

入门新秀,希望做笔记记录自己学到的东西,也希望能帮助同样入门级的人,也希望老板能帮忙改正错误~侵权删除。
[En]
Entry rookie, hope to take notes to record what they have learned, but also hope to help the same entry-level people, but also hope that the bosses can help correct mistakes ~ infringement deletion.
目录
一、SVM定义与解决目标
SVM是一个二类分类器。其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化成一个凸二次规划问题的求解。即找到一个超平面,使两类数据离超平面越远越好,这样就可以让模型对新的数据分类更准确,即分类器更加稳定。
🎈支持向量:距离分离超平面最近的一些点
[En]
🎈 support vector: some points closest to the separated hyperplane
🎈区间最大化:求取最大支持向量到分离超平面的距离,并以此为目标寻找分离超平面
[En]
🎈 interval maximization: find the distance from the maximized support vector to the separated hyperplane, and take this as the goal to find the separated hyperplane
🎈数据分类的类别
(1)线性可分
(2)线性不可分
二、SVM算法原理
1、线性可分
分为2种:无松弛变量和带松弛变量
以2个特征为例:
如下图所示:如何对黑点和红点进行分类,我们可以直观地看到粉色线是最好的分界线(因为超平面对训练样本的局部干扰具有最好的容忍度,也就是稳定性更高)。
[En]
As shown in the following figure: how to classify black dots and red dots, we can intuitively see that the pink line is the best dividing line (because the hyperplane has the best tolerance to the local disturbance of the training sample, that is, higher stability).
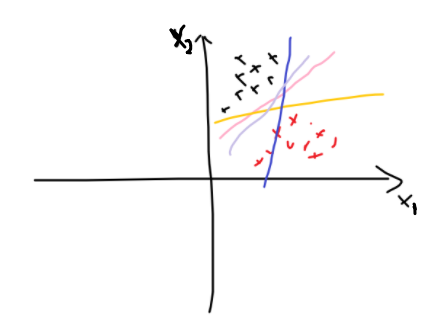

🌳原始待分类的数据:(x11,x12,y1),……,(xm1,xm2,ym)
x1,x2就是不同维的特征
y的取值为1或-1(因为2分类)
🌳目标超平面:
—— 求最优w和b
(这里其实展开就是
w是法向量,决定了超平面的方向;
b是位移项,决定了超平面与原点间的距离)
🌳那么空间中任意一点(x1,x2)到目标超平面的距离则为:
🌳又有定义:(其中
和分别是第i个样本和第i个样本值所对应的目标值)
为函数距离;
所以我们综合函数之间的距离和点到面的距离,它就变成:
[En]
So we synthesize the distance between the function and the distance from the point to the face, and it becomes:
为数据集与分隔超平面的几何距离;
(1)这里用几何距离而不用函数距离的原因:
当w,b成倍增加时,函数距离也会相应的成倍的增加,但几何函数则不会
(2)我们刚刚不是说y的取值是1或-1嘛,这就保证了如果样本分类正确,则这个值是一个正数;如果样本分类错误,这个值是一个负数。这很好理解,分类对了就是同一边,就是正数嘛,即公式如下:
🌳但如果只以
来划分,那么它的容错性可能不是很好,所以SVM这里引入了这个:
如图所示:(我不用费心在图中的转置符号上写字。(嘻嘻)
[En]
As shown in the picture: (I don’t bother to write on the transpose symbol in the picture. Hee hee)
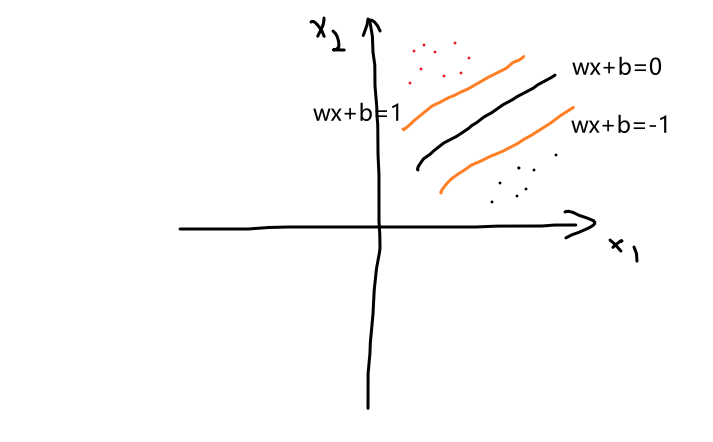
🌳间隔
其中,支持向量使上述方程的等号成立。从两个异类支持向量到超平面的距离之和,也称为区间:
[En]
Among them, the support vector makes the equal sign of the above equation hold. The sum of the distances from two heterogeneous support vectors to the hyperplane, also known as interval :
(其实就是那两条橙色的线的距离)
🌳最大间隔划分超平面
所以我们要找到对应的w和b让
最大,即以下公式:
条件由以下所得:
(1)无松弛变量
🌳由上式进行变式
为了最大化间隔,仅需最大化
,这等价于最小化
这就是SVM的基本型
🌳的基础上,将约束条件集成到优化目标函数中,建立了拉格朗日公式。
[En]
🌳, we integrate the constraints into the optimization objective function and establish the Lagrange formula.
令 L(w,b,α)对 w和b的偏导为零,得到:
代入L得
解出
后代入得:
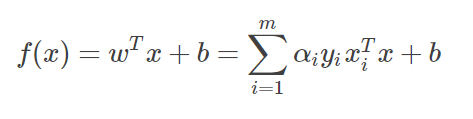
(2)带松弛变量 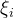 和惩罚因子C
和惩罚因子C
当C趋近于无穷大时,基本等价于无松弛变量的时候,当C取有限值的时允许一些样本不满足约束。
其余与上述一样
2、线性不可分
如果训练样本是线性不可分的,那么只要样本的属性是有限的,就可以将它们映射到高维特征空间,使这些样本线性可分。
[En]
If the training samples are linearly inseparable, then as long as the attributes of the samples are limited, they can be mapped to the high-dimensional feature space to make these samples linearly separable.
Note:升维后不一定线性可分,不过一般情况下升维后会更接近线性可分
每当遇到线性密不可分的情况时,就会映射到高维空间,维度就会爆炸,所以计算会很困难。此时,我们可以使用核函数来简化计算。虽然核函数也将特征从低维转化为高维,但它是在低维计算的,实际效果在高维表现出来,解决了维度爆炸的问题。
[En]
Whenever the linear inseparable situation is encountered, it will be mapped to the high-dimensional space, and the dimension will explode, so the calculation will be very difficult. At this time, we can use the kernel function to simplify the calculation. Although the kernel function also transforms the features from low-dimensional to high-dimensional, it is calculated in low-dimensional, and the actual effect is shown in high-dimensional to solve the problem of dimensional explosion.
(1)核函数定义和应用背景
只要对称函数对应的核矩阵是半正定的,它就可以用作核函数。
[En]
As long as the kernel matrix corresponding to a symmetric function is positive semidefinite, it can be used as a kernel function.
但是在不知道特征映射的形式时,我们并不知道什么样的核函数才是合适的。因此,核函数的选择成为SVM的最大变数 。
要构造核函数,首先必须确定从输入空间到特征空间的映射。为了获得从输入空间到映射空间的映射,我们需要知道数据在输入空间中的分布,但在大多数情况下,我们不知道所处理数据的具体分布,所以通常很难构造一个完全符合输入空间的核函数,所以我们使用了几个常用的核函数来代替构造核函数。
[En]
To construct the kernel function, we must first determine the mapping from the input space to the feature space. In order to obtain the mapping from the input space to the mapping space, we need to know the distribution of the data in the input space, but in most cases, we do not know the specific distribution of the data we are dealing with, so it is generally difficult to construct a kernel function that fully conforms to the input space, so we use several commonly used kernel functions instead of constructing kernel functions.
(2)线性核函数 LINEAR
(内积)
LINEAR主要用于线性可分的情况。我们可以看到特征空间到输入空间的维度是一样的,其参数少,速度快。对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的。
(3)高斯径向基核函数 RBF
它是一种具有强局部性的核函数,它可以将样本映射到高维空间,是应用最广泛的一种,无论是大样本还是小样本都有更好的性能,而且它的参数比多项式核函数少,所以在大多数情况下,当你不知道使用什么核函数时,高斯核函数是首选的。
[En]
It is a kind of kernel function with strong locality, it can map a sample to a higher dimensional space, it is the most widely used one, no matter the large sample or the small sample has better performance, and it has fewer parameters than the polynomial kernel function, so in most cases, when you don’t know what kernel function to use, the Gaussian kernel function is preferred.
(4)多项式核函数 POLY
它还可以将低维输入空间映射到高维特征空间。然而,多项式核函数的参数很多。当多项式的阶数较高时,核矩阵的元素值会趋于无穷或无穷小,计算复杂度会很大,无法计算。
[En]
It can also map the low-dimensional input space to the high-dimensional feature space. However, the polynomial kernel function has many parameters. When the order of the polynomial is relatively high, the element value of the kernel matrix will tend to infinity or infinitesimal, and the computational complexity will be so large that it is impossible to calculate.
(5)神经元的非线性作用核函数 Sigmoid
关于Sigmoid函数的介绍可以看往期文章中
基于分层softmax的CBoW模型详解_tt丫的博客-CSDN博客_分层softmax中有关逻辑回归Sigmoid函数的讲解
这样SVM实现的就是一种多层神经网络
(6)核函数选择技巧
如果我们对数据的分布有了初步的了解,我们就会根据这些特征来选择核函数。
[En]
If we have a preliminary understanding of the distribution of the data, we will choose the kernel function according to these characteristics.
如果不清楚,可以使用交叉验证的方法来尝试不同的核函数,误差最小的核函数是效果最好的,也可以将多个核函数组合成一个混合核函数。
[En]
If we are not clear, we can use the method of cross-validation to try different kernel functions, and the kernel function with the smallest error is the one with the best effect, or we can combine multiple kernel functions to form a mixed kernel function.
如果特征的数量大到和样本数量差不多,则选用线性核SVM;
如果特征的数量小,样本的数量正常,则选用高斯核函数SVM;
如果特征数量少,样本数量大,则需要手动添加一些特征才能成为第一种情况。
[En]
If the number of features is small and the number of samples is large, some features need to be added manually to become the first case.
三、SVM代码实现
我们可以调用sklearn库中的SVM
比如说
model=sklearn.svm.SVC(C=2,kernel='rbf',gamma=10,decision_function_shape='ovo')
参数说明:
(1)C:C-SVC的惩罚参数C默认是1.0。C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,这样对训练集测试时准确率很高,但相对的,模型的泛化能力就会变弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
(2)kernel :核函数,默认是rbf,可以是
0 —— ‘linear’;1 —— ‘poly’;2 —— ‘rbf’;3 —— ‘sigmoid’
(3)degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略
(4)gamma :’rbf’,’poly’和’sigmoid’的核系数。当前默认值为’auto’,它使用1 / n_features,如果gamma=’scale’传递,则使用1 /(n_features * X.std())作为gamma的值。
(5)coef0 :核函数的常数项。对于’poly’和 ‘sigmoid’有用
(6) tol :默认为1e-3,停止训练的误差值大小
主要调节的参数有:C、kernel、degree、gamma、coef0
欢迎您在评论区提出批评和更正。谢谢。
[En]
You are welcome to criticize and correct in the comment area. Thank you.
Original: https://blog.csdn.net/weixin_55073640/article/details/123726799
Author: tt丫
Title: SVM模型详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527527/
转载文章受原作者版权保护。转载请注明原作者出处!