

用于通用信息抽取的统一结构生成
《Unified Structure Generation for Universal Information Extraction》
论文地址:https://arxiv.org/pdf/2203.12277.pdf
一、简介
信息抽取(IE \text{IE}IE)的目标是从无结构化文本中识别和结构化用户指定的信息。IE \text{IE}IE任务由于不同的目标(实体、关系、事件、情感等)、不同的结构(spans、triplets、record等)和特定的需求模式而高度的多样性。当前,大多数的IE \text{IE}IE方法都是针对具体的任务,对于不同的IE \text{IE}IE任务会有专用的架构、独立的模型、特定的知识来源。
二、通用信息抽取的统一结构生成
信息抽取的任务可以被形式化为text-to-structure \text{text-to-structure}text-to-structure的问题。本文的目标是通过单个框架将不同的IE \text{IE}IE任务统一建模为text-to-structure \text{text-to-structure}text-to-structure任务,即在统一的模型中共享相同的底层操作以及不同的转换能力。正式来说,给定一个预定义模式s s s和文本x x x,通用IE \text{IE}IE模型需要生成一个模式s s s指明的文本中x x x所包含结构化信息。
这里主要存在两个挑战。首先,由于IE \text{IE}IE任务的多样性,有许多不同的目标结构需要抽取,例如:实体、关系和事件等。其次,IE \text{IE}IE任务通常针对不同的需求需要使用不同的schema,因此需要自适应的控制抽取过程。
本小节描述了如何在统一框架内学习和执行各种IE \text{IE}IE任务,称该框架为UIE \text{UIE}UIE。具体来说,设计了结构化抽取语言SEL \text{SEL}SEL来将不同的抽取结构进行统一编码,即将实体、关系和事件编码成统一表示。然后,设计了结构化schema指导器SSI \text{SSI}SSI,其是一个基于schema的prompt机制,用于控制UIE \text{UIE}UIE模型如何抽取、如何关联和如何生成。
1. 用于统一结构编码的结构化抽取语言 SEL \text{SEL}SEL


基于上面的讨论,IE \text{IE}IE结构生成能够被分解为两个原子操作。
- 定位(spotting):从文本中定位目标片段,例如:实体和事件中的触发词。
- 关联(associating):按照预定义的期望将不同的信息片段关联在一起,例如实体对间的关系;
不同的IE \text{IE}IE结构能够通过原子结构生成操作进行组合。
具体来说,设计了统一结构抽取语言SEL \text{SEL}SEL,该语言能够通过spotting-associating \text{spotting-associating}spotting-associating结构编码不同的IE \text{IE}IE结构。如上图( a ) (a)(a )所示,每个SEL \text{SEL}SEL表达式包含三种类型的语义单元:
(1) SPOTNAME \text{SPOTNAME}SPOTNAME:表示原始文本中需要被定位信息的类型;
(2) ASSONAME \text{ASSONAME}ASSONAME:表示原始文本中需要被抽取的、特定类型的关联;
(3) INFOSPAN \text{INFOSPAN}INFOSPAN:表示原始文本中需要被定位或者关联的文本片段;
上图( b ) (b)(b )展示了SEL \text{SEL}SEL如何表示实体、关系和事件的结构。其中包含三个实体,每个实体都使用一个spotting \text{spotting}spotting结构表示,即person:Steve \text{person:Steve}person:Steve、organization:Apple \text{organization:Apple}organization:Apple和time:1997 \text{time:1997}time:1997。work for \text{work for}work for表示实体Steve \text{Steve}Steve和Apple \text{Apple}Apple间的一个关系。此外,事件也可以被表示成关联结构。事件的trigger \text{trigger}trigger是一个spotting \text{spotting}spotting结构”start-postion:became” \text{“start-postion:became”}”start-postion:became”,事件的arguments \text{arguments}arguments则是被触发词关联的三个结构:(employee,Steve) \text{(employee,Steve)}(employee,Steve)、(employer,Apple) \text{(employer,Apple)}(employer,Apple)和(time,1997) \text{(time,1997)}(time,1997)。
SEL \text{SEL}SEL具有如下优势:
(1) 能够统一编码各种IE \text{IE}IE结构,因此能将不同的IE \text{IE}IE任务统一建模为text-to-structure \text{text-to-structure}text-to-structure过程;
(2) 使用统一结构高效表示所有的抽取结果,天然适合执行联合抽取;
(3) 输出结构紧密,大大减低了编码的复杂度;
举例来说,实体识别和事件检测两种不同的任务都可以使用相同的语法(SpotName: InfoSpan) \text{(SpotName: InfoSpan)}(SpotName: InfoSpan)。此外,关系抽取和事件抽取分别是二元结构entity-relation-entity \text{entity-relation-entity}entity-relation-entity和N N N元结构event-arguments \text{event-arguments}event-arguments,但它们都能够使用语法(SpotName: InfoSapn(AssName: InfoSpane),…) \text{(SpotName: InfoSapn(AssName: InfoSpane),…)}(SpotName: InfoSapn(AssName: InfoSpane),…)。这种统一的结构化抽取语言能够在不设计任务相关结构的情况下,使UIE \text{UIE}UIE能够从不同的IE \text{IE}IE任务中学习。
; 2. 用于可控 IE \text{IE}IE 结构生成的结构化Schema指导器 SSI \text{SSI}SSI
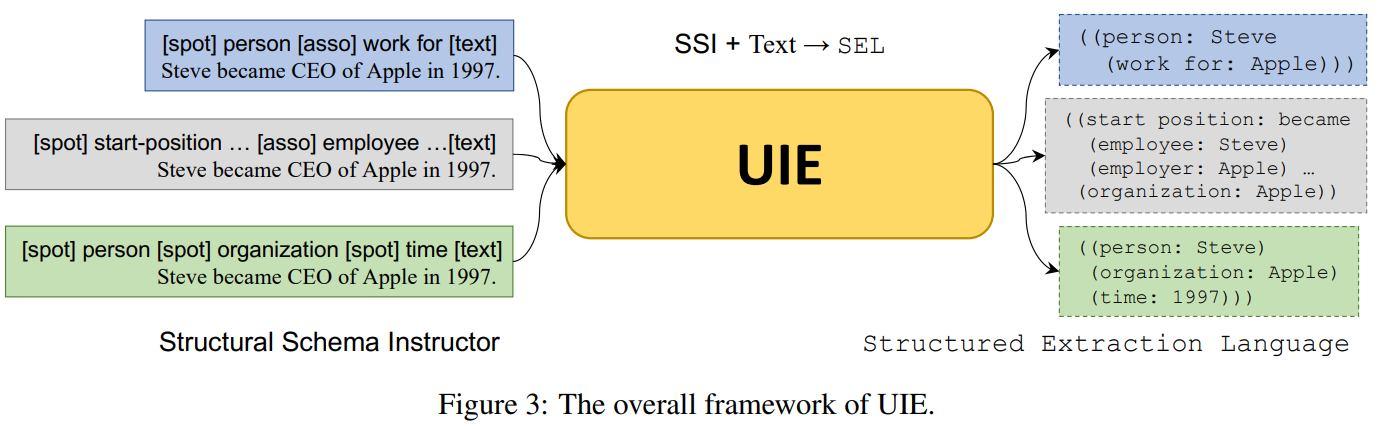
UIE \text{UIE}UIE通过使用SEL \text{SEL}SEL来为不同的IE \text{IE}IE任务生成统一的结构。但是,不同的IE \text{IE}IE任务具有不同的schemas,因此如何在抽取过程中自适应的生成期望的信息是一个挑战。例如,给定一个句子Steve became CEO of Apple in 1997. \text{Steve became CEO of Apple in 1997.}Steve became CEO of Apple in 1997.,期望生成三个实体结构((person: Steve)(organization: Apple)(Time: 1997)) \text{((person: Steve)(organization: Apple)(Time: 1997))}((person: Steve)(organization: Apple)(Time: 1997))和一个事件结构(start position: became(employee: Steve)(employer: Apple)) \text{(start position: became(employee: Steve)(employer: Apple))}(start position: became(employee: Steve)(employer: Apple))。为了能够实现这个目标,本文提出了结构化schema指导器SSI \text{SSI}SSI,其是一个基于schema的prompt机制,用于控制模型来确定哪些信息需要被定位,哪些信息需要被关联。
上图展示了整个UIE \text{UIE}UIE框架。正式来说,UIE \text{UIE}UIE将SSI(s) \text{SSI(s)}SSI(s)和文本序列(x) \text{(x)}(x)作为输入,并生成一个SEL(y) \text{SEL(y)}SEL(y)
y = UIE ( s ⊕ x ) (1) y=\text{UIE}(s\oplus x)\tag{1}y =UIE (s ⊕x )(1 )
其中,x = [ x 1 , … , x ∣ x ∣ ] x=[x_1,\dots,x_{|x|}]x =[x 1 ,…,x ∣x ∣]是文本序列,s = [ s 1 , … , s ∣ s ∣ ] s=[s_1,\dots,s_{|s|}]s =[s 1 ,…,s ∣s ∣]是结构化schema指导器,且y = [ y 1 , … , y ∣ y ∣ ] y=[y_1,\dots,y_{|y|}]y =[y 1 ,…,y ∣y ∣]是SEL \text{SEL}SEL序列。
2.1 结构化Schema指导器 SSI \text{SSI}SSI
结构化Schema指导器SSI \text{SSI}SSI是由基于schema的prompt构成,并使用其作为生成的前缀。
具体来说,与spotting-association \text{spotting-association}spotting-association结构相对于,SSI \text{SSI}SSI包含三种类型的片段。
(1) SPOTNAME \text{SPOTNAME}SPOTNAME:特定信息抽取任务中的需要被定位信息的名称,例如NER \text{NER}NER任务中的”person”;
(2) ASSONAME \text{ASSONAME}ASSONAME:关联名称,例如关系抽取中的”work for”;
(3) 特殊符号[spot],[asso],[text] \text{[spot],[asso],[text]}[spot],[asso],[text]:这些符号被添加到SPOTNAME \text{SPOTNAME}SPOTNAME、ASSONAME \text{ASSONAME}ASSONAME和输入文本之前;
SSI \text{SSI}SSI中的所有tokens都会被拼接并放在原始序列之前。如上图所示,对于UIE \text{UIE}UIE的整个输入形式为
s ⊕ x = [ s 1 , s 2 , … , s ∣ s ∣ , x 1 , x 2 , … , x ∣ x ∣ ] = [ [spot] , … , [spot] , … , [asso] , … , [asso] , … , [text] , x 1 , x 2 , … , x ∣ x ∣ ] (2) \begin{aligned} s\oplus x=&[s_1,s_2,\dots,s_{|s|},x_1,x_2,\dots,x_{|x|}] \ =&[\textbf{[spot]},\dots,\textbf{[spot]},\dots,\ &\textbf{[asso]},\dots,\textbf{[asso]},\dots,\ &\textbf{[text]},x_1,x_2,\dots,x_{|x|}] \end{aligned}\tag{2}s ⊕x ==[s 1 ,s 2 ,…,s ∣s ∣,x 1 ,x 2 ,…,x ∣x ∣][[spot],…,[spot],…,[asso],…,[asso],…,[text],x 1 ,x 2 ,…,x ∣x ∣](2 )
举例来说,若按照关系模型”the person work for the company”来从句子中抽取信息,那么SSI \text{SSI}SSI就位[spot] person [spot] company [asso] work for [text] \text{[spot] person [spot] company [asso] work for [text]}[spot] person [spot] company [asso] work for [text]。给定一个记为s s s的SSI \text{SSI}SSI,那么UIE \text{UIE}UIE首先会编码输入文本x x x,然后通过编码器-解码器风格的架构,以线性化SEL \text{SEL}SEL的方式来生成目标结构y y y。
基于schema的prompt能够:
(1) 能够高效的指导UIE \text{UIE}UIE进行SEL \text{SEL}SEL生成,因此通用的IE \text{IE}IE能够能够被转移到新的IE \text{IE}IE任务中;
(2) 能够自适应的控制定位哪些信息、关联哪些信息和生成哪些信息,所以不同类型任务和标签的知识可以被更好的共享;
2.2 基于 UIE \text{UIE}UIE 的结构生成
给定SSI \text{SSI}SSI s和文本x作为输入,UIE \text{UIE}UIE通过生成线性化的SEL \text{SEL}SEL来抽取目标信息。本文使用编码器-解码器风格的架构来执行text-to-SEL \text{text-to-SEL}text-to-SEL的过程。给定一个文本序列x x x和schema指导器s s s,UIE \text{UIE}UIE首先会计算每个token的隐藏表示H = [ s 1 , … , s ∣ s ∣ , x 1 , … , x ∣ x ∣ ] \textbf{H}=[s_1,\dots,s_{|s|},x_1,\dots,x_{|x|}]H =[s 1 ,…,s ∣s ∣,x 1 ,…,x ∣x ∣]:
H = Encoder ( s 1 , … , s ∣ s ∣ , x 1 , … , x ∣ x ∣ ) (3) \textbf{H}=\text{Encoder}(s_1,\dots,s_{|s|},x_1,\dots,x_{|x|}) \tag{3}H =Encoder (s 1 ,…,s ∣s ∣,x 1 ,…,x ∣x ∣)(3 )
其中,Encoder ( ⋅ ) \text{Encoder}(\cdot)Encoder (⋅)是一个Transformer编码器。然后,UIE \text{UIE}UIE会以自回归的方式将输入解码为线性化的SEL \text{SEL}SEL。解码的第i i i步,UIE \text{UIE}UIE会生成SEL \text{SEL}SEL序列中的第i i i个token y i y_i y i ,并解码出状态h i d \textbf{h}i^d h i d
y i , h i d = Decoder ( [ H ; h 1 d , … , h i − 1 d ] ) (4) y_i,\textbf{h}_i^d=\text{Decoder}([\textbf{H};\textbf{h}_1^d,\dots,\textbf{h}{i-1}^d]) \tag{4}y i ,h i d =Decoder ([H ;h 1 d ,…,h i −1 d ])(4 )
其中,Decoder ( ⋅ ) \text{Decoder}(\cdot)Decoder (⋅)是一个Transformer解码器,其预测条件概率p ( y i ∣ y < i , x , s ) p(y_i|y_{。最终,当输出为
时Decoder ( ⋅ ) \text{Decoder}(\cdot)Decoder (⋅)就完成了预测。然后,将预测的SEL \text{SEL}SEL转换为需要抽取的信息。
先前的IE \text{IE}IE将标签看作是具体的符号,UIE \text{UIE}UIE则通过text-to-structure \text{text-to-structure}text-to-structure生成范式将标注转换成了自然语言中的token。通过将标签和结构转换为语言,UIE \text{UIE}UIE能够有效的将预训练语言模型BART \text{BART}BART和T5 \text{T5}T5中的知识进行迁移,并且相关的任务能够轻易的共享这些知识。
三、预训练
本小节主要包括:(1) 如何预训练大规模的UIE \text{UIE}UIE模型,其能够为不同的IE \text{IE}IE任务捕获通用的IE \text{IE}IE能力;(2) 如何微调UIE \text{UIE}UIE来适应不同类型的IE \text{IE}IE任务。
具体来说,作者先收集了几个大规模的数据集(包括:结构化的知识库、无结构化的文本以及平行语料);然后,将这些异构的数据集进行统一并预训练UIE \text{UIE}UIE模型;最后,通过请求式的微调来使预训练模型UIE \text{UIE}UIE适应下游的各种IE \text{IE}IE任务。
1. 语料构建
UIE \text{UIE}UIE需要编码文本,映射文本到结构,并解码出有效的结构。因此,作者从网络中收集了大规模的预训练语料:
D p a i r \mathcal{D}{pair}D p a i r 是一个text-structure \text{text-structure}text-structure平行语料,每个实例都是一个平行对,即token序列x x x和结构化记录y y y。作者通过使用英文Wikipedia \text{Wikipedia}Wikipedia与Wikidata \text{Wikidata}Wikidata进行对齐,从而收集了大规模的平行text-structure \text{text-structure}text-structure对。D p a i r \mathcal{D}{pair}D p a i r 被用于预训练UIE \text{UIE}UIE的text-to-structure \text{text-to-structure}text-to-structure迁移能力。
D r e c o r d \mathcal{D}{record}D r e c o r d 是一个结构化的数据集,每个实例都是一个结构化的记录y y y。作者从ConceptNet \text{ConceptNet}ConceptNet和Wikidata \text{Wikidata}Wikidata中收集结构化数据。D r e c o r d \mathcal{D}{record}D r e c o r d 被用来预训练UIE \text{UIE}UIE的结构化解码能力。
D t e x t \mathcal{D}{text}D t e x t 是无结构化文本数据集。作者使用英文Wikipedia \text{Wikipedia}Wikipedia中的所有普通文本。D t e x t \mathcal{D}{text}D t e x t 被用来预训练UIE \text{UIE}UIE的语义编码能力。
2. 预训练
2.1 使用 D p a i r \mathcal{D}_{pair}D p a i r 进行 text-to-structure \text{text-to-structure}text-to-structure 预训练
为了能够使模型捕获基本的text-to-structure \text{text-to-structure}text-to-structure映射能力,这里是以D p a i r = { ( x , y ) } \mathcal{D}{pair}={(x,y)}D p a i r ={(x ,y )}来预训练模型UIE \text{UIE}UIE。具体来说,对于给定的平行样本对( x , y ) (x,y)(x ,y ),抽取需要定位的类型s s + s{s+}s s +和y y y中的关联类型s a + s_{a+}s a +来构成正样本s + = s s + ∪ s a + s_+=s_{s+}\cup s_{a+}s +=s s +∪s a +。然而,仅使用这样的正样本来训练UIE \text{UIE}UIE,模型仅仅会简单的记住预训练数据中的三元组。为了能够学习到通用的映射能力,这里也自动构造了负样本。即采样负的定位类型s s − s_{s-}s s −和负的关联类型集合s a − s_{a-}s a −,然后拼接出最终的数据集s m e t a = s + ∪ s s − ∪ s a − s_{meta}=s_+\cup s_{s-}\cup s_{a-}s m e t a =s +∪s s −∪s a −。
举例来说,”person”和”word”在记录”((person: Steve)(work for: Apple))” \text{“((person: Steve)(work for: Apple))”}”((person: Steve)(work for: Apple))”中是正样本,并且采样”vehicle”和”located in”作为样样本。最后,text-to-structure \text{text-to-structure}text-to-structure预训练目标函数为
L P a i r = ∑ ( x , y ) ∈ D p a i r − log p ( y ∣ x , s m e t a ; θ e , θ d ) (5) \mathcal{L}{Pair}=\sum{(x,y)\in\mathcal{D}{pair}}\;-\text{log}\;p(y|x,s{meta};\theta_e,\theta_d) \tag{5}L P a i r =(x ,y )∈D p a i r ∑−log p (y ∣x ,s m e t a ;θe ,θd )(5 )
其中,θ e \theta_e θe 和θ d \theta_d θd 是编码器和解码器的参数。
2.2 使用 D r e c o r d \mathcal{D}_{record}D r e c o r d 进行结构化生成预训练
为了预训练UIE \text{UIE}UIE对于由SEL \text{SEL}SEL和schema \text{schema}schema定义结构的生成能力,这里使用D r e c o r d \mathcal{D}{record}D r e c o r d 来预训练UIE \text{UIE}UIE。将UIE \text{UIE}UIE的解码器作为一个结构化语言模型,且D r e c o r d \mathcal{D}{record}D r e c o r d 中的每个记录都是一个SEL \text{SEL}SEL表达式,则
L R e c o r d = ∑ y ∈ D r e c o r d − log p ( y i ∣ y < i ; θ d ) (6) \mathcal{L}{Record}=\sum{y\in\mathcal{D}{record}}\;-\text{log}\;p(y_i|y{
通过为结构化生成进行预训练,解码器能够捕获SEL \text{SEL}SEL的规律性和不同标签间的交互。
2.3 使用 D t e x t \mathcal{D}_{text}D t e x t 改进语义表示
在text-to-structure \text{text-to-structure}text-to-structure预训练的过程中,继续在D t e x t \mathcal{D}{text}D t e x t 上使用MLM \text{MLM}MLM来预训练UIE \text{UIE}UIE,从而改进UIE \text{UIE}UIE的语义表示能力。
L T e x t = ∑ x ∈ D t e x t − log p ( x ′ ′ ∣ x ′ ; θ e , θ d ) (7) \mathcal{L}{Text}=\sum_{x\in\mathcal{D}_{text}}\;-\text{log}\;p(x”|x’;\theta_e,\theta_d) \tag{7}L T e x t =x ∈D t e x t ∑−log p (x ′′∣x ′;θe ,θd )(7 )
其中,x ′ x’x ′是被遮蔽部分token的原文本,x ′ ′ x”x ′′是被遮蔽的token片段。这个预训练能够有效的缓解特殊语义符号SPOTNAME \text{SPOTNAME}SPOTNAME和ASSONAME \text{ASSONAME}ASSONAME的语义的灾难性遗忘。
2.4 最终的预训练损失函数
使用T5-v1.1-base \text{T5-v1.1-base}T5-v1.1-base和T5-v1.1-large \text{T5-v1.1-large}T5-v1.1-large来初始化UIE-base \text{UIE-base}UIE-base和UIE-large \text{UIE-large}UIE-large。最终的目标函数合并了上面的所有任务
L = L P a i r + L R e c o r d + L T e x t (8) \mathcal{L}=\mathcal{L}{Pair}+\mathcal{L}{Record}+\mathcal{L}{Text} \tag{8}L =L P a i r +L R e c o r d +L T e x t (8 )
在实现中,将所有的预训练数据都表示为三元组。对于D t e x t \mathcal{D}{text}D t e x t 中的文本数据x x x,构建三元组( None , x ′ , x ′ ′ ) (\text{None},x’,x”)(None ,x ′,x ′′),其中x ′ x’x ′是被遮蔽部分token的原始文本,x ′ ′ x”x ′′是被遮蔽的token片段。对于D p a i r \mathcal{D}{pair}D p a i r 中的text-record \text{text-record}text-record数据( x , y ) (x,y)(x ,y ),通过为每个text-record \text{text-record}text-record采样meta-schema来构造三元组( s , x , y ) (s,x,y)(s ,x ,y )。对于D r e c o r d \mathcal{D}{record}D r e c o r d 中的记录数据y y y,采用( None,None , y ) (\text{None,None},y)(None,None ,y )作为输入三元组。
3. 按需微调

给定一个预训练好的UIE \text{UIE}UIE模型,通过模型微调能够快速调整模型来适应不同的IE \text{IE}IE任务和设置。给定一个标注好的语料D t a s k = ( s , x , y ) \mathcal{D}{task}={(s,x,y)}D t a s k =(s ,x ,y ),使用交叉熵损失函数来微调UIE \text{UIE}UIE
L F T = ∑ ( s , x , y ) ∈ D T a s k − log p ( y ∣ x , s ; θ e , θ d ) (9) \mathcal{L}{FT}=\sum_{(s,x,y)\in\mathcal{D}{Task}}\;-\text{log}\;p(y|x,s;\theta_e,\theta_d) \tag{9}L F T =(s ,x ,y )∈D T a s k ∑−log p (y ∣x ,s ;θe ,θd )(9 )
为了缓解自回归模型在解码过程中的曝光偏差,设计了一种Rejection \textbf{Rejection}Rejection机制来进行更加有效的微调。具体来说,给定一个实例( s , x , y ) (s,x,y)(s ,x ,y ),先使用SEL \text{SEL}SEL来编码y y y,然后以概率p ϵ p{\epsilon}p ϵ随机的向SPOTNAME \text{SPOTNAME}SPOTNAME和ASSONAME \text{ASSONAME}ASSONAME中插入[ NULL ] [\text{NULL}][NULL ],来构造负样本( SPOTNAME,[NULL] ) (\text{SPOTNAME,[NULL]})(SPOTNAME,[NULL])和( ASSONAME,[NULL] ) (\text{ASSONAME,[NULL]})(ASSONAME,[NULL])。举例来说,上表中f a c i l i t y facility f a c i l i t y在prompt中是负spot,也就是在矩阵”Steve became CEO of Apple in 1997″中并没有f a c i l i t y facility f a c i l i t y实体。因此,随机将噪音”(facility:[NULL])” \text{“(facility:[NULL])”}”(facility:[NULL])”加入至record中。通过这种方式,UIE \text{UIE}UIE能够通过生成[NULL] \text{[NULL]}[NULL]来学习拒绝错误的生成。
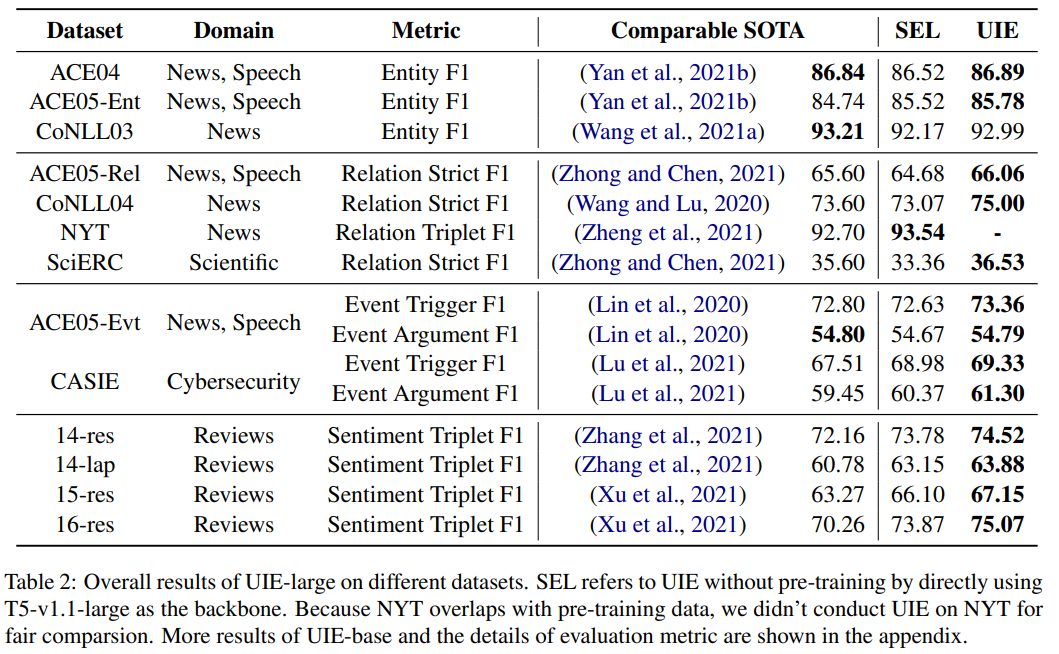
; 四、实验
五、总结
- 通过生成模型统一不同的信息提取任务
[En]
unify different information extraction tasks by generating models*
- 为不同任务设计了统一的抽取语言
[En]
designed a unified extraction language for different tasks*
- 通过prompt来控制模型的生成行为;
- 展示了对此模型进行预培训的方法
[En]
shows a way to pre-train this model*
Original: https://blog.csdn.net/bqw18744018044/article/details/124325208
Author: BQW_
Title: 【自然语言处理】【信息抽取】UIE:用于通用信息抽取的统一结构生成
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527655/
转载文章受原作者版权保护。转载请注明原作者出处!