

作者:咏江


达摩院NLP团队在国际多语言复杂命名实体识别大赛获得10个第一、2个第二,13个track平均F1较排名第二的团队超过+2%,相关NER技术在国际顶级会议ACL、EMNLP发表10+篇论文,分别通过AliNLP平台和阿里云NLP推广到集团内外,同时在集团内部重点推广多语言搜索AE和ICBU。
一、背景
SemEval(Semantic Evaluation)是由国际计算语言学协会(Association for Computational Linguistics, ACL)下属的SIGLEX主办的在自然语言处理(NLP)领域全球范围内影响力最强、规模最大、参赛人数最多的语义测评竞赛. 自2001年起,SemEval至今已成功举办十五届。多语言理解自从第一届的SemEval开始就备受关注。
在本次我们参加的SemEval比赛中,比赛的目标是为 11 种语言构建NER 系统,包括英语、西班牙语、荷兰语、俄语、土耳其语、韩语、波斯语、德语、汉语、印地语和孟加拉语。该任务有13个赛道,包括1个多语言赛道、11个单语赛道和1个混合语言赛道。多语言赛道需要训练能够处理所有语言的多语言 实体识别 模型。单语赛道需要训练单语模型仅适用于一种语言,而混合语言赛道中一个句子中同时包含多种语言。本次比赛的数据集主要包含来自三个领域的句子:维基百科、网络问答和用户检索。这些句子往往都是简短和缺少上下文的句子。此外,这些短句通常包含语义模糊和复杂的实体,这使问题变得更加困难。 我们提出了一种基于多语言知识库检索的NER系统,提交的系统获得10个第一,2个第二,13个track平均F1较排名第二的团队超过+2%。
二、团队基础
作为达摩院NLP团队的基础算法小组,我们对内承担着电商、新闻、娱乐、地址、电力等行业的信息抽取能力的建设,对外我们把已有的能力进行商业化输出。
这次比赛我们把过去几年所有根据业务场景在多语言NER方面积累的大部分技术进行了尝试,包括如下一些工作:
发表会议
论文名
topic
ACL 2020
Structure-Level Knowledge Distillation for Multilingual Sequence Labeling
蒸馏/统一模型
EMNLP 2020
AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network
模型加速
EMNLP 2020
More Embeddings, Better Sequence Labelers?
性能优化
EMNLP 2020
An Investigation of Potential Function Designs for Neural CRF
性能优化
ACL 2021
Structural Knowledge Distillation: Tractably Distilling Information for Structured Predictor
蒸馏/统一模型
ACL 2021
Automated Concatenation of Embeddings for Structured Prediction
极致性能
ACL 2021
Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning
知识增强
ACL 2021
Multi-View Cross-Lingual Structured Prediction with Minimum Supervision
跨语言
ACL 2021
Risk Minimization for Zero-shot Sequence Labeling
跨领域/跨语言
EMNLP 2021
Word Reordering for Zero-shot Cross-lingual Structured Prediction
跨语言
NAACL 2022
ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition
多模态
三、比赛源起:赛场是技术特别好的练兵场
各行业的文本理解问题中,实体抽取是最基础/最广泛的NLP落地应用之一。无论是集团内部的alinlp还是公有云,实体抽取的调用量和用户数都是名列前茅。海量业务场景下我们面临相同的数据挑战:搜索词、商品标题、快递单、电力调度文本、新闻稿件、语音ASR后的文本等等行业内的文本,这些文本来源不同:
行业
翻译文本
短文本
高歧异文本
质量差
电商Query
Y
Y
Y
N
电商标题
Y
N
Y
Y
地址行业
N
Y
N
N
语音NER
N
Y
Y
Y
新闻行业
N
Y
Y
N
SemEval
Y
Y
Y
Y
可以看出,本次比赛数据的风格基本继承了我们在业务场景中遇到的各种问题,因此是技术特别好的练兵场。
四、比赛的挑战
本次多语言信息抽取的难度有以下两方面:
数据角度:
多语言语料的标注成本高。在多语言语料标注命名实体,需要具有不同语言能力的标注者,尤其是一些小语种,具备标注能力的标注者稀少,标注成本较高。而依赖翻译或者远程监督的标注方法生成的样本标注质量差,难以满足模型训练和评估的需要。
-
低资源语言上样本稀疏。低资源语言上本身语料稀缺,而一些跨语言的数据增广方法很难保证在语义连贯、语法正确的前提下对齐源语言和目标语言上的命名实体标注。
-
数据不平衡。高资源语言的语料一般远远高于低资源语料,造成了不同语言之间的数据不平衡。直接在不平衡数据上学习到的模型在不同语言上性能差距明显,难以适用于实际场景。
方法角度:
-
多语言常识知识的理解:在上下文缺少的情况下,识别句中的简单常见实体,对大多数NER模型来说都是困难的。因此如何利用好多语言外部知识来增强模型的常识理解能力是我们需要解决的问题。
-
不同语言之间的冲突和联系:一方面不同语言上任务相关的知识是可以相互强化的,另一方面不同语言上的噪声(数据标注噪声、跨语言存在语义差异等)也是互相影响的。在多语言场景下统一多语言模型的设计需要兼顾知识和噪声,充分利用多语言数据,达到多语言设置下性能增益最大。
五、我们是怎么做的
我们最终优化的方案包括多个流程,这里主要介绍我认为最核心(也是提升最大的)的技术, “基于知识的命名实体识别系统”,在这里简单介绍一下我们的技术方案,完整的report可以在arxiv上查看。
在过去不同业务场景和学术界公开数据集优化的过程中,我们获得了一条最重要的经验: 引入额外的知识可以大幅度提升实体理解能力。
于是在拿到比赛的官方数据 (训练集+验证集)后,我们对数据进行了分析,有几点有趣的发现
-
训练集大多数比较长
-
验证集分布更加多样,包括很多翻译的短query
在没有拿到测试数据的时候,我们觉得领域迁移这个问题带来的挑战可能非常大。在比赛的初期,我们在设计模型的时候,考虑了以下几个因素:
-
由于一共有13个track,我们的方案在不同track的方案尽量是统一的,这样有利于模型迭代
-
当面临不同模型选择的时候,我们拿英文作为调试模型的数据集
-
测试阶段仅有四天 (后来推迟到六天),同时测试集的数量比较大,我们的模型推理速度不能成为瓶颈
-
面对领域迁移的问题,我们希望融合外部知识来使得模型学会基于外部知识的上下文模仿,而不是对训练数据的过拟合
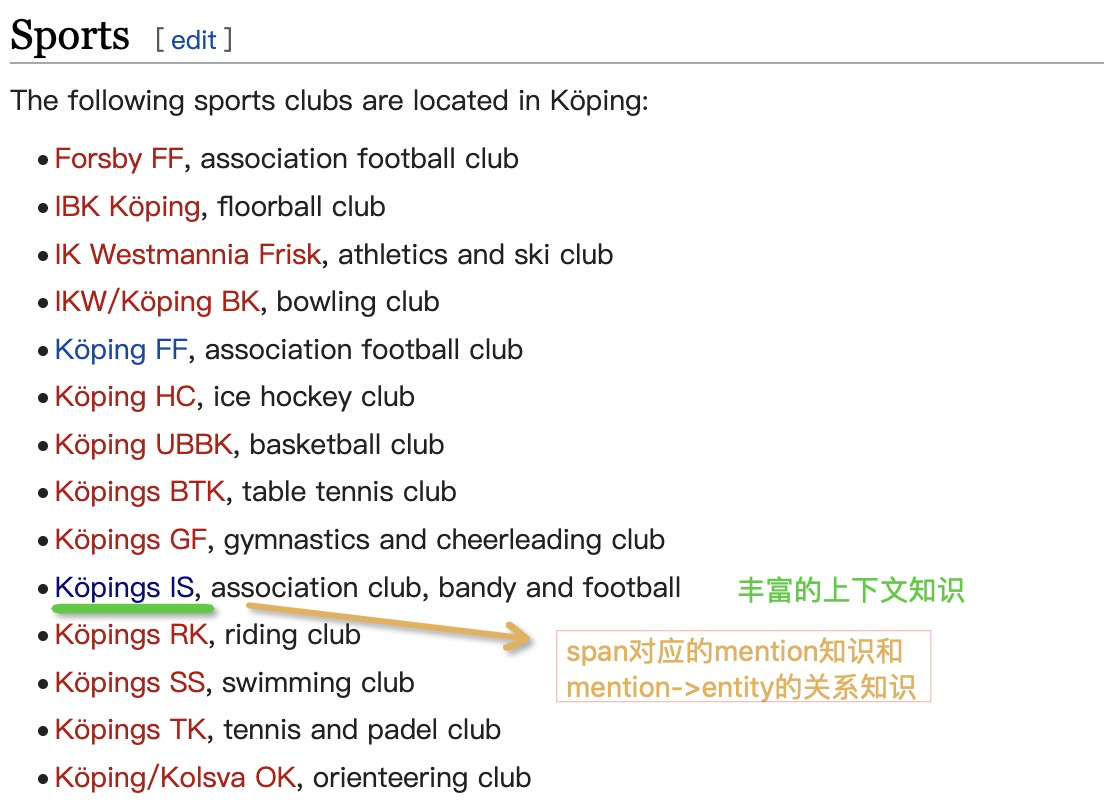
同时,我们分析一些例子发现,此比赛对知识的需求也很大,如下面的例子: köpings is rate. 这里的 “köpings is” 是一个运动俱乐部,因此是一个团体实体类型(GRP). 而没有额外的知识输入,在这个语法规则 (xx is xxx)下,模型比较容易将köpings预测成地名(LOC)。
而我们通过检索搜索引擎,可以获得丰富的上下文,这些上下文可以提供额外的知识帮助模型进行消歧。
因此采用我们去年发表在ACL 2021上的Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning 方法,当时我们发现可以大幅度提升模型性能. 但是谷歌/百度的检索数据都是比较脏的. 在如此脏乱的数据喂给模型,模型都可以有比较好的性能. 这让我进一步思考,如何从其他来源来获取更加充足且干净的知识. 而容易获得,且有着十几种语言的,多语言维基百科就是一个很好的知识库. 接着我们分析了下维基百科可以提供哪些额外知识帮助我们进行模型训练。
-
丰富的各行业文本
-
海量的词组信息 (span/mention knowledge)
-
从短语到实体名的跳转信息 (wiki中的链接跳转功能,即mention->entity信息)
我们提出了一种基于通用的检索知识库的多语言信息抽取系统。通过在知识库中检索输入句子的相关知识,便可以更容易的进行实体的识别和抽取。首先,基于11 种语言的维基百科,我们构建了一个多语言知识库来搜索输入句子的相关知识,这个可以看成是我们构建了wiki文档的文本索引。在检索的过程中,我们做了两件重要的事儿
-
将检索文本中的短语信息标示出来
-
将短语及其实体标示出来
例如 维基百科中提供了非常丰富的实体链接信息,如 ”’Apple -> Apple Inc”’,”’Steve Jobs -> Steve Jobs”’ ,因此这个句子 Steve Jobs founded Apple}可以转化成
我们利用ElasticSearch对wiki的文本构建索引,在检索过程中,我们考虑如下几种检索方式
-
句子检索:直接将待处理的文本丢到ElasticSearch里进行检索
-
交互式实体检索: 先通过一个现有模型对文本进行打标,再将打标结果和整个句子以 OR 的形式进行检索
对于检索到的文本,我们考虑如下几种不同的利用方式
-
仅利用检索到的句子
-
利用检索到的段落
-
我们也增加了一个把”短语及其实体”删掉的对比实验
最终方案如下图所示:
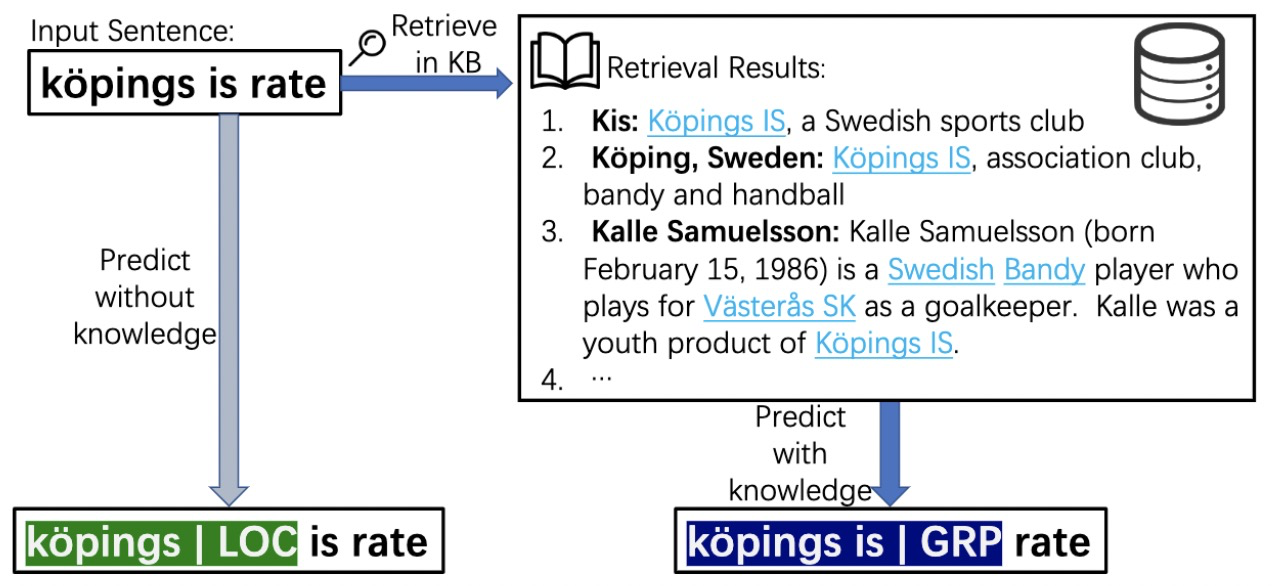
在应用时,我们通过引入上下文的方法来利用检索到的知识,具体做法上,我们将输入句子和检索到的知识拼接在一起,并将连接的字符串输入信息抽取模型中。具体的,对于一个句子x,我们获取其对应的上下文x’,组合成新的输入,再通过优化后的XLMR-large预训练模型。
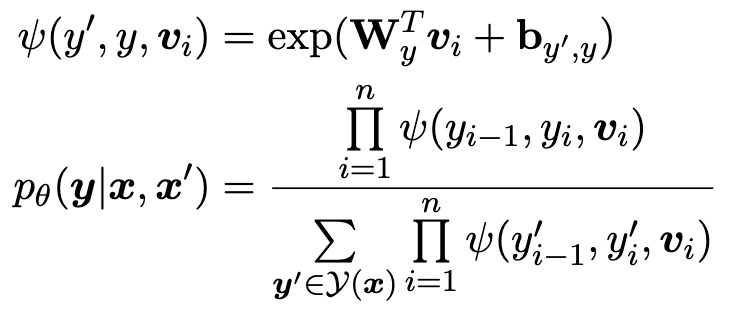
该方法部分来自我们在去年在自然语言处理的顶级会议ACL已发表的论文 Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning .
实验结果如下 (lowner是in-domain,MSQ和OSCAS是out-of-domain)
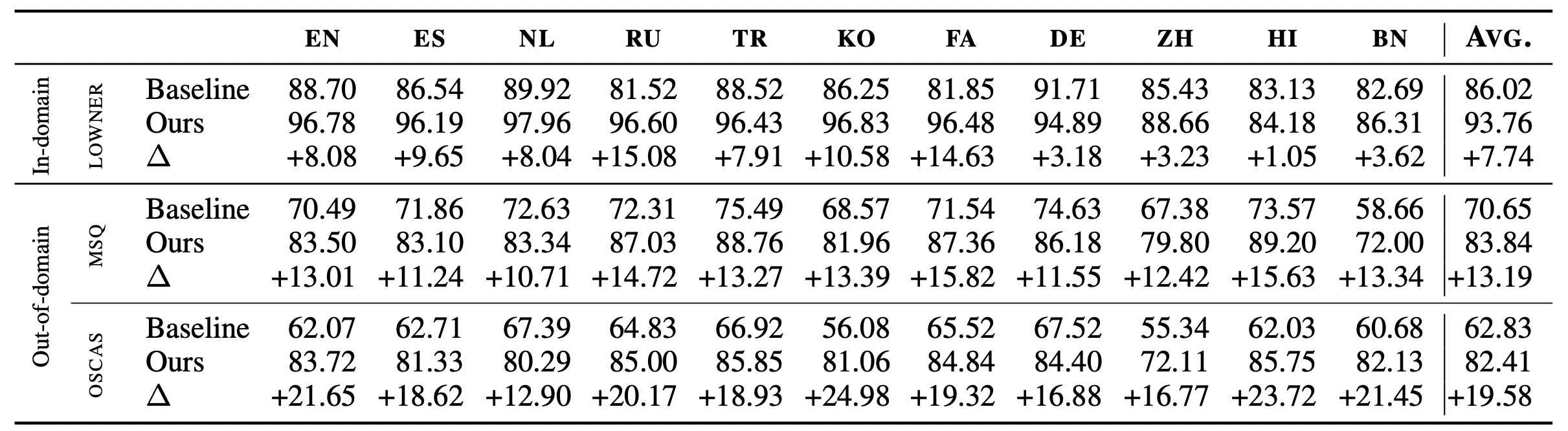
我们发现,基于知识库检索所增强的知识可以大幅度提升信息抽取系统的性能,在相同分布的数据下可以带来绝对提升7%的F1,在跨领域条件下(如表里的MSQ网络问答数据集和OSCAS用户搜索词数据集)可以带来10%-20%的F1性能提升。
最终,我们 提交的系统获得10个第一,2个第二,13个track平均F1较排名第二的团队超过+2%。参与的团队有47个队伍,包括网易/科大讯飞/平安科技/华为/IBM/Cisco/三星电子/深圳苹果树,中科大/中科院/洪堡大学/阿尔托大学/印度理工等. 详细结果在这里。下面我们选取并比较了几支团队的效果,可以发现,我们的方案在F1上平均 超过排名第二的系统+2%,在英文/俄语等语种大幅度超过其他提交系统。

其他一些显著提升性能的技巧,以下技巧可以在上述方法的基准上进一步提升,某些技巧比较通用,可以适用于各种NLP的任务中:
-
在拿到数据后,我们利用多语言预训练语言模型XLMR-large,在比赛数据集进行masked language modeling的continue pretraining,在所有数据集上都 可以带来0.5%-1% F1的性能提升。
-
我们先把所有数据合在一起,进行finetune后,再在每个track的数据集进行二次finetune, 可以带来2% F1的提升。
-
通过我们发表在EMNLP 2020和ACL 2021的组合向量的技术 可以进一步带来性能0.8%左右的提升。
-
最后,我们通过多次的模型训练,将结果进行ensemble, 可以提升模型性能+0.5%-1%。
以上策略之间性能提升不会相互冲突, 最终我们的方案获得10个第一、2个第二,13个track平均F1较排名第二的团队超过+2%
六、应用落地
NER是NLP应用最广泛的技术之一,我们在集团内外进行推广,包括:
1.多语言搜索AE & ICBU 我们支持了AE和ICBU的Query和商品的实体抽取,并与AE和ICBU业务方通力合作推广搜索相关性。
2.AliNLP平台和阿里云NLP 文中提到的NER相关的技术沉淀,我们通过AliNLP平台以及阿里云NLP推广给集团内外部客户,欢迎大家试用和反馈。
本文相关链接:
1.比赛官网: SemEval 2022 Task 11: MultiCoNER
2.比赛代码: 已开源,在 GitHub – Alibaba-NLP/KB-NER: Winner system (DAMO-NLP) of SemEval 2022 MultiCoNER shared task over 10 out of 13 tracks.
3.我们的report: https://arxiv.org/pdf/2203.00545.pdf
4.最终各track排名: SemEval 2022 Task 11: MultiCoNER
Original: https://blog.csdn.net/AlibabaTech1024/article/details/124928757
Author: 阿里技术
Title: 10个第一、2个第二,达摩院NLP团队在SemEval 2022的夺冠之旅
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528214/
转载文章受原作者版权保护。转载请注明原作者出处!