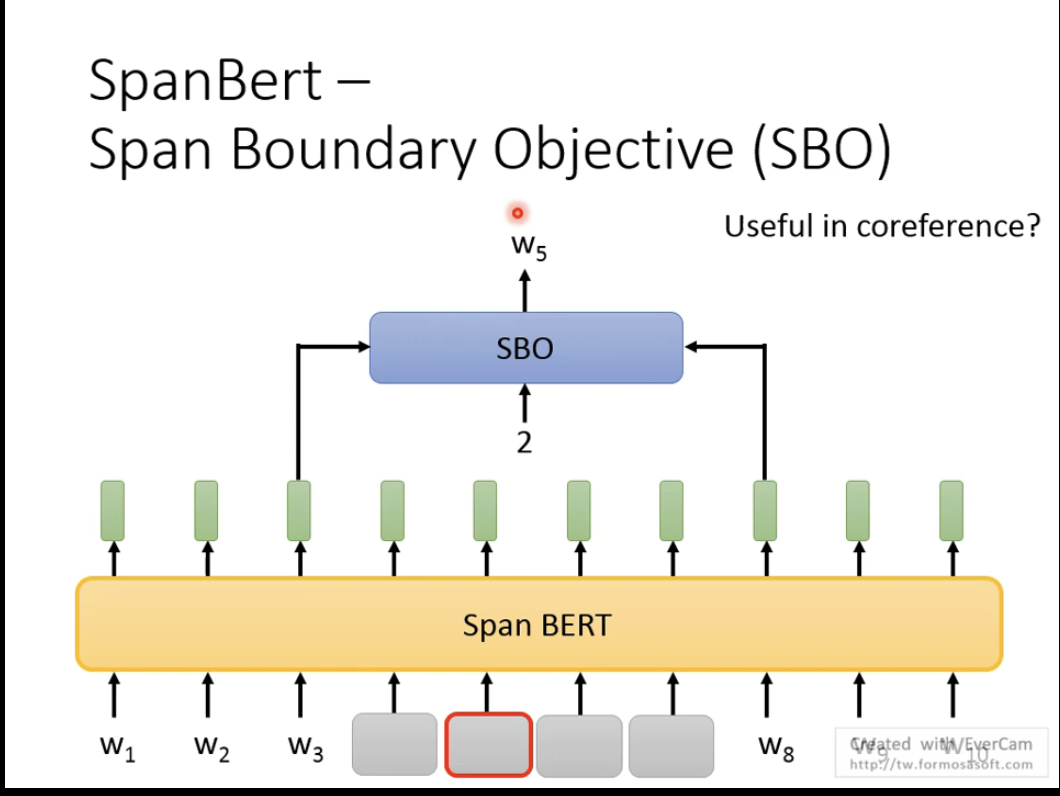

将w4-w7进行mask,输入到Span BERT中,然后再将w3和w8对应的embedding输入到SBO中,再给定一个2(表示被mask的范围的第2个token),让SBO预测出w5
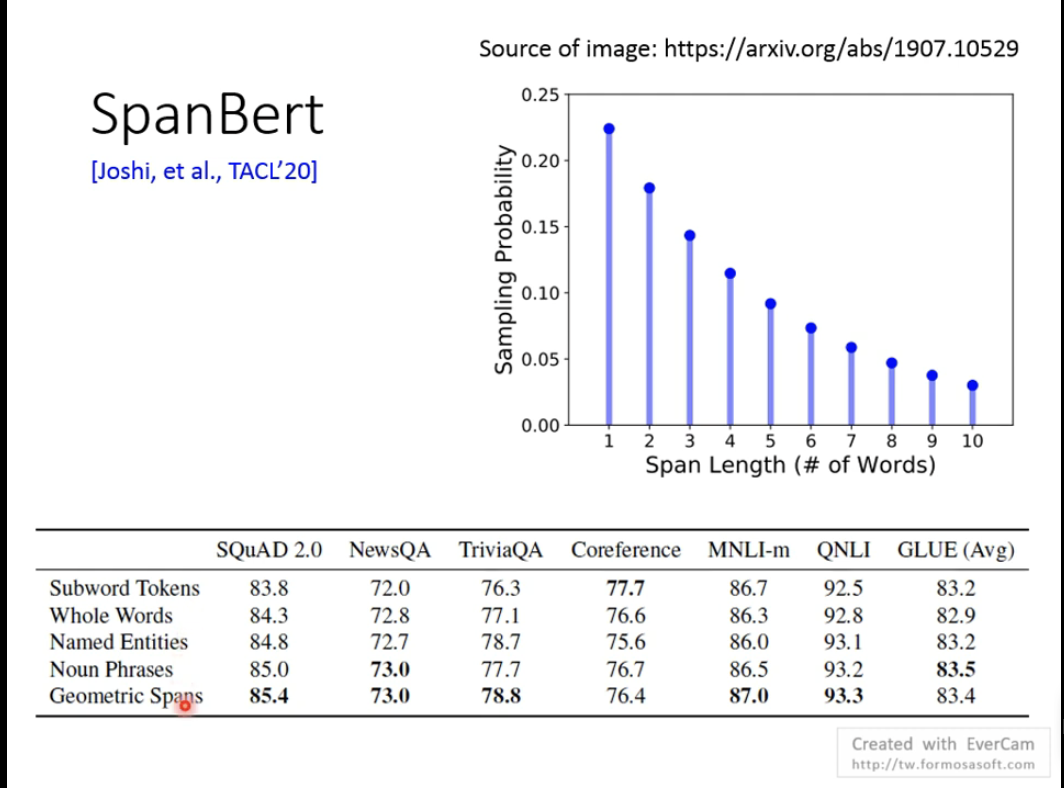
span Bert中,被mask的范围是按照一定的概率进行的,如下图中的span Length(# of words)所示
MASS(Mask Sequence to sequence pre-trainning)也有用到Span mask
8. pretrain by Translation
使用机器翻译的方法去预训练语言模型,如下图所示:
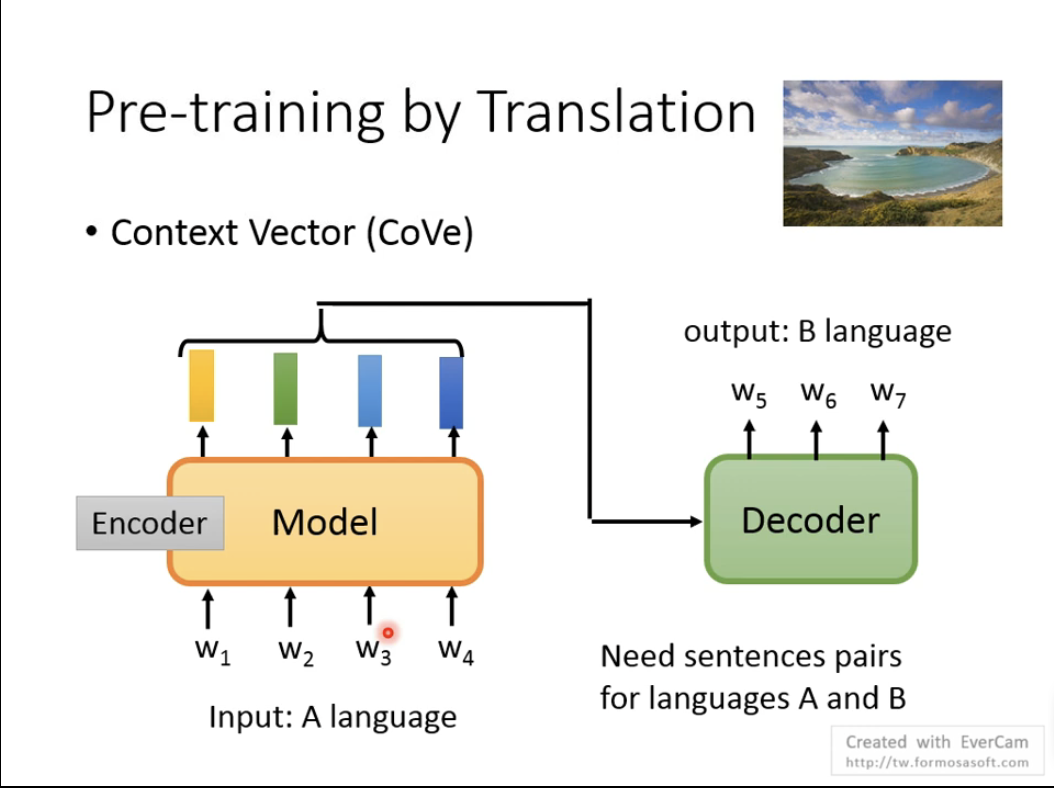
但是该方法需要大量的平行语料
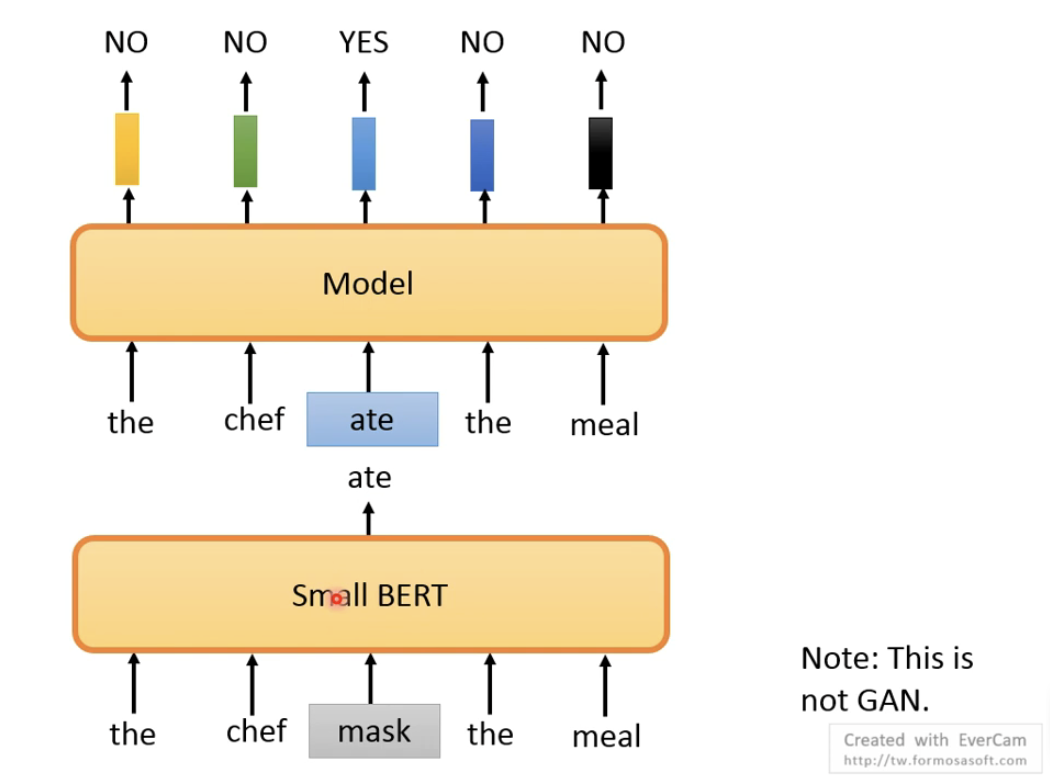
9. Replace Token Detection
先将一些token替换为其他token,然后让模型去预测哪些token是被替换,替换的token必须是符合语法规则的,因为不合符语法规则,模型很容易就判断出来,因此使用一个很小的BERT模型,将替换的token进行mask,然后再让small bert预测出来,再输入到ELECTRA,让模型去预测输入的token,哪些是被替换的,哪些是没有被替换的。
ELECTRA就是使用该方式,如下图所示
Original: https://blog.csdn.net/qq_28935065/article/details/123467182
Author: qq_28935065
Title: Language Model Pretrain 方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530017/
转载文章受原作者版权保护。转载请注明原作者出处!