

目录
Transformer
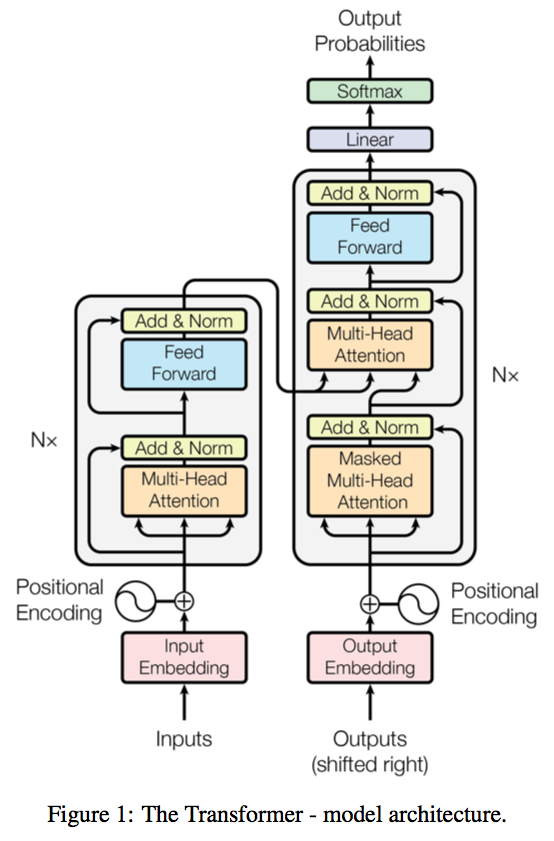

Transformer 是由 Google 团队在 17 年 6 月提出的 NLP 经典之作,由 Ashish Vaswani 等人在 2017 年发表的论文 Attention Is All You Need 中提出。
原文网址如下:
https://arxiv.org/pdf/1706.03762.pdf
Transfromer中使用了self-attention机制,那何为attention?
Attention其实就是一个当前的输入与输出的匹配度。
; 1.self-attention 具体原理
- 第一步,Encoder的每个输入单词创建三个向量,
即 Query vector, Key vector, Value vector,三个向量分别由embedding结果和权重矩阵相乘得到。 - 第二步,由q*k计算得分,得到关注度。
- 第三步,将数据处理的稳健,并进行softmax。
- 第四步,得分乘以Value向量值。
- 第五步,将value加权得到self-attention值。
2.多头注意力机制
使用多个权重矩阵,分别与 Query vector, Key vector, Value vector进行self-attention计算。并将计算结果拼接为一个矩阵,进行前向传播计算。
3.Decoder
Decoder神奇之处在于将向量转变为单词,实现方法通过一个全连接层和Softmax函数实现。得到与候选单词数量相同维度的矩阵,根据概率选择最大的作为该位置的结果。
源码复现:
https://github.com/jadore801120/attention-is-all-you-need-pytorch
Model部分源码如下:
class Encoder(nn.Module):
''' A encoder model with self attention mechanism. '''
def __init__(
self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, dropout=0.1, n_position=200, scale_emb=False):
super().__init__()
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, src_seq, src_mask, return_attns=False):
enc_slf_attn_list = []
enc_output = self.src_word_emb(src_seq)
if self.scale_emb:
enc_output *= self.d_model ** 0.5
enc_output = self.dropout(self.position_enc(enc_output))
enc_output = self.layer_norm(enc_output)
for enc_layer in self.layer_stack:
enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)
enc_slf_attn_list += [enc_slf_attn] if return_attns else []
if return_attns:
return enc_output, enc_slf_attn_list
return enc_output,
class Decoder(nn.Module):
''' A decoder model with self attention mechanism. '''
def __init__(
self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, n_position=200, dropout=0.1, scale_emb=False):
super().__init__()
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_slf_attn_list, dec_enc_attn_list = [], []
dec_output = self.trg_word_emb(trg_seq)
if self.scale_emb:
dec_output *= self.d_model ** 0.5
dec_output = self.dropout(self.position_enc(dec_output))
dec_output = self.layer_norm(dec_output)
for dec_layer in self.layer_stack:
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)
dec_slf_attn_list += [dec_slf_attn] if return_attns else []
dec_enc_attn_list += [dec_enc_attn] if return_attns else []
if return_attns:
return dec_output, dec_slf_attn_list, dec_enc_attn_list
return dec_output,
class Transformer(nn.Module):
''' A sequence to sequence model with attention mechanism. '''
def __init__(
self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx,
d_word_vec=512, d_model=512, d_inner=2048,
n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,
trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True,
scale_emb_or_prj='prj'):
super().__init__()
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx
assert scale_emb_or_prj in ['emb', 'prj', 'none']
scale_emb = (scale_emb_or_prj == 'emb') if trg_emb_prj_weight_sharing else False
self.scale_prj = (scale_emb_or_prj == 'prj') if trg_emb_prj_weight_sharing else False
self.d_model = d_model
self.encoder = Encoder(
n_src_vocab=n_src_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=src_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.decoder = Decoder(
n_trg_vocab=n_trg_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=trg_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
assert d_model == d_word_vec, \
'To facilitate the residual connections, \
the dimensions of all module outputs shall be the same.'
if trg_emb_prj_weight_sharing:
self.trg_word_prj.weight = self.decoder.trg_word_emb.weight
if emb_src_trg_weight_sharing:
self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight
def forward(self, src_seq, trg_seq):
src_mask = get_pad_mask(src_seq, self.src_pad_idx)
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)
enc_output, *_ = self.encoder(src_seq, src_mask)
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)
seq_logit = self.trg_word_prj(dec_output)
if self.scale_prj:
seq_logit *= self.d_model ** -0.5
return seq_logit.view(-1, seq_logit.size(2))
Original: https://blog.csdn.net/weixin_39490300/article/details/123168345
Author: 易烊千蝈
Title: 处理时间序列数据的高端模型Transformer和Pytorch代码实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528158/
转载文章受原作者版权保护。转载请注明原作者出处!