

前言
知识图谱与自然语言处理可以说是紧密结合,两者相辅相成。从一开始的Google搜索,到现在的机器人聊天、大数据风控、证券投资、智能医疗、推荐系统等应用,无一不与知识图谱息息相关。
依赖机器学习和深度学习算法的模型试图从相关性和概率的角度,通过数据统计来描述世界背后的“真相”,但距离真正的“人工智能”仍有一段距离。《知识图谱》更像是能像人类一样分析推理的机器智能。
[En]
Models that rely on machine learning and deep learning algorithms try to describe the “truth” behind the world through data statistics from the point of view of relevance and probability, but it is still a long way from the real “artificial intelligence”. The “knowledge graph ” is more like machine intelligence that can analyze and reason like human beings.
本文以通俗易懂的方式解释了知识图的相关知识,并通过金融风险控制案例详细描述了如何从头开始构建知识图。以及在这一过程中要经历的步骤和在每个阶段要考虑的问题。
[En]
This article explains the knowledge related to the knowledge graph in an easy-to-understand way, and describes in detail how to build the knowledge graph from scratch through the financial risk control case . As well as the steps to be experienced in the process and the problems to be considered at each stage.*

一、知识图谱概论
1.引言
知识图谱(Knowledge Graph)是由 Google 公司在 2012 年提出来的一个新的名词,也叫语义网络。从学术的角度,可以给知识图谱这样的定义:” 知识图谱本质上是语义网络的知识库“。但这有点抽象,换个角度来说,从实际应用的角度出发其实可以简单地把知识图谱理解成 多关系图。
所以说知识图谱,本质上 ,是一种 揭示实体之间关系的语义网络。
为了更好地理解知识图谱,我们必须首先理解信息和知识的区别。
[En]
In order to better understand the knowledge graph, we must first understand the difference between information and knowledge.
- 信息是指外部的客观事实。举例:这里有一瓶水,它现在是10°。
- 知识是对外部客观规律的归纳和总结。举例:水在零度的时候会结冰。
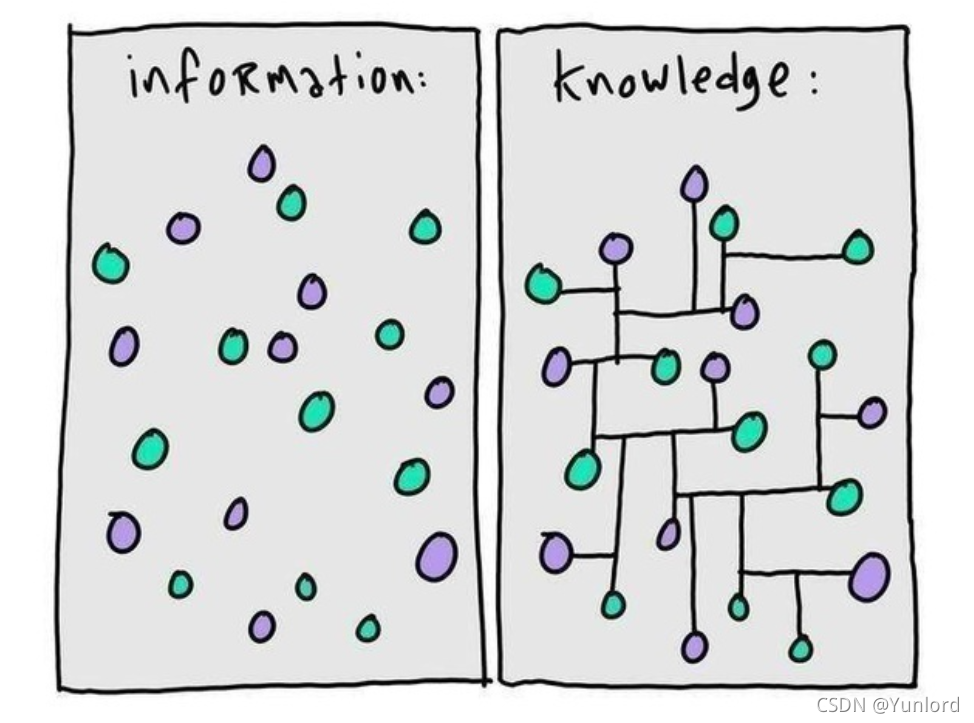
简单的说,就是如上图所示,信息是一个个独立的孤点,而知识就是在信息的基础上形成连接。总的来说,知识图谱就是由一条条知识组成,建立实体之间的联系,每条知识表示为一个SPO(Subject-Predicate-Object)三元组。

然后从不同的角度理解知识图谱的概念。
[En]
Then understand the concept of knowledge graph from different perspectives.
- 在 Web视角下,知识图谱如同简单文本之间的超链接一样, 通过建立数据之间的语义链接,支持语义搜索。
- 在 自然语言处理视角下,知识图谱就是 从文本中抽取语义和结构化的数据。
- 在 知识表示视角下,知识图谱是 采用计算机符号表示和处理知识的方法。
- 在 人工智能视角下,知识图谱是 利用知识库来辅助理解人类语言的工具。
- 在 数据库视角下,知识图谱是 利用图的方式去存储知识的方法。
知识图谱技术已经成为AI领域重要的分支,虽然起步晚,但经过过去几年的快速发展,已经成为各行各业中比较核心的工具之一。只要数据之间有互联,而且有这方面的分析需求,知识图谱就可以成为有效工具。
而现在很多数据是相互关联的,如果你想要分析这些链接的价值,知识图可以是一个有效的工具。随着万物互联时代的到来,链接中包含的信息必然会发挥更大的价值,这也是近年来知识图谱发展如此迅速的主要原因。
[En]
And now a lot of data are connected to each other, if you want to analyze the value of these links, knowledge graph can be an effective tool. With the advent of the era of the Internet of everything, the information contained in the link is bound to play a greater value, which is the main reason why the knowledge graph has developed so rapidly in recent years.
2.什么是知识图谱
目前,学术界对知识图的定义还没有统一的定义。谷歌发布的文件中明确描述,知识图是一种用图模型来描述知识之间关系的技术方法,对世界上的一切事物进行建模。
[En]
At present, there is no unified definition of knowledge graph in academic circles. It is clearly described in the documents released by Google that knowledge graph is a technical method of using graph model to describe the relationship between knowledge and modeling everything in the world.
具体来说,知识图是一种通用的语义知识形式化描述框架,它用节点来表示语义符号,用边来表示语义之间的关系。
[En]
Specifically, knowledge graph is a general formal description framework of semantic knowledge, which uses nodes to represent semantic symbols and edges to represent the relationship between semantics.
在知识图谱里,我们通常用”实体”来表达图里的节点,用”关系”来表达图里的”边”。 实体指的是现实世界中的事物,比如人、地名、概念、药物、公司等, 关系则用来表达不同实体之间的某种联系,比如人”居住在”深圳、李明是王海的”老板”、张朵的”手机号码”是138X…。
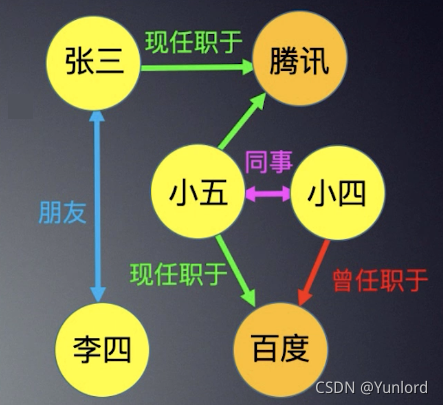
现实世界中的许多场景非常适合用知识图来表示。例如,在社交网络图中,我们可以同时拥有“人”和“公司”实体。人与人之间的关系可以是“朋友”,也可以是“同事”。一个人和一个公司之间的关系可以是“现在”或“以前”的关系。同样,风险控制知识图可以包括电话和公司实体,并且电话和电话之间的关系可以是呼叫关系。
[En]
Many scenes in the real world are very suitable to be expressed by knowledge graph. For example, in a social network graph, we can have both “human” and “corporate” entities. The relationship between people can be either “friend” or “colleague”. The relationship between a person and a company can be a “current” or “former” relationship. Similarly, a risk control knowledge graph can include “phone” and “company” entities, and the relationship between phone and phone can be “call” relationship.
3.知识图谱的表示
接下来,详细解释了构成知识图的三个元素:实体、关系和属性。
[En]
Next, it explains in detail the three elements that make up the knowledge graph, including: * entity * , * relationship * and * attribute * .
- 实体:又叫作本体,指客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念或联系。实体是知识图谱中最基本的元素。
- 关系:在知识图谱中,边表示知识图谱中的关系,用来表示不同实体间的某种联系。
- 属性:知识图谱中的实体和关系都可以有各自的属性。
在现实世界中,实体和关系也会拥有各自的属性,比如人可以有”姓名”和”年龄”。 当一个知识图谱拥有属性时,我们可以用属性图(Property Graph)来表示。

上图是一个简单的属性图。
[En]
The image above is a simple attribute diagram.
- 李明是李飞的父亲
- 李明今年25岁,职位是总经理
- 李明和张三是朋友关系
- 李明拥有一个138开头的电话号码
- 电话号开通时间是2018年
这种属性图的表达很贴近现实生活中的场景,也可以很好地描述业务中所包含的逻辑。除了属性图,知识图谱也可以用RDF来表示,它是由很多的三元组(Triples)来组成。RDF在设计上的主要特点是易于发布和分享数据,但不支持实体或关系拥有属性,如果非要加上属性,则在设计上需要做一些修改。目前来看,RDF主要还是用于学术的场景,在工业界我们更多的还是采用图数据库(比如用来存储属性图)的方式。
知识图谱应用的前提是已经构建好了知识图谱,也可以把它认为成一个知识库。这也是为什么它可以用来回答一些搜索相关问题的原因,比如在百度搜索引擎里输入” 周杰伦妻子是谁“,我们直接可以得到答案” 昆凌“。这是因为我们在系统层面上已经创建好了一个包含”周杰伦”和”昆凌”的实体以及他俩之间关系的知识库。所以,当我们执行搜索的时候,就可以通过关键词提取(”周杰伦”, “昆凌”, “妻子”)以及知识库上的匹配可以直接获得最终的答案。这种搜索方式跟传统的搜索引擎是不一样的。后者返回的是网页,而不是最终的答案,多了一层用户自己筛选并过滤信息的过程。

二、知识图谱构建与技术
1.知识图谱的构建
知识图的体系结构主要包括其自身的逻辑结构和体系结构。
[En]
*The architecture of knowledge graph mainly includes its own logical structure and architecture. *
知识图谱在 逻辑结构上可分为 模式层与 数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的 Neo4j、Twitter 的 FlockDB、JanusGraph 等。模式层构建在数据层之上, 主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
知识图谱的 体系架构是指其构建模式的结构,如下图所示:

知识图的构建是后续应用的基础,而构建的前提是从不同的数据源提取数据。对于垂直知识图,他们的数据来源主要来自两个渠道:一个是业务本身的数据,通常包含在公司的数据库表中,以结构化的方式存储;另一个是网络上公开爬取的数据,通常是以网页形式存储的非结构化数据。
[En]
The construction of knowledge graph is the basis of subsequent application, and the premise of construction is to extract data from different data sources. For vertical knowledge graphs, * their data sources mainly come from two channels: one is the data of the business itself, which is usually contained in the company’s database tables and stored in a structured way; the other is the publicly crawled data on the network, which is usually unstructured data stored in the form of web pages. *

前者一般只需要简单预处理即可以作为后续AI系统的输入,但后者一般需要借助于自然语言处理等技术来提取出结构化信息。比如在上面的搜索例子里,周杰伦和昆凌的关系就可以从非结构化数据中提炼出来,比如百度百科等数据源。
信息抽取的难点是处理非结构化数据。在构建相似地图的过程中,自然语言处理技术主要涉及以下几个方面:
[En]
The difficulty of information extraction is to deal with unstructured data. In the process of constructing similar maps, natural language processing techniques are mainly involved in the following aspects:
- 实体命名识别(Name Entity Recognition)
- 关系抽取(Relation Extraction)
- 实体统一(Entity Resolution)
- 指代消解(Coreference Resolution)
2.知识图谱技术
大规模知识库的建设和应用需要多种自然语言处理技术的支持。通过知识抽取技术,可以从一些开放的半结构化和非结构化数据中提取实体、关系和属性等知识元素。通过知识融合,可以消除实体、关系、属性和事实对象等参照项之间的歧义,形成高质量的知识库。知识推理是在现有知识库的基础上进一步挖掘隐藏的知识,从而丰富和扩充知识库。分布式知识表示形成的综合向量对知识库的构建、推理、融合和应用具有重要意义。
[En]
The construction and application of large-scale knowledge base needs the support of a variety of natural language processing technologies. Through the technology of * knowledge extraction * , knowledge elements such as entities, relationships and attributes can be extracted from some open semi-structured and unstructured data. Through * knowledge fusion * , the ambiguity between the referential items such as entities, relations, attributes and factual objects can be eliminated, and a high-quality knowledge base can be formed. * knowledge reasoning * is to further mine the hidden knowledge on the basis of the existing knowledge base, so as to enrich and expand the knowledge base. The comprehensive vector formed by distributed knowledge representation is of great significance to the construction, reasoning, fusion and application of knowledge base.
知识抽取:
知识抽取主要面向开放的关联数据,利用自动化技术抽取可用的知识单元。知识单元主要包括三个知识元素:实体(概念的外延)、关系和属性。并在此基础上形成了一系列高质量的事实表述,为上层模式层的建设奠定了基础。知识抽取有三个主要任务:
[En]
Knowledge extraction is mainly oriented to open linked data, and the available knowledge units are extracted by automatic technology. The knowledge unit mainly includes three knowledge elements: * entity (extension of concept) * , * relation * and * attribute * . And on this basis, a series of high-quality fact expressions are formed, which lays the foundation for the construction of the upper pattern layer. There are three main tasks of knowledge extraction:
- 实体提取:也称为命名实体识别,指的是从原始语料库中自动识别命名实体。由于实体是知识图中最基本的元素,实体抽取的完整性、准确性和召回率将直接影响知识库的质量。因此,实体抽取是知识抽取中最基本、最关键的步骤。
[En]
entity extraction: also known as named entity recognition, which refers to the automatic recognition of named entities from the original corpus. Because entity is the most basic element in the knowledge graph, the integrity, accuracy and recall rate of its extraction will directly affect the quality of the knowledge base. Therefore, entity extraction is the most basic and critical step in knowledge extraction.*
- 关系抽取:目标是解决实体之间的语义链接问题。早期的关系提取主要是通过人工构建语义规则和模板来识别实体关系。随后,实体间的关系模型逐渐取代了人工预定义的语法和规则。
[En]
relationship extraction: the goal is to solve the problem of semantic links between entities. The early relationship extraction is mainly through manual construction of semantic rules and templates to identify entity relations. Subsequently, the relationship model between entities gradually replaced the artificial predefined syntax and rules.*
- 属性提取:属性提取主要针对实体,通过属性可以形成实体的完整轮廓。由于实体的属性可以看作实体与属性值之间的名称关系,因此实体属性提取问题可以转化为关系提取问题。
[En]
attribute extraction: attribute extraction is mainly for entities, and a complete outline of entities can be formed through attributes. Because the attribute of an entity can be regarded as a name relationship between the entity and the attribute value, the problem of entity attribute extraction can be transformed into a relation extraction problem.*
知识表示:
近年来,以深度学习为代表的表征学习技术取得了重要进展,它可以将实体的语义信息表示为密集的低维实值向量,然后在低维空间中高效地计算实体、关系及其复杂的语义关联,对于知识库的构建、推理、融合和应用具有重要意义。
[En]
In recent years, the representation learning technology represented by deep learning has made important progress, which can express the semantic information of entities as dense low-dimensional real-valued vectors, and then efficiently calculate entities, relationships and their complex semantic associations in low-dimensional space, which is of great significance for the construction, reasoning, fusion and application of knowledge base.
知识融合:
由于知识图谱中的知识源广泛,存在着知识质量不同、来自不同数据源的知识重复、知识关联不够清晰等问题,因此有必要进行知识融合。知识融合是一种高层次的知识组织,它使来自不同知识源的知识能够在同一框架下进行异质数据集成、歧义消解、处理、推理验证、更新等步骤。实现数据、信息、方法、经验和人的思想的融合,形成高质量的知识库。
[En]
Because there are a wide range of knowledge sources in the knowledge graph, there are some problems, such as the quality of knowledge is different, knowledge repetition from different data sources, knowledge association is not clear enough, so it is necessary to carry out knowledge fusion. Knowledge fusion is a high-level knowledge organization, which enables knowledge from different knowledge sources to carry out heterogeneous data integration, disambiguation, processing, reasoning verification, updating and other steps under the same framework. To achieve the integration of data, information, methods, experience and human ideas, to form a high-quality knowledge base.
其中,知识更新是其中重要的一环。人类的认知能力、知识储备和业务需求都会随着时间的推移而增加。因此,知识图谱的内容也需要与时俱进。无论是一般知识图谱还是行业知识图谱,都需要不断迭代更新,拓展现有知识,增添新知识。
[En]
Among them, knowledge updating is an important part. Human cognitive ability, knowledge reserve and business needs will all increase over time. Therefore, the content of knowledge graph also needs to keep pace with the times. * whether it is general knowledge graph or industry knowledge graph, they all need to be iterated and updated constantly to expand existing knowledge and add new knowledge.*
第三,知识图谱的构建过程和设计。
[En]
Third, the construction process and design of knowledge graph.
首先,我们还是要设定一个具体的问题,让整个设计有明确的目的。在这一章中,我们主要以金融风险控制为例来描述知识图谱的构建过程。
[En]
First of all, we still have to set a specific problem, so that the whole design has a clear purpose. In this chapter, we mainly take * financial risk control * as an example to describe the construction process of knowledge graph.
构建一个完整的知识图谱包括以下步骤:
[En]
The construction of a complete knowledge graph includes the following steps:
- 定义具体的业务问题
- 数据的收集
- 预处理
- 知识图谱设计
- 存储知识图谱
- 应用知识图谱
- 系统评估
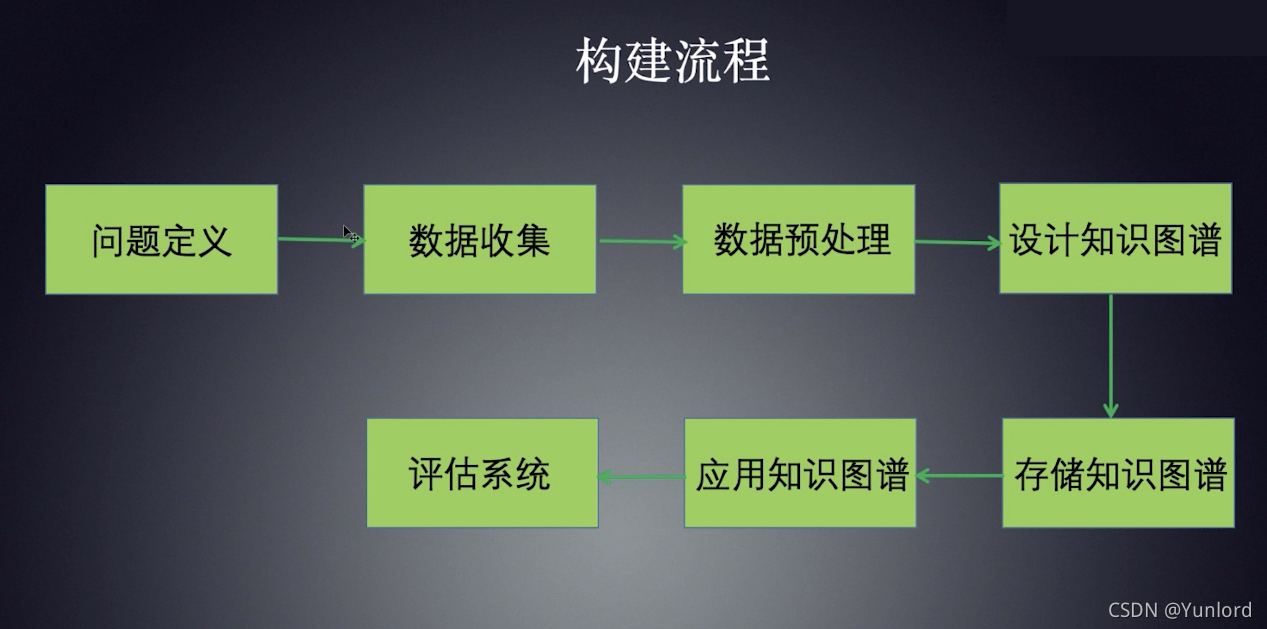
让我们按照这个过程来讨论一下每一步需要做什么和需要考虑什么。
[En]
Let’s follow this process to talk about what needs to be done and what needs to be thought about in each step.
1.定义具体的业务问题
金融归根揭底要解决的是风控的问题,包括个人贷款、风险定价、保险、证券投资。在P2P网贷环境下,最核心的问题是风控,也就是怎么去评估一个借款人的风险。在线上的环境下,欺诈风险尤其为严重,并且很多这种风险隐藏在复杂的关系网络之中,而知识图谱正好是为这类问题所设计的。
在这个过程中,最核心的其实就是地图的设计,因为地图一旦设计好,就会成为我们后续的“大脑”,设计的好坏将直接影响到未来的应用。这类似于建数据库表,一旦设计不合理,就会出现很多问题。在很大程度上,知识图谱的设计取决于对业务的理解和对未来业务的展望。
[En]
In this process, the core is actually the design of the map, because once the map is designed, it will become our follow-up “brain”, good or bad design will directly affect the future application. This is similar to building database tables, once the design is not reasonable, there will be a lot of problems. To a large extent, designing a knowledge graph depends on the understanding of the business and the prospect of the future business.
目前,需要解决的问题是如何通过技术手段来确定一个人的申请人的欺诈风险。
[En]
At present, the problem to be solved is how to determine the fraud risk of a person’s applicant by technical means.
如何判断一个人欺诈风险,传统方法可以根据 个人特征:年龄、单位、工资,但是仅仅关注一个点,而现在通过知识图谱,可以根据关系特征:周围朋友、电话号码等等,比如,朋友是否有失信记录或者不同人用相同手机号码登记,这就把我们查询的范围从一个点扩大到一个面。
什么时候需要知识图谱?在进入下一个话题的讨论之前, 要明确的一点是,对于自身的业务问题到底需不需要知识图谱系统的支持。因为在很多的实际场景,即使对关系的分析有一定的需求,实际上也可以利用传统数据库来完成分析的。所以为了避免使用知识图谱而选择知识图谱,以下给出了几点总结。
- 有没有强烈 可视化需求
- 有没有设计 深度搜素的场景
- 对查询效率有无 实时性要求
- 数据多样化、解决数据孤岛问题
- 你是否有能力和成本构建知识图谱系统
[En]
whether you have the ability and cost to build a knowledge graph system*
- 是否有一定的 知识推理需求
2.数据收集和预处理
下一步是识别数据源并进行必要的数据预处理。对于数据源,我们需要考虑以下几点:
[En]
The next step is to identify the data source and do the necessary data preprocessing. For data sources, we need to consider the following:
- 我们已经有哪些数据?
- 虽然现在没有,但有可能拿到哪些数据?
- 其中哪部分数据可以用来降低风险?
- 哪部分数据可以用来构建知识图谱?
这里需要注意的是,并不是所有与反欺诈相关的数据都必须进入知识图谱,这一部分的一些决策原则将在下一节中更详细地介绍。
[En]
What needs to be noted here is that not all data related to anti-fraud must enter the knowledge graph, and some of the decision-making principles of this part will be introduced in more detail in the following section.
对于反欺诈,有几个数据来源我们很容易想象,包括用户的基本信息、行为数据、运营商数据、电商数据、黑名单、网络公开信息等。假设我们已经有了数据源的列表,下一步就是看看哪些数据需要进一步处理,比如对于非结构化数据,我们或多或少需要使用与自然语言处理相关的技术。用户填写的基本信息基本存储在业务表中,除了个别需要进一步处理的字段外,许多字段都可以直接用于建模或添加到知识图系统中。对于行为数据,我们需要经过一些简单的处理,并提取有效信息,如“用户在页面上停留的时间”等。对于网络上公开的网页数据,需要一些与信息抽取相关的技术。
[En]
For anti-fraud, there are several data sources that we can easily imagine, including the basic information of * users, behavior data, operator data, e-commerce data, blacklists, public information on the network, and so on. Assuming that we already have a list of data sources, the next step is to see which data needs further processing, for example, for unstructured data, we more or less need to use technologies related to natural language processing. The basic information filled in by users is basically stored in the business table, except for individual fields that need further processing, many fields can be directly used for modeling or added to the knowledge graph system. For behavioral data, we need to go through some simple processing and extract valid information such as “how long the user stays on a page” and so on. For the web page data open on the network, some technologies related to information extraction are needed.*
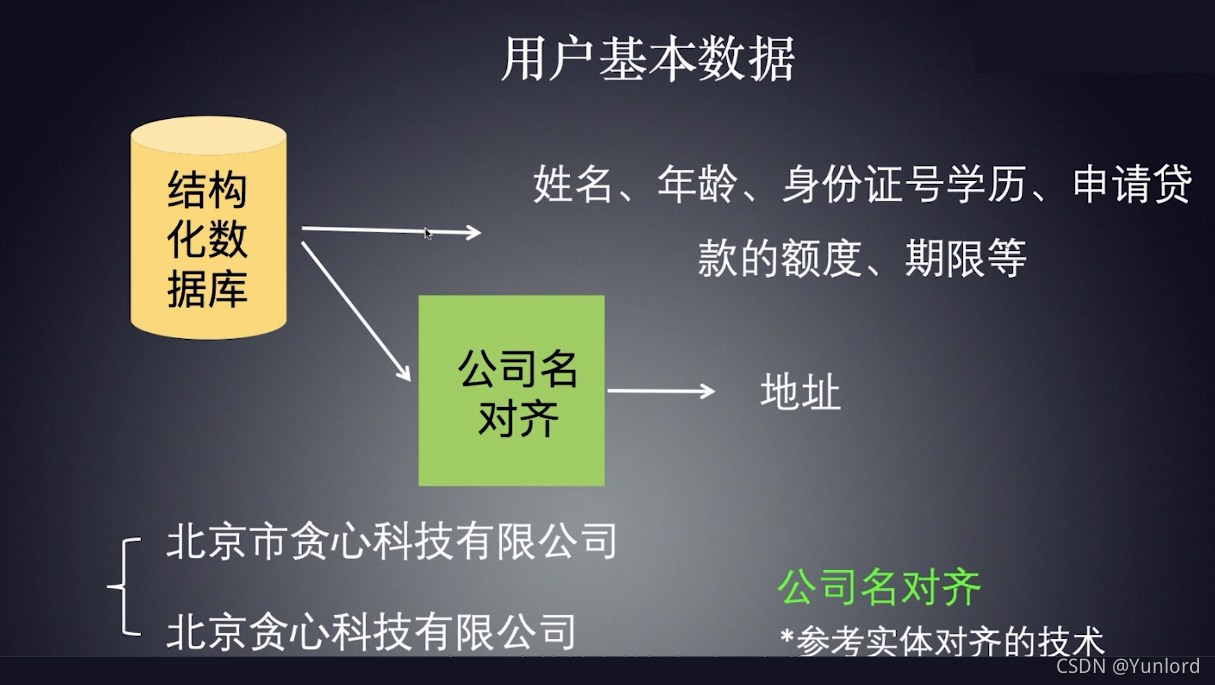
例如,对于用户的基本信息,我们可能需要做以下操作。一方面,可以从结构化数据库中直接提取和使用用户信息,如姓名、年龄、教育程度等字段。但另一方面,对于填写的公司名称,我们可能需要做进一步的处理。例如,一些用户填写了“北京贪婪科技有限公司”。其他人填写的是“北京望京贪婪科技有限公司”。事实上,它们都指向同一家公司。因此,这个时候我们需要做公司名称对齐,技术细节可以参考前面提到的实体对齐技术。
[En]
For example, for the basic information of the user, we probably need to do the following. On the one hand, user information such as name, age, education and other fields can be extracted and used directly from the structured database. But on the other hand, for the company name filled in, we may need to do further processing. For example, some users fill in “Beijing greedy Technology Co., Ltd.” and others fill in “Beijing Wangjing greedy Technology Co., Ltd.”. In fact, they all point to the same company. Therefore, at this time, we need to do the company name alignment, the technical details can refer to the entity alignment technology mentioned earlier.
3.知识图谱的设计
知识图谱的设计是一门艺术,不仅要对业务有很深的理解,也需要对未来业务可能的变化有一定预估,从而设计出最贴近现状并且性能高效的系统。
在知识图谱的设计中,我们肯定会面临以下共性问题:
[En]
In the design of knowledge graph, we will certainly face the following common problems:
- 需要哪些实体、关系和属性?
- 哪些属性可以做为实体,哪些实体可以作为属性?
- 哪些信息不需要放在知识图谱中?
基于这些常见问题,我们从以往的设计经验中提炼出一系列设计原则。这些设计原则类似于传统数据库设计中的范式,指导相关人员在保证系统效率的同时,设计出更合理的知识图系统。
[En]
Based on these common problems, we abstract a series of design principles from previous design experience. These design principles are similar to the paradigm in the traditional database design to guide the relevant personnel to design a more reasonable knowledge graph system while ensuring the efficiency of the system.

以上是对以往经验的总结,可能并不完全准确,但至少可以反映出我们在设计知识图谱时所避免的漏洞。接下来,我会围绕每一点向大家解释。
[En]
The above is summed up from previous experience and may not be completely accurate, but it can at least reflect the holes that we avoid when designing knowledge graphs. Next, I will explain to you around each point.
业务原则:一切从业务逻辑出发,也就是说通过观察知识图谱设计也很容易推测其背后业务逻辑。而且设计时也要想好未来业务的变化。
分析原则:知识图谱中任何实体都是为了关系分析而服务,如果实体对分析网络结构没有帮助,则可以设计成属性甚至不要放在知识图谱中。
冗余原则:知识图谱设计中,避免把超级节点放入到知识图谱中,这会导致系统性能急剧下降,并且避免存放任何信息。
效率原则:知识图谱尽量轻便,只存储关键信息,剩下的可以存储在传统数据库中。
利用上述原则,我们可以设计出一张金融反欺诈领域的图表。最后,一个简化的图表如下所示。当然,地图在实际应用中要比这复杂得多!
[En]
Using the above principles, we can design a graph in the field of financial anti-fraud. Finally, a simplified graph is shown below. Of course, the map in practical application is much more complicated than this!
4.知识图谱的存储
知识图谱主要有两种存储方式:一种是 基于RDF的存储;另一种是 基于图数据库的存储。它们之间的区别如下图所示。RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。

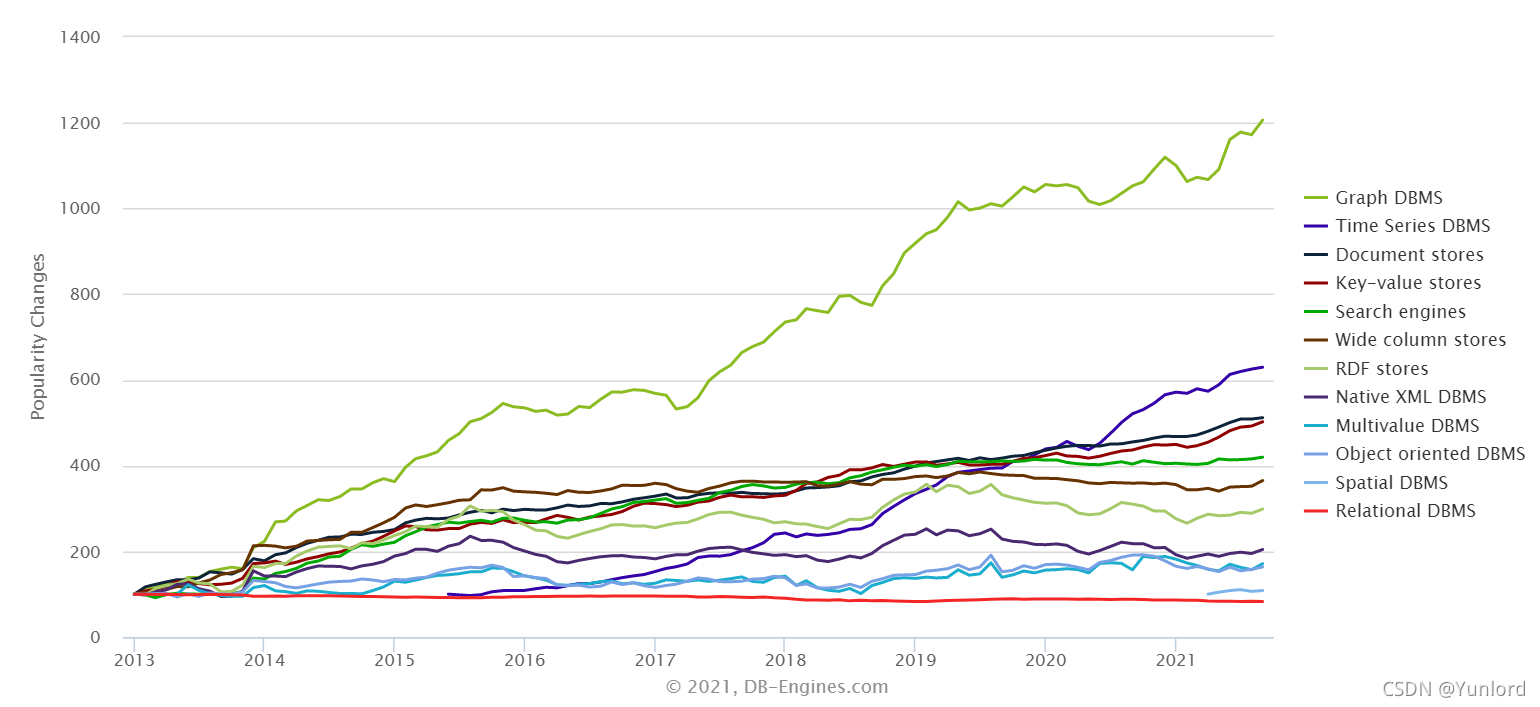
根据最新的统计,图数据库仍然是增长最快的存储系统。相反,关系型数据库的增长基本保持在一个稳定的水平。同时,也列出了常用的图数据库系统以及他们最新使用情况的排名。 其中 Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式。相反,OrientDB 和 JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃,这也就意味着使用过程当中不可避免地会遇到一些刺手的问题。如果选择使用RDF的存储系统,Jena或许一个比较不错的选择。
5.知识图谱的应用
在构建了知识图谱之后,我们应该用它来解决具体的问题。对于金融风险控制的知识图谱,首要任务是挖掘关系网络中隐藏的欺诈风险。从算法上看,有两种不同的场景:一种是基于规则的,另一种是基于概率的。前者依赖于专家的经验,后者依赖于数据驱动。
[En]
After building the knowledge graph, we should use it to solve specific problems. For the knowledge graph of financial risk control, the first task is to mine the hidden fraud risk in the relational network. From an algorithm point of view, there are * two different scenarios * : one is * rule-based * , and the other is * probability-based * . The former depends on the experience of experts, while the latter depends on data-driven.
鉴于目前AI技术的现状,基于规则的方法论还是在垂直领域的应用中占据主导地位,但随着数据量的增加以及方法论的提升,基于概率的模型也将会逐步带来更大的价值。
5.1 基于规则的应用
首先,我们来看几个基于规则的应用,它们是不一致验证、基于规则的特征提取、基于模式的判断。
[En]
First of all, let’s look at several rule-based applications, which are * inconsistency verification * , * rule-based feature extraction * , * pattern-based judgment * .
不一致性验证:
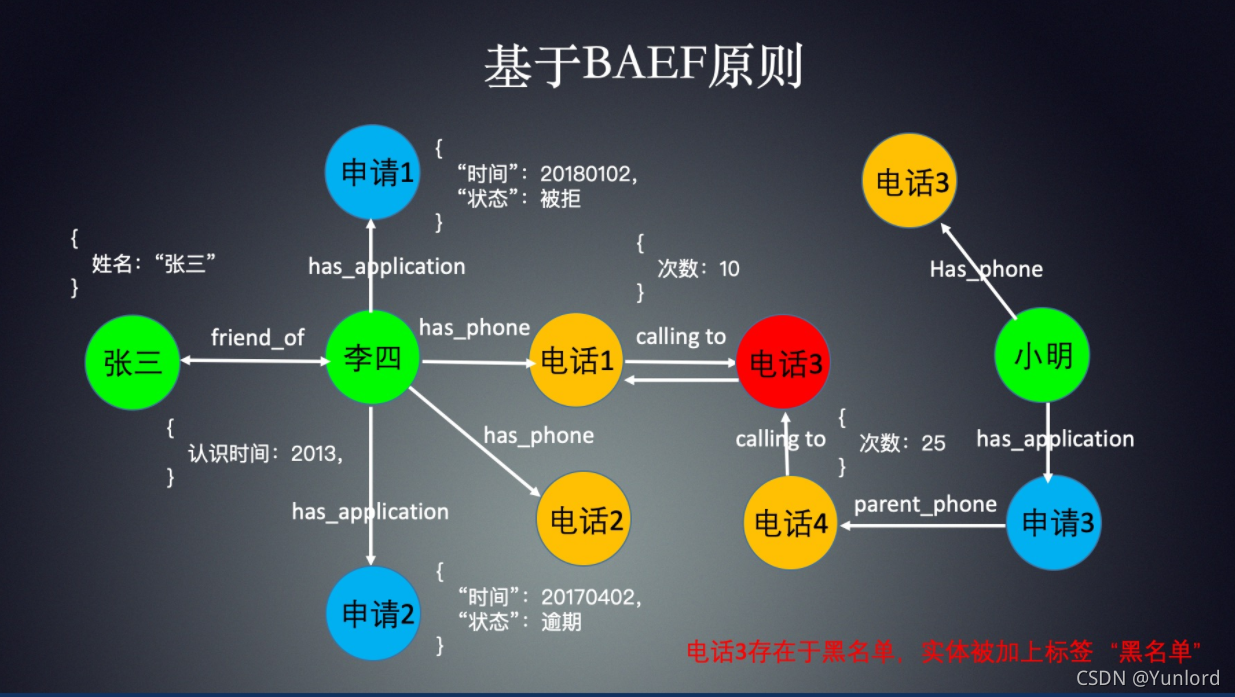
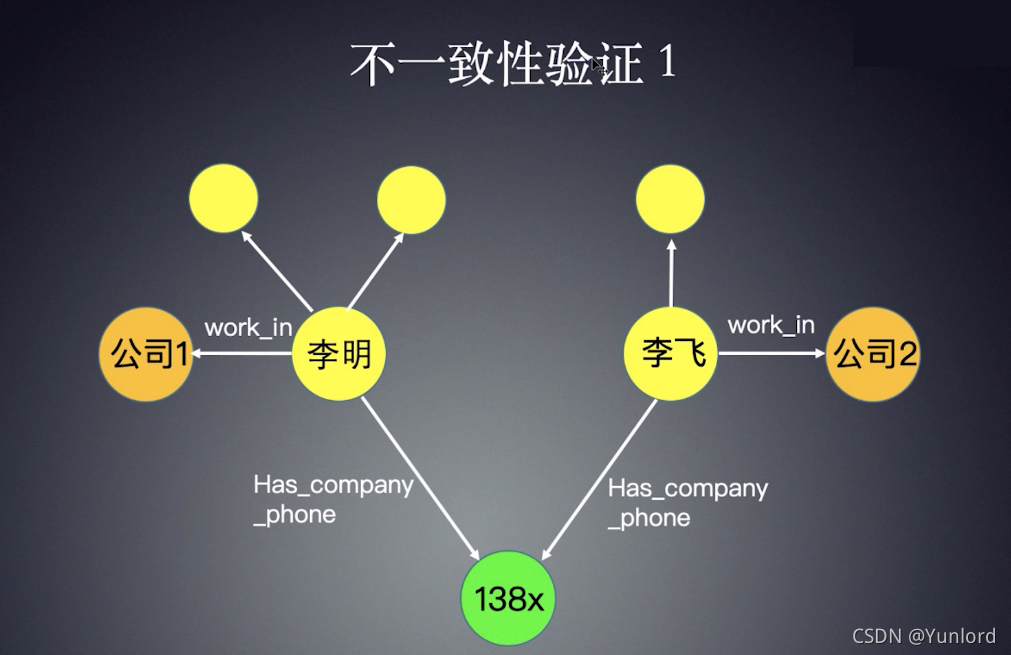
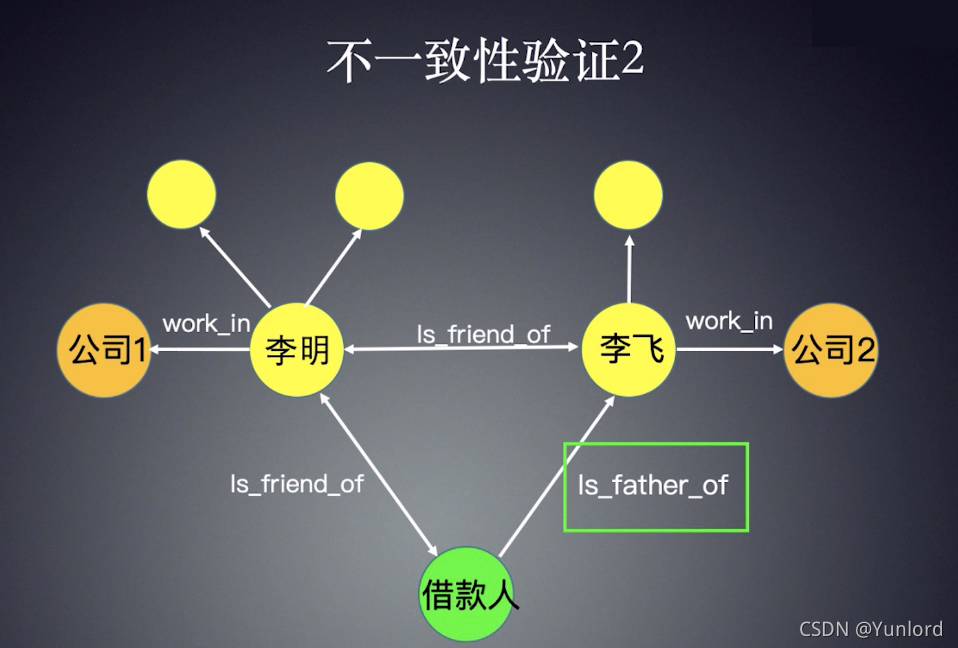
为了判断关系网络中的风险,一个简单的方法是做不一致的验证,即通过一些规则识别潜在的矛盾。这些规则是事先人为定义的,因此在设计规则时需要一些业务知识。例如,在下图中,李明和李斐表示的是同一个公司的电话号码,但从数据库中实际判断他们实际上在不同的公司工作,这是矛盾的。事实上,可以有很多类似的规则,这里没有列出。
[En]
In order to judge the risks in the relationship network, a simple way is to do inconsistency verification, that is, to identify potential contradictions through some rules. These rules are artificially defined in advance, so some business knowledge is needed in the matter of designing rules. For example, in the following picture, both Li Ming and Li Fei indicate the same company phone number, but actually judge from the database that they actually work in different companies, which is a contradiction. As a matter of fact, there can be many similar rules, which are not listed here.
基于规则提取特征:
我们还可以从基于规则的知识图中提取一些特征,这些特征通常是基于深度的搜索,如2度、3度甚至更高的维度。例如,我们可以问这样一个问题:“借款人和两者之间是什么关系?”从图中我们很容易观察到,借款人是李斐的父亲,李明是李斐的朋友。在提取这些特征后,它们可以用作风险模型的输入。我想在这里说明的是,如果这些功能不涉及深入的关系,实际上,传统的关系数据库就足以满足需求。
[En]
We can also extract some features from the knowledge graph based on rules, and these features are generally based on depth-based searches such as 2-degree, 3-degree or even higher dimensions. For example, we can ask the question: “what is the relationship between the borrower and the two?” From the picture, we can easily observe that the borrower is Li Fei’s father, and Li Ming is Li Fei’s friend. After these features are extracted, they can be used as the input of the risk model. I would like to make it clear here that if the features do not involve in-depth relationships, in fact, traditional relational databases are sufficient to meet the needs.
基于模式的判断:
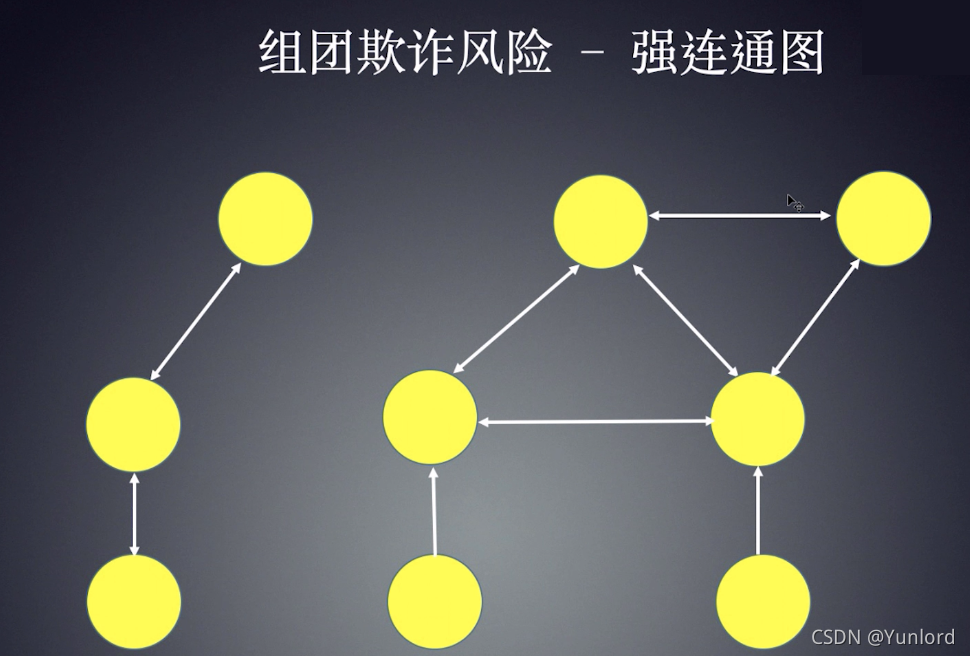
这种方法比较适用于找出团体欺诈,它的核心在于通过一些模式来找到有可能存在风险的团体或者子图(sub-graph),然后对这部分子图做进一步的分析。 这种模式有很多种,包括: 多点共享信息、三角关系、强连通图、团、弱连通图等等。在这里举几个简单的例子。 比如在下图中,三个实体共享了很多其他的信息,我们可以看做是一个团体,有欺诈嫌疑,并对其做进一步的分析。

例如,我们还可以从知识图中找到强连通图,对其进行标记,然后进行进一步的风险分析。强连通图是指每个节点可以通过一定的路径到达其他点,这表明这些节点之间存在着很强的关系。
[En]
For example, we can also find the strongly connected graph from the knowledge graph, mark it, and then do further risk analysis. Strongly connected graph means that each node can reach other points through a certain path, which shows that there is a strong relationship between these nodes.
5.2 基于概率统计的方法
除了基于规则的方法外,还可以使用概率和统计方法,如社区挖掘、标签传播、聚类等。
[En]
In addition to rule-based methods, probability and statistical methods can also be used, such as * community mining * , * tag propagation * , * clustering * and so on.
社区挖掘算法的目的在于从图中找出一些社区。对于社区,可以有多种定义,但直观上可以理解为社区内节点之间关系的密度要明显大于社区之间的关系密度。下面的图表示社区发现之后的结果,图中总共标记了三个不同的社区。一旦我们得到这些社区之后,就可以做进一步的风险分析。
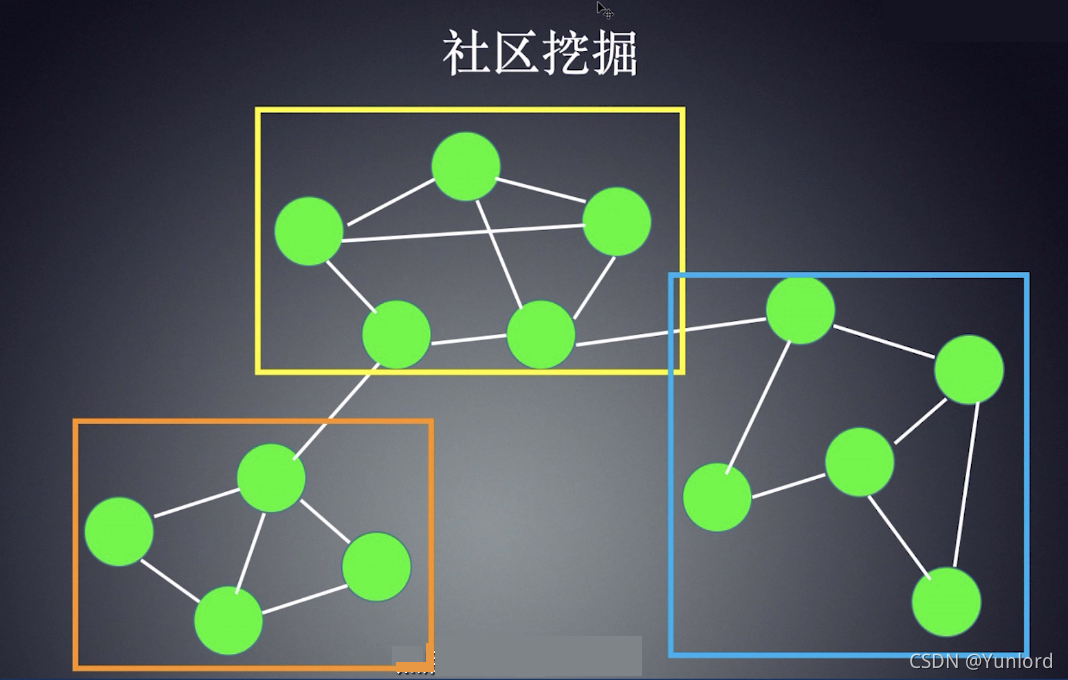
由于社区挖掘是基于概率方法论的,其优点是不需要人工定义规则,特别是对于大型关系网络,定义规则本身是一件非常复杂的事情。
[En]
Because community mining is based on probability methodology, the advantage is that there is no need to define rules artificially, especially for a large relational network, defining rules itself is a very complicated thing.
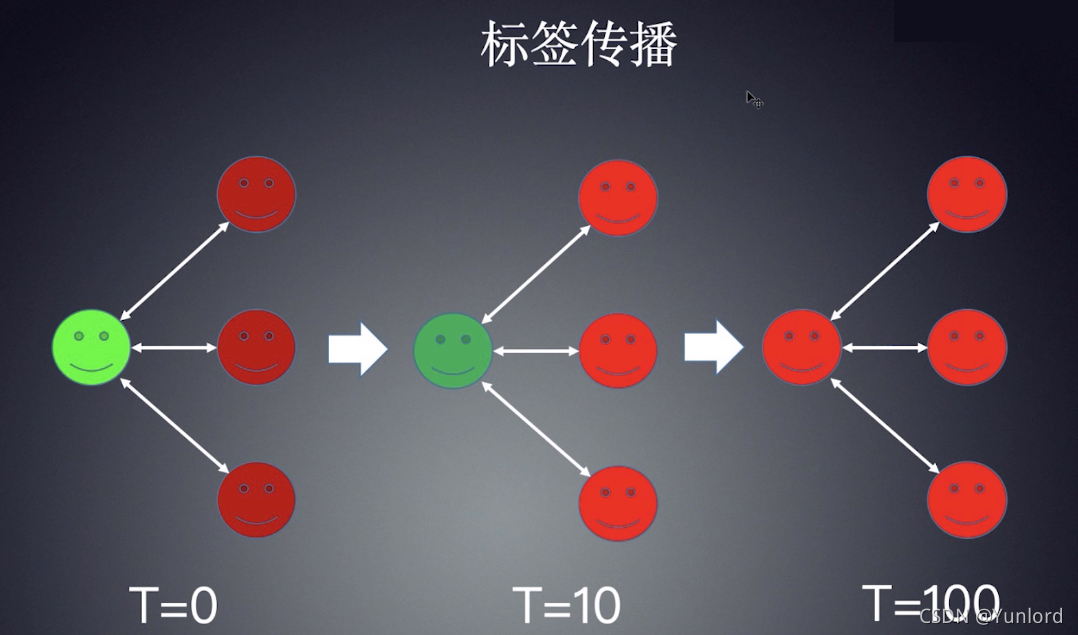
标签传播算法的核心思想在于节点之间信息的传递。这就类似于,跟优秀的人在一起自己也会逐渐地变优秀是一个道理。因为通过这种关系会不断地吸取高质量的信息,最后使得自己也会不知不觉中变得更加优秀。具体细节不在这里做更多解释。
与常规方法相比,基于概率的方法的缺点是需要足够的数据。如果数据量小,整个图是稀疏的,那么基于规则的方法就可以成为我们的首选。尤其是金融领域,数据标签较少,这是基于规则的方法论在金融领域仍被更广泛使用的主要原因。
[En]
Compared with the regular methodology, the disadvantage of the probability-based approach is that it requires enough data. If the amount of data is small and the whole graph is sparse, the rule-based method can become our first choice. Especially for the financial sector, there are fewer data labels, which is the main reason why rule-based methodology is still more widely used in the financial field.
5.3 基于动态网络的分析
以上所有分析都是基于静态关系图。所谓静态关系图,是指我们不考虑图结构本身随时间的变化,而是着眼于当前的知识图结构。然而,我们也知道,地图的结构会随着时间的推移而变化,这些变化本身可能与风险相关联。
[En]
All of the above analyses are based on a static relationship graph. The so-called static relationship graph means that we do not consider the change of the graph structure itself with time, but focus on the current knowledge graph structure. However, we also know that the structure of the map changes over time, and these changes themselves can be associated with risk.
在下面的图中,我们给出了一个知识图谱T时刻和T+1时刻的结构,我们很容易看出在这两个时刻中间,图谱结构(或者部分结构)发生了很明显的变化,这其实暗示着潜在的风险。
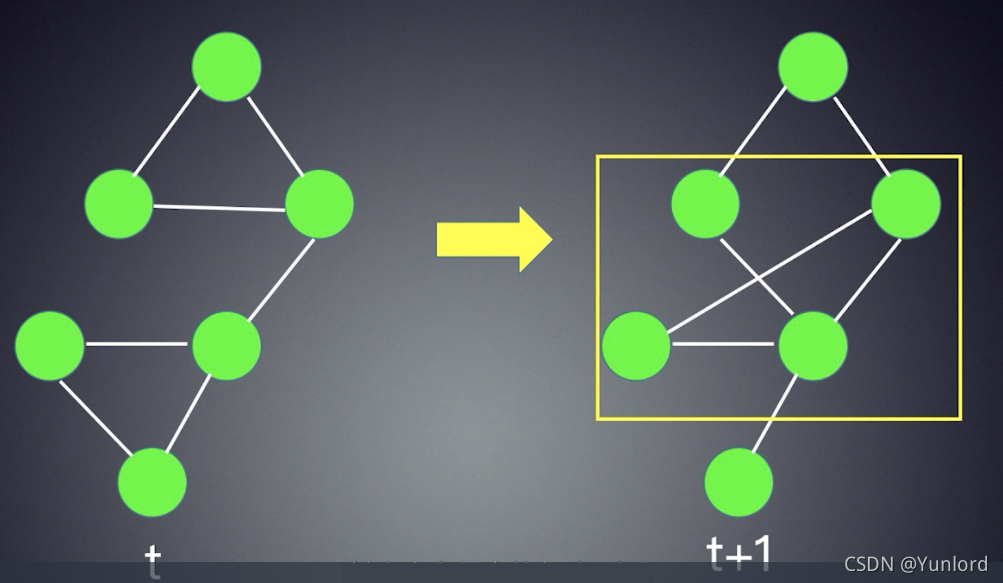
总结
知识图谱是一个富有挑战性和趣味性的领域。只要有正确的实际应用场景,知识图谱的价值就值得期待。在不久的将来,知识图技术将在各个领域得到广泛应用。
[En]
Knowledge graph is a challenging and interesting field. As long as there is a correct practical application scenario, the value of knowledge graph is worth looking forward to. In the near future, knowledge graph technology will be widely used in various fields.
而知识图是一种相对较新的工具,它的主要功能是分析关系,尤其是深度关系。所以在商业上,首先要保证它的必要性,其实很多问题都可以用非知识图的方式来解决。
[En]
And knowledge graph is a relatively new tool, its main function is to analyze the relationship, especially the depth relationship. So in business, first of all to ensure its necessity, in fact, many problems can be solved in a non-knowledge graph way.
知识图中最重要的角色之一就是知识推理。而知识推理是强势人工智能的必由之路。
[En]
One of the most important roles in the field of knowledge graph is knowledge reasoning. And the reasoning of knowledge is the only way to strong artificial intelligence.
最后,需要强调的是, 知识图谱工程本身还是以业务为重心,以数据为中心。
相关资料已上传,关注文末链接即可获取全部内容。
本文是从零开始学NLP 系列文章第十六篇,希望小伙伴们多多支持,互相交流。
参考:
贪心学院nlp
Original: https://blog.csdn.net/kobepaul123/article/details/120819406
Author: Yunlord
Title: 强人工智能必经之路?知识图谱超详细总结,快速入门KG首选(万字长文,值得收藏)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527313/
转载文章受原作者版权保护。转载请注明原作者出处!