

本文作为入门级教程,介绍了 词袋模型(bag of words model)和 词向量模型(word embedding model)的基本概念。
目录
先来初步理解一个概念和一个操作:
一个概念:词袋:一张由训练语料得到的词汇表(词典)
一个操作:在给出一篇文本后,需要把文本转换(编码)成数值,才能汇编成词典。用数值表示文本的方法有很多,例如最常见的One-Hot表示法,此外还有TF表示法、TF-IDF表示法。
1 词袋模型和编码方法
1.1 文本向量化
文本向量化就是指用数值向量来表示文本的语义,即,把人类可读的文本转化成机器可读形式。
如何转化成机器可读的形式?这里用到了信息检索领域的 词袋模型,词袋模型在部分保留文本语义的前提下对文本进行向量化表示。
1.2 词袋及编码方法
我们先来看2个例句:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个词语都是独立的。例如上面2个例句,就可以构成一个词袋,袋子里包括Jane、wants、to、go、Shenzhen、Bob、Shanghai。假设建立一个数组(或词典)用于映射匹配:
[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
那么上面两个例句就可以用以下两个向量表示,对应的下标与映射数组的下标相匹配,其值为该词语出现的次数:
1 [1,1,2,1,1,0,0]
2 [0,1,2,1,0,1,1]
这两个词频向量就是词袋模型,可以很明显的看到语序关系已经完全丢失。
1 one-hot编码
步骤如下:
假设我有一堆需要编码的文本:


1.构建词袋:
这里词语的顺序可以随机:

2. 对于每一个单词,我们观察该词语是否出现,出现就为1,没有出现就是0,得到 文本向量,规则如下:


; 2 TF编码
TF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在所在文本中的频次,词语序列中未出现的词语其数值为0。用数学式子表达为:
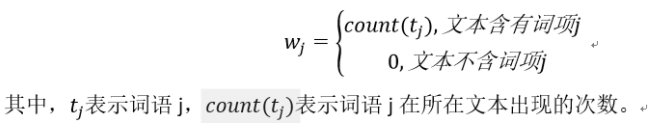
同样地:

可以发现,相比one-hot,tf还体现了词语出现的频次。
3 TF-IDF表示法
TF-IDF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在所在文本中的频次乘以词语的 逆文档频率,词语序列中未出现的词语其数值为0。用数学式子表达为:

同样地:

; 2 词嵌入模型
相比不考虑语序的词袋模型,词嵌入模型是 考虑词语位置关系的一种模型。通过大量语料的训练,将每一个词语映射到高维度(几千、几万维以上)的向量当中,通过求余弦的方式,可以判断两个词语之间的关系,例如例句中的Jane和Bob在词向量模型中,他们的余弦值可能就接近1,因为这两个都是人名,Shenzhen和Bob的余弦值可能就接近0,因为一个是人名一个是地名。
现在常用word2vec构成词嵌入模型,它的底层采用基于CBOW和Skip-Gram算法的神经网络模型。
2.1 CBOW模型
CBOW模型的训练 输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。比如上面的第一句话,将上下文大小取值为2,特定的这个词是”go”,也就是我们需要的输出词向量,上下文对应的词有4个,前后各2个,这4个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这4个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
这样我们这个CBOW的例子里,我们的输入是4个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大), 对应的CBOW神经网络模型输入层有4个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。这样当我们有新的需求,要求出某4个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
2.2 Skip-Gram模型
Skip-Gram模型和CBOW的思路是反着来的,即 输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。还是上面的例子,我们的上下文大小取值为2, 特定的这个词”go”是我们的输入,而这4个上下文词是我们的输出。
这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前4的4个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小(4)个神经元。隐藏层的神经元个数我们可以自己指定。这样当我们有新的需求,要求出某1个词对应的最可能的4个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前4的softmax概率对应的神经元所对应的词即可。
词嵌入模型突出特点:在词嵌入模型中,词向量与词向量之间有这非常特殊的特性。例如现在存在国王、男生、女人、皇后四个词向量,那么一个完善的词向量模型,就存在”国王-男人+女人=皇后”这样的关系。
两种模型对比
词袋模的One-Hot表示法、TF表示法、TF-IDF表示法的数值计算规则都没有考虑词语之间的共现关系。比如”的”字的后边只能接名词性词语,”地”字的后边只能接动词性词语。显然词袋模型无法表示词语之间的共现关系,也就是说词袋模型认为一个词出现的可能性与其他词出现的可能性无关,词语的出现是相互独立的。
词袋模型最大的缺陷是向量的维度高,维度高造成了后续相似度或者文本分类的计算量非常大,同时数据稀疏也导致了相似度区分不明显。由于词袋模型表示的文本向量的每个维度都代表一个词语,因此可以用聚类后簇中心向量的具有较大值的维度对应的词语来作为簇的关键词。.
词嵌入模型是浅层神经网络的副产品,在用浅层神经网络做文本分类时,发现在得到分类结果的同时,输入矩阵刚好可以用来表示词语,由于词语是用上下文来表达的,因此在一定程度上反映了词语的语义,但这并不是机器真正明白了词语的意义,而只是相似的词语之间向量相似度大而已。
它的 优点:
1.不需要人工参与可以得到,大厂推出了各种词向量库,词汇量一般都是百万级。
2.可以表达一个词语的向量,这是前几年办不到的。
3. 文本的表示维度降下来了,一般只需100到300维之间。
缺点也很明显:
1.强烈依赖分词特别是未登录词识别技术,也就是说新出现的词没有对应向量。2.不是真正明白词语意思,对一词多义无能为力,只能表达最通用的语义。
3.有些词在语义上没有近义关系,但因为经常出现在相同的上下文中,向量的相似度也很大。有些概念抽象的词(特别时文本类别名称词),按照相似度检索到的近义词之间不具有语义相关性。
5. 每个维度不再对应一个特征词语,后续排查分类badcase时不方便。
3 示例
这里需要用到 sklearn包。Sklearn的特征抽取模块可以从原始数据中抽取特征。目前该模块提供了图像和文本特征抽取类。文本的特征抽取类可以从原始文本中抽取出词语特征,特征数据格式满足所有机器学习算法对输入数据格式的要求。 请注意特征抽取与特征选择的区别。特征抽取是将文本数据转换成机器学习模型可读的形式(即本文所说的文本向量化)而特征选择是一种应用于数值特征的机器学习技术。
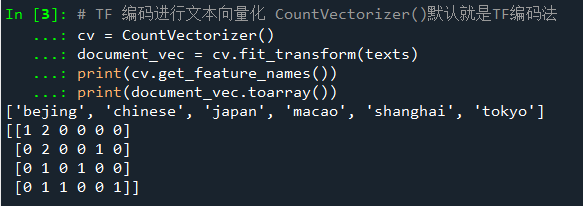
用sklearn对下边的文本进行词袋模型向量化表示:
完整代码:
from sklearn.feature_extraction.text import CountVectorizer
texts = ['Chinese Bejing Chinese',
'Chinese Chinese Shanghai',
'Chinese Macao',
'Tokyo Japan Chinese']
cv = CountVectorizer(binary=True)
document_vec = cv.fit_transform(texts)
print(cv.get_feature_names())
print(document_vec.toarray())
cv = CountVectorizer()
document_vec = cv.fit_transform(texts)
print(document_vec.toarray())
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer(use_idf=True, smooth_idf=False, norm=None)
tv_fit = tv.fit_transform(texts)
print(tv.get_feature_names())
print(tv_fit.toarray())
tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
tv_fit = tv.fit_transform(texts)
print(tv.get_feature_names())
print(tv_fit.toarray())
结果:



参考:
https://www.cnblogs.com/chenyusheng0803/p/10978883.html
https://zhuanlan.zhihu.com/p/70314114
Original: https://blog.csdn.net/weixin_42468475/article/details/121522295
Author: 学渣渣渣渣渣
Title: 【NLP】词袋模型(bag of words model)和词嵌入模型(word embedding model)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528264/
转载文章受原作者版权保护。转载请注明原作者出处!