

一些知识点
concordance
concordance查找语料库中特定的单词的上下文, 检索词指定窗口大小的上下文。
concordance(word,width,lines),其中 width表示包括 word在内的窗口大小, lines几行。


; similar
使用 similar 来查找具有相似上下文的词。

common_contexts(['word1','word2'])
共用两个及以上单词上下文的词汇。——哪两个词共用上下文。

表示text2中出现
the word以及 the world,以此类推。
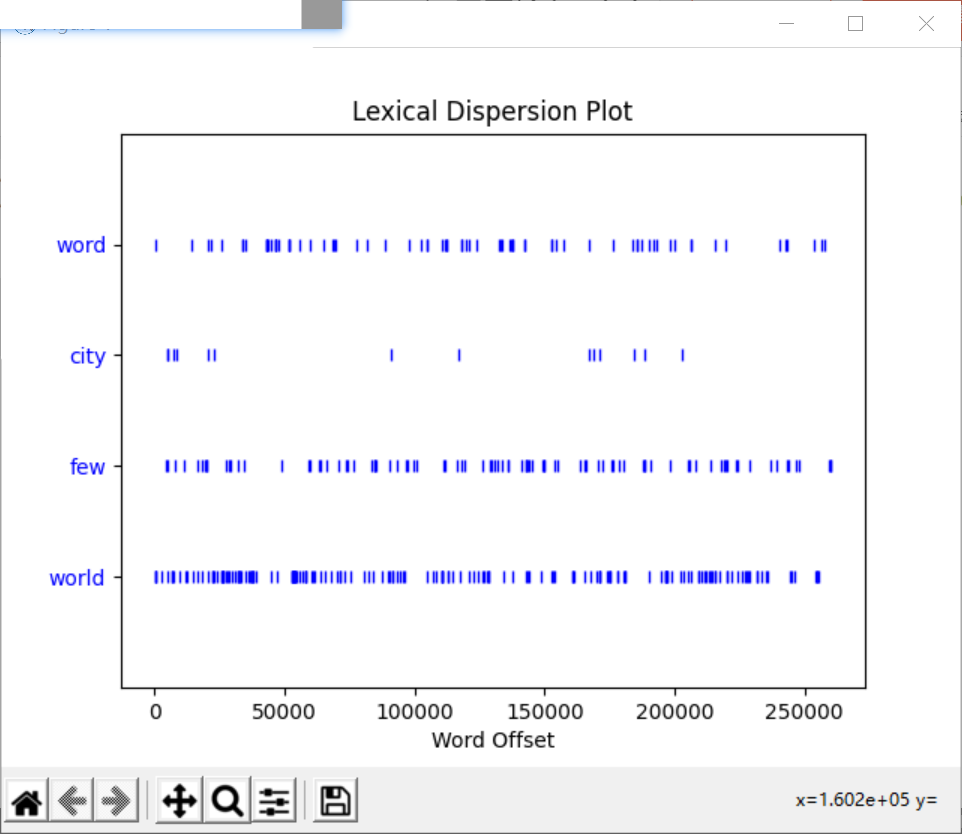
; dispersion_plot(['word1','word2',...])
查看词汇离散图,查看词的分布情况。每个关键词所在的行代表着整个文本,横轴的位置代表着文本位置。
text1.dispersion_plot(['word','city','few','world'])
文本计数与排序

; 文本简单统计
函数 FreqDist方法获取文本中每个出现的标识符的频率分布,接受列表。

.keys()查看主键,.freq()打印频率

.N查看样本总数

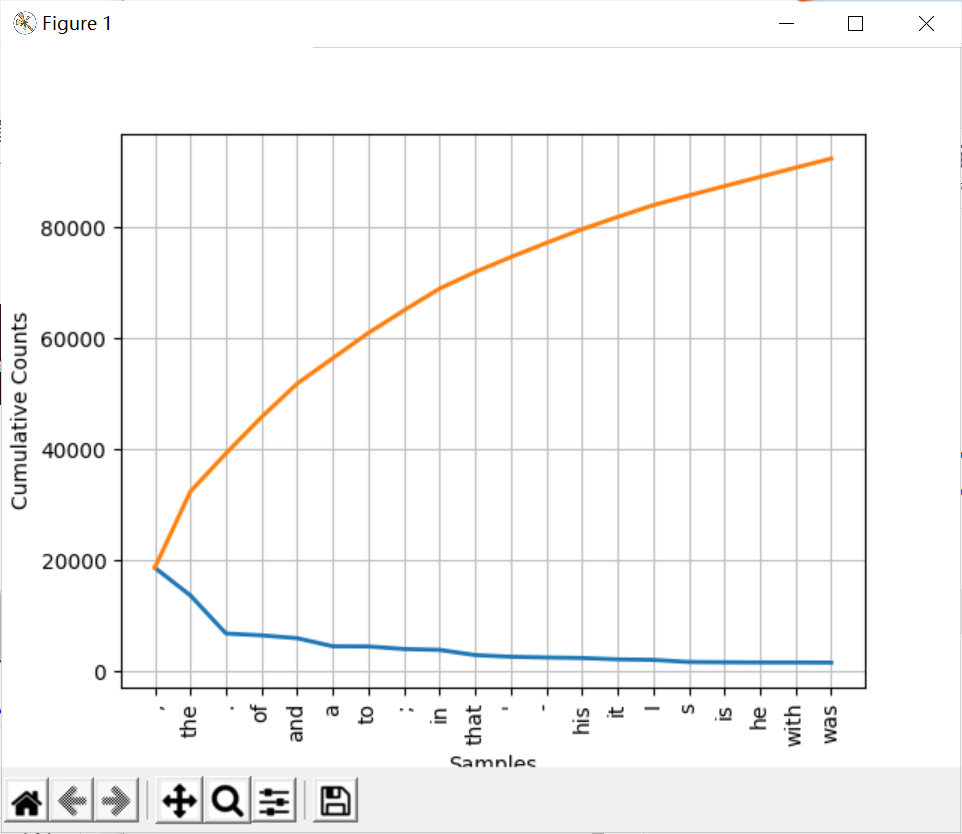
plot 绘制频率分布图
FreqDist接受使用plot,接受一个数字n,图像包括出现次数最多的前n项。 cumulative表示出现次数是否累加,绘制累计频率分布图。下图红色表示 cumulative=True的情况。
; tabulate 绘制频率分布表
以表格形式打印频率最高的n项。

选择长单词

; 找搭配词

分析文本中不同词长的频率分布

; NLTK中常见的语料库
- 古腾堡
gutenberg - 布朗
brown
语料库的基本处理步骤
- 导入语料库
from nltk.corpus import gutenberg as bg
-
使用实例化对象对该语料库文本进行操作
-
查看语料库中有多少个文件
.fileids()
- 查看语料库中指定文件的单词
.words(fileids=[f1,f2,f3])

ConditionalFreqDist(条件,事件)
对应方法类似于FreqDist,专门统计条件词频类。
‘can’,’could’,’may’,’might’,’must’,’will’这几个单词在brown语料库中的’news’,’religion’,’hobbies’,’science_fiction’,’romance’,’humor’几个主题下的词频对比。
使用nltk载入并分析自己的语料库
nltk.corpus.PlaintextCorpusReader- Brown语料库一共有多少个类别?一共有多少个文件?
类别’news’下,有多少篇新闻文本?
新闻’ca01′ 包含了多少个单词?多少个句子?
打印新闻’ca02’的原始文本。
br.categories()
br.fileids()
len(br.fileids(categories='news'))
len(br.words('ca01'))
len(br.sents('ca01'))
br.raw('ca02')
正则表达式
re.search(p,s)判断字符串s中是否有模式p,有则返回非空对象,否则返回空none。.匹配除换行符之外的任何字符;^匹配字符串开头;*匹配前一个正则的0或者更多(贪婪);+匹配前一个正则的1或者更多(贪婪);?匹配前一个正则的0或者1(贪婪);*???+?不贪婪模式;{m,n}匹配前一个正则的m到n个重复;|或者;
Original: https://blog.csdn.net/Suzerk/article/details/124150386
Author: Suzerk
Title: nltk自然语言处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528596/
转载文章受原作者版权保护。转载请注明原作者出处!