

Redis Persistent Replication Sentinel Cluster的一些理解
我喜欢把工作中接触到的各种数据库叫做存储系统,笼统地说:Redis、Mysql、Kafka、ElasticSearch 都可以视为存储系统。各个存储系统在持久化刷盘策略、checkpoint机制、事务机制、数据的可靠性保证、高可用性保证的一些实现细节是深入理解背后存储原理的基础,把它们对比起来看,也能更好地理解。在写代码的时候,也许只需要了解它们提供的API就能完成大部分任务了,再加上强大的运维,也许也不用去关注什么安装、配置、维护这些”琐事”了, 但这样当数据量大,出现性能问题的时候,也常常一筹莫展。
由于在工作中使用到Redis的地方也比较简单,心血来潮的时候,看看某个具体的数据结构的底层实现原理,比如REDIS_ZSET,但是对存储原理、键过期机制、集群了解得少。读了《Redis 设计与实现》和官方Documentation后,感觉它背后处处体现着优化:Redis是单线程的(需要放到特定的场景下的讨论)、Redis数据类型的底层实现(object encoding)在数据量少的时候采用一种物理存储结构,在数据量大的时候自动转换成另一种存储结构、还有一些地方用到了为了效率而取近似的思想,这些都让Redis很美好。
Redis Persistent
先从Redis持久化说起,有两种:RDB和AOF。由于Redis是内存数据库,因此持久化机制比MySQL要”显眼”一些。其实对于所有的存储系统来说,持久化机制除了保证数据的可靠性(将数据写入磁盘这种永久性存储介质上)之外,它背后反映的是:磁盘与内存这两种存储介质的访问速度的差异。磁盘访问是百毫秒级、内存访问可能是百微秒级、cpu cache访问是百纳秒级。正是这种差异,在有限的内存下,刷盘策略就是保证:程序运行产生的数据已经在内存中了,什么时候,以什么样的频率将数据同步到(fsync)磁盘。对于Redis而言,程序所需的数据以某种数据结构保存在内存中了,那它需要的是:如何把内存中的数据”持久化”到磁盘?
RDB:执行save或者bgsave 命令生成rdb文件,或者以参数配置方式 save 60 10000这样就把所有的数据保存到磁盘上了。但是这样,还是存在很大的风险:执行了bgsave后,Client又写入一些数据到Redis Server上了怎么办?或者还没来得及执行bgsave Redis Server就挂了怎么办?

AOF:Client的向Server发送的写命令,Sever执行写命令后并将之追加到aof_buf 缓冲区,aof_buf缓冲区以某种方式将数据保存到AOF文件。什么方式呢?这就与appendfsync参数有关了。
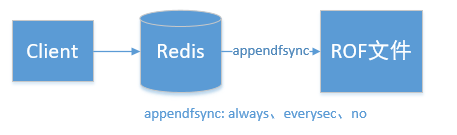
Redis 决定何时将 aof_buf 中的数据刷新到磁盘AOF文件上与MySQL的redo log buffer 刷盘参数 innodb_flush_log_at_trx_commit 以及ElasticSearch的Translog刷盘参数 index.translog.durability非常相似。本质上都是如何平衡效率和可靠性二者之间的矛盾:
怎样保证一条数据也不丢失呢?Client写入一条数据,我就刷一次磁盘。(这就是可靠性问题)
写一次就就fsync同步磁盘,影响Client写入速度。(这就是效率问题,效率响应吞吐量和响应时间)
RDB和AOF的区别是:
- RDB保存的是数据的内容(键值对),而AOF保存的是命令(SET KEY VALUE),正是由于AOF保存的文件命令,针对AOF的优化:AOF重写功能减少AOF文件体积。
- RDB是 point in time备份,我把它翻译成 定点备份。AOF是根据写命令 持续地备份。
The RDB persistence performs point-in-time snapshots of your dataset at specified intervals. the AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset.
Redis Replication
Redis Replication是实现Redis Sentinel 和 Cluster的基石。与其他存储系统(比如ElasticSearch、Kafka)所不同的是,Redis Replication是 针对节点而言,从节点执行 SLAVEOF MASTER_IP PORT命令向master异步复制数据。而在ElasticSearch或者Kafka中,它们天然地将数据配置成 多副本的形式,ElasticSearch中的主副本叫Primary shard,从副本叫Replica,Primary shard 和 replica 分布在不同的节点上,从而避免了Single Point Of Failure,而多个数据副本之间的读写模型又称为数据副本模型。
Redis Replication是把数据从master节点复制一份到slave节点上,那么从哪里开始复制呢?因此就有了完整重同步(full resynchronization,由SYNC命令触发)和部分同步(partial resynchronization,由PSYNC触发)。当新节点开始主从复制时,先执行同步过程(判断是执行full 还是 partial 同步),同步完成后进入到命令传播阶段。
这里提一下Redis partial resynchronization 涉及到的Replication ID,相当于数据版本号,在Redis Replication官方文档描述:
Every Redis master has a replication ID: it is a large pseudo random string that marks a given story of the dataset.
Each master also takes an offset that increments for every byte of replication stream that it is produced to be sent to slaves, in order to update the state of the slaves with the new changes modifying the dataset.
Slave 连上Master开始同步时,会发送Replication ID,如果一致,就会比较复制偏移量(offset),从而决定是否执行部分重同步。那如何处理某个Slave 晋升成 master 之后,其它Slave连接到新的master,其它Slave持有的Replication ID与新master的Replication ID肯定是不一样的,那如何避免这种情况可能导致的完整重同步呢?
However it is useful to understand what exctly is the replication ID, and why instances have actually two replication IDs the main ID and the secondary ID.
原来有两个Replication ID: main ID and the secondary ID,通过 secondary ID(旧的Replication ID),当其他Slave连接到新的master上时,也不需要完全重同步了:
The reason why Redis instances have two replication IDs is because of slaves that are promoted to masters. After a failover, the promoted slave requires to still remember what was its past replication ID, because such replication ID was the one of the former master. In this way, when other slaves will synchronize with the new master, they will try to perform a partial resynchronization using the old master replication ID.
下面来讨论下为什么Redis Replication是异步的?而基于多副本机制的ElasticSearch和Kafka 的Replication机制与Redis差别是挺大的,在实现思路上有很大不同。
Redis Replication Documentation有一段,这里只讨论第一种mechanisms
This system works using three main mechanisms:
- When a master and a slave instances are well-connected, the master keeps the slave updated by sending a stream of commands to the slave, in order to replicate the effects on the dataset happening in the master side due to: client writes, keys expired or evicted, any other action changing the master dataset.
the master keeps the slave updated by sending a stream of commands to the slave,什么时候sending呢?或者说sending策略是什么?这个sending策略,是Redis Replication 被称为 异步复制的原因吧。再看这一句 due to: client writes, keys expired or evicted, any other action changing,其实是说:redis 主从复制如何处理Client写、键过期、键被Evict了等情况的?比如说:
- Client向master节点写入一个Key后,这个Key会立即同步给Slave成功了,再返回响应给Client?
- Redis Key过期了怎么办?Key被Evicted出去了怎么办?expired 与 evicted 还是有区别的,expired 聚焦于键的生存时间(TTL)为0了之后,如何处理key?键过期了,这个键还是可能存在于Redis中的(主动删除策略 vs 被动删除策略)。而 evicted 聚焦于:当Redis 内存使用达到了max memory后,根据配置的maxmemory-policy将某个key删除。
- 在实际应用中,一般采用主从复制实现读写分离,Client写Master,读Slave。因此,Master上的键过期了之后,如何及时地删除Slave上过期的键,使得Client不读取到已过期的数据?其官方文档中说:Slave不会expire Key,当master上的Key过期了之后,发送一个DEL命令给Slave,让Slave也删除这个过期的键。
so Redis uses three main techniques in order to make the replication of expired keys able to work:
- Slaves don’t expire keys, instead they wait for masters to expire the keys. When a master expires a key (or evict it because of LRU), it synthesizes a DEL command which is transmitted to all the slaves.
在Redis Replication中还有一个问题:Allow writes only with N attached replicas:只有当至少N个Slave都”存活”时,才能接受Client的写操作,这是避免单点故障保证数据可靠性的一种方式。
Starting with Redis 2.8, it is possible to configure a Redis master to accept write queries only if at least N slaves are currently connected to the master.
但要注意,由于Redis的异步复制特性,它并不能保证Key一定写入N个Slave成功了。因此我的理解,这里的N个Slave,其实是: 只要有N个slave与master节点保存着 正常 连接,那么就可以写数据
However, because Redis uses asynchronous replication it is not possible to ensure the slave actually received a given write, so there is always a window for data loss.
它只是一种 尽量 保证数据安全的机制,主要由2个参数配置: min-slaves-to-write 和 min-slaves-max-lag。
If there are at least N slaves, with a lag less than M seconds, then the write will be accepted.
You may think of it as a best effort data safety mechanism, where consistency is not ensured for a given write, but at least the time window for data loss is restricted to a given number of seconds. In general bound data loss is better than unbound one.
由于这种异步复制的特征,在redis sentinel master-slave模型下,如果client发起一个写操作,并且收到了写入成功的响应,当发生故障时,这个写操作写入的数据也是有可能丢失的!因为异步复制,当client写入master的数据尚未来得及同步给slave时,master宕机,sentinel选出一个slave作为新的master,新master发起主从同步,就会覆盖到原来master上的部分数据。
Sentinel + Redis distributed system does not guarantee that acknowledged writes are retained during failures, since Redis uses asynchronous replication. However there are ways to deploy Sentinel that make the window to lose writes limited to certain moments, while there are other less secure ways to deploy it.
又或者说:master与其所有的slave连接发生了网络分区,如下图所示:

master M1已经是一个过时的master了,而如果client c1 刚好与这个过时的master在同一个网络分区下,C1会一直认为M1是正常的master,那么c1写入的数据就会丢失。(详情可参考:Redis Sentinel Documentation)
那有没有办法解决Redis Sentinel这种因为异步复制带来的数据丢失问题呢?二种解决方案:
-
Use synchronous replication (and a proper consensus algorithm to run a replicated state machine).
-
Use an eventually consistent system where different versions of the same object can be merged.
这里来讨论一下第一种方法,使用”同步复制”来保证 acknowledged write 不会丢失。这种方法的理论知识可参考Raft共识算法。在Raft共识算法中提到了复制状态机,通过它来保证已提交的消息不会丢失。下面我从ElasticSearch的数据副本模型角度以及Kafka的的副本模型来讨论一下:在ES和Kafka中是如何保证 acknowledged write 的可靠性(不丢失)的。
当Client 发起一次写文档的请求时,ES首先根据 docid 进行哈希,找到该文档应该写入到哪个主分片上,当该文档写入到主分片后,将该文档同步给各个副本分片,这里的副本分片是同步副本列表(in-sync)集合里面的副本分片,当同步副本列表集合中的副本分片都写入该文档后,就会给主分片返回响应,最终主分片再给Client响应,这就是”同步复制”的acknowledged write。
从上面的流程可看出,由于同步副本列表集合机制,一篇文档是写入了多个副本的,因此可以避免单点故障导致的数据丢失。另外,当因为网络分区等原因导致主分片失效(stale primary shard)时ES的master节点可以从in-sync集合中选出一个副本分片作为新的主分片,由于in-sync集合中的副本分片与主分片的数据是同步的,因此发生这种主分片身份变化的情况也不会导致acknowledged write丢失。而这就是同步复制可以保证acknowledged write不丢失的原因,这是与 Redis Sentinel 异步复制无法保证acknowledged write 不丢失的区别。另外,值得注意的是,默认情况下Client向ES写入一篇文档时,只要同步副本列表集合中的一个分片写入成功了(wait_for_active_shards=1),就返回写成功响应给Client。主分片肯定是in-sync集合中的分片。
类似地,在Kafka中如何保证生产者的消息一定写入成功了(已提交),分析的思路也是一样的。在Kafka中,Producer有个ack参数,可配置为-1(或者all),Kafka中也有in-sync集合,并且Kafka中也有个参数 min.insync.replicas 参数来控制producer发送的消息要写入到几个副本中才能返回写入成功响应给生产者客户端。Kafka的 min.insync.replicas参数与ES中的 wait_for_active_shards 参数二者的原理是一样的。将Producer的ack参数设置成-1或者all,再配合 min.insync.replicas参数 就能保证一条消息至少会写入多个副本才返回acknowledged write响应给Client。当主副本发生宕机时,只要是从in-sync集合中选出一个副本作为新的主副本,那么就不会出现像 redis sentinel 中那种因异步复制导致的acknowledged write丢失问题,但如果主副本不是从in-sync集合中选出来的,就会出现数据丢失,这也是为什么 Kafka中有个配置参数unclean.leader.election=false 来强制保证kafka只能从in-sync集合中选出副本作为主副本的原因。
从ES得Kafka的数据副本同步过程可以看出,它们与Raft的共识算法中的复制状态机模型还是有那么一点区别的。
在ElasticSearch和Kafka中,也有非常与之类似的机制:ElasticSearch有个参数
wait_for_active_shards,它也是在Client向ES 某个 index 写入一篇文档时,检查这个 index 下是否有 wait_for_active_shards 个活跃的分片,如果有的话,就允许写入,当然了,检查活跃分片数量并写入(check-then-act)是两步操作,并不是 原子操作,因此ElasticSearch也并不能保证说文档一定成功地写入到wait_for_active_shards 个分片中去了。事实上,在返回给Client的ACK响应中,有一个_shard字段标识本次写操作成功了几个分片、失败了几个分片。另外需要注意的是:ElasticSearch和Kafka针对写入操作引入一种”同步副本集合”(in-sync replication)机制,Kafka中也有同步副本列表集合,还记得Kafka的 broker 参数min.insync.replicas的作用吗?它们都是为了缓解:数据只写入了一个节点,尚未来得及复制到其他节点上,该节点就宕机而导致的数据丢失的风险(这也是经常提到的单点故障SPOF)
ES的5个节点某个索引的分片如下图:

额外说一下:这里提到的尽量保证数据安全,是通过多副本方式/主从复制方式保证数据安全,针对的是跨节点、避免单点故障。还有一种数据安全是针对单机的持久化机制而言的:数据写入到内存了,产生了dirty page,但是尚未来得及刷盘,节点就宕机了怎么办?因此存储系统中都有一个WAL(Write Ahead Log 方案),比如MySQL的redo log、ElasticSearch的Translog,其总体思路是:先写日志再写数据,若发生故障,则从日志文件中恢复尚未持久化到磁盘上的数据,从而保证了数据安全。
Redis Sentinel vs Redis Cluster
Redis Sentinel是一个Sentinel集群监控多 组主从节点,Redis Cluster则是多个master节点组成一个集群,同时每个master节点可拥有多个slave节点做数据备份。Sentinel和Cluster都具有高可用性,其背后的实现是通过主从复制,将数据以”副本”形式存储在多个节点上。
Redis Sentinel provides high availability for Redis. In practical terms this means that using Sentinel you can create a Redis deployment that resists without human intervention to certain kind of failures.
我觉得它们一个主要的区别是在数据分布上,对于Sentinel而言,是一台节点存储所有的数据(所有的键值对),这就是所谓的数据分布方式。如果一台Redis 存储不下所有的数据怎么办?这就是Redis Cluster需要解决的问题,它是由若干个master节点共同存储数据,能够线性地扩展到1000+节点。
High performance and linear scalability up to 1000 nodes. There are no proxies, asynchronous replication is used, and no merge operations are performed on values.
在Redis Cluster中,是通过”槽指派”方式对Key进行哈希。整个键空间划分成16384个固定的槽,每个节点通过槽指派负责处理哪些槽。采用哈希进行数据分布的优势是:能够较好地保证Key的分布是均匀的,均匀地分配在各个master节点上。这里显然有一致性哈希的思想在里面,槽的数量是固定的,只有16384个,但是Redis的节点的数量可以动态地变化,这时候只需要部分数据迁移。当Client写入一个Key时,先通过 CRC16(kEY)%16383计算出这个Key属于哪个槽,然后再查询slots数组得知这个槽被指派给了哪个节点,于是就把键值对存储到这个节点上。
谈到数据分布方式,这个问题的本质是:由于存储系统是个集群,有多台节点,那么把数据放到哪一台节点(其实是分片/分区所在的节点)上比较合适?这里需要考虑数据分布的均匀性,即不能有数据倾斜。在ElasticSearch中,当Client发起索引文档请求时,若不指定docid,会自动生成docid,并且通过murmur3函数进行哈希,选择一个合适的分片来存储该文档。类似地,在Kafka中,生产者发送消息时,消息是送到Kafka上的哪个分区(Partition)呢?,当生产者的消息不指定key时,采用Round-Robin算法轮询,当指定了消息的key时,针对murmur2对key哈希,然后求余分区数,确定出消息发送到哪个分区。
这里来重点讨论高可性下的failover机制:(故障的自动恢复)
不管是Redis Sentinel 还是 Redis Cluster,如果一台节点宕机了,要如何自动恢复呢?Redis Sentinel的failover机制是这样的:
- 某个Sentinel节点监测到某节点故障了,将之标记为主观下线
- Sentinel节点向其他Sentinel节点询问,该节点是否真的已经下线,当收到 大多数(quorum)(足够数量)的Sentinel节点都认为该节点下线时,将之标记为客观下线。这里的大多数是:sentinel.conf配置文件中的quorum参数的设置,比如:
sentinel monitor mymaster 127.0.0.1 6379 2配置中 quorum=2 - Sentinel集群发起选举,选出一个主Sentinel,由主Sentinel负责故障节点的Failover。选举算法基于Raft,选举规则是先到先得:比如说多个源Sentinel(候选Sentinel)向同一个目标Sentinel发起投票请求,谁的请求最先到达,目标Sentinel就把选票投给谁。当候选Sentinel获取 大多数节点的投票时,就成为主Sentinel。这里的大多数是针对raft选举算法而言的。
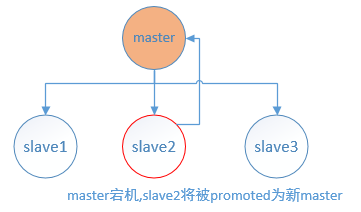
需要注意的是,在redis sentinel 检测出master故障,并进行failover的过程,涉及到了2个”大多数”,一个是 sentinel.conf 配置参数 quorum,另一个是进行sentinel选举所采用的raft选举算法中的大多数。这2个还是有一点区别的,举例来说:一个5节点的sentinel集群,quorum参数配置为2,意味着只要有2台sentinel节点认为master宕机了,就能够触发 failover,既5台sentinel开始进行sentinel选主,但是选出主sentinel节点是需要大多数节点,也即至少3台sentinel节点同意的。当选出主sentinel节点后,就由它负责选择一台合适的slave节点作为新的master。
此外,quorum 参数也能够影响主sentinel选举的过程,当quorum设置为一个比 sentinel集群大多数(根据上面示例,大多数是3) 还要大的值时,也即当 quorum大于3时,比如quorum=5,那么:sentinel选举时,需要全部5个sentinel节点一致投票某个sentinel节点作为主sentinel节点才行。具体可参考:Redis Sentinel Documentation
为什么要通过Sentinel选主这种方式选出主Sentinel,并由主Sentinel负责故障的Failover呢?我的理解是:首先需要对故障节点达成共识,即:一致认为某个节点确实发生了故障,然后对故障恢复的处理也要达到共识,不能出现:两个Sentinel节点同时在对同一个故障节点Failover的情形,而要想达成共识,分布式一致性选举算法就是解决方案。
最后来看下,Redis Cluster 是如何进行故障的Failover的?
- 集群中的每个节点定期向其他节点PING,某个master节点宕机,无法回复PONG,被标记为疑似下线(PFAILED)
- 当集群中的大多数master节点都认为该节点宕机时,该master节点被标记为下线状态(FAILED)。将故障节点标记为FAILED的节点,向集群广播一条该master节点已经FAILE的消息。
- 此时,slave节点已经发现了它所复制的主节点FAIL了,于是发起failover(与Redis Sentinel不同的是,这里的故障failover是由从节点发起的)
- 集群中各个master节点向 故障master节点下的 slave 节点投票,获取大多数master节点投票的slave节点将成为新的master节点,这里的选举算法也是基于Raft实现的。
网络分区问题(consistency guarantees)
Redis Cluster Tutorial中说Redis集群无法保证强一致性,换句话说:Redis Cluster会丢失”写确认”的数据,即Client向Redis Cluster写入一个Key,Client收到了这个Key写入成功的响应,但是这个Key可能因故障而丢失了。导致故障的原因有2个:Redis的异步复制特性以及网络分区。
Redis Cluster is not able to guarantee strong consistency. In practical terms this means that under certain conditions it is possible that Redis Cluster will lose writes that were acknowledged by the system to the client.
对于异步复制来说,Redis提供了WAIT命令来缓解这种”写确认”丢失的问题。WAIT有点类似于同步复制的意味,它都指定一个Key要写入多少个slave才会返回确认给Client了,那么为什么官方文档中还是说:WAIT 也不能完全保证acknowledged write 丢失呢?因为:同步复制是保证写确认不丢失的其中一个步骤,在failover过程中,选出的新master并不一定是拥有最新写入的数据的那台slave,Kafka中不是也有”不安全的选举”吗?(unclean.leader.election参数)
而至于网络分区导致的写确认丢失问题,又提供了参数 node timeout 来缓解。举例来说就是:如果一台master和某个Client划分在了同一个网络分区中,Client可以持续给将数据写入这台master,但是这台master已经与集群中的大多数master节点以及它的备份slave失去了联系了,这是一台很不安全的master,应当主动放弃master身份,并拒绝Client的写入才行。因此,Redis cluster应当有某种机制及时检测出这种情况。这就是node timeout参数的意义。但是发生网络分区后 node timeout 时间内写入的数据,就有可能丢失了。
After node timeout has elapsed, a master node is considered to be failing, and can be replaced by one of its replicas. Similarly after node timeout has elapsed without a master node to be able to sense the majority of the other master nodes, it enters an error state and stops accepting writes.
那么:ElasticSearch又是如何处理这种网络分区的情形的呢?
看ES的data-replication 数据副本模型可知,当primary shard写入文档时,会将之同步到 in-sync 集合的replica,然后才返回Cllient acknowledged write。在同步文档给 in-sync 集合中的replica时,replica会验证该primary shard是否是过时的(stale),如果replica发现primary shard 已经过时了(相当于redis中的发生网络分区处于少数派中的那种master节点),就会拒绝该primary shard的同步文档的请求。
While forwarding an operation to the replicas, the primary will use the replicas to validate that it is still the active primary. If the primary has been isolated due to a network partition (or a long GC) it may continue to process incoming indexing operations before realising that it has been demoted. Operations that come from a stale primary will be rejected by the replicas.
当ES的 primary shard 收到replica的拒绝同步文档响应后,它自己也会向ES的master节点检查自己是否已经被master节点”降级为”普通副本了。于是,它就不再接受Client的文档写入请求,从而过时的primary shard 就不会返回acknowledged write给Client了。
When the primary receives a response from the replica rejecting its request because it is no longer the primary then it will reach out to the master and will learn that it has been replaced. The operation is then routed to the new primary.
至此,Redis Persistent、Redis Replication、Redis Sentinel、Redis Cluster 就大概介绍完了。我发现Redis的Tutorial和Documentation写得真是好,还有通俗易懂的《Redis设计与实现》,都是理解 Redis 的好材料。最近一直想总结下各个存储系统背后的原理,无奈技术和时间都不够,只能写一点笔记作为记录了吧,我想接下来是要去读一读系统的源码,以期有更深入的认识。
原文链接:https://www.cnblogs.com/hapjin/p/11181148.html
参考:程序员的宇宙时间线
Original: https://www.cnblogs.com/hapjin/p/11181148.html
Author: 大熊猫同学
Title: Redis Persistent Replication Sentinel Cluster的一些理解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528942/
转载文章受原作者版权保护。转载请注明原作者出处!