

笔记目录
- 关于Transformer
- 小样本学习
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis
- Leveraging Graph to Improve Abstractive Multi-Document Summarization
- Context-Guided BERT for Targeted Aspect-Based Sentiment Analysis
- Does syntax matter? A strong baseline for Aspect-based Sentiment Analysis with RoBERTa
* - Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT
- COSFORMER : RETHINKING SOFTMAX IN ATTENTION
- Label Confusion Learning to Enhance Text Classification Models
- MASKER: Masked Keyword Regularization for Reliable Text Classification
* - Convolutional Neural Networks for Sentence Classification
- Ideography Leads Us to the Field of Cognition: A Radical-Guided Associative Model for Chinese Text Classification
- ACT: an Attentive Convolutional Transformer for Efficient Text Classification
- Merging Statistical Feature via Adaptive Gate for Improved Text Classification
- Pytorch实战
* - 初识Pytorch
- 初识词表
- 词嵌入
- TextCNN-Pytorch代码
- 简单CNN二分类Pytorch实现
- 杂记
– - Visual Prompt Tuning (VPT)
- Adversarial Multi-task Learning for Text Classification
- reStructured Pre-training
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer「谷歌:T5」
关于Transformer
- transformer在大的数据集上表现更好。
-> BERT模型,在大数据集上进行预训练得到语言模型结果。 - vi-T是对顺序不敏感的,因此用固定的位置编码对输入进行补充。
-> 那么为什么Transformer会对位置信息不敏感呢?输入和输出不也是按照一定序列排好的吗?
-> 回忆一下, encoder self-attention机制,在tokens序列中,后面的token包含有前面token的语义信息,而前面的token同样是包含有后面token的信息的,并不像simpleRNN一样是从左向右依次提取。那么这样将会导致序列提取出来的信息”包罗万象”,比如在”我爱你”这句话某一层的提取结果中,每一个位置上的token都会叠加其余位置上token的信息,经过多个自注意力层提取之后,原始输入”我爱你”和”你爱我”这两句话对应的特征序列理应是不容易区分开的,然而这两句话的现实涵义则是完全不同的。
-> 疑惑:RNN有长文本遗忘的问题,对于长文本,语句双向的涵义叠加起来看起来似乎合理,可以解决问题;但对于短文本,双向RNN会不会也有和Transformer同样的问题,即混淆序列中token的位置信息?


[token之间的相关性;K、Q (token*W) 之间的相似性] - transformer N维序列的输入[x]对应N维序列的输出[c],RNN里边可以只保留最后一个状态向量h i h_i h i ,而transformer必须全部保留,因为参数不共享(多头自注意力机制那里也不共享参数)。
-> 猜测:考虑到句子中每个位置上不同单词出现的频数不同,因此不共享参数可能可以达到更好的效果(多头自注意力机制则更好理解了,如果共享了参数那么也没有其存在的必要了)。

- 疑惑:如果编码器输入x_1和解码器输入x_1’的维度不一样,那么K和Q之间的相似度该如何计算呢?还是有些模棱两可,不求甚解……

* NLP的输入序列必须等长,如果超长就要切片,如果长度不足就要补齐。





- Transformer在训练阶段的解码器部分,为了防止自注意力偷窥到预测单词之后的序列,采用mask方法。

- 有个问题,mask掉的到底是什么?参考了知乎上的回答,虽然可以自圆其说,但整体理解上面还是有些模棱两可:

; 小样本学习
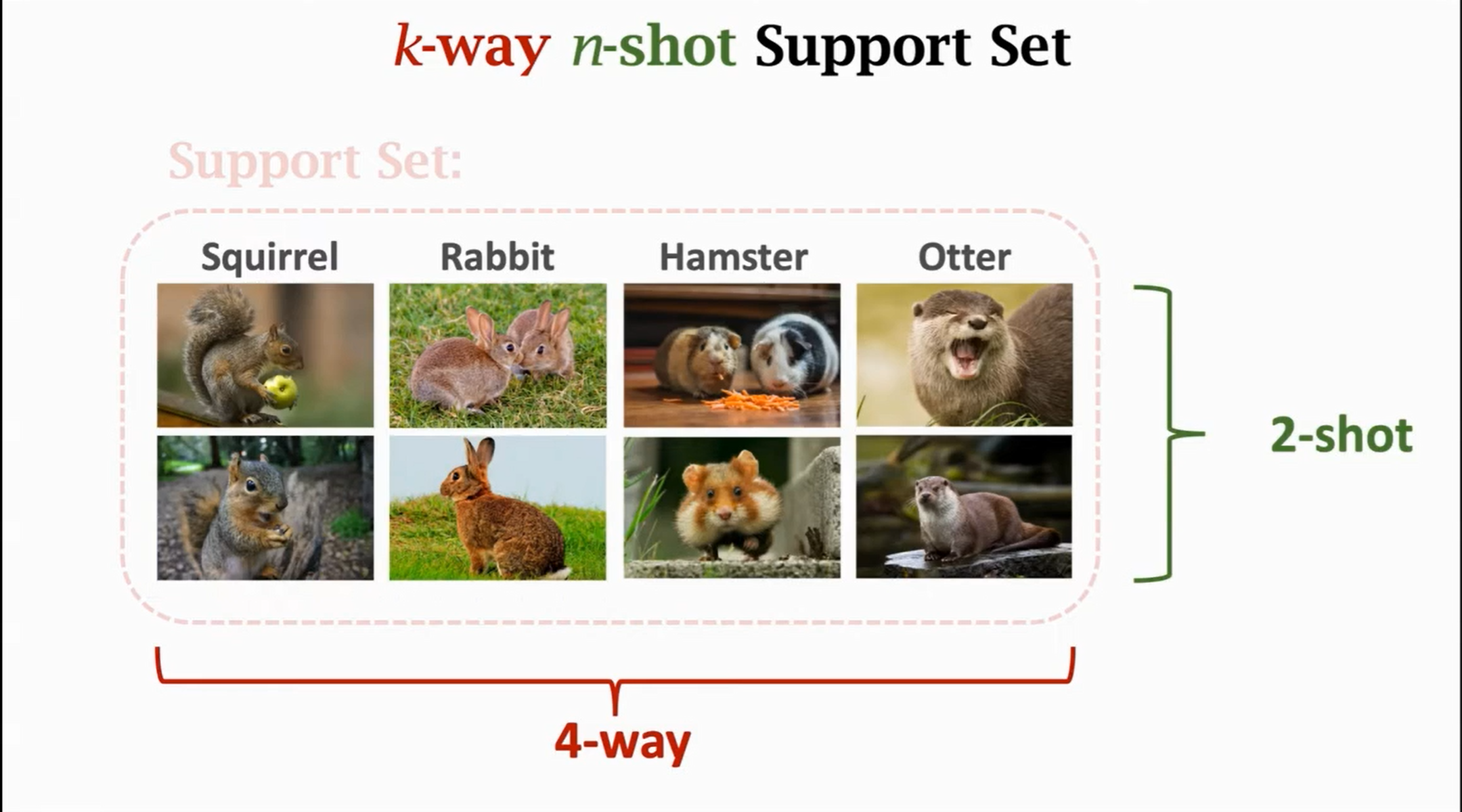

Tips:
- 对Transformer求Q和K的相关度时,也可以做此改进。
- 从K、Q、V入手,看看是否能对Transformer模型改进。
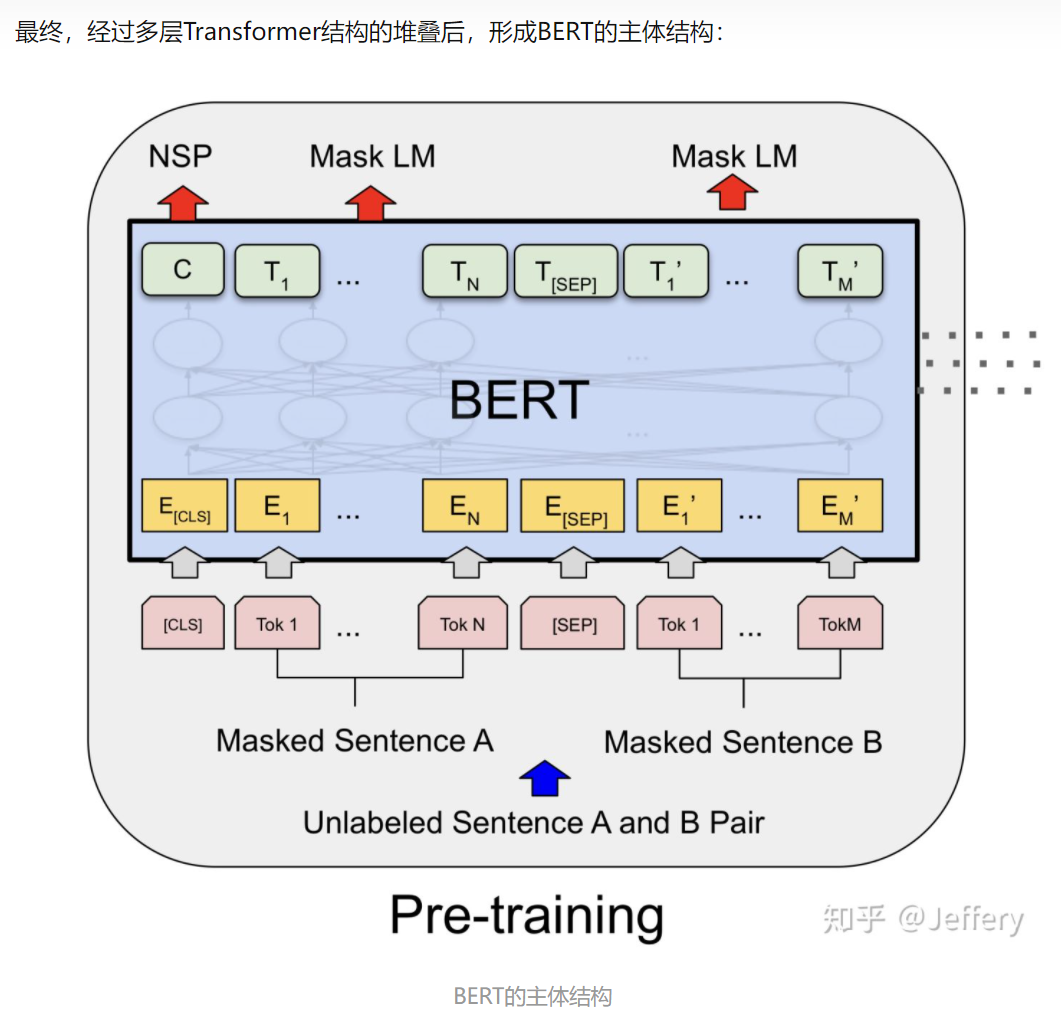
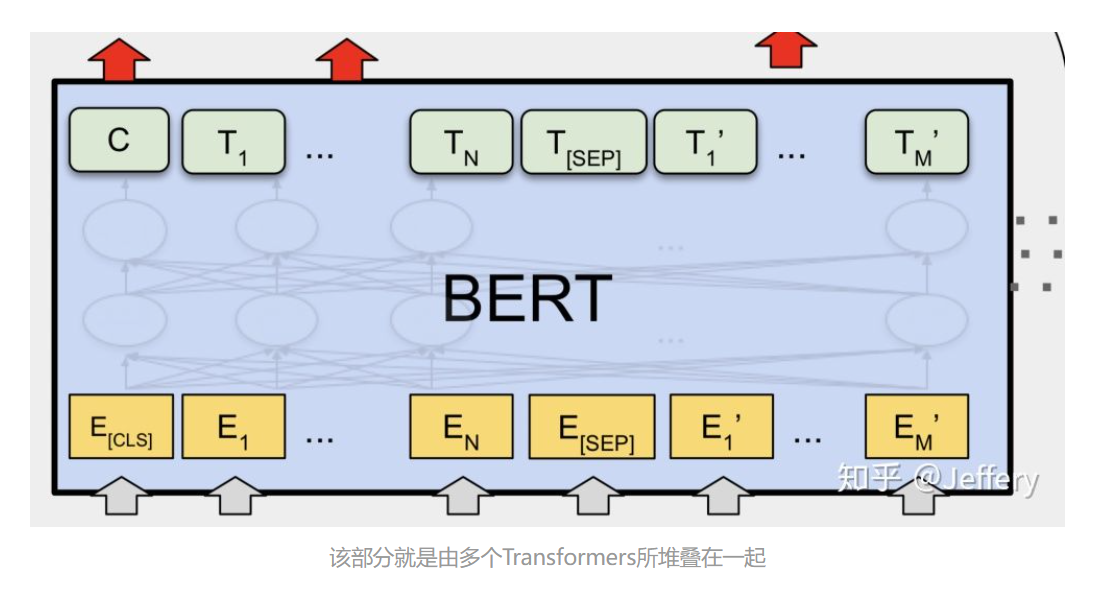
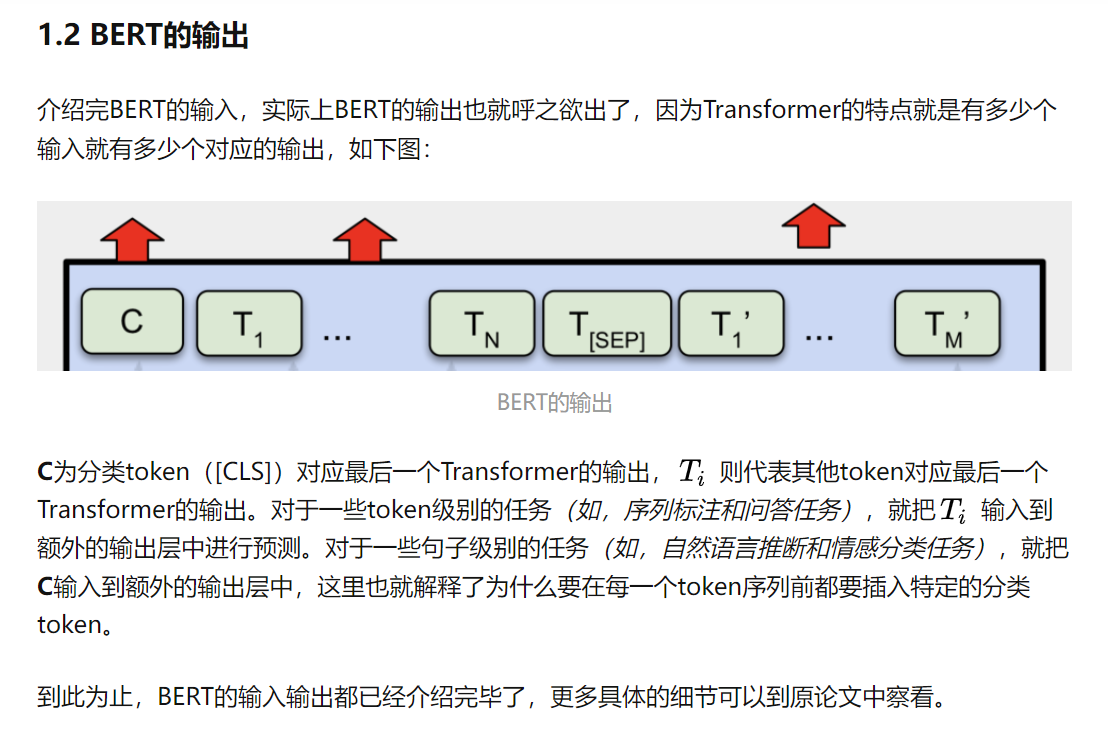
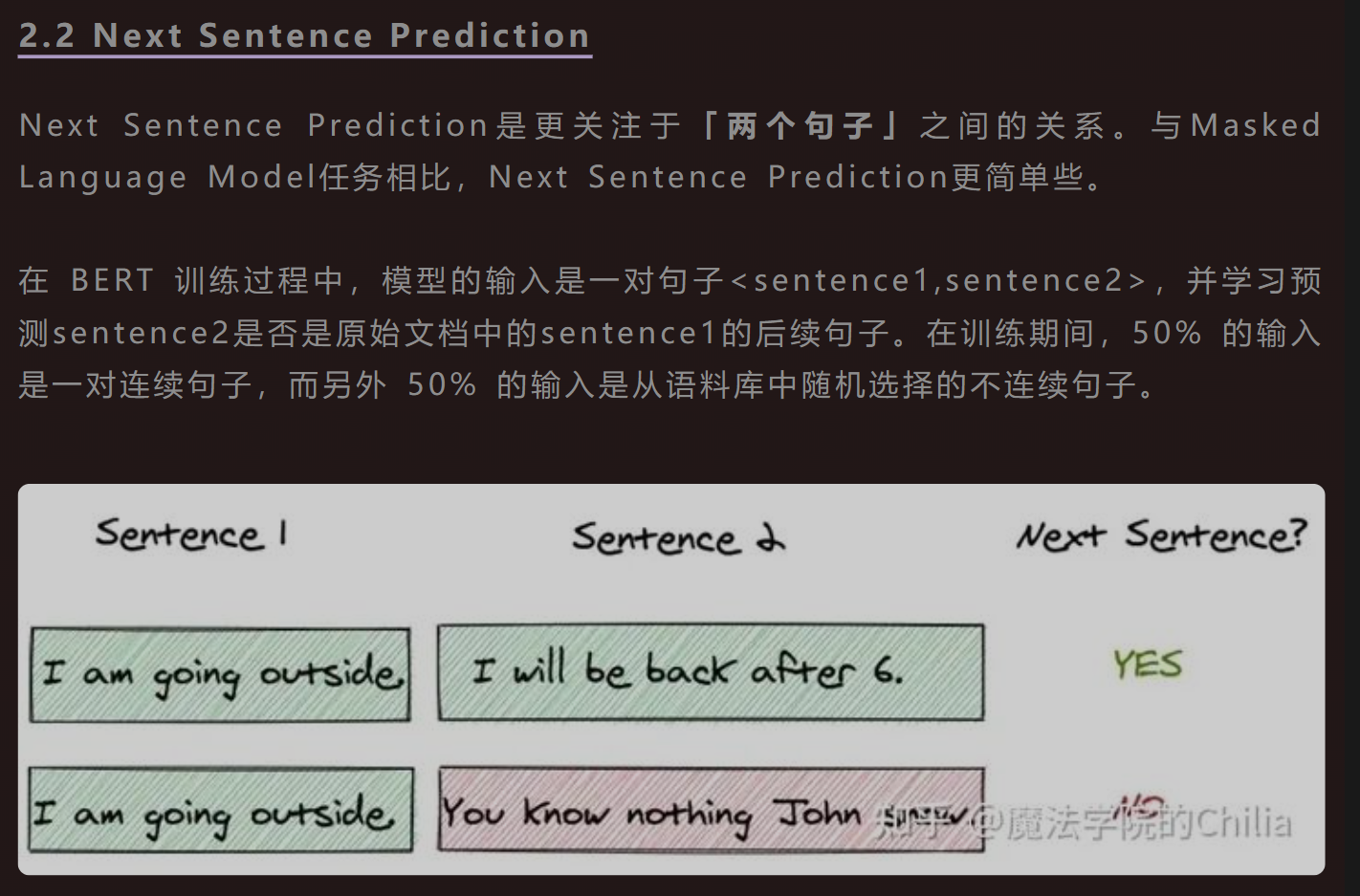
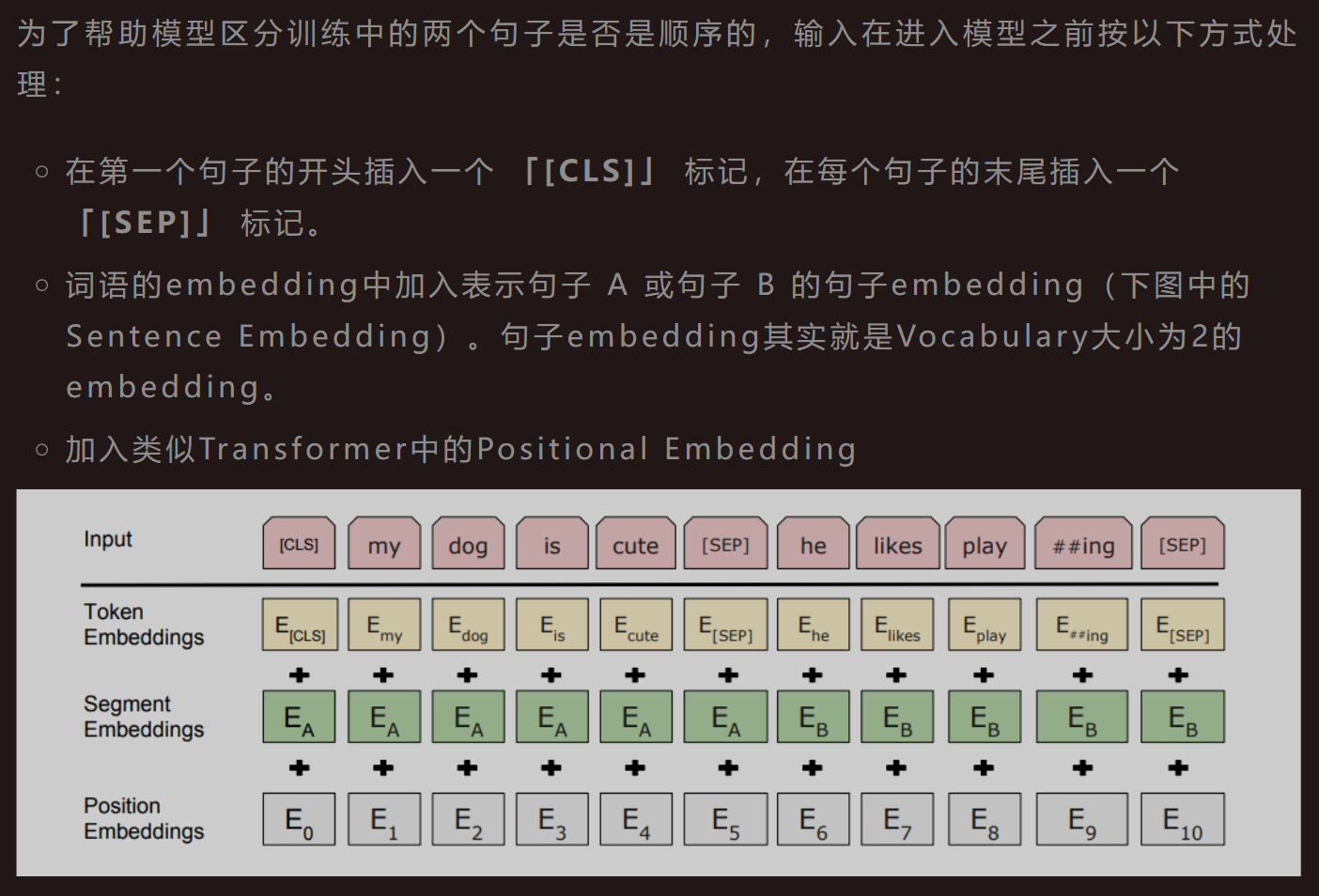
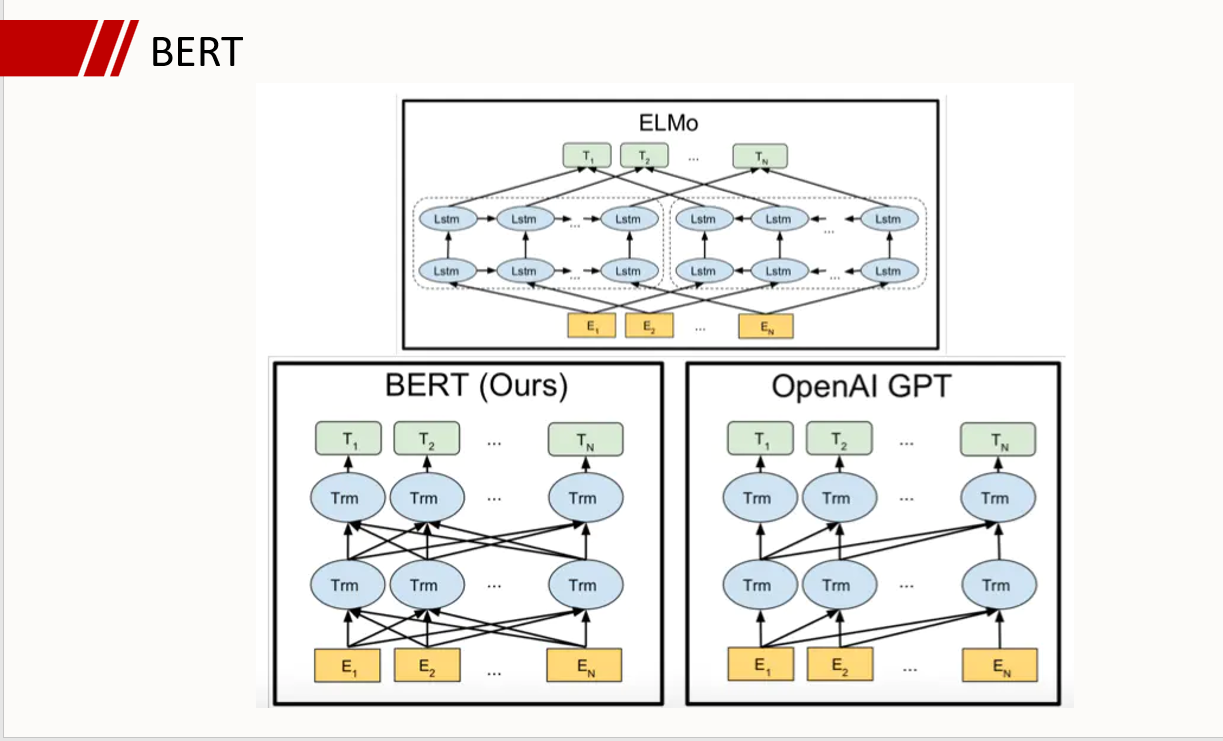
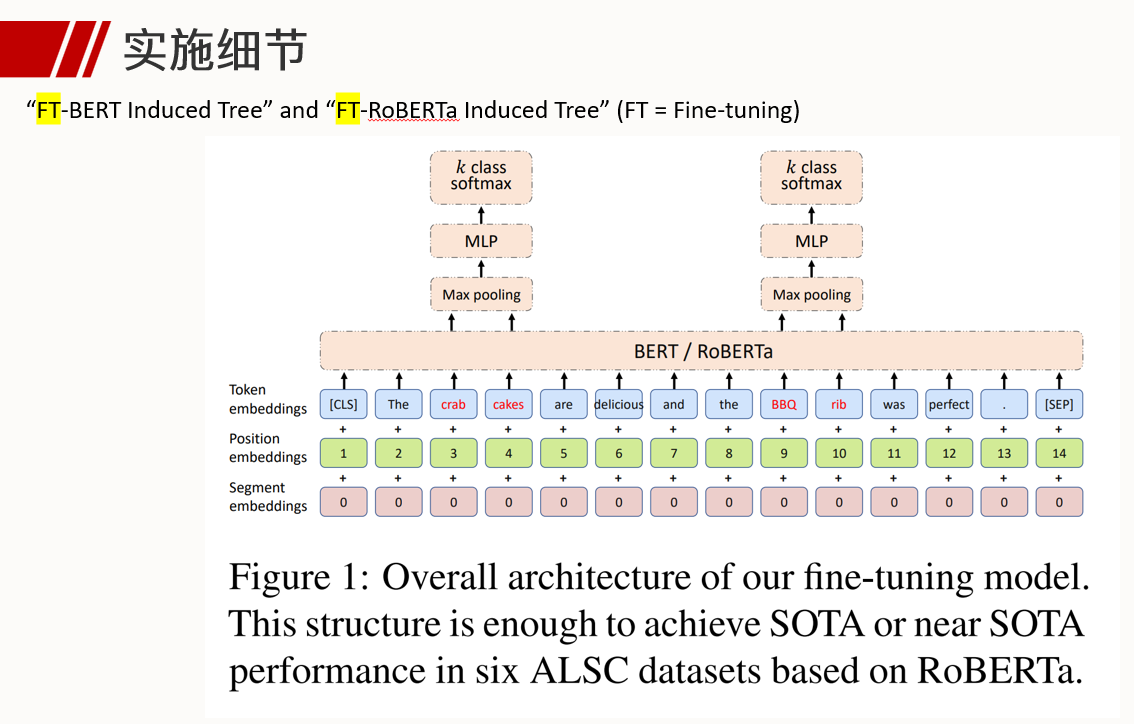
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Transformer的decoder部分为单向模型,因为文本生成需要从左向右依次预测下一个位置上的字母;而encoder部分则为双向模型,因为每一个位置上的token都整合了其余位置上所有token的信息。概括来说,BERT模型是深度堆叠的Transformer,并且只利用了其中encoder部分的模型。







https://zhuanlan.zhihu.com/p/98855346


https://www.cnblogs.com/gaowenxingxing/p/15005130.html,博客园
https://www.zhihu.com/question/425387974,知乎问答











; SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis


- 上述提到的情感词的极性,可以理解为给定词语蕴涵积极或消极的意义。那么如何理解以上三类先验知识呢?首先,为了让特征提取器对情感词更敏感,需要在预训练阶段接受情感词的特征信息。其次,模型知道一个词是不是情感词之后,还需要知道这个情感词的意义是积极的还是消极的。另外,假设一条影评”电影很好看,但是爆米花不好吃”,我们该如何做情感分析呢?文中引入了属性词-情感词对的说法,在这个例子中就是”电影-好看”、”爆米花-不好吃”,强化了属性与其对应的情感词之间的联系,而弱化了不相关的词间联系。通过消融实验发现这三种做法确实能够提高模型解释力。







- Reference:https://zhuanlan.zhihu.com/p/267837817
Leveraging Graph to Improve Abstractive Multi-Document Summarization
- key words: 文本生成和摘要、多文档输入、图神经网络
相关背景:
之前的许多模型诸如BERT,RoBERTa等等,均会限制输入的token数量不能超过512个。

利用本文提出的图模型,在BERT和预训练语言模型上进行改进,可以突破序列化结构对输入长度的限制,处理多文档的输入。

[CLS]: classifier, [SEP]: separator , [UNK]: unknow


- 本文的核心点在于使用图网络对段落间的相关度进行了测量,然后将这一权重作为全局注意力(global attention)进行计算,将预测出的第t个token与某一段中的第i个token之间的相关度作为局部注意力(local attention)进行计算,注意这个local attention通过global attention指导计算得到。

; Context-Guided BERT for Targeted Aspect-Based Sentiment Analysis




















Does syntax matter? A strong baseline for Aspect-based Sentiment Analysis with RoBERTa



- cosFormer
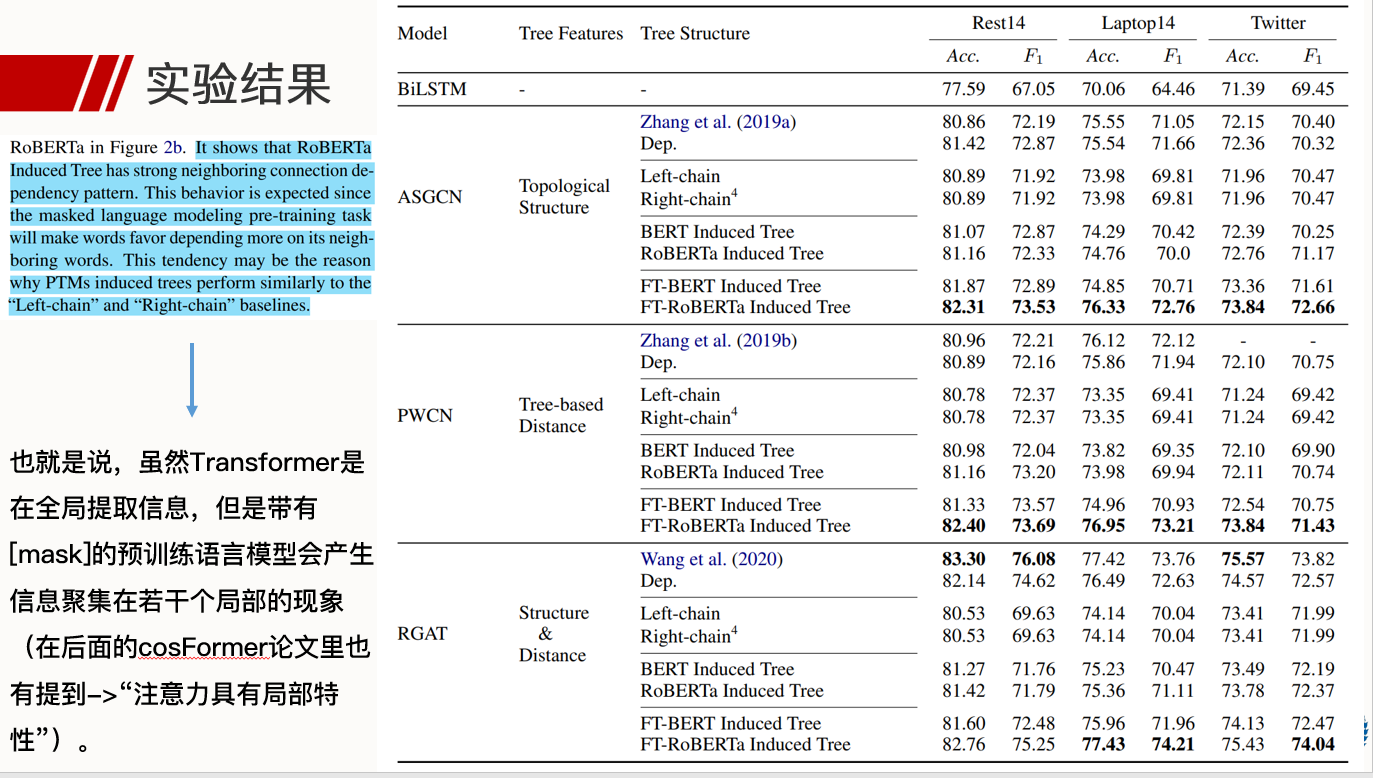



-
这里有两个问题:
-
pAsd的值为什么反而比Asd更大?
- 按照理解,Asd计算中,对某一个aspect来说引入了不属于他的”pair”内的sentiment的距离(在multi-aspect任务中),整体的加权平均,对于任何一种句法树来说,都没理由希望Asd的值最小,也就是说,在这里的Asd即使达到最小值并没有解释力。


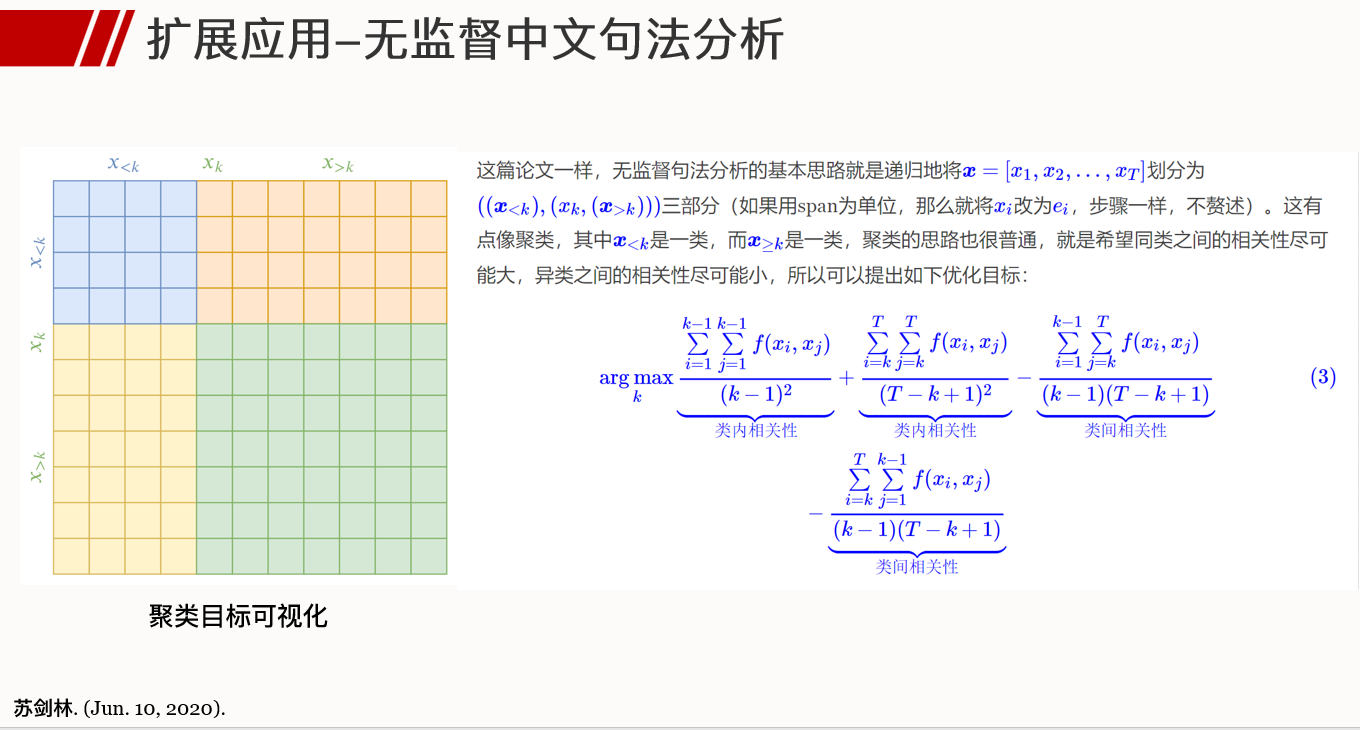
; Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT
I n t r o d u c t i o n Introduction I n t ro d u c t i o n
- 近些年,预训练语言模型E L M o 、 B E R T 、 X L N e t ELMo、BERT、XLNet E L M o 、BERT 、X L N e t在各种下游任务中都实现了SOTA。为了更深入的了解预训练语言模型,许多探针任务被设计出来。探针(probe)通常是一个简单的神经网络(具有少量的额外参数),其使用预训练语言模型输出的特征向量,并执行某些简单任务(需要标注数据)。通常来说,探针的表现可以间接的衡量预训练语言模型生成向量的表现。
- 基于探针的方法最大的缺点是需要引入额外的参数,这将使最终的结果难以解释,难以区分是预训练语言模型捕获了语义信息还是探针任务学习到了下游任务的知识,并将其编码至引入的额外参数中。
- 本文提出了一种称为Perturbed Masking的无参数探针,其能用于分析和解释预训练语言模型。
- Perturbed Masking通过改进M L M MLM M L M(Masked Language Model)任务的目标函数来衡量单词x j x_j x j 对于预测x i x_i x i 的重要性。
推荐阅读:
https://www.pianshen.com/article/40441703264/
https://spaces.ac.cn/archives/7476















- 以下内容来自:https://mp.weixin.qq.com/s/7qbonGz2u9e6BQ444IJbWw




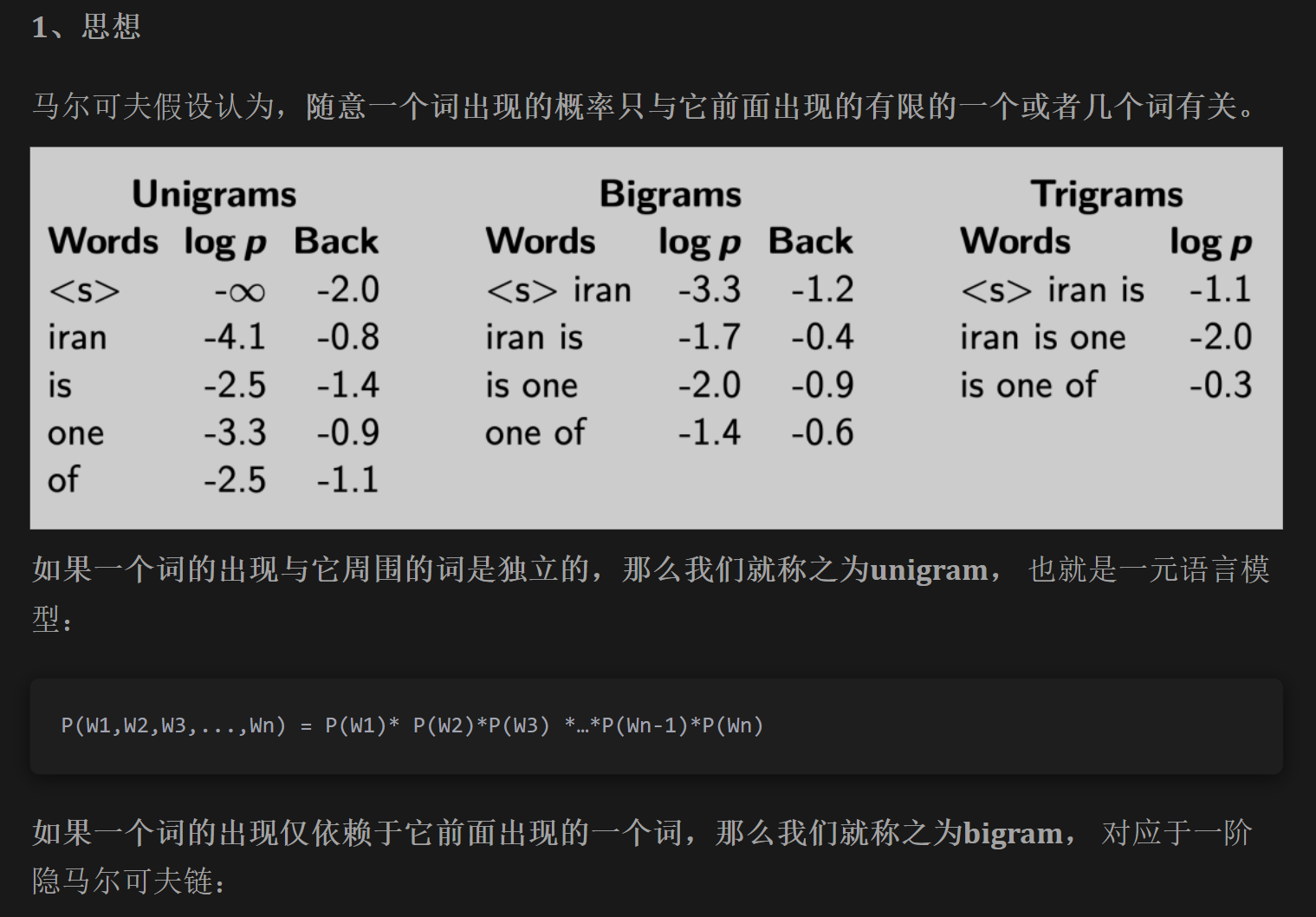




- 以下,https://mp.weixin.qq.com/s/cUk-bORVqqcYj-oQtDx21A









- p(A·B)

- 分层设置学习率,靠近输入的层提取底层的共性特征,靠近输出的层提取高级的(特定场景)专有特征。微调时,靠近输入层的学习率就应该比较小。这个想法其实对于CV领域的效果会更好。有人做实验,使用ImageNet数据集预训练的模型,用在汉字识别上,只训练最后的全连接层(frozen前面所有卷积层的参数),就取得了与前人相近的实验结果,也是这个道理。
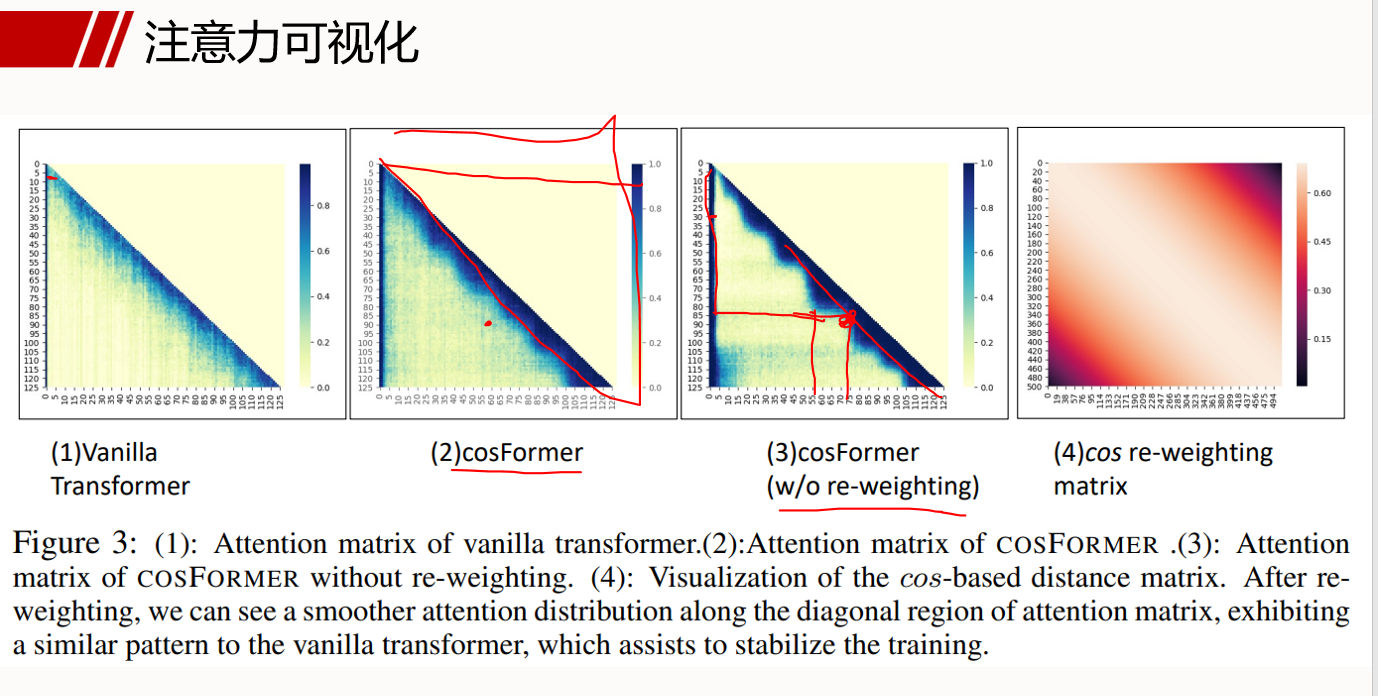
; COSFORMER : RETHINKING SOFTMAX IN ATTENTION
- 推荐阅读:https://www.freesion.com/article/1548803712/
- transformer:
q u e r y = X ∗ W Q , k e y = X ∗ W K , v a l u e = X ∗ W V ( q u e r y , k e y ∈ R n × d 1 , v a l u e ∈ R n × d 2 ) query = X * W^Q, key = X * W^K, value = X * W^V (query, key ∈ R^{n \times d_1}, value ∈ R^{n \times d_2})q u ery =X ∗W Q ,k ey =X ∗W K ,v a l u e =X ∗W V (q u ery ,k ey ∈R n ×d 1 ,v a l u e ∈R n ×d 2 ) - cosFormer:
M ≥ N M \geq N M ≥N

- o u t p u t ∈ R n × d 2 output∈R^{n \times d_2}o u tp u t ∈R n ×d 2
- s o f t m a x ( A ⋅ B ) ≠ s o f t m a x ( A ) × s o f t m a x ( B ) softmax(A·B) \neq softmax(A) \times softmax(B)so f t ma x (A ⋅B )=so f t ma x (A )×so f t ma x (B )




在另一篇论文中,题出最终的注意力系数取{-1, 0, 1, 2}的情况,我也认为系数应该越丰富越好,但是本文中认为在相关矩阵中负数是一种冗余的数据,剔除掉之后实验效果更好。



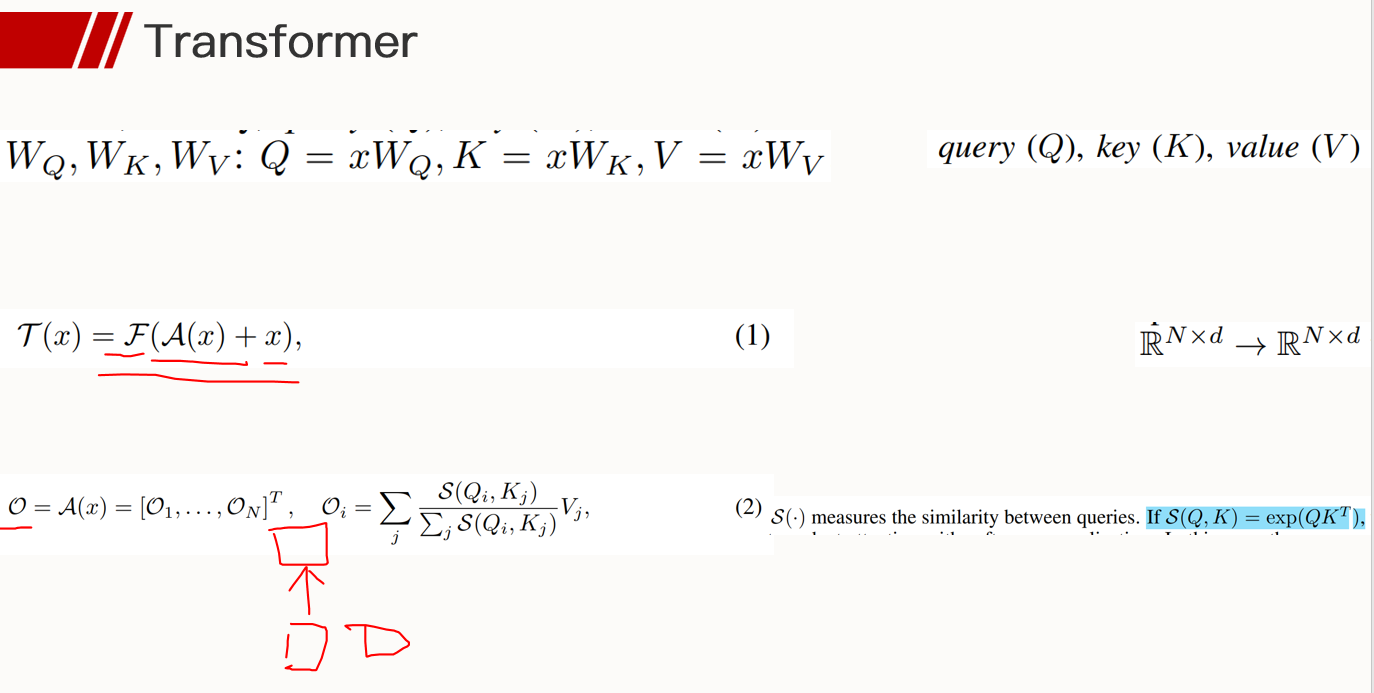














; Label Confusion Learning to Enhance Text Classification Models
















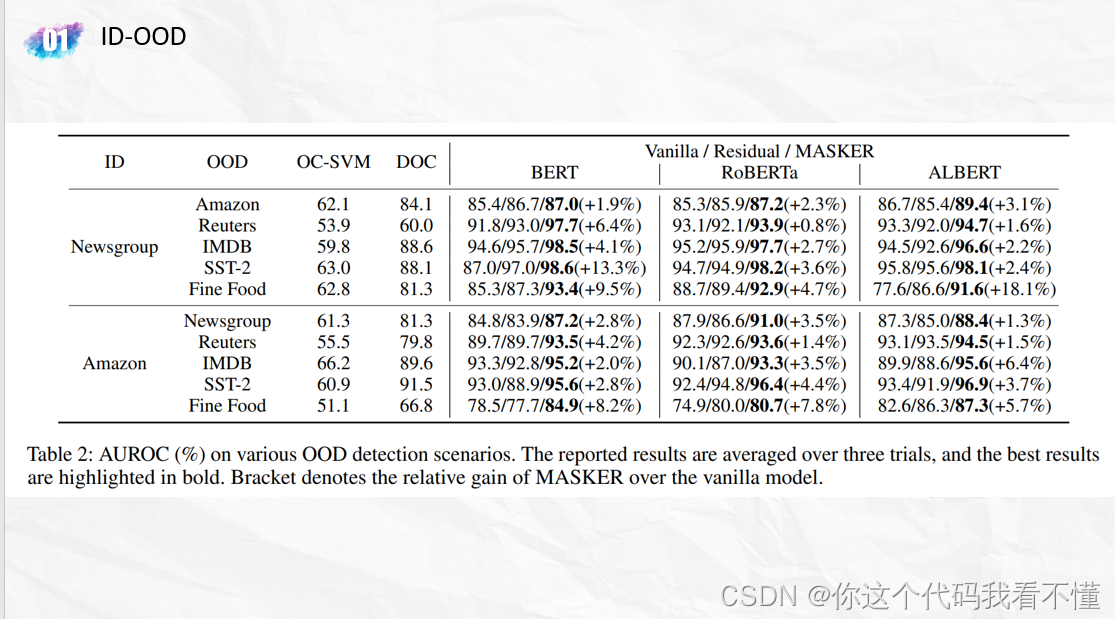
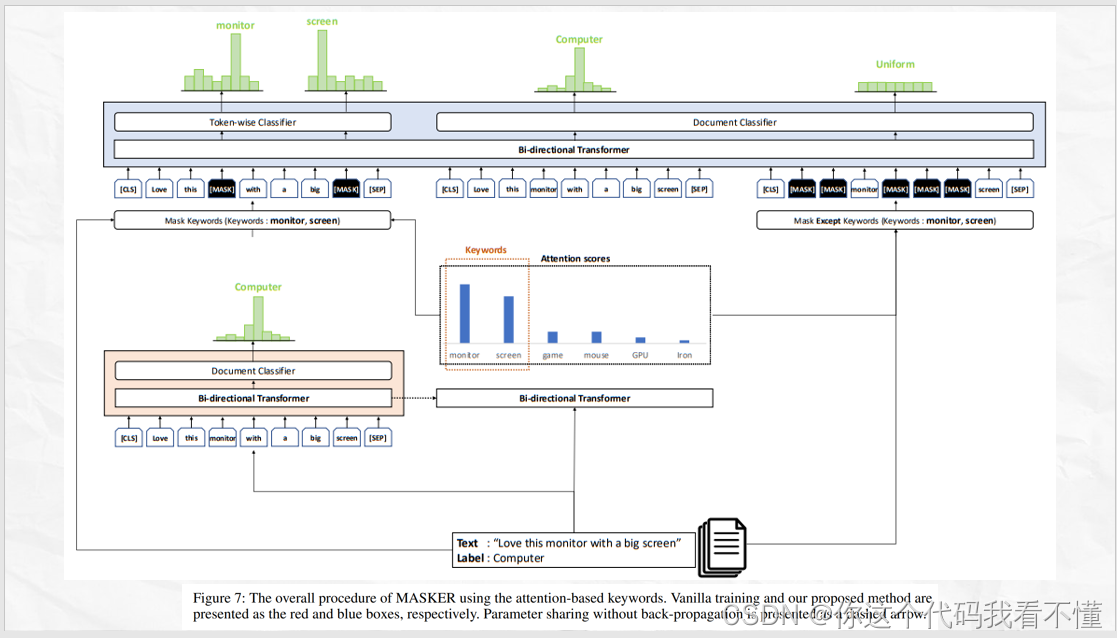
MASKER: Masked Keyword Regularization for Reliable Text Classification
Convolutional Neural Networks for Sentence Classification
























; Ideography Leads Us to the Field of Cognition: A Radical-Guided Associative Model for Chinese Text Classification



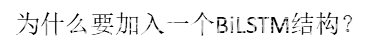









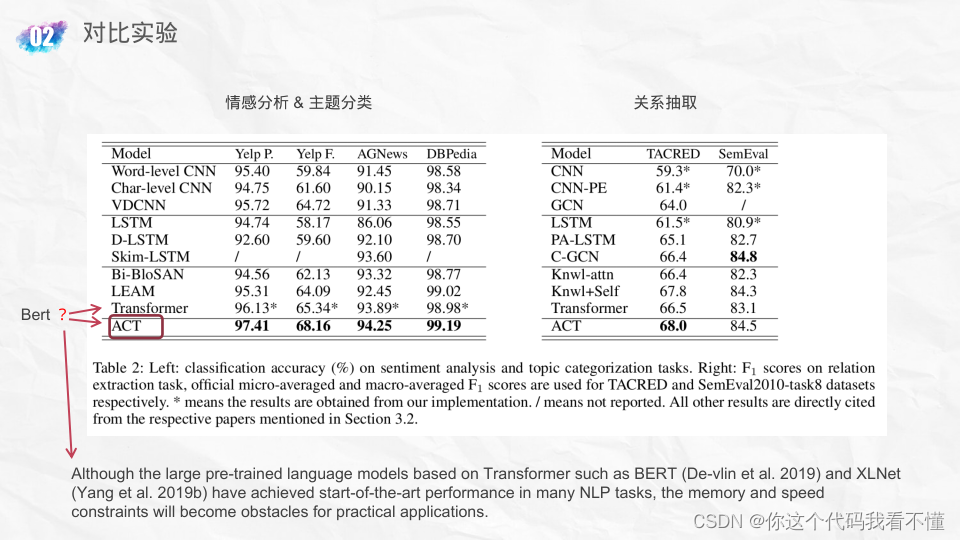
ACT: an Attentive Convolutional Transformer for Efficient Text Classification

由于需要构建知识图谱,所以在实体识别的基础上,我们需要构建一个模型来识别同一个句子中实体间的关系。关系抽取本身是一个分类问题。给定两个实体和两个实体共同出现的句子文本,判别两个实体之间的关系。
&多头
bert-12/24


; Merging Statistical Feature via Adaptive Gate for Improved Text Classification

TCoL字典 V 仅从训练集获得,防止信息泄露。
似然估计

而由x->z是识别模型\phi,类似于自编码器的编码器。
z为原因
p(z)先验概率
p(z|ζ)后验概率
p(ζ|z)似然估计

(K · Q · V)
- 交叉注意力
- 自注意力


Pytorch实战
初识Pytorch
使用GPU进行训练:

测试:

加载数据:

训练:

准确率:

; 初识词表
vocab.pkl
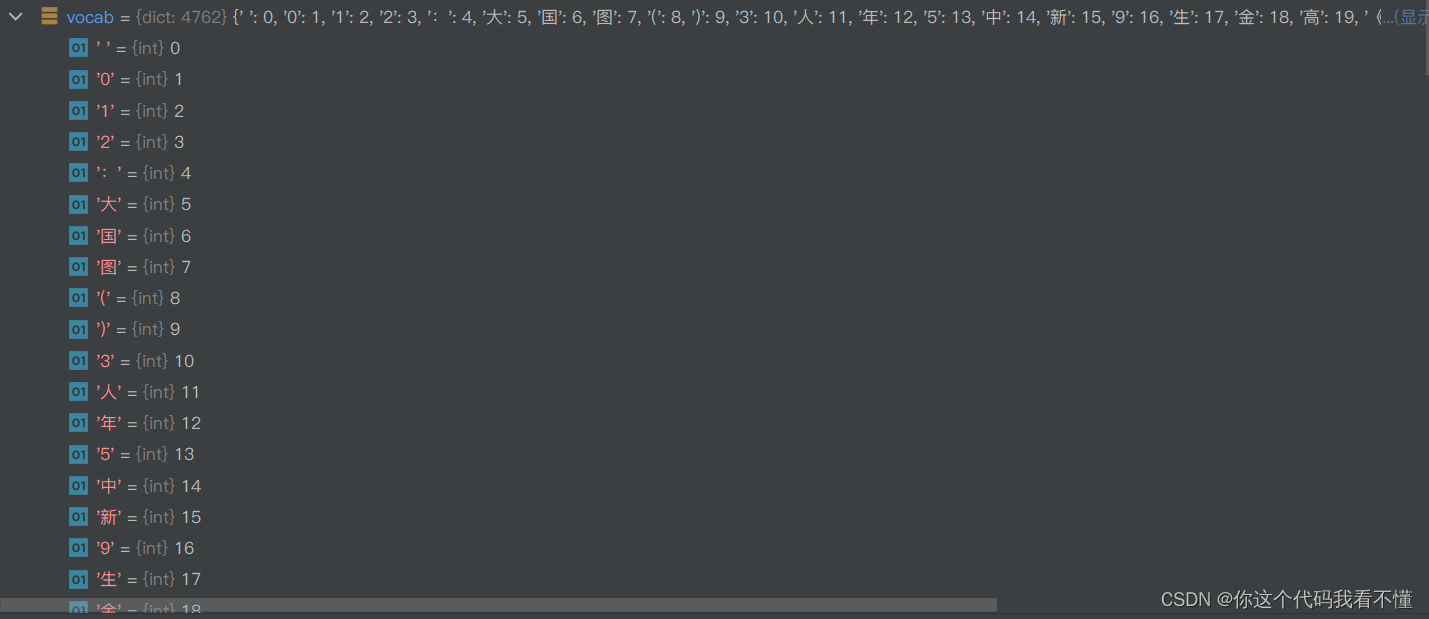
加载词表或构建词表:
if os.path.exists(config.vocab_path):
vocab = pkl.load(open(config.vocab_path, 'rb'))
else:
vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)
pkl.dump(vocab, open(config.vocab_path, 'wb'))
print(f"Vocab size: {len(vocab)}")
def build_vocab(file_path, tokenizer, max_size, min_freq):
vocab_dic = {}
with open(file_path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content = lin.split('\t')[0]
for word in tokenizer(content):
vocab_dic[word] = vocab_dic.get(word, 0) + 1
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]
vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}
'''
tinydict = {'Name': 'Runoob', 'Age': 7}
tinydict2 = {'Sex': 'female' }
tinydict.update(tinydict2)
>>
tinydict : {'Name': 'Runoob', 'Age': 7, 'Sex': 'female'}
'''
vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})
return vocab_dic
词嵌入
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
out = self.embedding(x[0])

embedding_SougouNews.npz


TextCNN-Pytorch代码
run.py
import time
import torch
import numpy as np
from train_eval import train, init_network, test
from importlib import import_module
import argparse
from tensorboardX import SummaryWriter
parser = argparse.ArgumentParser(description='Chinese Text Classification')
parser.add_argument('--model', default='TextCNN', type=str,
help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')
parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained')
parser.add_argument('--word', default=False, type=bool, help='True for word, False for char')
args = parser.parse_args()
if __name__ == '__main__':
dataset = 'THUCNews'
embedding = 'embedding_SougouNews.npz'
if args.embedding == 'random':
embedding = 'random'
model_name = args.model
if model_name == 'FastText':
from utils_fasttext import build_dataset, build_iterator, get_time_dif
embedding = 'random'
else:
from utils import build_dataset, build_iterator, get_time_dif
x = import_module('models.' + model_name)
config = x.Config(dataset, embedding)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True
start_time = time.time()
print("Loading data...")
vocab, train_data, dev_data, test_data = build_dataset(config, args.word)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
config.n_vocab = len(vocab)
model = x.Model(config).to(config.device)
writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))
if model_name != 'Transformer':
init_network(model)
print(model.parameters)
test(config, model, test_iter)
train_eval.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
import pickle as pkl
from tensorboardX import SummaryWriter
import csv
def get_key(_dict_, val):
for key, value in _dict_.items():
if value == val:
return key
return 'Key Not Found'
def init_network(model, method='xavier', exclude='embedding', seed=123):
for name, w in model.named_parameters():
if exclude not in name:
if 'weight' in name:
if method == 'xavier':
nn.init.xavier_normal_(w)
elif method == 'kaiming':
nn.init.kaiming_normal_(w)
else:
nn.init.normal_(w)
elif 'bias' in name:
nn.init.constant_(w, 0)
else:
pass
def train(config, model, train_iter, dev_iter, test_iter, writer):
start_time = time.time()
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
total_batch = 0
dev_best_loss = float('inf')
last_improve = 0
flag = False
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
writer.add_scalar("loss/train", loss.item(), total_batch)
writer.add_scalar("loss/dev", dev_loss, total_batch)
writer.add_scalar("acc/train", train_acc, total_batch)
writer.add_scalar("acc/dev", dev_acc, total_batch)
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
writer.close()
test(config, model, test_iter)
def test(config, model, test_iter):
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def evaluate(config, model, data_iter, test=False):
print(config.class_list)
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
vocab = pkl.load(open(config.vocab_path, 'rb'))
file = open("saved\\predict.csv", "w", newline='', encoding="utf-8-sig")
label_txt = open("THUCNews\\data\\test.txt", "r", encoding="utf-8")
lines = label_txt.readlines()
num = 0
with torch.no_grad():
for texts, labels in data_iter:
if len(texts[0]) < config.batch_size:
print("当前batch size不足,跳出")
break
outputs = model(texts)
for row in range(config.batch_size):
_str_ = lines[num]
num += 1
_str_ = _str_.strip('\n')
_str_ = _str_.replace(_str_[-1], "")
label = labels[row].item()
output = torch.argmax(outputs[row], -1).item()
csv_file = csv.writer(file)
csv_file.writerow([_str_, config.class_list[output], config.class_list[label]])
loss = F.cross_entropy(outputs, labels)
loss_total += loss
print(labels)
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
file.close()
label_txt.close()
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)
utils.py
import os
import torch
import numpy as np
import pickle as pkl
from tqdm import tqdm
import time
from datetime import timedelta
MAX_VOCAB_SIZE = 10000
UNK, PAD = '', ''
'''
tqdm # python进度条函数
from tqdm import tqdm
import time
d = {'loss':0.2,'learn':0.8}
for i in tqdm(range(50),desc='进行中',ncols=10,postfix=d): #desc设置名称,ncols设置进度条长度.postfix以字典形式传入详细信息
time.sleep(0.1)
pass
'''
def build_vocab(file_path, tokenizer, max_size, min_freq):
vocab_dic = {}
with open(file_path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content = lin.split('\t')[0]
for word in tokenizer(content):
vocab_dic[word] = vocab_dic.get(word, 0) + 1
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]
vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}
'''
tinydict = {'Name': 'Runoob', 'Age': 7}
tinydict2 = {'Sex': 'female' }
tinydict.update(tinydict2)
>>
tinydict : {'Name': 'Runoob', 'Age': 7, 'Sex': 'female'}
'''
vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})
return vocab_dic
def build_dataset(config, ues_word):
if ues_word:
tokenizer = lambda x: x.split(' ')
else:
tokenizer = lambda x: [y for y in x]
if os.path.exists(config.vocab_path):
vocab = pkl.load(open(config.vocab_path, 'rb'))
else:
vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)
pkl.dump(vocab, open(config.vocab_path, 'wb'))
print(f"Vocab size: {len(vocab)}")
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content, label = lin.split('\t')
words_line = []
token = tokenizer(content)
seq_len = len(token)
if pad_size:
if len(token) < pad_size:
token.extend([vocab.get(PAD)] * (pad_size - len(token)))
'''
In[36]: ["hi"]*3
Out[36]: ['hi', 'hi', 'hi']
'''
else:
token = token[:pad_size]
seq_len = pad_size
for word in token:
words_line.append(vocab.get(word, vocab.get(UNK)))
contents.append((words_line, int(label), seq_len))
return contents
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return vocab, train, dev, test
class DatasetIterater(object):
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
self.n_batches = len(batches) // batch_size
self.residue = False
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas):
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
return (x, seq_len), y
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)
return batches
elif self.index > self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
def build_iterator(dataset, config):
iter = DatasetIterater(dataset, config.batch_size, config.device)
return iter
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
if __name__ == "__main__":
'''提取预训练词向量'''
train_dir = "./THUCNews/data/train.txt"
vocab_dir = "./THUCNews/data/vocab.pkl"
pretrain_dir = "./THUCNews/data/sgns.sogou.char"
emb_dim = 300
filename_trimmed_dir = "./THUCNews/data/embedding_SougouNews"
if os.path.exists(vocab_dir):
word_to_id = pkl.load(open(vocab_dir, 'rb'))
else:
tokenizer = lambda x: [y for y in x]
word_to_id = build_vocab(train_dir, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)
pkl.dump(word_to_id, open(vocab_dir, 'wb'))
embeddings = np.random.rand(len(word_to_id), emb_dim)
f = open(pretrain_dir, "r", encoding='UTF-8')
for i, line in enumerate(f.readlines()):
lin = line.strip().split(" ")
if lin[0] in word_to_id:
idx = word_to_id[lin[0]]
emb = [float(x) for x in lin[1:301]]
embeddings[idx] = np.asarray(emb, dtype='float32')
f.close()
np.savez_compressed(filename_trimmed_dir, embeddings=embeddings)
models.TextCNN.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextCNN'
self.train_path = dataset + '/data/train.txt'
self.dev_path = dataset + '/data/dev.txt'
self.test_path = dataset + '/data/test.txt'
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()]
self.vocab_path = dataset + '/data/vocab.pkl'
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.dropout = 0.5
self.require_improvement = 1000
self.num_classes = len(self.class_list)
self.n_vocab = 0
self.num_epochs = 20
self.batch_size = 128
self.pad_size = 32
self.learning_rate = 1e-3
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300
self.filter_sizes = (2, 3, 4)
self.num_filters = 256
'''Convolutional Neural Networks for Sentence Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
out = self.embedding(x[0])
out = out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
return out
简单CNN二分类Pytorch实现
main.py
from torch.utils.data import DataLoader
from loadDatasets import *
from model import *
import torchvision
import torch
torch.set_default_tensor_type(torch.DoubleTensor)
torch.autograd.set_detect_anomaly = True
gpu_device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
if __name__ == '__main__':
batch_size = myModel.batch_size
train_data = myDataLoader('train.csv', 'datasets', transform=torchvision.transforms.ToTensor())
print("训练集数量{}".format(len(train_data)))
dev_data = myDataLoader('dev.csv', 'datasets', transform=torchvision.transforms.ToTensor())
print("验证集数量{}".format(len(dev_data)))
valid_batch_size = len(dev_data) // (len(train_data)/batch_size)
valid_batch_size = int(valid_batch_size)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_data, batch_size=valid_batch_size, shuffle=True)
cnn_model = myModel()
cnn_model.load_state_dict(torch.load("model\\cnn_model.pth"), strict=False)
cnn_model = cnn_model.to(gpu_device)
loss_fun = nn.CrossEntropyLoss()
loss_fun = loss_fun.to(gpu_device)
epochs = 2
optimizer = torch.optim.Adam(cnn_model.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
eps=1e-08,
weight_decay=0,
amsgrad=False)
total_train_step = 0
for epoch in range(epochs):
print("===========第{}轮训练开始===========".format(epoch + 1))
for trainData, validData in zip(train_loader, dev_loader):
train_seq, train_label = trainData
valid_seq, valid_label = validData
batch_size_train = len(train_seq)
batch_size_valid = len(valid_seq)
if batch_size_train < batch_size or batch_size_valid < valid_batch_size:
print("当前不足一个batch_size,停止训练")
break
train_seq = train_seq.to(gpu_device)
train_label = train_label.to(gpu_device)
valid_seq = valid_seq.to(gpu_device)
valid_label = valid_label.to(gpu_device)
cnn_model.from_type = "train"
train_output = cnn_model(train_seq)
train_output = train_output.to(gpu_device)
cnn_model.from_type = "valid"
cnn_model.valid_batch_size = valid_batch_size
loss = loss_fun(train_output, train_label)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
total_train_step += 1
cnn_channel = ""
if (train_output.argmax(1) == train_label).sum() / batch_size > 0.65:
if cnn_model.channel["cnn1"]["status"]:
cnn_model.channel["cnn1"]["prob"] *= 1.0005
cnn_channel = "cnn1"
else:
cnn_model.channel["cnn2"]["prob"] *= 1.0005
cnn_channel = "cnn2"
if total_train_step % 50 == 0:
print("训练次数{},当前损失值 --------- {}".format(total_train_step, loss))
accuracy_train = (train_output.argmax(1) == train_label).sum() / batch_size
print("batch train-accuracy {}%".format(accuracy_train * 100))
print("model total_num {}".format(cnn_model.total_num))
print("当前执行的通道 {}".format(cnn_channel))
prob1 = cnn_model.channel["cnn1"]["prob"] / (cnn_model.channel["cnn1"]["prob"] + cnn_model.channel["cnn2"]["prob"])
prob2 = cnn_model.channel["cnn2"]["prob"] / (cnn_model.channel["cnn1"]["prob"] + cnn_model.channel["cnn2"]["prob"])
print("通道1概率值 {} 通道2概率值{}".format(prob1, prob2))
torch.save(cnn_model.state_dict(), "model\\cnn_model.pth")
test.py
import torch
import torchvision
from torch.utils.data import DataLoader
from loadDatasets import myDataLoader
from model import myModel
import csv
torch.set_default_tensor_type(torch.DoubleTensor)
torch.autograd.set_detect_anomaly = True
test_batch_size = 1024
gpu_device = torch.device("cuda:0")
test_data = myDataLoader('test.csv', 'datasets', transform=torchvision.transforms.ToTensor())
print("测试集数量{}".format(len(test_data)))
test_loader = DataLoader(test_data, batch_size=test_batch_size, shuffle=True)
cnn_model = myModel()
cnn_model.load_state_dict(torch.load("model\\cnn_model.pth"), strict=False)
cnn_model.eval()
cnn_model = cnn_model.to(gpu_device)
test_size = 0
test_num = 0
for testData in test_loader:
test_seq, test_label = testData
test_seq = test_seq.to(gpu_device)
test_label = test_label.to(gpu_device)
batch_size_test = len(test_seq)
if batch_size_test < test_batch_size:
print("当前不足一个batch_size,停止训练")
break
cnn_model.from_type = "test"
test_output = cnn_model.forward(test_seq)
test_output = test_output.to(gpu_device)
test_size += test_batch_size
test_num += (test_output.argmax(1) == test_label).sum()
result_csv = open("result\\result.csv", "a")
csv_write = csv.writer(result_csv)
csv_write.writerow(['概率分布', '预测值', '真实值'])
for predict, label in zip(test_output, test_label):
probability_distribution = "[" + str(predict[0].to(torch.float64).item()) + "," + str(predict[1].to(torch.float64).item()) + "]"
label = label.item()
predict_cls = predict.view(-1, 2).argmax(1)
predict_cls = predict_cls.item()
csv_write.writerow([probability_distribution, predict_cls, label])
result_csv.close()
accuracy_test = test_num / test_size
print("total test-accuracy {}%".format(accuracy_test * 100))
model.py
import random
import torch.nn as nn
import torch
torch.set_default_tensor_type(torch.DoubleTensor)
class myModel(nn.Module):
batch_size = 128
def __init__(self):
super().__init__()
self.from_type = ""
self.total_num = 0
self.cnn1_num = 0
self.cnn2_num = 0
self.current_batch_size = self.batch_size
self.valid_batch_size = self.batch_size
self.channel = {
"cnn1": {
"prob": 0.5,
"status": False
},
"cnn2": {
"prob": 0.5,
"status": False
}
}
self.cnn1 = nn.Sequential(
nn.Conv2d(1, 3, (1, 2), padding="same"),
nn.ReLU(inplace=False),
nn.Conv2d(3, 5, (1, 3)),
nn.ReLU(inplace=False),
nn.Conv2d(5, 7, (1, 5)),
nn.ReLU(inplace=False),
nn.Flatten(),
)
self.cnn2 = nn.Sequential(
nn.Conv2d(1, 2, (1, 2), padding="same"),
nn.ReLU(inplace=False),
nn.Conv2d(2, 4, (1, 3)),
nn.ReLU(inplace=False),
nn.Conv2d(4, 7, (1, 5)),
nn.ReLU(inplace=False),
nn.Flatten(),
)
self.fc = nn.Sequential(
nn.Linear(28, 14),
nn.Dropout(0.5),
nn.Linear(14, 7),
nn.ReLU(inplace=False),
nn.Linear(7, 2),
nn.Softmax()
)
def forward(self, x):
if self.from_type == "valid":
self.current_batch_size = self.valid_batch_size
else:
self.current_batch_size = self.batch_size
x = x.to(torch.device("cuda:0"))
self.total_num = self.total_num + 1
self.channel["cnn1"]["status"] = False
self.channel["cnn2"]["status"] = False
self.channel["cnn1"]["prob"] = self.channel["cnn1"]["prob"] / (
self.channel["cnn1"]["prob"] + self.channel["cnn2"]["prob"])
self.channel["cnn2"]["prob"] = self.channel["cnn2"]["prob"] / (
self.channel["cnn1"]["prob"] + self.channel["cnn2"]["prob"])
x1 = torch.zeros([self.batch_size, 28])
x2 = torch.zeros([self.batch_size, 28])
x1 = x1.to(torch.device("cuda:0"))
x2 = x2.to(torch.device("cuda:0"))
random_num = random.random()
if random_num < self.channel["cnn1"]["prob"]:
x1 = torch.relu(self.cnn1(x))
self.channel["cnn1"]["status"] = True
else:
x2 = torch.relu(self.cnn2(x))
self.channel["cnn2"]["status"] = True
x = (x1 * self.channel["cnn1"]["prob"] + x2 * self.channel["cnn2"]["prob"])
x = self.fc(x)
return x
loadDatasets.py
import os
import pandas as pd
import torch
from torch.utils.data import Dataset
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
class myDataLoader(Dataset):
def __init__(self, annotations_file, root_dir, transform=None, target_transform=None):
full_path = os.path.join(root_dir, annotations_file)
self.csv_data = pd.read_csv(full_path)
del self.csv_data['Unnamed: 0']
X = self.csv_data.drop('SeriousDlqin2yrs', axis=1)
y = self.csv_data['SeriousDlqin2yrs']
from imblearn.over_sampling import SMOTE
model_smote = SMOTE()
X, y = model_smote.fit_resample(X, y)
self.csv_data = pd.concat([y, X], axis=1)
self.length = len(self.csv_data)
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return self.length
def __getitem__(self, idx):
seq = self.csv_data.iloc[idx, 1:]
seq = np.array(seq)
seq = torch.tensor(seq)
seq = seq.reshape(1, 1, 10)
label = self.csv_data.iloc[idx][0]
label = torch.tensor(label).long().item()
return seq, label
- 卷积层参数量计算:

杂记



; 自定义损失函数踩坑
修改损失函数之后,发生了 grad==none的情况( train_output.grad):


虽然本项目的训练没有出现问题,最终损失值可以下降,但在另一个项目里边发生了损失不收敛的问题,所以目前无法确定是修改损失函数之后导致模型不收敛还是梯度没有反向传播回去(目前认为前者可能性更大一些,准备重新定义一个模型了)。
因为没有更多精力排查问题,所以现在暂时先避开可能导致出现这种问题的修改方式。建议对于模型输出的修改全部在 model类的 forward()中进行,尽量不要在损失函数中定义。
批归一化
num_features:特征的维度 (N,L) -> L ; (N,C,L) -> C:
class torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True) [source]
num_features:特征的维度 (N,C,X,Y) -> C:
class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)[source]
Con1d和Conv2d
Con1d和Conv2d的区别
图像的数据一般是三维的 W ∗ H ∗ C WHC W ∗H ∗C,文本的数据一般是二维的 L ∗ D L*D L ∗D
C C C 代表图像的通道数, D D D 代表词向量的维度。
k e r n e l _ s i z e kernel_size k er n e l _s i ze:卷积核的尺寸
在Conv2D中,是一个二维的元组 w ∗ h w*h w ∗h ,当然也可以传入整数,代表 w = = h w==h w ==h ;
在Conv1D中,是整数 l l l 。
- Conv2d:

如图,输入为7 ∗ 7 ∗ 3 773 7 ∗7 ∗3的图片,卷积核大小为3 ∗ 3 33 3 ∗3,卷积核个数为2 2 2,参数量为3 ∗ 3 ∗ 3 ∗ 2 3332 3 ∗3 ∗3 ∗2 - Conv1d:

如图,输入序列为3 ∗ 3 33 3 ∗3的文本,卷积核大小为2 2 2,个数为1 1 1,参数量为3 ∗ 2 ∗ 1 32*1 3 ∗2 ∗1 - shape
[1,
2,
3,
4]
[[12,45],
[33,58],
[60,17],
[10,82]]
torch.tensor([[12,45]]).shape
Out[31]: torch.Size([1, 2])
torch.tensor(
[[1],
[2],
[3],
[4]]).shape
Out[32]: torch.Size([4, 1])
torch.tensor(
[[[12,45],
[33,58],
[60,17],
[10,82]]]).shape
Out[34]: torch.Size([1, 4, 2])
膨胀卷积
- 普通卷积:

stride = 2, output_size = 3 - 膨胀卷积:

output_size = 3
参数量一致,输出大小不变,但增大了感受野。
这种效果类似于在卷积层之前添加了池化层,但膨胀卷积的作法可以在不增加参数量的情况下,保证输出维度不变。
; 稀疏Attention

- 膨胀注意力:
Atrous Self Attention就是启发于”膨胀卷积(Atrous Convolution)”,如下右图所示,它对相关性进行了约束,强行要求每个元素只跟它相对距离为k,2k,3k,…的元素关联,其中k>1是预先设定的超参数。

- Local Self Attention
显然Local Self Attention则要放弃全局关联,重新引入局部关联。具体来说也很简单,就是约束每个元素只与前后k k k个元素以及自身有关联,如下图所示:

- Sparse Self Attention
Atrous Self Attention是带有一些洞的,而Local Self Attention正好填补了这些洞,所以一个简单的方式就是将Local Self Attention和Atrous Self Attention交替使用,两者累积起来,理论上也可以学习到全局关联性,也省了显存。

Prompt Learning初探

- PL VS 传统的下游任务微调法:
fine-tuning做分类的为[CLS]位置的输出,而prompt learning为[mask]位置的输出,易演顶针,鉴定为醍醐灌顶。
; 固定bert参数的方法
手动反向传播和优化器
l o s s = ( x ∗ w − y ) 2 loss=(xw-y)^2 l oss =(x ∗w −y )2
g r a d w = 2 ∗ ( x ∗ w − y ) ∗ x grad_w=2(xw-y)x g r a d w =2 ∗(x ∗w −y )∗x
Visual Prompt Tuning (VPT)

- 固定住bert参数试一试

d一般为某数的平方(如果输入图像为正方形)

d_model / h

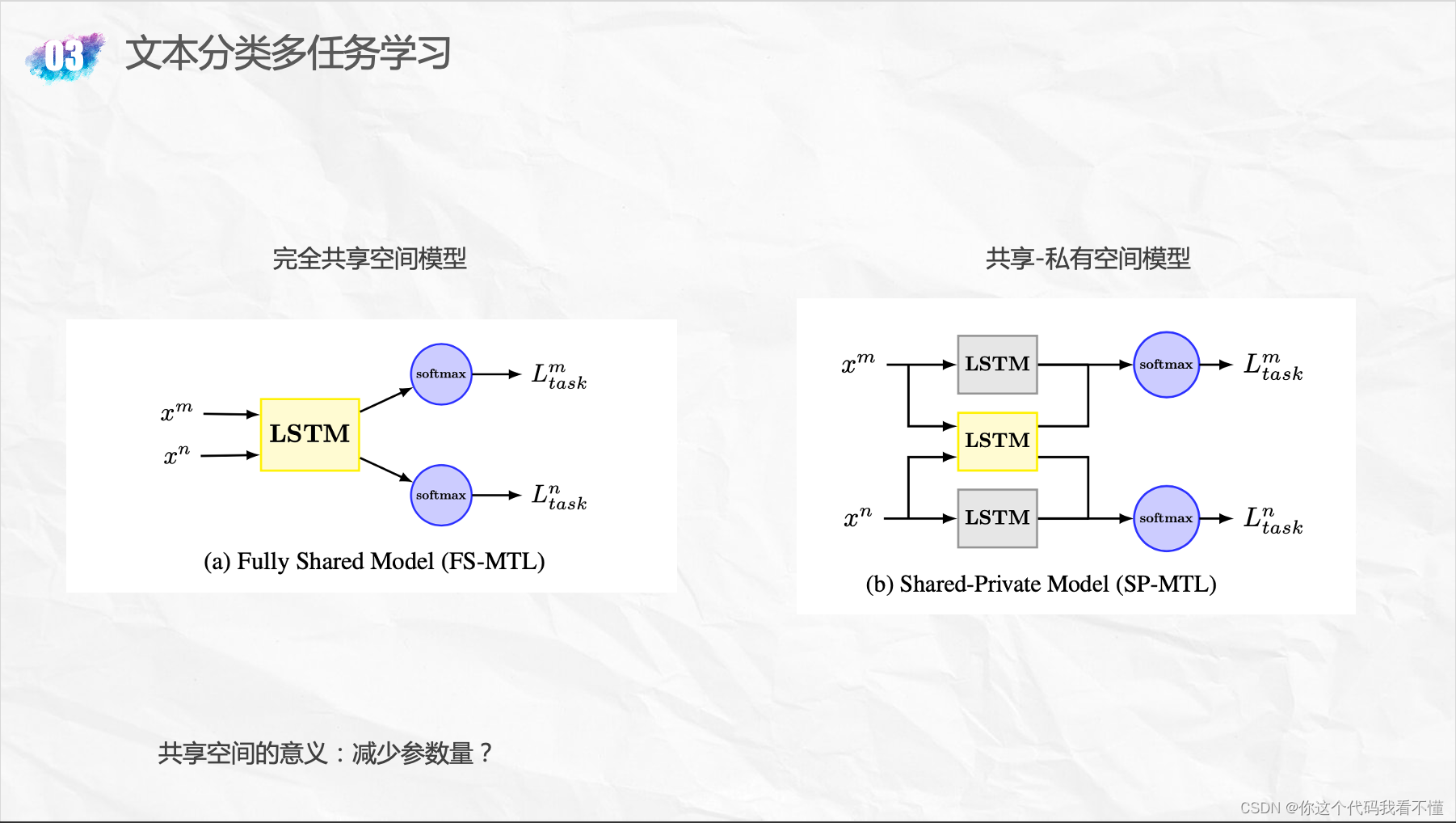
; Adversarial Multi-task Learning for Text Classification









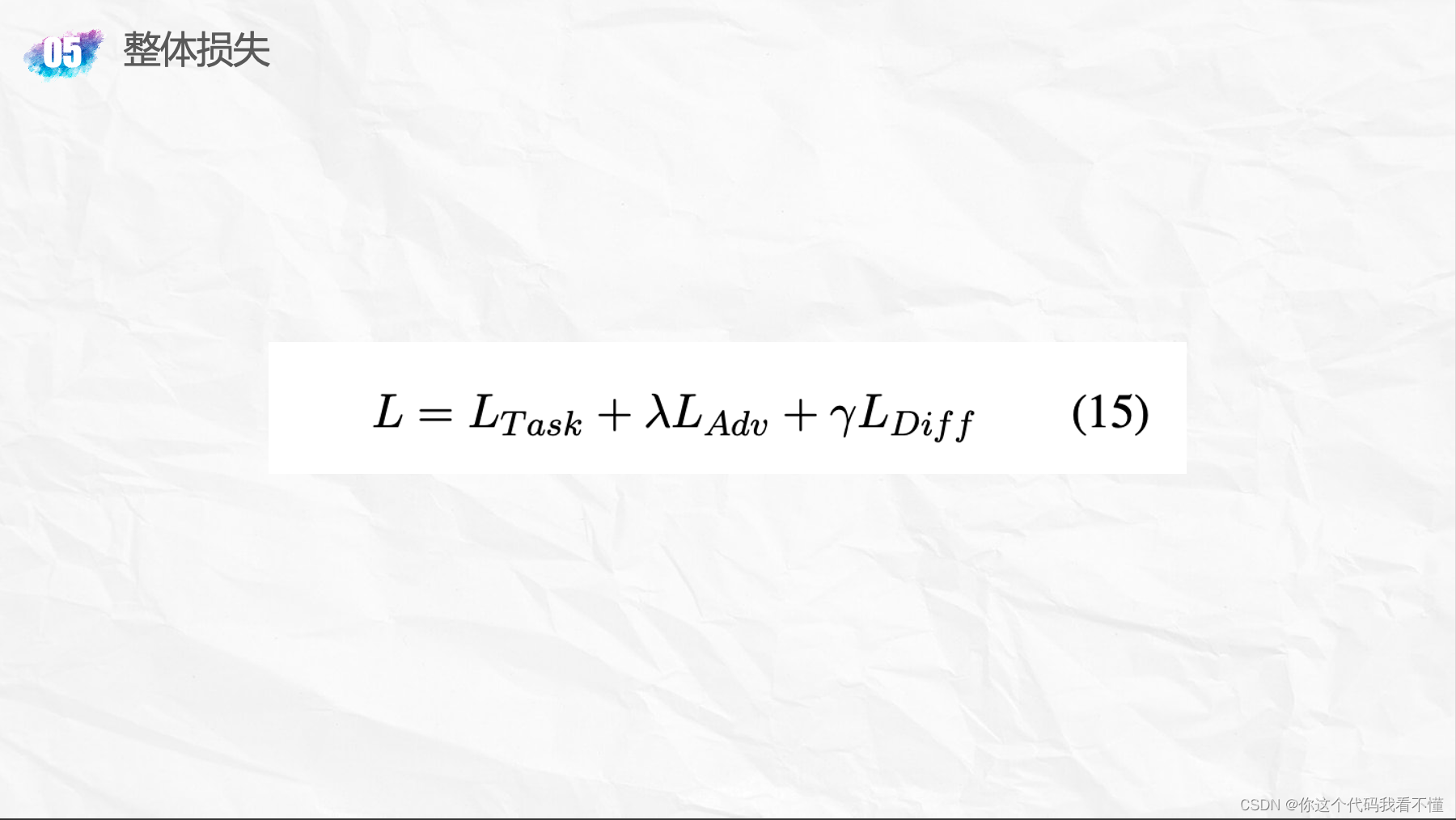





- 节省空间
reStructured Pre-training
















; Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer「谷歌:T5」


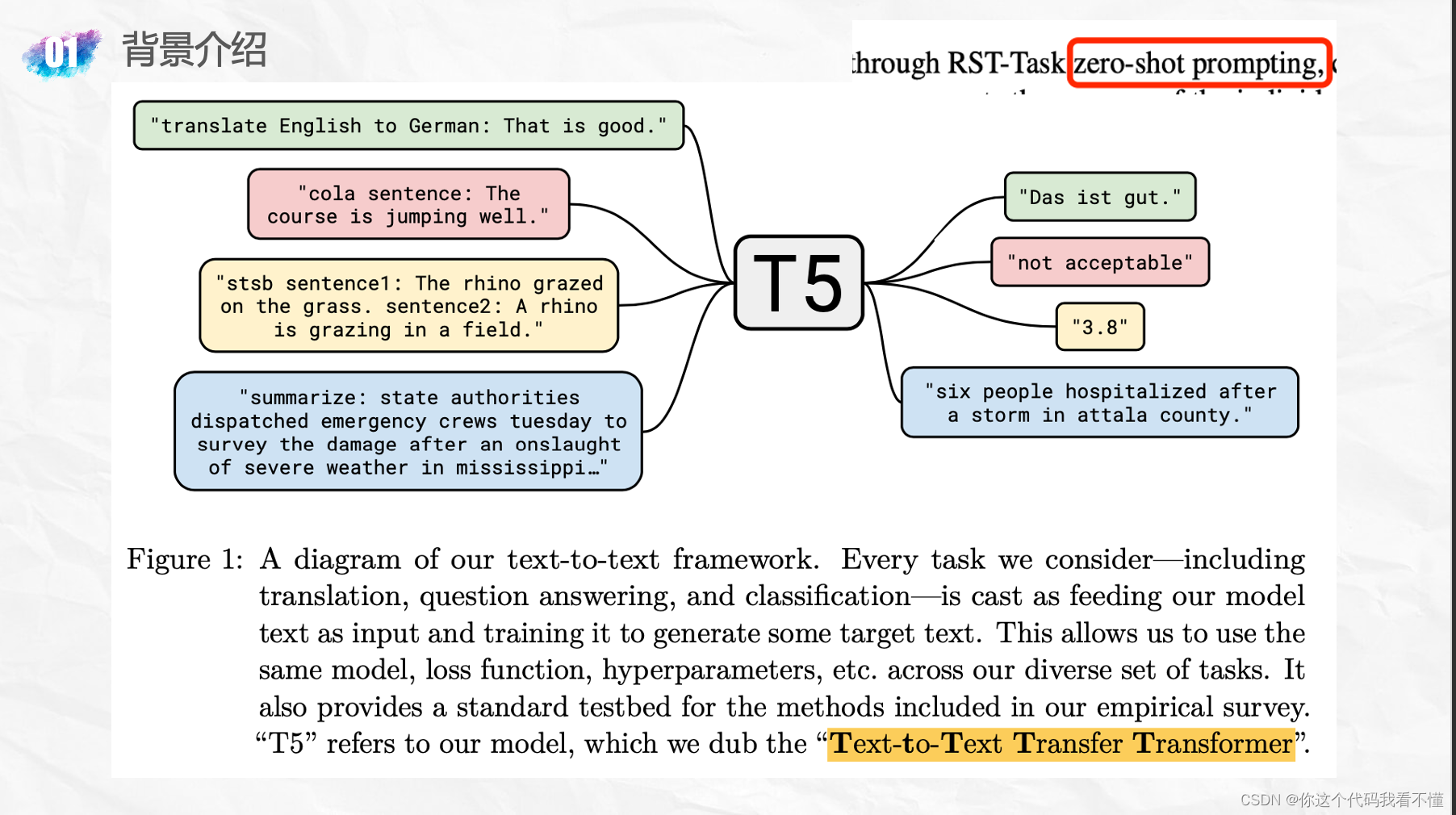














- 智慧的眼神?
( a + b ) m i n = a m i n + b m i n (a + b){min} = a{min} + b_{min}(a +b )min =a min +b min
- 以防笔记丢失,先发布为妙(●’◡’●)周更ing…
Original: https://blog.csdn.net/weixin_43349479/article/details/123223913
Author: 你这个代码我看不懂
Title: 自然语言处理NLP文本分类顶会论文阅读笔记(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528317/
转载文章受原作者版权保护。转载请注明原作者出处!