

巨佬请关闭!原文:
https://arxiv.org/abs/1607.06450
博主水平有限,本文目的是让大一大二有志于NLP领域学习的大学生们少走弯路,可当作学习笔记。今天在重新回顾ViT模型的基本结构的时候,发现很多知识盲区,这仅是其中一个。
Layer Normalization利用神经元输入的总和分布在一个小批量的训练案例上来计算均值和方差,然后用这些均值和方差来规范化每个训练案例上该神经元的总和输入。
批一归一化依赖于batch_size,RNN中(时间步骤不确定)不适用。
层归一化单一样本进行层归一化,与batch Normalization相同都设置有adaptive bias 和gain增益参数, 且在训练和测试中执行相同运算。RNN中每个时间点都可以进行Layer Normalization
作用:显著降低训练时间。
在前馈神经网络中,将输入x进行非线性映射 x->输出y。 第l层时,al 记作输入。
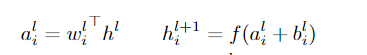

Wl 为权重矩阵参数。
Bl 为偏置参数。
F() 为非线性映射。
目前,深度学习中改成的权重依赖于上一层的输出影响较大。Batch Normalization是通过将小的训练批次中的样本计算均值和方差进行归一化。
然而一个层的输出变化会导致总和输入到下一个层中相关变化(”covariate shift)。通过修正方差均值来减少协变的影响
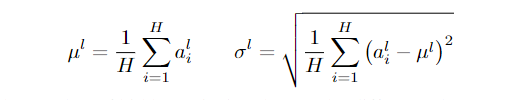
神经元个数是H, 对于该层的每个ai求和 最后除以H 得到均值ul。方差计算如第二个式子。
每一层神经元共享同一套神经元参数,参数即为均值和样本差。一层训练有很多个样本,每个样本是有不同归一化参数的。
Pytorch 中实现:
需要注意的是,Pytorch的LayerNorm类中有个normalized_shape参数,其用来指定Norm维度,但指定维度必须是最后一层维度。例如数据的shape是[3, 4, 5],那么normalized_shape可以是[5],也可以是[4,5] , [3,4,5]。但不能是[3] [3,4]
import torch
import torch.nn as nn
def layer_norm_process(feature: torch.Tensor, beta=0., gamma=1., eps=1e-5):
var_mean = torch.var_mean(feature, dim=-1, unbiased=False)
# 均值
mean = var_mean[1]
# 方差
var = var_mean[0]
# layer norm process
feature = (feature - mean[..., None]) / torch.sqrt(var[..., None] + eps)
feature = feature * gamma + beta
return feature
此处参考Layer Normalization解析_太阳花的小绿豆的博客-CSDN博客_layer normalization
Original: https://blog.csdn.net/m0_60920298/article/details/124262473
Author: 踏实钻研
Title: ViT模型关联的Layer Normalization研读(一)初学者
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528232/
转载文章受原作者版权保护。转载请注明原作者出处!