

目录
模型架构
BERT的基础transformer结构(encoder部分):


输入部分:
对于transformer来说,输入部分会进行两个操作,包括Input Embedding和Positional Encoding两部分。
Input Embedding就是将输入转为词向量,可以是随机初始化,也可以是使用word2vec。
Positional Encoding就是位置编码,用正余弦三角函数来代表它。
上面是输入部分的操作,那么输入是什么呢?
[En]
The above is the operation of the input part, so what is the input?
实际上输入由三部分组成:Input = token embedding + segment embedding + position embedding

首先看Input部分,重点关注两个部分:
- 正常词汇:my, dog, is, cute, he, likes, play, ##ing(这种符号是分词后的产物,不用特意关注,当做正常词看就行)
-
特殊词汇:[CLS], [SEP]
两种特殊词汇的产生是由于BERT的预训练任务有一个是NSP(Next Sentence Prediction)二分类任务,是去判断 两个句子之间的关系。[SEP]就是为了告诉机器,在这个符号之前的是一个句子,在这个符号之后的是另一个句子。[CLS]是用于二分类的特殊符号,在训练时会将[CLS]的输出向量接一个二分类器来做二分类任务。但请注意,[CLS]的输出向量并不能代表句子的语义信息(用CLS做无监督的文本相似度时效果很差)。bert pretrain模型直接拿来做sentence embedding效果甚至不如word embedding,CLS的embedding效果最差(也就是pooled output),把所有普通token embedding做pooling勉强能用(这也是
开源项目bert-as-service的默认做法),但也不会比word embedding更好。 -
Token Embeddings:对所有词汇进行正常的embedding,比如随机初始化等。
- Segment Embeddings:用于区分两个句子,如上图所示,第一个句子的单词全是E A E_A E A ,第二个句子的单词全是E B E_B E B 。
- Position Embeddings:这一部分和基础结构中输入部分的Positional Encoding操作是 不同的。Positional Encoding使用正余弦函数,而Position Embeddings使用的是随机初始化,让模型自己学习出来Embedding。
最开始那张图仅仅是基础结构,因为在原论文中使用的是多个encoder堆叠在一起,如BERT-BASE结构是通过12个encoder堆叠在一起。
; 预训练步骤
分为MLM(Mask Language Model)和NSP(Next Sentence Prediction)两步
MLM(Mask Language Model)
BERT在预训练时使用的是大量的无标注语料,所以预训练任务要考虑用无监督学习来做。
无监督目标函数:
- AR(Auto Regressive):自回归模型,只考虑单侧的信息,典型的就是GPT
- AE(Auto Encoding):自编码模型,从损坏的输入数据中预测重建原始数据,可以使用上下文的信息,这也是BERT使用的方法。
例如,有一句话:“我喜欢吃东西]
[En]
For example, there is a sentence: “I like to eat]
AR:P ( 我 爱 吃 饭 ) = P ( 我 ) P ( 爱 ∣ 我 ) P ( 吃 ∣ 我 爱 ) P ( 饭 ∣ 我 爱 吃 ) P(我爱吃饭) = P(我)P(爱|我)P(吃|我爱)P(饭|我爱吃)P (我爱吃饭)=P (我)P (爱∣我)P (吃∣我爱)P (饭∣我爱吃)
AE:mask之后:【我爱mask饭】
P ( 我 爱 吃 饭 ∣ 我 爱 m a s k 饭 ) = P ( m a s k = 吃 ∣ 我 爱 饭 ) P(我爱吃饭|我爱mask饭) = P(mask = 吃|我爱饭)P (我爱吃饭∣我爱m a s k 饭)=P (m a s k =吃∣我爱饭)
打破了原本文本,让他进行文本重建,模型要从周围文本中不断学习各种信息,努力地让他能够预测或无限接近mask这里应该填”吃”。
但mask模型也有缺点:
若mask后【我爱mask mask】
优化目标:P ( 我 爱 吃 饭 ∣ 我 爱 m a s k m a s k ) = P ( 吃 ∣ 我 爱 ) P ( 饭 ∣ 我 爱 ) P(我爱吃饭|我爱mask mask) = P(吃|我爱)P(饭|我爱)P (我爱吃饭∣我爱m a s k m a s k )=P (吃∣我爱)P (饭∣我爱)
这里”吃”和”饭”模型会认为是相互独立的,但实际上我们知道”吃”和”饭”这两个词并不是独立的,室友一定关联的。
下面将介绍mask的具体过程:
随机mask 15%的单词,但并不是这些单词都要替换成mask。这15%的单词中,选出其中80%的单词直接替换成mask,其中10%的单词原封不动,剩下10%替换成其他单词,可以看代码更好地理解一下:
for index in mask_indices:
if random.random() < 0.8:
masked_token = "[MASK]"
else:
if random.random() < 0.5:
masked_token = tokens[index]
else:
masked_token = random.choice(vocab_list)
NSP
NSP样本如下:
- 从训练语料库中取出两个连续的段落作为正样本
- 从不同文档中随机创建一对段落作为负样本
缺点:主题预测(两段文本是否来自同一文档)和连贯性预测(两个段落是不是顺序关系)合并成一个单项任务。由于主题预测是非常简单的,非常容易去学习,导致NSP很容易没有效果。
下游任务微调BERT
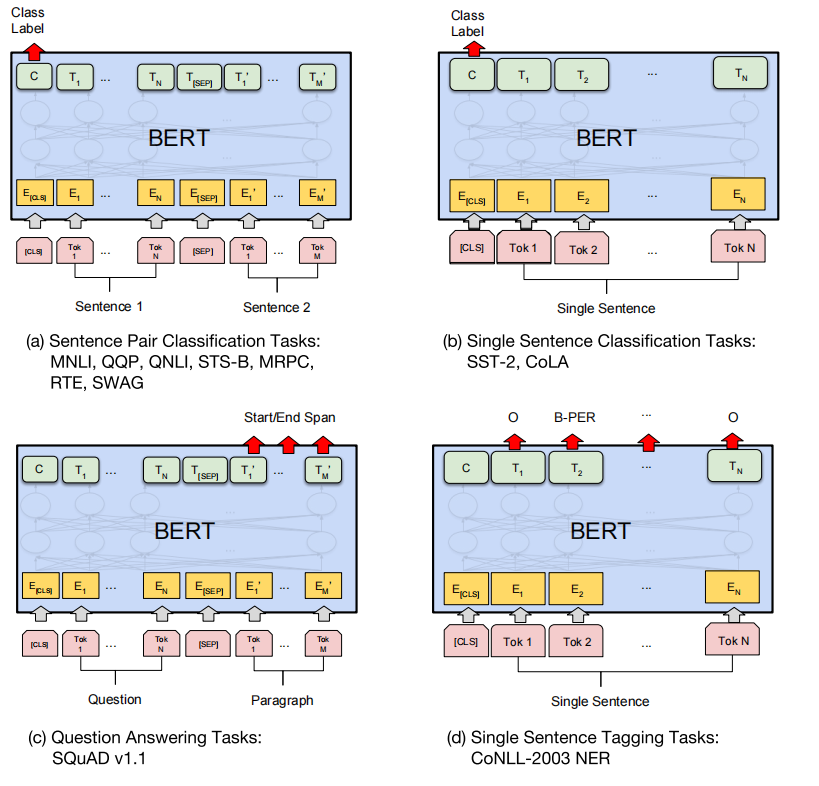
(a)句子对分类:也可以说是文本匹配任务,把两个句子拼接起来,用CLS输出判断,如0—不相似,1—相似;
(b)单个句子分类:用CLS输出做分类;
©问答
(d)序列标注任务:把每一个Token输入,做一个softmax,看他属于哪一个。
; 如何提升BERT下游任务表现
最简单的步骤:
- 获取谷歌中文BERT
- 基于任务数据进行微调
多一点改进(四步,以微博文字情感分析为例):
[En]
A little more improvement (four steps, take Weibo text emotion analysis as an example):
- 在大量通用语料上训练一个LM(Language Model,语言模型,以下简称LM)(Pretrain);
——一般不去做,直接用中文谷歌BERT - 在 相同领域上继续训练LM(Domain transfer);
——在大量 _微博文本_上训练这个BERT - 在 任务相关的小数据上继续训练LM(Task transfer);
——在 _微博情感文本_上(有的文本不属于情感分析的范畴) - 在任务相关数据上做具体任务(Fine-tune)
一般情况下,先 Domain transfer,再进行 Task transfer,最后 Fine-tune,性能是最好的。
如何在相同领域数据中进行further pre-training
- 动态mask:每次epoch去训练的时候mask,每次训练的mask很大概率是不一样的,而不是一直使用同一个。
- n-gram mask:比如 ERNIE 和 SpanBert 都是类似于做了实体词的mask
参数:
Batch size:16,32——影响不太大
Learning rate(Adam):5e-5,3e-5,2e-5,尽可能小一点,避免灾难性遗忘
Number of epoch:3,4
Weighted decay修改后的Adam,使用warmup,搭配线性衰减
Original: https://blog.csdn.net/Friedrichor/article/details/123768705
Author: friedrichor
Title: 通俗易懂地理解BERT并微调
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527659/
转载文章受原作者版权保护。转载请注明原作者出处!