

前言
由于被宿友问了很多问题,于是就果断在2021最后一天自己从头实现自定义dataset, 自定义模型,写了训练代码,预测输出代码。
准确率虽然不高,但这个过程让我清楚了中间处理的一些细节。另外本文对于如何使用huggingface的transformers模型去解决特定任务,具有一定的参考学习意义。
数据集: https://dl.fbaipublicfiles.com/glue/data/SST-2.zip
我一开始发现结果不是很好,以为是我模型参数,优化器之类的没调好…(后来发现错误见下文)


另外本文代码绝大部分都是凭我自己意思写出来的,可能规范性啥的还不算好,请路过的大佬不吝赐教。
2022.1.2补充: 对不起,是我缩进没注意, 按理是要每个step(因为每一个step就是一个batch)就要反向传播更新一次权重。
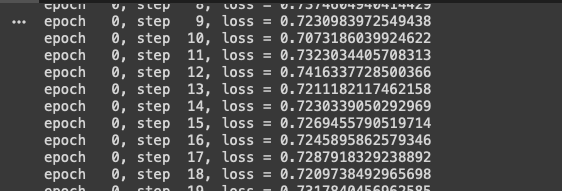
可以看到损失降下去了
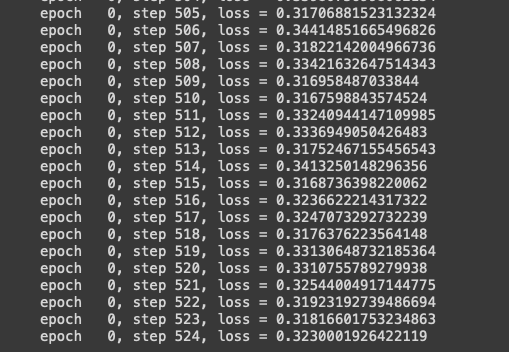
这里只为演示,我的epoch_num设置为1轮,一般都是5~10, 不过也看具体任务。
至于只训练一个epoch为什么会这么好呢,主要是我模型中的主干网络distilBert加载了在SST2数据集上进行预训练的distilbert-base-uncased-finetuned-sst-2-english权重。可能从distilbert-base-uncased权重开始训练的话要多几个epoch才能接近这个效果。
不过无所谓,这里只是一个流程罢了,可以方便大家以后延续使用。大家也可以更具自己需要,更换模型,模型更换非常简单。只需要改一句话就够了(下文会说)。

2022.1.3补充: 对不起,上述结果是有问题的。是偏乐观的。因为加载了fine-tune的权重,虽然我没有泄露用来当测试集的数据,但我那从train.tsv分出来的15%的数据,实际上是被别人fine-tune过了,于是会使得结果更加乐观。有空我再更正,不过不是大问题,大家使用的时候,读入的数据注意一下就好。
另外值得一提的事,也可以把padding操作写成一个函数,然后放入dataloader的collate_fn参数中,这样就不用在内存存着全部数据的padding的部分了,而是只存当前batch的padding部分。
; 代码
需要装下transformers, NLPer应该不陌生了
bash下:
!pip install transformers
使用的数据集 bash下:
!wget https://dl.fbaipublicfiles.com/glue/data/SST-2.zip
解压一下:
!unzip SST-2.zip
引入库
import numpy as np
import pandas as pd
from sklearn.utils import shuffle
import torch
import transformers
import warnings
import pandas as pd
import torch.nn as nn
import torch.utils.data as Data
import torch.nn.functional as F
from sklearn import metrics
from transformers import AutoTokenizer, AutoModel
warnings.filterwarnings('ignore')
声明好跑的设备
device = 'cuda'
数据准备
读取数据文件
df = pd.read_csv('/content/SST-2/train.tsv', delimiter='\t', skiprows=[0], header=None)
df_len = len(df)
print(df)
print('df_len: ', df_len)
划分训练集和测试集
split_rate = 0.85
train_df = df[:int(df_len * split_rate)]
test_df = df[int(df_len * split_rate):]
设置一下参数
lr = 0.001
epoch_num = 5
train_batch_size = 64
test_batch_size = 64
加载一下分词器,并指定一下使用的模型名字(关于model_name_str设置为甚么具体大家看下面代码的注释)。
model_name_str = 'distilbert-base-uncased-finetuned-sst-2-english'
tokenizer = AutoTokenizer.from_pretrained(model_name_str)
也可以先下好权重文件和配置文件,然后model_name_str指定文件夹即可。
自定义dataset类
根据crossEntropyLoss的用法, labels不去onehot也是可以的, 详见 torch.nn.CrossEntropyLoss用法
class SentimentDataset(Data.Dataset):
def __init__(self, rawdata_df):
super(SentimentDataset, self).__init__()
print(rawdata_df[1].value_counts())
self.labels = torch.tensor(rawdata_df[1].values).long()
tokenized = rawdata_df[0].apply((lambda x:tokenizer.encode(x, add_special_tokens = True)))
max_len = 0
for i in tokenized.values:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0] * (max_len - len(i)) for i in tokenized.values])
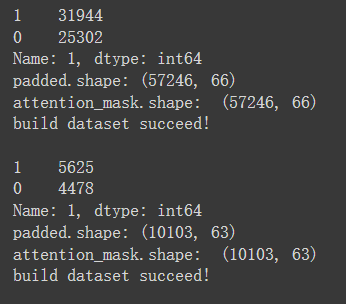
print('padded.shape:', padded.shape)
attention_mask = np.where(padded != 0, 1, 0)
print('attention_mask.shape: ', attention_mask.shape)
self.data = torch.LongTensor(padded)
self.attention_mask = torch.tensor(attention_mask)
print('build dataset succeed!\n')
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return self.data[idx].to(device), self.attention_mask[idx].to(device), self.labels[idx].to(device)
train_dataset = SentimentDataset(train_df)
test_dataset = SentimentDataset(test_df)
train_loader = Data.DataLoader(train_dataset, train_batch_size, shuffle=True)
test_loader = Data.DataLoader(test_dataset, test_batch_size, shuffle=True)
自定义模型
注意下次想要加载之前保存过的模型文件之前,要先运行下面这个模型定义。如何保存下文会讲。
这里提一下SST2类的forward函数里的这两句。
按照transformers的bert类实现,返回的输出是个元组(如果return_dict参数为False情况下,该参数默认值为False),那么x[0]就是输出的特征, x[1:]就是输出的一些列中间结果。
这里我们取x[0]即输出的特征
然后我们对每一个batch取第一个(第0个)token即 【cls】 特殊字符的词向量.
第一个 : 指的是取所有batch, 0是指取第0个token, 第三个 : 是指取出词向量的所有值(bert默认为768)。
features = x[0][:, 0, :]
x = self.fc1(features)
class SST2(nn.Module):
def __init__(self, class_num=2, no_grad=True):
super(SST2, self).__init__()
hidden_dim = 768
self.backbone = AutoModel.from_pretrained(model_name_str)
if no_grad:
for layer in list(self.backbone.parameters()):
layer.requires_grad = False
self.fc1 = nn.Linear(hidden_dim, hidden_dim * 4)
self.fc2 = nn.Linear(hidden_dim * 4, class_num)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x, attention_mask):
x = self.backbone(x, attention_mask=attention_mask)
features = x[0][:, 0, :]
x = self.fc1(features)
x = self.relu(x)
x = self.fc2(x)
x = self.sigmoid(x)
return x
def show_backbone(self):
for name in self.backbone.state_dict():
print("{:30s}: {}, require_grad={}".format(name, self.backbone.state_dict()[name].shape))
def predict_label(self, x, attention_mask):
with torch.no_grad():
x = self.forward(x, attention_mask)
predict_labels = torch.max(x, dim=1)[1]
return predict_labels
def predict_example(self, input_str_lt, return_proba=True):
tokenized_input = []
for input_str in input_str_lt:
tokenized_input.append(tokenizer.encode(input_str, add_special_tokens = True))
data = torch.tensor(tokenized_input).to(device)
attention_mask = torch.ones_like(data).to(device)
print('attention_mask.shape: ', attention_mask.shape)
predicted = model(x=data, attention_mask=attention_mask)
proba, labels = torch.max(predicted, dim=1)
if return_proba:
return labels, proba
else:
return labels
实例化模型
model = SST2(class_num = 2, no_grad=False).to(device)
假如你是6分类,那么是
model = SST2(class_num = 6,no_grad=False).to(device)
def get_parameter_number(model_analyse):
total_num = sum(p.numel() for p in model_analyse.parameters())
trainable_num = sum(p.numel() for p in model_analyse.parameters() if p.requires_grad)
return 'Total parameters: {}, Trainable parameters: {}'.format(total_num, trainable_num)
查看一下模型总的参数量和可学习参数量
get_parameter_number(model)

for name, param in model.named_parameters():
if param.requires_grad:
print(name)
损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5, weight_decay=1e-4)
scheduler = transformers.get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=len(train_loader),
num_training_steps=epoch_num*len(train_loader))
训练
for epoch in range(epoch_num):
for step, (input_ids, att_mask, labels) in enumerate(train_loader):
predicted = model(x=input_ids, attention_mask=att_mask).to(device)
loss = criterion(predicted, labels)
print('epoch {:3}, step {:3}, loss = {}'.format(epoch, step, loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
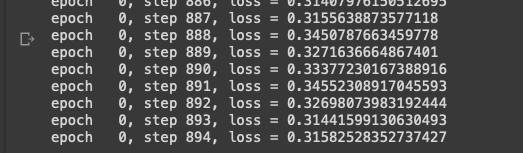
可以看到一个epoch需要894个step
看一下训练集与ground truth对比:
注意: 请注意查看注释那一句 “如果你在dataset时没有对labels进行one_hot,请把这下面这一句取max下标注释掉!”
for step, (input_ids, att_mask, labels) in enumerate(train_loader):
predicted_labels = model.predict_label(x=input_ids, attention_mask=att_mask)
labels = torch.max(labels, dim=1)[1]
if step < 4:
print(predicted_labels)
print(labels)
print()

测试
看一下测试集与ground truth对比, 并放入列表中:
注意: 请注意查看注释那一句 “如果你在dataset时没有对labels进行one_hot,请把这下面这一句取max下标注释掉!”
total_predict_lt = []
total_label_lt = []
for step, (input_ids, att_mask, labels) in enumerate(test_loader):
predicted_labels = model.predict_label(x=input_ids, attention_mask=att_mask)
labels = torch.max(labels, dim=1)[1]
total_predict_lt.extend(predicted_labels.tolist())
total_label_lt.extend(labels.tolist())
if step < 4:
print(predicted_labels)
print(labels)
print()
看下acc
metrics.accuracy_score(total_label_lt, total_predict_lt)
保存与读取
torch.save(model, 'SST2.pt')
下次加载模型可以这样子(就不需要训练了,当然你也可以继续进行fine-tune)
model = torch.load('SST2.pt')
预测输出
test_lt = ['I love you', 'I hate you']
label_lt, proba_lt = model.predict_example(input_str_lt=test_lt, return_proba=True)
for i in range(len(test_lt)):
print('{} 是否积极:{}, 置信度: {}'.format(test_lt[i], label_lt[i], proba_lt[i]))

Original: https://blog.csdn.net/weixin_43850253/article/details/122263916
Author: Andy Dennis
Title: 情感分析bert家族 pytorch实现(ing
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528058/
转载文章受原作者版权保护。转载请注明原作者出处!