

文本分类是NLP自然语言处理中一项基本功能,它在新闻分类、主题分类、问答匹配、意图识别、情感分类、推断等领域都有涉及。
学习应用文本分类任务的难点有被识别语言的复杂性和评测函数的设计等,本篇将介绍一个NLP中的深度学习模型——TextCNN模型,CNN的核心思想是捕捉局部特征,对于文本来说,局部特征就是由若干单词组成的滑动窗口,形同N-gram,CNN的优势在于能够自动地对N-gram特征进行组合筛选从而获得不同抽象层的语义信息。下面这张图是很多博客中引用的一张TextCNN介绍图,具体介绍可以参考下面链接中的一篇文章:1510.03820.pdf (arxiv.org)
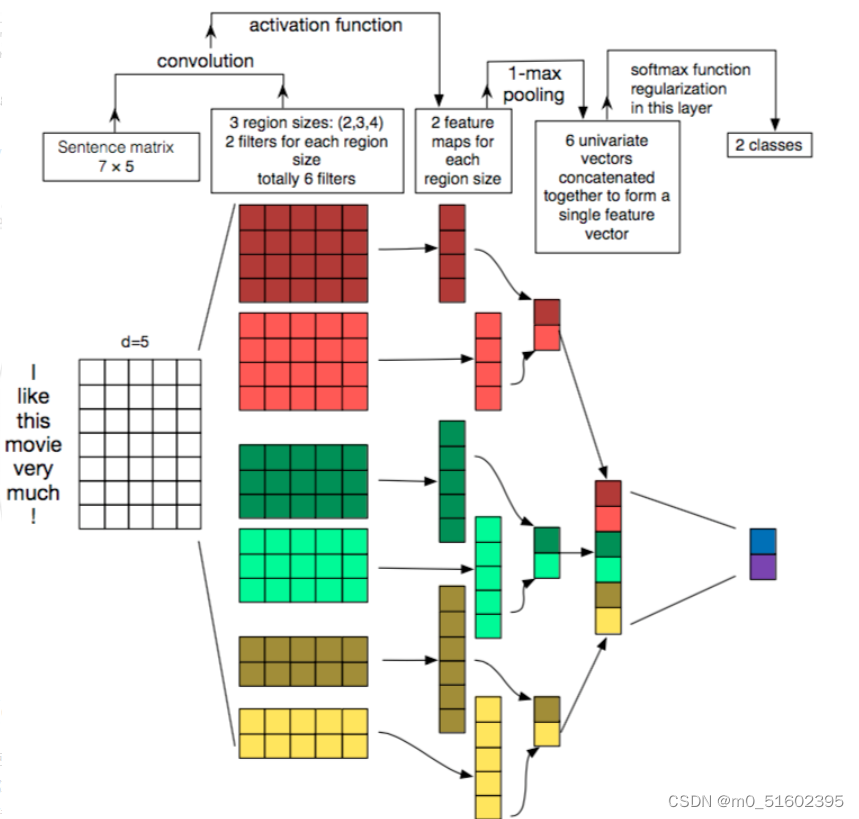

这张图最左边是一个初始文本(初始数据集),我们把句子中的每一个单词提取出来,为他构建一个五维的向量描述一个词,第二步就是选择卷积核,这里可以根据实际情况自己选择,可以把他理解为一个滑动窗口,没构造一个卷积核后就将滑动窗口向下滑动若干行,在第三步中就是对每个卷积核来通过过滤层对数据做处理,这里用到的就是文本分类的核心卷积神经网络,具体实现方法也推荐一篇文章,里面对卷积神经网络讲解的也十分清楚:CS231n笔记:通俗理解CNN – mathor (wmathor.com)通过若干过滤层之后进行的下一步就是选择最大/最小值,以图中为例,深红色的四块通过选择得到一块深红色,它可以代表这一组的典型去进行下一步运算,对每一步运算结果做提取后就可以构建出全连接层,最后再放入池化层就得到了卷积运算结果。下面附上一份简单的TextCNN文本分类代码,依靠pytorch实现。
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
3 words sentences (=sequence_length is 3)
sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
labels = [1, 1, 1, 0, 0, 0] # 1 is good, 0 is not good.
TextCNN Parameter
embedding_size = 2
sequence_length = len(sentences[0]) # every sentences contains sequence_length(=3) words每个句子有sequence_length个词
num_classes = len(set(labels)) # num_classes=2 类数:这里是2(1或0)
batch_size = 3
word_list = " ".join(sentences).split()
vocab = list(set(word_list))
word2idx = {w: i for i, w in enumerate(vocab)}
print(word2idx)
vocab_size = len(vocab)
def make_data(sentences, labels):
inputs = []
for sen in sentences:
inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) # To using Torch Softmax Loss function
return inputs, targets
input_batch, target_batch = make_data(sentences, labels)
print(input_batch)
print(88888)
print(target_batch)
input_batch, target_batch = torch.LongTensor(input_batch), torch.LongTensor(target_batch)
print(input_batch)
print(77777)
print(target_batch)
dataset = Data.TensorDataset(input_batch, target_batch)
print(dataset)
loader = Data.DataLoader(dataset, batch_size, True)
print(loader)
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
output_channel = 3
self.conv = nn.Sequential(
# conv : [input_channel(=1), output_channel, (filter_height, filter_width), stride=1]
nn.Conv2d(1, output_channel, (2, embedding_size)),
nn.ReLU(),
# pool : ((filter_height, filter_width))
nn.MaxPool2d((2, 1)),
)
# fc
self.fc = nn.Linear(output_channel, num_classes)
def forward(self, X):
'''
X: [batch_size, sequence_length]
'''
batch_size = X.shape[0]
embedding_X = self.W(X) # [batch_size, sequence_length, embedding_size]
embedding_X = embedding_X.unsqueeze(1) # add channel(=1) [batch, channel(=1), sequence_length, embedding_size]
conved = self.conv(embedding_X) # [batch_size, output_channel*1*1]
flatten = conved.view(batch_size, -1)
output = self.fc(flatten)
return output
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
Training
for epoch in range(5000):
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
Test
test_text = 'i hate me'
tests = [[word2idx[n] for n in test_text.split()]]
test_batch = torch.LongTensor(tests).to(device)
Predict
model = model.eval()
predict = model(test_batch).data.max(1, keepdim=True)[1]
if predict[0][0] == 0:
print(test_text,"is Bad Mean...")
else:
print(test_text,"is Good Mean!!")
它的主体思想是对一系列话进行训练,输出结果只有两类,一个是1代表乐观语言1另一个是2代表悲观语言,训练之后就可以对我们输入的语言进行判断,得到他是乐观语言还是悲观语言。
Original: https://blog.csdn.net/m0_51602395/article/details/124656251
Author: 难熬吗1884
Title: NLP自然语言处理——文本分类(CNN卷积神经网络)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528430/
转载文章受原作者版权保护。转载请注明原作者出处!