

此前的文章介绍过Seq2seq模型,并将其用于机器翻译。Seq2seq模型的一个问题在于随着输入句子越来越长,更早输入的单词就很大可能会被忘掉。于是,随着输入句子中单词数变多,翻译质量就会很快劣化。改善此问题的一个方法就是引入注意力机制(Attention),这种方法最初在文献【1】中被提出。
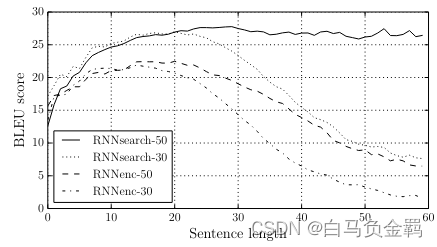
下面是【1】中给出的一个评估机器翻译质量的图示,其中横轴是句子中单词的数量,纵轴是评价机器翻译质量的BLEU分值。可见,随着句子中单词的数量的增多,Seq2seq模型的机器翻译质量劣化得很快,但在引入了Attention之后,翻译质量可以得到很大改善。

总的来说,注意力机制有如下一些优点:
• Attention tremendously improves Seq2Seq model.
• With attention, Seq2Seq model does not forget source input.
• With attention, the decoder knows where to focus.
但我们也需明白,引入Attention会大幅增加模型的计算量!
具体来说,如何在RNN中引入Attention呢?结合之前介绍的Seq2seq模型,如下图所示,Encoder的输出是
,对于每个Cell的
Original: https://blog.csdn.net/baimafujinji/article/details/123810692
Author: 白马负金羁
Title: 在RNN模型中引入注意力机制(Attention)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528188/
转载文章受原作者版权保护。转载请注明原作者出处!