

本次实现BiLSTM+CRF模型的数据来源于DataFountain平台上的”产品评论观点提取”竞赛,数据仅用来做模型练习使用,并未参与实际竞赛评分。
竞赛地址:产品评论观点提取
- 数据分析
数据分为测试集数据7528条,测试集数据(未统计)。
测试集数据共有四个属性,分别是:ID号,文本内容,BIO实体标签,class分类
本次比赛的任务一共分为两部分,第一部分是 NER部分,采用BIO实体标签作为训练参考,另一部分为文本分类,目前只做了NER部分,因此暂时只针对NER部分讲解。
测试集数据具体如下:
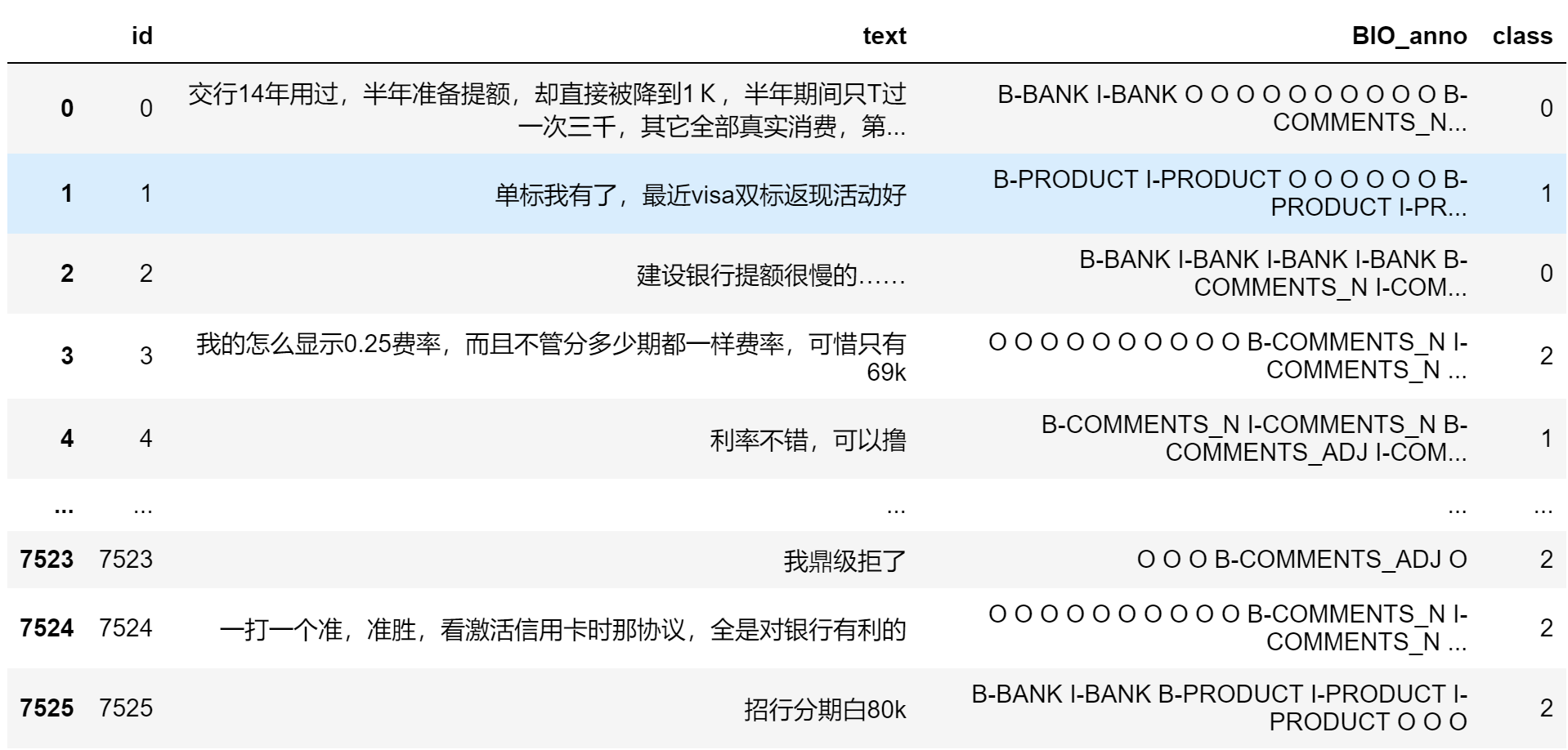

首先分析一下我们的text长度,对训练集中7525个样本的text长度进行统计,可以得到一下直方图:
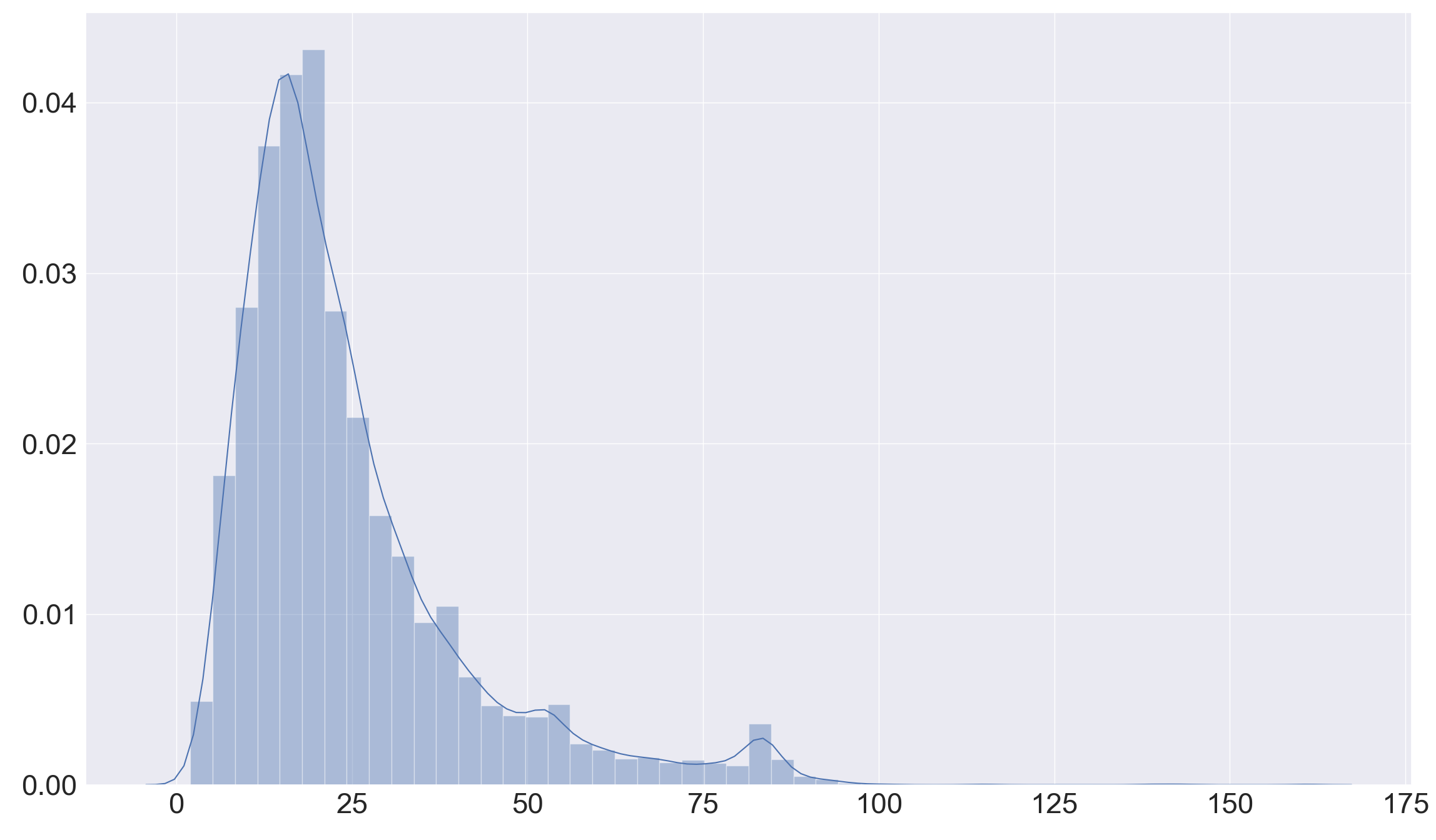
从图中可以看出,文本长度为20左右的数据量最大,总体来说文本长度都在100个字符以内,所以我们可以把要放入模型训练的固定文本长度MAX_LEN设置为100。
要做NER任务,就需要把每个字符预测为某一类标签,加上O标签,我们的标签一共有九类,可以查看一下训练集中除了O以外的八类标签的频次情况,就可以知道是否有某一类标签的数据量过少,过少的话就有可能带来此类标签预测效果不好的结果。
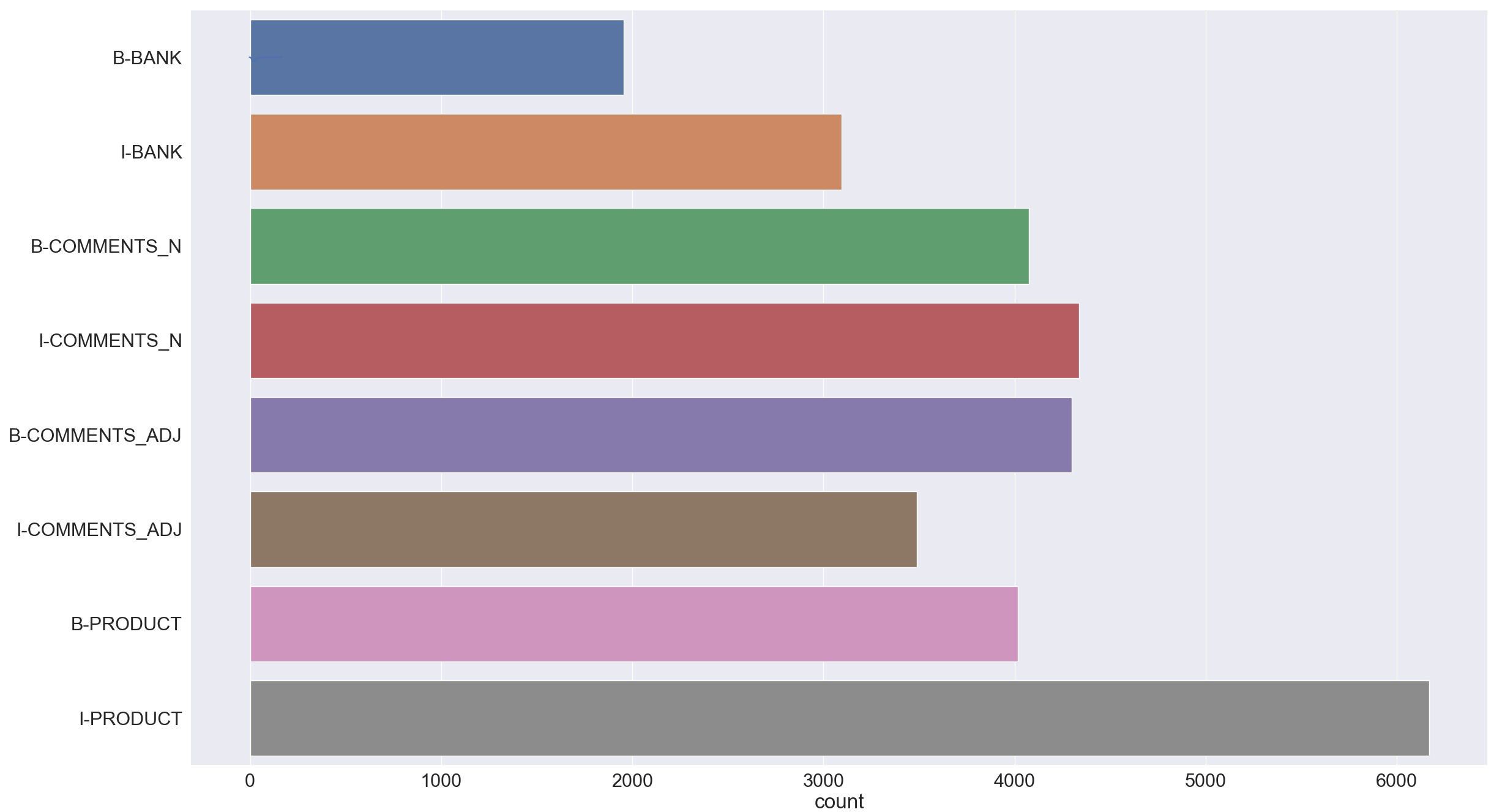
从上图的频次直方图可以看到,出现频次最高的是’I-PRODUCT’,共有6000多次,频次最低的是’B-BANK’,共有不到2000次
不过总的来说差距不算太悬殊,tag的分布可以说是较为均匀的,问题不大。
- BiLSTM+CRF模型
对于NER任务,较为常用的模型有HMM、CRF等机器学习方法,(Bi)LSTM+CRF,CNN+CRF,BERT+CRF,后续我会记录一下BERT+CRF等等模型的实现,首先从BiLSTM+CRF开始。
(1)BiLSTM+CRF模型示意图:
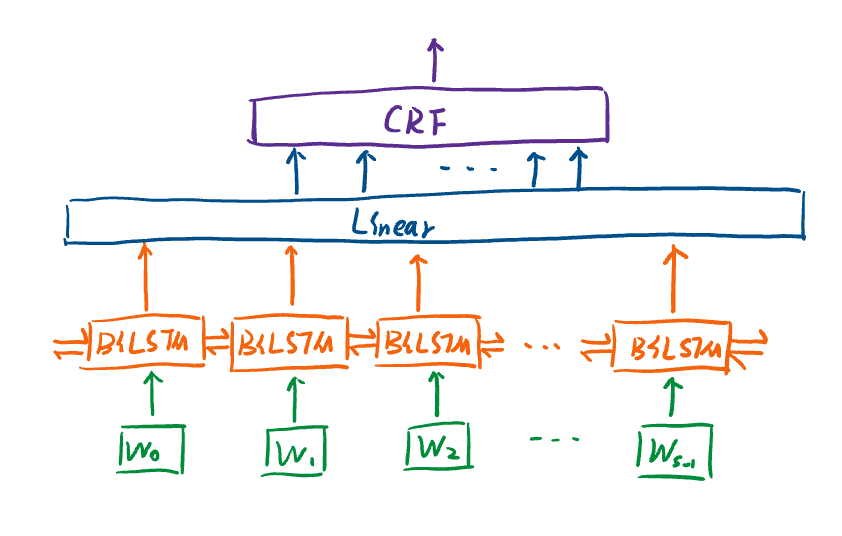
模型的输入为固定长度的文本,文本中的每个词向量为Wi。经过BiLSTM层训练后进入全连接层,就可以得到每个词在每个tag位置的概率了,因为我们总共有九个tag,所以全连接层的输出的最低维度就是长度为9的向量。最后经过CRF层训练后,就可以输出loss值;如果是预测的话,使用CRF层的decode方法,就可以得到每个词具体预测的tag了。
(2)模型各层数据结构的变化示意图:
之所以画有这个数据结构变化流程,是因为我个人非常纠结在模型变化中的数据结构变化(可能是我菜..),但是在参考网上别的资料的时候,基本上没有见过有提供这类总结的,所以我就画个图,万一有人和我一样需要呢[doge]
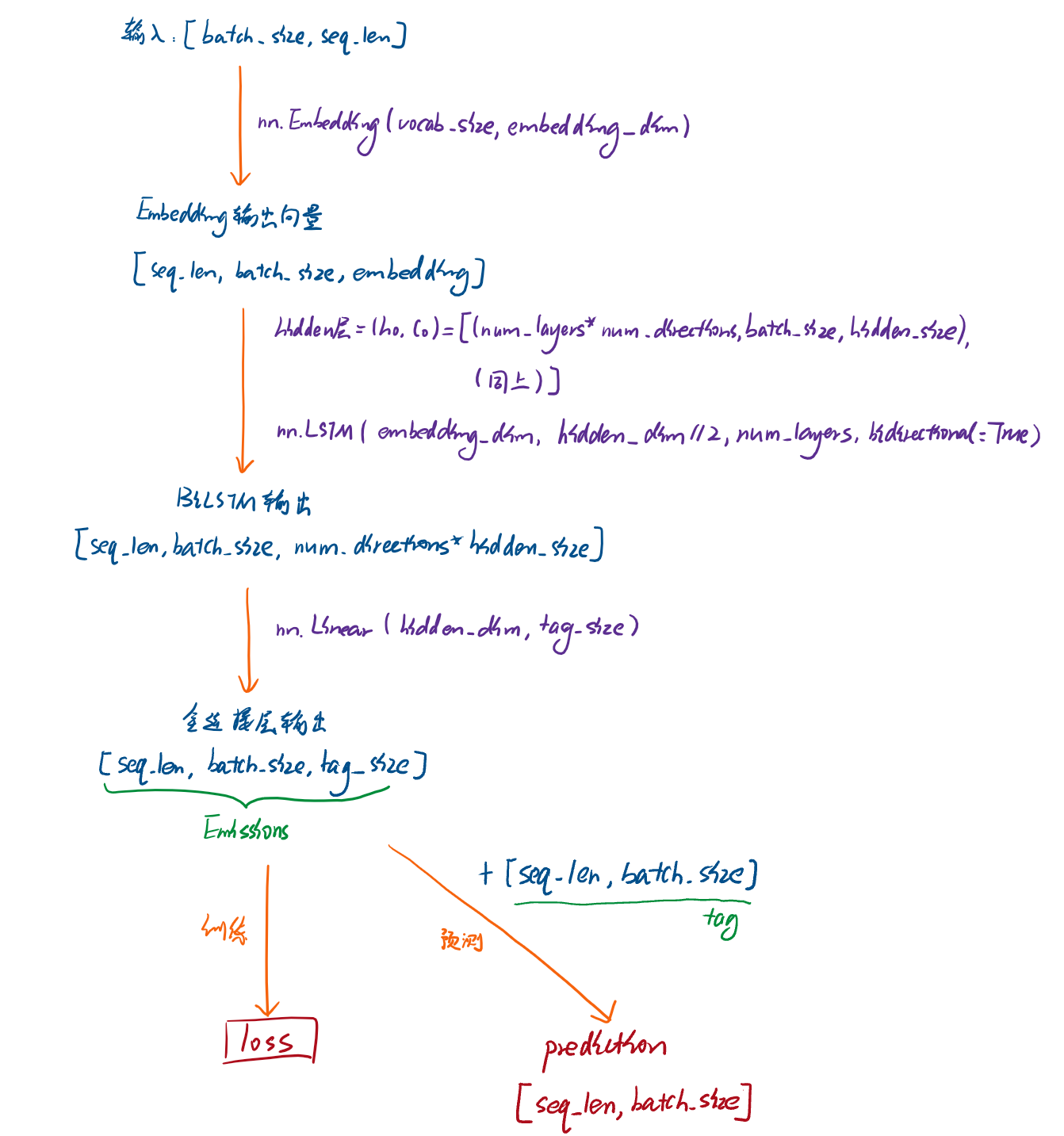
上图中,输入的结构是[batch_size, seq_len],batch_size就是数据集每个batch的大小了这个很简单,seq_len是文本长度,一般文本长度都是固定的(短于固定长度的话就需要padding)。输入数据实际上就是经过词转index,再经过padding过后的训练集/验证集数据了。
这里有一点需要注意:输入数据的结构中,我们一般第一个维度都是batch_size,但是实际上pytorch的各层模型中,它们默认的数据输入参数都是batch_first=False,因此后面就需要将数据转换成[seq_len, batch_size]的结构。
另外非常重要的是,由[batch_size,seq_len]转[seq_len, batch_size],不要用tensor类的view方法,也不要用numpy中的reshape方法,这样转换的维度是不正确的(你可以试试),应该要用tensor类的permute方法来转换维度。
图中中间部分的转换流程就不讲了,没什么太多问题,最后经过CRF层的时候,如果是进行训练,那么需要参数emissions和tags,输出结果就是loss值,不太一样的是这里的loss值应该是进行了一个-log的操作,因此直接输出的loss值就会变成复数,为了能够用常用的优化器进行参数优化,这里的loss值需要乘以一个-1;如果是进行预测,就需要调用decode方法。
- 具体实现
模型使用pytorch实现,jupyter notebook版本的完整代码在github上:NLP-NER-models
整体实现和核心代码如下:
(1)词转index&填充长度不足/截取过长的文本
MAX_LEN = 100 #句子的标准长度
BATCH_SIZE = 8 #minibatch的大小
EMBEDDING_DIM = 120
HIDDEN_DIM = 12
获取 tag to index 词典
def get_tag2index():
return {"O": 0,
"B-BANK":1,"I-BANK":2, #银行实体
"B-PRODUCT":3,"I-PRODUCT":4, #产品实体
"B-COMMENTS_N":5,"I-COMMENTS_N":6, #用户评论,名词
"B-COMMENTS_ADJ":7,"I-COMMENTS_ADJ":8 #用户评论,形容词
}
获取 word to index 词典
def get_w2i(vocab_path = dicPath):
w2i = {}
with open(vocab_path, encoding = 'utf-8') as f:
while True:
text = f.readline()
if not text:
break
text = text.strip()
if text and len(text) > 0:
w2i[text] = len(w2i) + 1
return w2i
def pad2mask(t):
if t==pad_index: #转换成mask所用的0
return 0
else:
return 1
def text_tag_to_index(dataset):
texts = []
labels = []
masks = []
for row in range(len(dataset)):
text = dataset.iloc[row]['text']
tag = dataset.iloc[row]['BIO_anno']
#text
#tag
if len(text)!=len(tag): #如果从数据集获得的text和label长度不一致
next
#1. word转index
#1.1 text词汇
text_index = []
text_index.append(start_index) #先加入开头index
for word in text:
text_index.append(w2i.get(word, unk_index)) #将当前词转成词典对应index,或不认识标注UNK的index
text_index.append(end_index) #最后加个结尾index
#index
#1.2 tag标签
tag = tag.split()
tag_index = [tag2i.get(t,0) for t in tag]
tag_index = [0] + tag_index + [0]
#2. 填充或截至句子至标准长度
#2.1 text词汇&tag标签
if len(text_index)MAX_LEN: #句子过长,截断
text_index = text_index[:MAX_LEN-1]
text_index.append(end_index)
tag_index = tag_index[:MAX_LEN-1]
tag_index.append(0)
masks.append([pad2mask(t) for t in text_index])
texts.append(text_index)
labels.append(tag_index)
#把list类型的转成tensor类型,方便后期进行训练
texts = torch.LongTensor(texts)
labels = torch.LongTensor(labels)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts,labels,masks
#unk:未知词 pad:填充 start:文本开头 end:文本结束
unk_flag = '[UNK]'
pad_flag = '[PAD]'
start_flag = '[STA]'
end_flag = '[END]'
w2i = get_w2i() #获得word_to_index词典
tag2i = get_tag2index() #获得tag_to_index词典
#获得各flag的index值
unk_index = w2i.get(unk_flag, 101)
pad_index = w2i.get(pad_flag, 1)
start_index = w2i.get(start_flag, 102) #开始
end_index = w2i.get(end_flag, 103) #中间截至(主要用在有上下句的情况下)
#将训练集的字符全部转成index,并改成MAX_LEN长度
texts,labels,masks = text_tag_to_index(train_dataset)
(2)pytorch BiLSTM+CRF模型设置
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim, pad_index,batch_size):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.pad_idx = pad_index
self.batch_size = batch_size
#####中间层设置
#embedding层
self.word_embeds = nn.Embedding(vocab_size,embedding_dim,padding_idx=self.pad_idx) #转词向量
#lstm层
self.lstm = nn.LSTM(embedding_dim, hidden_dim//2, num_layers = 1, bidirectional = True)
#LSTM的输出对应tag空间(tag space)
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size) #输入是[batch_size, size]中的size,输出是[batch_size,output_size]的output_size
#CRF层
self.crf = CRF(self.tagset_size) #默认batch_first=False
def forward(self, sentence, tags=None, mask=None): #sentence=(batch,seq_len) tags=(batch,seq_len)
self.batch_size = sentence.shape[0] #防止最后一batch中的数据量不够原本BATCH_SIZE
#1. 从sentence到Embedding层
embeds = self.word_embeds(sentence).permute(1,0,2)#.view(MAX_LEN,len(sentence),-1) #output=[seq_len, batch_size, embedding_size]
#2. 从Embedding层到BiLSTM层
self.hidden = (torch.randn(2,self.batch_size,self.hidden_dim//2),torch.randn(2,self.batch_size,self.hidden_dim//2)) #修改进来 shape=((2,1,2),(2,1,2))
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
#3. 从BiLSTM层到全连接层
#从lstm的输出转为tagset_size长度的向量组(即输出了每个tag的可能性)
lstm_feats = self.hidden2tag(lstm_out)
#4. 全连接层到CRF层
if tags is not None: #训练用 #mask=attention_masks.byte()
if mask is not None:
loss = -1.*self.crf(emissions=lstm_feats,tags=tags.permute(1,0),mask=mask.permute(1,0),reduction='mean') #outputs=(batch_size,) 输出log形式的likelihood
else:
loss = -1.*self.crf(emissions=lstm_feats,tags=tags.permute(1,0),reduction='mean')
return loss
else: #测试用
if mask is not None:
prediction = self.crf.decode(emissions=lstm_feats,mask=mask.permute(1,0)) #mask=attention_masks.byte()
else:
prediction = self.crf.decode(emissions=lstm_feats)
return prediction
#创建模型和优化器
model = BiLSTM_CRF(len(w2i), tag2i, EMBEDDING_DIM, HIDDEN_DIM,pad_index,BATCH_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
#显示模型基本参数
model
Embedding层将词indx转词向量,torch.nn.Embedding方法应该是采用随机变量确定embedding向量的;
LSTM层,隐藏层节点数6,因是BiLSTM所以需要乘以2,即共12个hidden units;
全连接层,由BiLSTM输出的向量转入全连接层,输出维度为tag个数;
CRF层。
采用SGD梯度优化方法进行参数优化,learning rate设为0.01(没经过特别研究),weight_decay设为1e-4。
(3)训练
samples_cnt = texts.shape[0]
batch_cnt = math.ceil(samples_cnt/BATCH_SIZE) #整除 向上取整
loss_list = []
for epoch in range(10):
for step, batch_data in enumerate(train_loader):
# 1. 清空梯度
model.zero_grad()
# 2. 运行模型
loss = model(batch_data['texts'], batch_data['labels'],batch_data['masks'])
if step%100 ==0:
logger.info('Epoch=%d step=%d/%d loss=%.5f' % (epoch,step,batch_cnt,loss))
# 3. 计算loss值,梯度并更新权重参数
loss.backward() #retain_graph=True) #反向传播,计算当前梯度
optimizer.step() #根据梯度更新网络参数
loss_list.append(loss)
(4)验证集进行验证
因为这次使用的数据集没有验证集,所以在开始时把训练集按7:3分为训练集和验证集,把分离开的验证集进行测试,看最后的F1-Score值评分情况。
#batch_masks:tensor数据,结构为(batch_size,MAX_LEN)
#batch_labels: tensor数据,结构为(batch_size,MAX_LEN)
#batch_prediction:list数据,结构为(batch_size,) #每个数据长度不一(在model参数mask存在的情况下)
def f1_score_evaluation(batch_masks,batch_labels,batch_prediction):
all_prediction = []
all_labels = []
batch_size = batch_masks.shape[0] #防止最后一batch的数据不够batch_size
for index in range(batch_size):
#把没有mask掉的原始tag都集合到一起
length = sum(batch_masks[index].numpy()==1)
_label = batch_labels[index].numpy().tolist()[:length]
all_labels = all_labels+_label
#把没有mask掉的预测tag都集合到一起
#_predict = y_pred[index][:length]
all_prediction = all_prediction+y_pred[index]
assert len(_label)==len(y_pred[index])
assert len(all_prediction) == len(all_labels)
score = f1_score(all_prediction,all_labels,average='weighted')
return score
#把每个batch的数据都验证一遍,取均值
model.eval() #不启用 BatchNormalization 和 Dropout,保证BN和dropout不发生变化
score_list = []
for step, batch_data in enumerate(test_loader):
with torch.no_grad(): #这部分的代码不用跟踪反向梯度更新
y_pred = model(sentence=batch_data['texts'],mask=batch_data['masks'])
score = f1_score_evaluation(batch_masks=batch_data['masks'],
batch_labels=batch_data['labels'],
batch_prediction=y_pred)
score_list.append(score)
#score_list
logger.info("average-f1-score:"+str(np.mean(score_list)))
Original: https://blog.csdn.net/Rhiney_97/article/details/121974153
Author: 音无八重
Title: pytorch BiLSTM+CRF模型实现NER任务
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528192/
转载文章受原作者版权保护。转载请注明原作者出处!