

Aspect Sentiment Quad Prediction as Paraphrase Generation
Abstract
现有的研究通常考虑对部分情绪要素的检测,而不是一次预测四个要素。
本文引入了方面情感四元预测任务(ASQP),旨在联合检测一个特定意见句的四元情感元素,以揭示一个更全面、更完整的方面层面情感结构。
作者进一步提出了一个新的paraphrase范式,将ASQP任务转换为一个生成过程。一方面,生成公式允许端到端的方式求解ASQP,减轻了使用管道潜在的误差传播。另一方面,通过学习以自然语言的形式生成情感元素,可以充分利用情感元素的语义。
大量实验表明了方法的优越性。
1 Introduction
一般而言,ABSA包含四个基本的情感要素,包括方面术语(aspect term)、方面类别(aspect category)、意见术语(opinion term)和情绪极性(sentiment polarity)。例句” The pasta is over-cooked!“,其中四个情感元素分别为” food quality“、” pasta“、” overcooked“和” negative“。
早期的研究集中在单一元素的预测,而最近的研究建议同时提取多个相关的情绪元素。为此,本文引入了方面情绪四分量预测任务(ASQP),这个新任务弥补了以前任务的不足,并帮助我们全面理解用户的方面级意见。
为了解决ASQP问题,一个简单的想法是将四次预测问题分解成几个子任务,并以pipeline的方式解决它们。然而,这种多阶段的方法会产生严重的误差传播。此外,子任务通常表现为token或sequence分类问题,不能充分利用语义信息。
在本文中,作者提出以seq2seq的方式处理ASQP。一方面,四种情绪元素可以端到端进行预测,减轻了pipeline中的误差传播;另一方面,通过学习生成自然语言形式的情感元素,可以充分利用丰富的标签语义信息。
ASQP任务主要面临两个挑战:
- 如何将期望的情绪信息线性化以促进seq2seq学习
- 我们如何利用预训练模型来处理任务,这也是目前解决各种ABSA任务的常见做法
所以本文提出了一种新的paraphrase范式,可以将ASQP任务转换为释义生成问题。
例如,可以将情绪四分量(food quality, pasta, overcooked, negative) 转换成句子“Food quality is bad because pasta is overcooked” ,这样一个目标序列可以与输入句“the pasta is overcooked!”作为模型的映射,然后对这种输入目标对进行微调,无缝地利用大型预训练模型。
因此,情感元素的语义以自然句的形式与预训练模型融合在一起,而不是直接将情感四元素序列作为生成目标。
本文贡献:
- 提出了一个新的课题,即方面情绪四元素预测(ASQP),并引入了两个数据集,对每个样本进行情绪四元素标注,旨在分析更全面的方面层面情绪信息。
- 提出将ASQP作为一个释义生成问题来处理,该问题可以一次预测情感四元组,并充分利用自然语言标签的语义信息。
- 大量实验表明,所提出的paraphrase模型能够有效地处理ASQP和其他ABSA任务,在所有情况下都优于以往的最先进的模型。
- 实验还表明,在统一的框架下,该方法促进了相关任务间的知识转移,在低资源环境下尤其有效。
2 Related Work
3 Methodology
3.1 Problem Statement
给定一个句子x x x,相位情绪四元预测(ASQP)的目标是预测与方面类别、方面术语、意见词、情绪极性分别对应的所有情绪四元组{ ( c , a , o , p ) } {(c, a, o, p)}{(c ,a ,o ,p )}。方面类别c c c属于方面类别集V c V_c V c ;方面术语a a a和意见术语o o o通常是在句子x x x中的文本跨度,而如果没有明确提到目标,方面术语也可以为空:a ∈ V x ∪ { ∅ } a \in V_{\boldsymbol{x}} \cup{\varnothing}a ∈V x ∪{∅};o ∈ V x o∈V_x o ∈V x ,其中V x V_x V x 表示包含x x x的所有可能连续空间的集合;情绪极性p p p属于一个情绪类{ P O S , N E U , N E G } {POS, NEU, NEG}{P O S ,N E U ,N E G },分别表示积极、中性和消极情绪。
3.2 ASQP as Paraphrase Generation
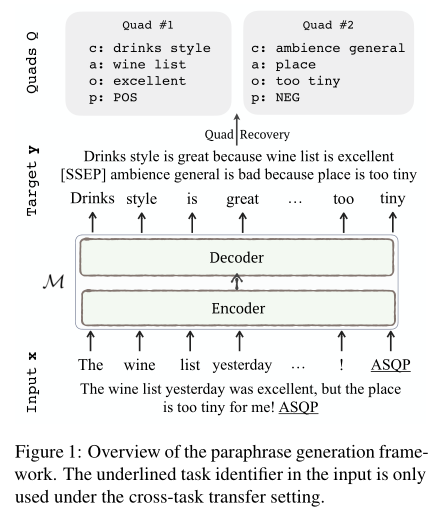

给定一个句子x x x,目标是生成一个目标序列y y y,其encoder-decoder为M : x → y M: x→y M :x →y,其中y y y包含所有需要的情感元素。然后从y y y中恢复情绪四元组Q = { ( c , a , o , p ) } Q = {(c, a, o, p)}Q ={(c ,a ,o ,p )}进行预测。
PARAPHRASE Modeling 为了促进seq2seq学习,给定句子标签对( x , Q ) (x, Q)(x ,Q ),paraphrase模型的一个重要组成部分是将情感四元组Q Q Q线性化为自然语言序列y y y,以构建输入目标对( x , y ) (x, y)(x ,y )。理想情况下,我们的目的是在释义过程中,忽略输入句中不必要的细节,而突出目标句中主要的情感成分。所以,作者将情绪四元组q = ( c , a , o , p ) q = (c, a, o, p)q =(c ,a ,o ,p )线性化为一个自然句子,如下所示:

其中P z ( ⋅ ) \mathcal{P}_{z}(·)P z (⋅)是z ∈ { c , a , o , p } z∈{c, a, o, p}z ∈{c ,a ,o ,p }的投影函数,它将情感元素z z z从原始格式映射到自然语言形式。
对于具有多个情感四元组的输入句子,首先将每个四元组线性化为一个自然句子。
Target Construction for ASQP 由于每个情绪四分体中的方面类别c c c和意见词o o o已经是自然语言形式,所以P c ( c ) \mathcal{P}{c}(c)P c (c ),P o ( o ) \mathcal{P}{o}(o)P o (o )。对于情绪极性,投影如下:
P p ( p ) = { great if p = P O S ok if p = N E U bad if p = N E G \mathcal{P}_{p}(p)=\left{\begin{array}{ll} \text { great } & \text { if } p=\mathrm{POS} \ \text { ok } & \text { if } p=\mathrm{NEU} \ \text { bad } & \text { if } p=\mathrm{NEG} \end{array}\right.P p (p )=⎩⎨⎧great ok bad if p =P O S if p =N E U if p =N E G
其主要思想是将情感标签从原始的类别格式转换为自然语言表达,需要注意的是,具体的映射既可以用公式(1)中的常识预先定义,也可以用数据相关来定义。
对于方面术语,如果没有明确提到,则映射为” it“,否则可以直接使用原始的自然语言形式:
P a ( a ) = { it a = ∅ a otherwise \mathcal{P}_{a}(a)=\left{\begin{array}{ll} \text { it } & a=\varnothing \ a & \text { otherwise } \end{array}\right.P a (a )={it a a =∅otherwise
之后就可以将一个情感四元组转换成包含所有元素的句子,以自然语言的形式进行seq2seq学习。

; 3.3 Sequence-to-Sequence Learning
输入到输出可以用经典的encoder-decoder模型(如Transformer)建模。给定句子x x x,编码器首先将其转换成上下文编码的序列e e e,然后解码器拟合出目标句子y y y:p θ ( y ∣ e ) p_θ(y|e)p θ(y ∣e )的条件概率分布,该输入表示由θ参数化。
θ \theta θ是啥?
在第i i i个时间步,解码器输出y i y_i y i 是基于编码后的输入e e e和之前的输出y < i y_{:y i = f d e c ( e , y < i ) y_{i}=f_{dec}\left(e, y_{,其中f d e c ( ⋅ ) f_{dec}(\cdot)f d e c (⋅)为解码器表示。为了,然后应用softmax以获得下一个token的概率分布:
p θ ( y i + 1 ∣ e , y < i + 1 ) = softmax ( W T y i ) p_{\theta}\left(\boldsymbol{y}{i+1} \mid \boldsymbol{e}, \boldsymbol{y}{
为什么用y < i y_{而不用y i − 1 y_{i-1}y i −1 ?
其中W W W将预测y i y_i y i 映射为一个logit向量,然后可以用来计算整个词汇集的概率分布
logit向量:概率P P P是一个0到1之间的实数,以掷骰子为例,掷出点数为6的概率为P = 1 6 P=\frac{1}{6}P =6 1 ,
Odds指的是 事件发生的概率 与 事件不发生的概率 之比。公式表示为:
O d d s = P 1 − P Odds=\frac{P}{1-P}O d d s =1 −P P
Odds的对数称之为Logit。(可理解为log-it)
Training 通过预训练的编码器-解码器模型如T5,可以用预训练的参数权值初始化θ θθ,并进一步微调输入目标对上的参数,使对数p θ ( y ∣ e ) p_θ(y|e)p θ(y ∣e )最大化:
max θ log p θ ( y ∣ e ) = ∑ i = 1 n log p θ ( y i ∣ e , y < i ) \max {\theta} \log p{\theta}(\boldsymbol{y} \mid \boldsymbol{e})=\sum_{i=1}^{n} \log p_{\theta}\left(\boldsymbol{y}{i} \mid \boldsymbol{e}, \boldsymbol{y}{
Inference and Quad Recovery 训练结束后,以自回归的方式生成目标序列y ′ y^{\prime}y ′,并在每个时间步中选择词汇集中概率最高的token作为下一个token。然后我们就可以从迭代中恢复预测的情绪四元组Q ′ Q^{\prime}Q ′。
具体来说,我们首先通过检测[SSEP]来分割多个四元组,然后对于每个线性化的情绪四元组,我们根据第3.2节介绍的方法提取情绪元素,并与Q Q Q中的gold情绪四序列进行比较。如果解码失败,我们将预测视为空(null)。
3.4 ABSA as Paraphrase Generation
所提出的paraphrase模型实际上提供了一个解决ABSA问题的通用范式,可以很容易地扩展到处理其他ABSA任务:只需要改变每个情绪元素的投影函数。
我们以目标方面情绪检测(TASD)[1]和方面情绪三联体提取(ASTE)[2]任务为例
[1] Wan H, Yang Y, Du J, et al. Target-aspect-sentiment joint detection for aspect-based sentiment analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(05): 9122-9129.
[2] Peng H, Xu L, Bing L, et al. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(05): 8600-8607.
TASD=Aspect-Category-Sentiment Detection (ACSD)
TASD任务预测了( c , a , p ) (c, a, p)(c ,a ,p )三联体,其中所有的情绪元素都具有与ASQP问题相同的条件。由于不涉及意见词预测,我们只设P o ( o ) = P p ( p ) \mathcal{P}{o}(o)=\mathcal{P}{p}(p)P o (o )=P p (p ), P p ( p ) \mathcal{P}{p}(p)P p (p )使用人工构造的意见词来描述释义中的情绪。其他投影函数可以保持与ASQP任务中的相同。例如,它将( s e r v i c e g e n e r a l , w a i t e r , N E G ) (service\text{ }general, waiter, NEG)(s e r v i c e g e n e r a l ,w a i t e r ,N E G )三连词转换成目标句” _service general is bad because waiter is bad“。
对于旨在预测( a , o , p ) (a, o, p)(a ,o ,p )三联体的ASTE任务,作者在所有情况下都将方面类别映射为一个隐式代词,例如 ” it” (P o ( o ) = i t \mathcal{P}{o}(o)=it P o (o )=i t),然后使用方面词的原始自然语言形式:P a ( a ) = a \mathcal{P}{a}(a)=a P a (a )=a。给出一个例子( C h i n e s e f o o d , n i c e , P O S ) (Chinese food, nice, POS)(C h i n e s e f o o d ,n i c e ,P O S ),就可以构造一个目标句”It is great because Chinese food is nice”。
3.5 Cross-task Knowledge Transfer
paraphrase方法可以在统一的框架中处理各种ABSA任务,这一特性使得知识在相关的ABSA任务之间很容易传递,在低资源设置(即有关任务的标记数据不足)下尤为有利。
paraphrase可以首先从TASD和ASTE任务中学习,然后通过对有限的ASQP数据进行微调,迁移到ASQP任务中。
4 Experimental Setup
Dataset SemEval Shared Challenges(2015,2016),意见词和方面类别的标注来自Wan et al. (2020)[1]和Peng et al. (2020)[2],对其中不满足条件的数据进行手工修改。最后得到Rest15和Rest16两个数据集,其中每条数据包含一个句子,句子中有一个或多个情绪四元组。
Baseline 以前ASQP没有人做过,所以作者构造了两个Baseline:
- Pipeline model:用HGCN[3]用于检测方面类别和情绪极性,基于BERT来提取方面词和意见词[4]
[3] Cai H, Tu Y, Zhou X, et al. Aspect-category based sentiment analysis with hierarchical graph convolutional network[C]//Proceedings of the 28th International Conference on Computational Linguistics. 2020: 833-843.
[4] Li X, Bing L, Zhang W, et al. Exploiting BERT for end-to-end aspect-based sentiment analysis[J]. arXiv preprint arXiv:1910.00883, 2019.
- Unified model:用TAS[1]提取( c , a , p ) (c, a, p)(c ,a ,p )三元组。作者改变了标记模式,同时预测方面项和意见项,以此构建统一的模型来预测情绪四元组,记为TASO(带意见的TAS)。在预测层方面有两种变体:1.使用线性分类层(TASO-Linear);2.使用CRF层(TASOCRF)。 作者还考虑了一种generation-type的基线模型 GAS,最初是在[5]中提出的,对其进行了修改,直接将情绪四元序列作为学习生成模型的目标。
[5] Zhang W, Li X, Deng Y, et al. Towards Generative Aspect-Based Sentiment Analysis[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 2021: 504-510.
5 Results and Discussions
5.1 Main Results
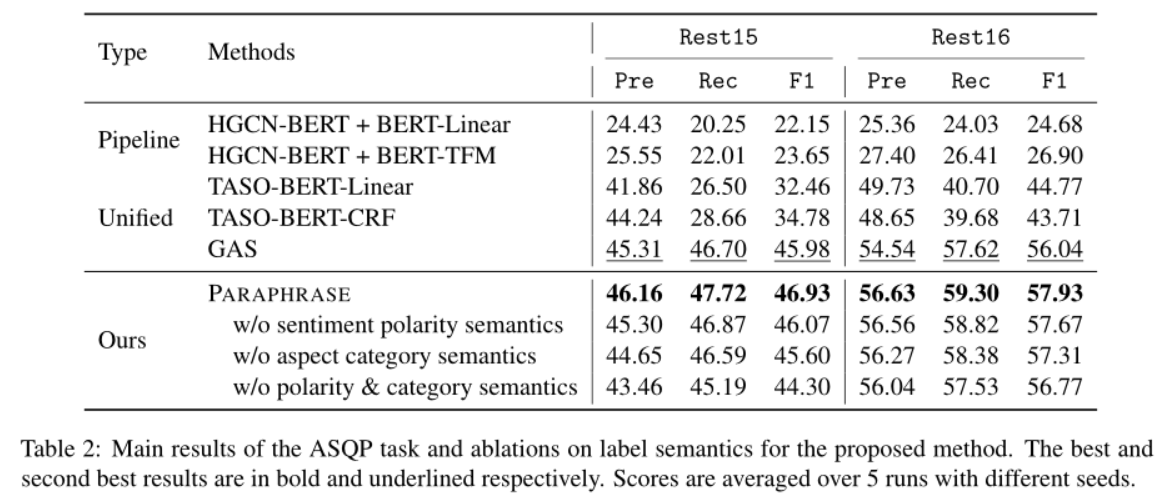
结果表明:
- 首先,pipeline方法的性能远远不能令人满意,虽然两者都以BERT为主,但unified方法(如TASO-BERT- Linear)的性能明显优于pipeline方法(如HGCN-BERT + BERT-Linear),验证了作者关于错误传播的假设。
- 其次,在unified方法中,GAS的性能明显优于TASO的两个变体,表明了对ASQP任务进行seq2seq建模的有效性。此外,为了统一解决任务,TASO将数据集扩展到∣ V c ∣ × ∣ V p ∣ \left|V_{c}\right| \times\left|V_{p}\right|∣V c ∣×∣V p ∣乘以原始大小,计算量和训练时间都比较大。
- 第三,作者提出的方法在两个数据集的所有指标上都表现最优,此外,与使用相同的预训练模型的GAS方法相比,paraphrase模型也取得了更好的结果,表明以自然语言形式构建目标序列是利用预训练生成模型知识的更好方式。
; 5.2 Effect of Label Semantics
为进一步调查标签语义的影响,作者进行了消融研究。
作者没有将标签映射到自然语言形式,而是将每个标签映射到一个特殊符号。作者考虑了三种情况:
- w/o 情感极性:P p ( p i ) = S P i \mathcal{P}_{p}(p_i)=SPi P p (p i )=S P i,其中p i p_i p i 为情感极性,例如,将正类映射为S P 1 SP1 S P 1;
- w/o 方面类别:P c ( c j ) = A C j \mathcal{P}_{c}(c_j)=ACj P c (c j )=A C j,将方面类别c j c_j c j 投射到一个索引为j 3 j^3 j 3的符号。例如,方面类别”食品质量”将映射到A C 3 AC3 A C 3;
- w/o 情感极性与方面类别:考虑了上述两种情况,即方面类别的意义和情感极性都被移除了。
结果表明,舍去任意一个元素都会导致性能下降,并且舍去两个元素之后性能下降的幅度会更大,舍去方面类别模型受到的影响更大。可能是因为情绪极性数量远远少于方面类别的数量。因此,符号和情绪极性之间更容易得到映射。
5.3 Results on ASTE and TASD Tasks
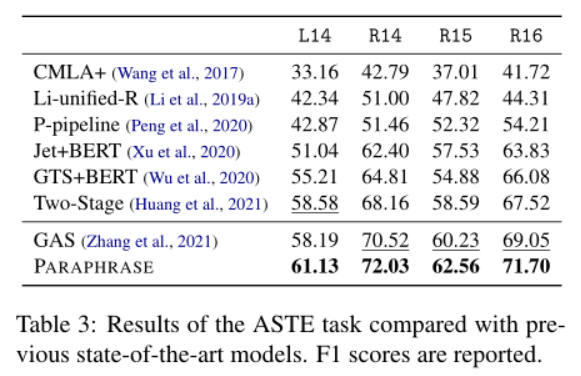
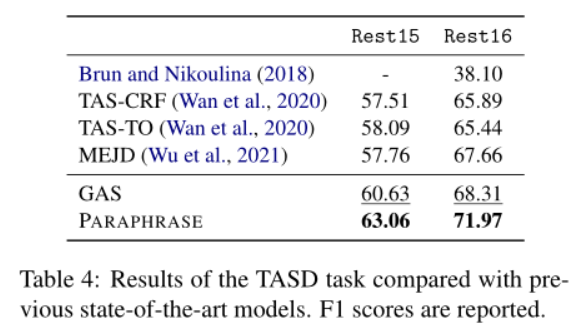
paraphrase方法在所有数据集上的表现始终优于以前的最先进的模型,表明了paraphrase方法的巨大通用性。
; 5.4 Error Analysis and Case Study
作者在每个数据集的开发集中抽取100个句子,并使用训练好的模型进行预测,然后对其中错误类型进行分类。
首先分析了情绪四元组中哪种类型的情绪元素是模型最难预测的,结果如图3a所示。
在这两个数据集中,最常见的错误是意见词。与方面词不同,意见词通常不是一个单独的词,模型常常难以探测到与基本事实完全相同的跨度,如图3b中的Example-1所示。对于方面类别,模型经常混淆语义相似的方面类别,比如” food quality“和” food style options“。对于情绪极性,最常见的错误是混淆了”积极”和”中性”,可能是由于数据集中的标签分布不平衡。

5.5 ABSA Cross-task Transfer
作者考虑两种情况:有足够的用于传输的ASTE/TASD数据(“足够的传输”),只有少量的ASTE/TASD数据(“少量的传输”)。
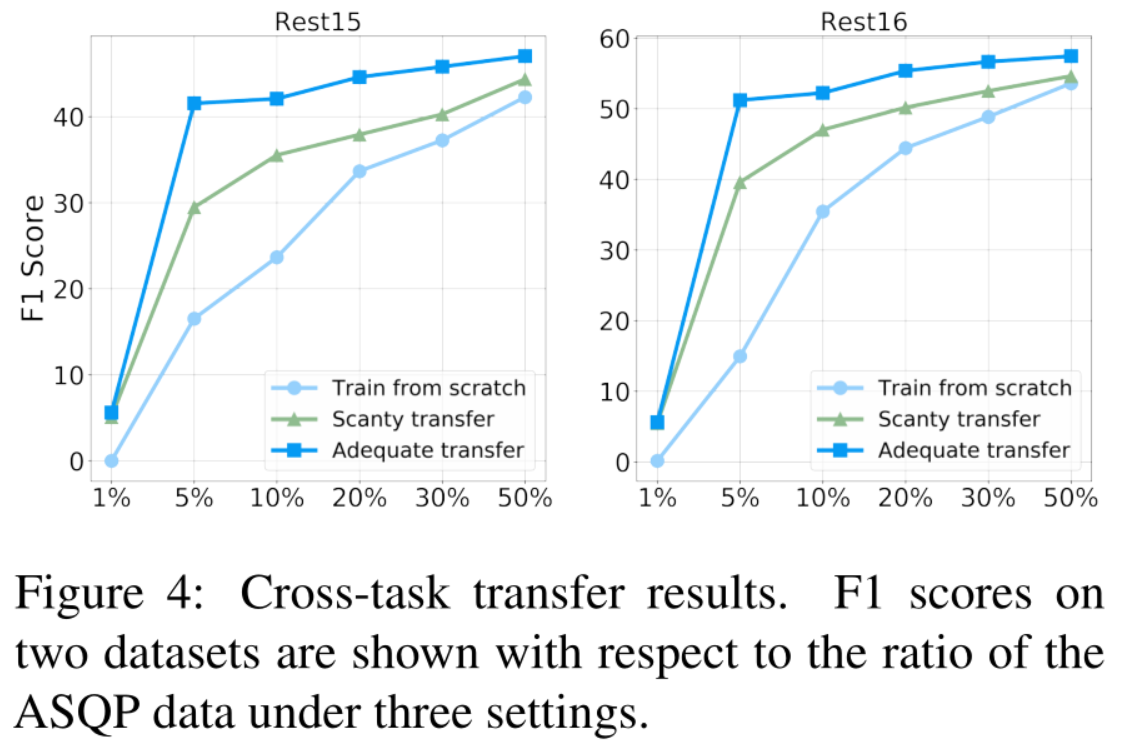
改变ASQP数据的比例,以模拟低资源设置的不同规模。从图中可以看出,利用从两个三元组检测任务中学习到的知识,有利于有关情绪的四元组预测。例如,使用足够的ASTE和TASD注释数据,与使用50% ASQP数据的纯训练相比,使用5%的ASQP数据就可以保持很高的性能。即使在相关任务传输的数据量很少的情况下,该模型仍然可以比单纯的情感四元数据训练效果更好,特别是在低资源设置下。
; 6 Conclusions
本文引入了一种新的ABSA任务,即方面情绪四元组预测(aspect sentiment quad prediction, ASQP),旨在提供更全面的方面级情绪分析。我们提出了一种新的paraphrase建模范式,将原始的四次预测作为释义生成问题来处理。在两个数据集上的实验表明,该模型与现有的先进模型相比具有优越性。
还证明了所提出的方法提供了一个统一的框架,可以很容易地适应处理其他ABSA任务。并进行了广泛的分析,以了解所提出方法的特点。
Original: https://blog.csdn.net/qq_43658933/article/details/123972826
Author: Trigger_2017
Title: 论文阅读——Aspect Sentiment Quad Prediction as Paraphrase Generation
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528180/
转载文章受原作者版权保护。转载请注明原作者出处!