

参考资料:
https://blog.csdn.net/feilong_csdn/article/details/88655927
https://fasttext.cc/docs/en/supervised-tutorial.html
https://fasttext.cc
1. 背景:
fasttext文本分类效率较高,可以快速生成文本分类baseline, 本文主要是了解fasttext核心优化点,以及熟悉官网python版本模型训练与预测。
将doc的词以及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。核心是模型结构与word2vector的cbow模型结构类似, 但是fasttext的输出是全部文档词,输出是文档的分类标签。
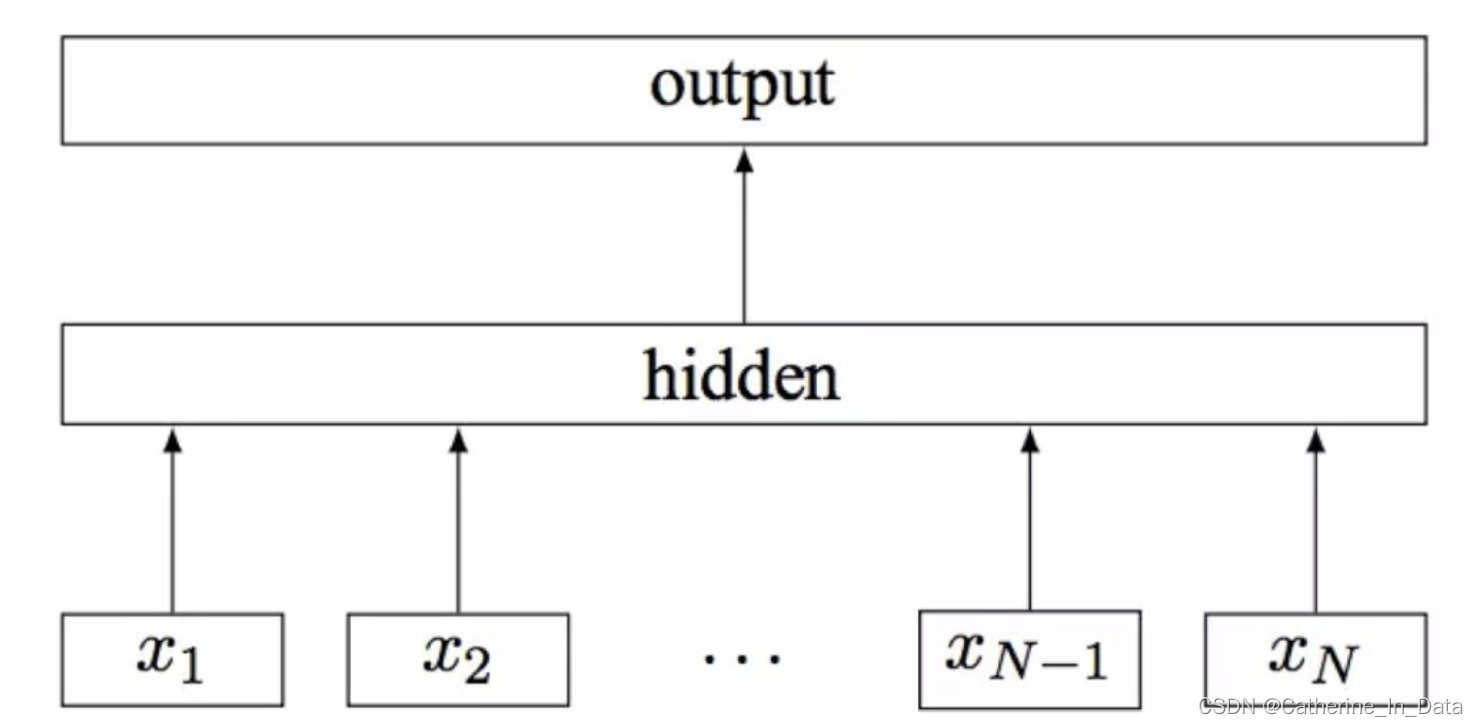

通过分层softmax 提高模型训练的效率, 因为原始softmax多分类需要计算所有的分类标签值,并做一次归一化,当分类标签比较大时,有些耗时,因此引入分层softmax。我理解分层softmax后,只需要关注根节点到叶子节点的路径预测,不需要关注其他分类标签(这里需要确认下,感觉还是没弄懂)。
softmax 回归:隐藏层与所有的node进行连接(inner 与leaf)

分层softmax回归:


输入增加n-gram特征,这个是跟word2vector差异
模型包含两部分输出: 词向量输出,文本分类。
官网模型优化几个trick:多个epoch训练, 学习率调整, 加入n-gram, lr=0.5, epoch=25, wordNgrams=2,loss 改为 loss=’hs’, 可提高训练速度
paper: https://arxiv.org/abs/1607.01759
fasttext Git:https://github.com/facebookresearch/fastText
fasttext官网:https://fasttext.cc/
数据:https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz
; 2. 运行demo
参考官网运行代码,跑了一遍,主要关注效果如何提升。
https://fasttext.cc/docs/en/supervised-tutorial.html
## 安装python 版本fasttext
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ pip install .
## 验证是否安装成功:
import fasttext
## 下载数据
linux
>> wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz
>> head cooking.stackexchange.txt
## 查看样本数
>> wc cooking.stackexchange.txt
15404 169582 1401900 cooking.stackexchange.txt
## 数据分割为训练与测试集
#python
>> head -n 12404 cooking.stackexchange.txt > cooking.train
>> tail -n 3000 cooking.stackexchange.txt > cooking.valid
- 数据example

- 模型训练
## 模型训练
import fastext
model = fasttext.train_supervised(input="cooking.train")
Read 0M words
Number of words: 14543
Number of labels: 735
Progress: 100.0% words/sec/thread: 31007 lr: 0.000000 avg.loss: 10.164967 ETA: 0h 0m 0s
## 保存模型文件
model.save_model("model_cooking.bin")
## 模型预测
model.predict("Which baking dish is best to bake a banana bread ?")
(('__label__baking',), array([0.0851237]))
## 模型在验证集上验证
model.test("cooking.valid")
(3000L, 0.124, 0.0541), precesion, recall, 默认是top1 的评估结果
model.test("cooking.valid", k=5) , top5的准确率与召回率
(3000L, 0.0668, 0.146)
## 输出 top5 分类标签
>>> model.predict("Why not put knives in the dishwasher?", k=5)
((u'__label__food-safety', u'__label__baking', u'__label__equipment', u'__label__substitutions', u'__label__bread'), array([0.0857 , 0.0657, 0.0454, 0.0333, 0.0333]))
- 模型优化
## 数据处理, 大小写转化, 数据标准些
#linux
>> cat cooking.stackexchange.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > cooking.preprocessed.txt
>> head -n 12404 cooking.preprocessed.txt > cooking.train
>> tail -n 3000 cooking.preprocessed.txt > cooking.valid
## 模型训练更多epoch
#python
>>> model = fasttext.train_supervised(input="cooking.train")
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 33793 lr: 0.000000 avg.loss: 10.410798 ETA: 0h 0m 0s
>>> model = fasttext.train_supervised(input="cooking.train", epoch=25)
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 35564 lr: 0.000000 avg.loss: 7.241970 ETA: 0h 0m 0s
>>> model.test("cooking.valid")
(3000, 0.522, 0.22574599971169093) ## 数据标准化后,效果有些提升
## learing rate 0.1 - 1.0
model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25)
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 36017 lr: 0.000000 avg.loss: 4.563952 ETA: 0h 0m 0s # loss 明显下降了比较多, 学习率影响挺大的
>>> model.test("cooking.valid")
(3000, 0.588, 0.2542885973763875) # 修改学习率后, 效果有提升
### 加入n-gram 特征。对于分类任务词的连续性比较重要。
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25, wordNgrams=2)
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 35100 lr: 0.000000 avg.loss: 3.208134 ETA: 0h 0m 0s. ## 输入加入ngram后,loss明显下降
>>> model.test("cooking.valid")
(3000, 0.6066666666666667, 0.2623612512613522) # 输入加入ngram特征, 效果有提升
注意 ngram分为字ngram, 词ngram。
- 大数据上使用层次softmax进行模型训练
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25, wordNgrams=2, bucket=200000, dim=50, loss='hs')
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 2199406 lr: 0.000000 loss: 1.718807 eta: 0h0m
- 多标签分类:Multi-label classification
loss = ‘ova’ 表示 one -vs - all
>>> model = fasttext.train_supervised(input="cooking.train", lr=0.5, epoch=25, wordNgrams=2, bucket=200000, dim=50, loss='ova')
Read 0M words
Number of words: 14543
Number of labels: 735
Progress: 100.0% words/sec/thread: 72104 lr: 0.000000 loss: 4.340807 ETA: 0h 0m
只保留阈值>0.5的lable
>>>model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)
Original: https://blog.csdn.net/zhouwenyuan1015/article/details/124132146
Author: Catherine_In_Data
Title: NLP之文本分类(二)—FastText
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528272/
转载文章受原作者版权保护。转载请注明原作者出处!