

·阅读摘要:
本文提出经典的Seq2Seq模型,应用于机器翻译领域。但是Seq2Seq适用于很多领域,比如多标签文本分类。
·参考文献:
[1] Sequence to Sequence Learning with Neural Networks【注一】:本论文提出的Seq2Seq模型,引发一系列基于Seq2Seq模型的文章问世。地位类似于2014年Kim发表的TextCNN,2017年Google发表的Transformer。
【注二】:论文的内容比较简单,重点都是在讲解Seq2Seq的原理。本篇博客将从pytorch实现Seq2Seq的角度讲解用代码逻辑理解Seq2Seq。
[1] Seq2Seq模型图
如下图,左边是编码器(Encoder),主要是把一个序列经过多层LSTM后转化为一个固定大小的隐藏层向量H H H。右边是解码器(Decoder),也是深层LSTM,它的输入是每次产生的词y i y_i y i 与编码器的输出H H H,解码器每次产生一个词,直到产生的词是 <eos></eos>为止。
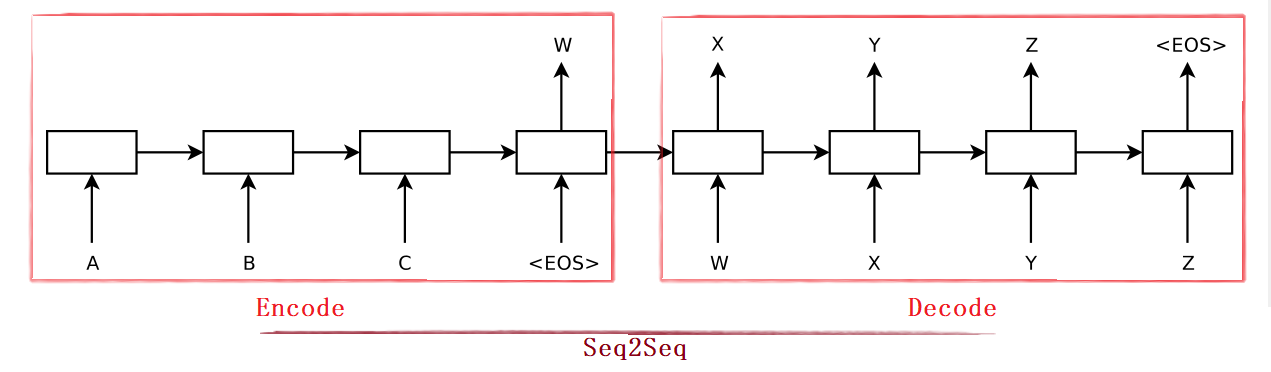

; [2] 编码器(Encoder)
代码如下:
代码中,参数
src是源序列,参数trg是目标序列
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cell
编码器(Encoder)就是一个普通的双向LSTM模型,比较简单。
正常情况下,我们使用的是最后一层,每个时间步的输出 outputs。
这里,编码器(Encoder)返回的是每一层每个时间步的输出 hidden与中间参数 cell。 hidden与中间参数 cell会作为解码器(Decoder)的输入。
[3] 解码器(Decoder)
代码如下:
代码中,参数
src是源序列,参数trg是目标序列
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(0))
return prediction, hidden, cell
解码器(Decoder)依然是一个LSTM层,它的输入是上一次的输出 hidden与 cell和上一次生成的单词的词向量 input。
【注三】:在第一次运行Decoder的时候,用的是Encoder的输出
hidden与cell和开始字符<sos></sos>的词向量。
到这里, 其实还是有诸多疑问的,包括:
1、解码器(Decoder)是一个词一个词蹦出来的,对于Decoder可见性的要用循环来遍历一下,这个循环怎么写的问题;
2、词向量怎么转化成单词,由于转化的单词要立即送到Decoder里,所以这个转化操作要在模型内完成,不应该作为输出,放到外面转化。
3、模型要返回全连接层的输出,这是个向量,便于后续做 loss计算;
4、如果Decoder出的第一个单词就错误的话,那整个Decoder出来的句子就打错特错,如何防止这种情况。
[4] Seq2Seq
最终把Encoder和Decoder整合,才算成功,代码如下:
代码中,参数
src是源序列,参数trg是目标序列
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
hidden, cell = self.encoder(src)
input = trg[0,:]
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputs
看到以上模型,可以解决在步骤[3]中残留的问题。首先用编码器得到输出,然后以一个for循环逐次执行解码器。
【注四】:
self.decoder的输出output是经过全连接层的,它的含义是概率,接下来执行output.argmax(1)就是找出其中最大概率对应的序号,这样去词典/标签集中一找就能对应得上了。【注五】:
teacher_force是一种非常好的机制,防止解码器一错再错,随机填入目标序列中的词作为输入,用以纠正。再训练阶段我们可以使用teacher_force机制,但是在验证、测试时使用teacher_force机制是不对的,我们需要设置模型的形参teacher_forcing_ratio=0。【注六】:模型最终
return的outputs是经过全连接层的!它的含义是概率!它要作为损失函数的输入计算loss的。⭐【注七】:这样写还是有点问题,在验证、测试的时候,还是这样的话,即使
teacher_forcing_ratio=0,但已经默认了生成序列的长度,这是不对的。⭐【注八】:在验证、测试的时候,我们应该以出现终止符
<eos></eos>为结束。对于机器翻译任务可行,但是对于多标签文本分类,应该没有效果。因为文本的最后一个单词是具有结束语义信息的,标签不具有。还要继续看论文深造。。。
[5] 结尾
其实有时候看代码比看论文更容易理解,只是好的代码不好找。
完整代码参考:https://github.com/bentrevett/pytorch-seq2seq/blob/master/1%20-%20Sequence%20to%20Sequence%20Learning%20with%20Neural%20Networks.ipynb
Original: https://blog.csdn.net/qq_43592352/article/details/123088043
Author: 征途黯然.
Title: 【多标签文本分类】代码详解Seq2Seq模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528399/
转载文章受原作者版权保护。转载请注明原作者出处!