
1. 文本预处理概述
与机器学习任务一样,自然语言处理任务的第一步是文本(数据)准备或文本(数据)预处理。文本预处理流程如下图所示:
[En]
Like machine learning tasks, the first step of natural language processing tasks is text (data) preparation or text (data) preprocessing. The process of text preprocessing is shown in the following figure:
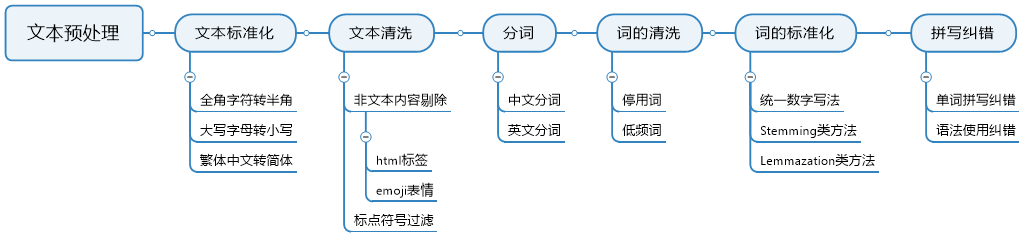

文本预处理受分词步骤的限制。以前的文本标准化和文本清洗是语料级(章节级)粒度的文本处理,而词清洗、标准化和文本表示是词级的粒度文本处理。
[En]
Text preprocessing is bounded by word segmentation steps. The previous text standardization and text cleaning are corpus-level (chapter-level) granularity text processing, and then word cleaning, standardization and text representation are word-level granularity text processing.
语料级文本处理的作用对象是数据集中的每一篇语料,它比单词级文本处理效率更高,并且可以提前去除影响分词效果的障碍(如:英文中按空格分词,但与单词直接相邻的逗号等标点会产生非标准单词的分词结果(’word,’ 标准形式应该是’word’))。
词级文本处理是在对语料库进行切分之后进行的,其处理对象是每个语料库中的每个单词。它主要进行四个主要步骤:词语过滤、词语书写标准化(如大写数字和阿拉伯数字的统一、英语单词不同时态的统一、语音书写形式的统一等)、拼写纠错和文本表示。
[En]
Word-level text processing is performed after the corpus is segmented, and its processing object is every word in each corpus. It mainly carries out four major steps: word filtering, standardization of word writing (such as the unification of capital numbers and Arabic numerals, the unification of different tenses of English words, the unity of voice writing forms, etc.), spelling error correction and text representation.
; 2. 文本标准化
2.1 字符编码标准化(全角英文字符转半角)
在计算机中,所有中文字符都是全角字符,而英文字母、阿拉伯数字及符号有全角和半角两种unicode编码方式。它们的全角字符unicode编码从65281~65374 (十六进制 0xFF01 ~ 0xFF5E),半角字符unicode编码从33~126 (十六进制 0x21~ 0x7E);而空格符比较特殊,全角unicode编码为12288 (0x3000),半角为32 (0x20)。
可见 除空格符外,每个全角字符的unicode编码等于其半角字符的unicode编码加65248,因此字符unicode编码标准化实现代码如下:
def full_to_half(text:str):
_text = ""
for char in text:
inside_code = ord(char)
if inside_code == 12288:
inside_code = 32
elif 65281 inside_code 65374:
inside_code -= 65248
_text += chr(inside_code)
return _text
2.2 英文大小写字母统一化
英文字母大小写的统一化可直接借助python内置字符串方法实现,具体代码如下:
def upper2lower(text:str):
return text.lower()
2.3 中文繁简字统一化
中文繁体字与简体字的统一化借助opencc包的OpenCC类实现,该类通过不同的转换功能代码实现不同的文字转化功能,转换功能代码表如下所示:
转换代码功能说明t2s繁体中文转简体s2t简体中文转繁体s2twp简体中文转繁体中文(带短语)t2hk繁体中文转繁体(香港标准)hk2s繁体中文(香港标准)转简体中文s2hk简体中文转繁体中文(香港标准)t2tw繁体中文转繁体(台湾标准)tw2s繁体中文(台湾标准)转简体中文tw2sp繁体中文(台湾标准)转简体中文(带短语)s2tw简体中文转换成繁体中文(台湾标准)
繁体和简体中文统一代码如下:
[En]
The code for the unification of complex and simplified Chinese is as follows:
from opencc import OpenCC
def chinese_standard(text:str, conversion='t2s'):
cc = OpenCC(conversion)
return cc.convert(text)
3. 文本清洗
文本清洗中,常通过Unicode码过滤来去除非文本内容。Unicode码表中,中日韩统一表意文字字符区间为 4E00~9FA5,半角英文字母、阿拉伯数字及符号的字符区间为 0x21~0x7E,所以标准文本字符范围为 [ 4E00 , 9FA5 ] ∪ [ 0x21 , 0x7E ] [\text{4E00}, \text{9FA5}] \cup[\text{0x21}, \text{0x7E}][4E00 ,9FA5 ]∪[0x21 ,0x7E ]。
非文本内容过滤和标点符号过滤使用正则表达式实现,如下所示:
[En]
Non-text content filtering and punctuation filtering are implemented with regular expressions, as follows:
import re
def clear_character(text):
pattern = [
"[^\u4e00-\u9fa5^a-z^A-Z^0-9^\u0020^\u0027^\u002e]",
"\.$"
]
return re.sub('|'.join(pattern), '', text)
4. 分词
敬请详见作者文章: 文本表示:分词.
5. 词的清洗
敬请详见作者文章: 文本表示:词的清洗.
6. 词的标准化
敬请详见作者文章: 文本表示:词的标准化.
7. 拼写纠错
敬请详见作者文章: 文本预处理:拼写纠错.
Original: https://blog.csdn.net/xunyishuai5020/article/details/122511940
Author: HadesZ~
Title: 自然语言处理(NLP)之一:文本预处理(文本准备)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527555/
转载文章受原作者版权保护。转载请注明原作者出处!