

目录
一、任务背景和分析
公司有项目需求,需要识别语音信号是男女性别以及是否是彩铃等。之前一直是做文本相关的NLP相关项目,为此也开始慢慢涉足语音领域了。语音领域和文本NLP领域是不一样的,我猜测——目前语音领域相关的预训练模型还不成熟,端到端的方案还不足以满足商用的需求,比如ASR或者SST语音自动识别的方案HUBERT和wav2vec等——否则大家都开始使用起来了,目前应该是采用一些比较传统的方案。
ASR任务目前对我们公司来说,自研还是非常困难的,就直接使用生态伙伴科大讯飞的算法;项目需求区分男女声和彩铃的声音,其实这个任务还是比较简单的,并没有语音识别或者声纹识别中那么复杂。在数据质量和场景简单的情况下,应该能取得不错的效果。
语音信号是时域信号,目前基于时域信息对语音进行分析的貌似不是特别多,没有比较好的模型直接提取到合适的特征;一般而言都是通过传统的信号处理方案来做的,把语音时域信号转化为时域信号后就能得到很多特征,比如:MFCC、Fbank、bark谱、基频、能量幅度、短时过零率之类的——详见语音特征小结。
区分男女、彩铃信号等任务的主要要点是什么?如果你能找到区分它们的特征,你可以使用深度学习模型或机器学习模型,或者直接使用规则来做到这一点。您需要查找哪些功能?
[En]
What are the main key points for tasks such as distinguishing between men and women and color ring back tone signals? If you can find the characteristics that distinguish them, you can use a deep learning model or a machine learning model, or directly use rules to do it. What kind of features do you need to find?
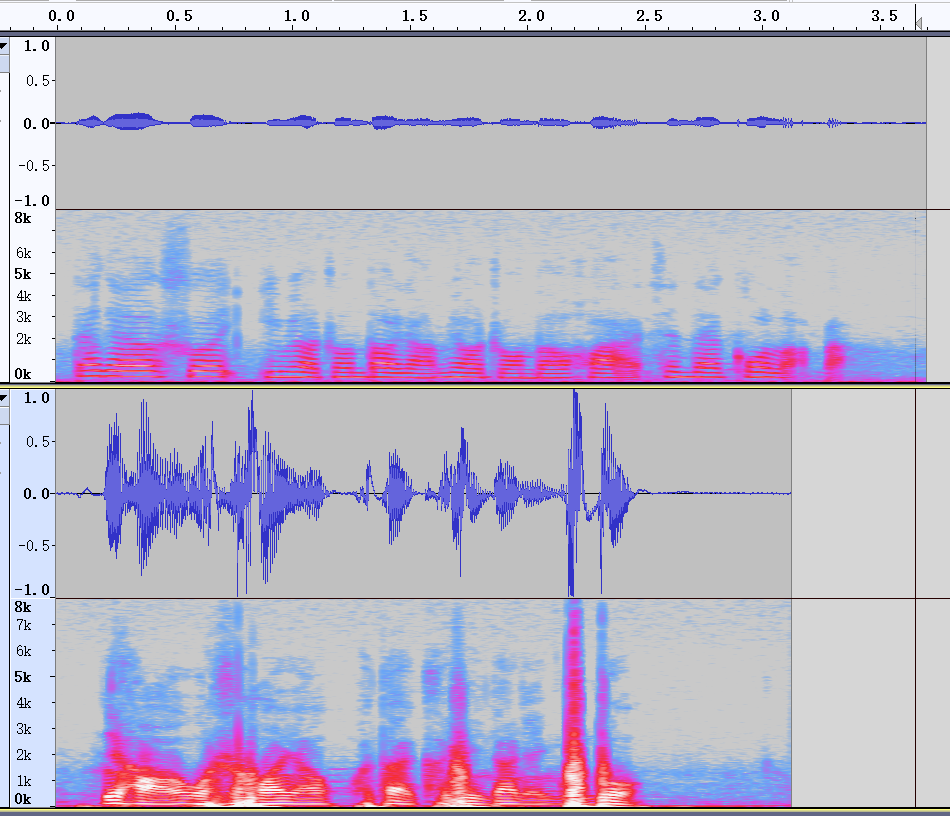

录了自己和女同事的音频,得到时序和频谱图(上图女,下图男)。感觉就从频谱图上直接看,还是看不出来的。一般而言男女声音的音高也就是频率是不一样的,但是也有重叠的部分;同时彩铃一般含有音乐的声音,它和人说话也有很大不同,音色不同,这个感觉在数理上反映也是频率的不同——据个人不完全理解这里的不同应该就是频率的分布不一样了,所以具体什么样的特征能区分开来也不是十分清楚的。那这个时候就得想到了深度学习的方案了,让模型自己去抽取相应的特征,也不需要管什么频率具体的分布,谱质心、谱对比度、基音周期等等特征,直接抽取语音信号的Fbank、Mfcc等特征,它们具体的区别,我不是专业的不清楚——知乎高赞问答解释如下语音信号提取声学特征时,MFCC和PLP的区别是什么?,喂入模型中即可!
另一方面,这是一个简单的分类任务,他们的三个班级直接有天然的区别,不需要太复杂的模型,应该能够做到。
[En]
On the other hand, this is a simple classification task, their three classes directly have natural differences, and do not need too complex models, should be able to do.
所以基本的方案就是
1、抽取Mfcc或者Fbank特征
2、Mfcc或者Fbank特征喂入模型(CNN/Lstm/LSTM+CNN)
3、分类得出结果。
当然也可以采用语音领域的预训练方案,wvNet或者wav2Vec这样的预训练+finetune的方案,这个方案比较新还没来得及学习,后续会学习,然后验证。
二、特征抽取
librosa
由于librosa库提供的特征提取API比较丰富,便选择了该库进行Mfcc和Fbank的提取。这里没啥好聊的,原理部分mfcc和fbank计算过程比较复杂详见——语音信号处理之(四)梅尔频率倒谱系数(MFCC)和语音识别特征处理(MFCC,Fbank,PNCC)
,而我就当个调包侠吧(原理部分就多去看几遍吧)。主要对提取特征的API的一些参数和遇到的坑进行一些总结吧
librosa.load(wav_path, sr=sr)——音频文件加载
把字节流的音频文件加载为基于sr抽样率的采样点数据,浮点数float32,numpy.array
注意点,mp3格式的文件需要调用其他的库,需要pip install;sr不设置会已默认的sr=22050
librosa.util.frame(wav, frame_length=frame_length, hop_length=hop_length)——分帧
设置帧长和帧移,这不是时间单位,而是采样点个数。比如采样率16000,1s内采样16000个数据点;frame_length 30ms应该就是480个采样点frame_length=480
fbank = librosa.feature.melspectrogram(y=wav, sr=sr, n_fft=frame_length, hop_length=hop_length, center=False,n_mels=128) fbank = fbank.T fbank = librosa.power_to_db(fbank)——梅尔频谱
n_fft短时傅里叶窗口长度,和帧长是一致的;n_mels采用多少个mel滤波器,最后得到的特征就是多少维度的;center参数需要进入源码去看,如果为True,表示音频会做padding,会使得帧D[:, t]的中心为信号 y[t * hop_length];而center=False的时候,不采用padding;要使得分帧后抽取特征再把特征cat起来和不分帧直接抽取特征的结果一致的话,就得采用center=False。
librosa.feature.mfcc(y=wav, sr=sr, n_mfcc=13, n_fft=frame_length, hop_length=hop_length, center = False, win_length = frame_length)——mel倒谱系数
librosa.feature.spectral_centroid(y=wav, sr=sr, n_fft=frame_length, hop_length=hop_length,center = False)——频谱中心
librosa.feature.spectral_contrast(y=wav, sr=sr, n_fft=frame_length, hop_length=hop_length, n_bands=4,center = False)——频谱对比度
librosa.core.piptrack(y=wav, sr=sr, S=None, n_fft=frame_length, hop_length=hop_length,center = False)
wave
读取语音的字节流和librosa中提取特征的不同
def read_wave(path):
"""Reads a .wav file.
Takes the path, and returns (PCM audio data, sample rate).
"""
with contextlib.closing(wave.open(path, 'rb')) as wf:
num_channels = wf.getnchannels()
assert num_channels == 1
sample_width = wf.getsampwidth()
assert sample_width == 2
sample_rate = wf.getframerate()
assert sample_rate in (8000, 16000, 32000, 48000)
pcm_data = wf.readframes(wf.getnframes())
params = wf.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
return pcm_data, sample_rate
wave读出来的是16bit的字节流,pcm编码数据,形如:
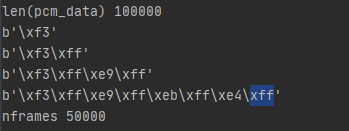
一般而言,采样率sr = 16000的话,1s音频采样数据点就为16000个,而得到的pcm字节流就是32000个。这个时候需要分别存储模型是小端模式还是大端模式,可以把16bit的byte转化为int型和float型,神经网络中需要处理float32型数据。处理就是把2个长度的byte传化为1个int或者float:
#把bytes转化为int
for k in range(0,int(len(frame_byte)/2)):
pcmInt.append(int.from_bytes(frame_byte[k * 2:k * 2 + 2], byteorder='little', signed=True))
再转化为float32
feature = np.array(pcmInt)/0x7fff
使用struct.unpack()转化——把16进制的2个byte字节流转化为float
pcmFloat = []
for k in range(0, int(len(frame_byte) / 2)):
pcmFloat.append(struct.unpack('h', frame_byte[index * 2:index * 2 + 2])[0] / ((2 ** 15) - 1))
最后一种直接把一长串的16进制字节流转化为short int型,然后再做除法,得到最后的float32型数据np.frombuffer():
feature = np.frombuffer(frame_byte, ctypes.c_short)/0x7fff
以上3中方法,其中最后一种最好,CPU占用最少。
torchaudio
torchaudio 支持以 wav 和 mp3 格式加载声音文件
metadata = torchaudio.info(SAMPLE_WAV_PATH)//查看音频信息
waveform, sample_rate = torchaudio.load(SAMPLE_WAV_SPEECH_PATH)//加载音频返回的是张量
torchaudio提供了Spectrogram,MelSpectrogram,MFCC等特征的提取
specgram = torchaudio.transforms.Spectrogram()(waveform)
specgram = torchaudio.transforms.MelSpectrogram()(waveform)
三、数据集
由于这是验证方案可行性的初步研究,所以数据集中使用的是通用数据集。
[En]
As it is a preliminary study to verify the feasibility of the scheme, the common dataset is used in the dataset.
四、模型训练
1、频域信号+LSTM+2DCNN
尝试的特征分为频域信号的MFCC和Fbank;模型层面首先采用的是LSTM和二维卷积以及残差二维卷积网络的组合。测试出来后的效果还可以,这里采用二维卷积网络的原因就是直接凭直觉把一帧一帧的语音信号,组合为一个语音图像,就类似图像分类,所以采用了这个网络。
简单的看看具体的流程:
MFCC
语音信号——》分帧——》过VAD——》判定is_speech,并用循环链表判定人声起始和结束点——》合并所有的frames注意去掉重复的——》librosa抽取各种特征包含{mffc、基音周期、谱质心和谱对比度}——》lstm+ nn.Linear
- Fbank+CNN+resCNN+RNN(LSTM)
FBank
语音信号——》分帧——》过VAD——》判定is_speech,并用循环链表判定人声起始和结束点——》合并所有的frames注意去掉重复的——》librosa抽取各种特征包含{Fbank、基音周期、谱质心和谱对比度}——》lstm+ nn.Linear
- Fbank+CNN+resCNN+RNN(LSTM)
上述方案的精度略有不同,大致接近以下数据,当然它也与使用的帧的数量有关。
[En]
The accuracy of the above scheme varies slightly, roughly near the following data, and of course it is also related to the number of frames used.
Test_acc: 0.943867 Test_recal: 0.857778 Test_f1: 0.826552
模型代码如下:
class GenderRecogiCnnLstmModel(nn.Module):
def __init__(self,n_class=2,rescnn_layers = 1,rnn_layers = 1,n_feats=128,dropout=0.1):
super(GenderRecogiCnnLstmModel,self).__init__()
self.cnn = nn.Conv2d(in_channels=1,out_channels=4,kernel_size=3,stride=1,padding=3//2)
# n residual cnn layers with filter size of 32
self.rescnn_layers = nn.Sequential(*[
Residual2DCNN(4, 4, kernel=3, stride=1, dropout=dropout, n_feats=n_feats)
for _ in range(rescnn_layers)
])
self.rnn_layers = nn.Sequential(
*[ nn.LSTM(input_size=n_feats if i==0 else n_feats*2,hidden_size=n_feats,batch_first=True,bidirectional=True)
for i in range(rnn_layers)
]
)
self.classifier = nn.Sequential(
nn.Linear(n_feats * 2, n_feats), # birnn returns rnn_dim*2
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(n_feats, n_class)
)
def forward(self,embeddings,mask):
# embeddings [B,L,D]
x = embeddings.unsqueeze(1).permute(0,1,3,2)# [B,1,D,L]
x = self.cnn(x) #[]
x = self.rescnn_layers(x)
x = x.view(x.shape[0],-1,x.shape[-2])
x,_ = self.rnn_layers(x)
# x = self.pooling(x, mask)
x = torch.mean(x,dim=1)
out = self.classifier(x)
out = torch.softmax(out, dim=-1)
return out
def pooling(self,embedding,mask):
embedding_mask = mask.unsqueeze(-1).expand(embedding.size()).float()
t = embedding * embedding_mask
sum_embeddings = torch.sum(t,dim=1)
sum_mask = embedding_mask.sum(dim=1)
# 限定每个元素的最小值是1e-9,保证分母不为0
sum_mask = torch.clamp(sum_mask, min=1e-9)
# output_vectors = []
# output_vectors.append(sum_embeddings / sum_mask)
#
# output_vectors = torch.cat(output_vectors, 1)
output_vectors = sum_embeddings / sum_mask
return output_vectors
class Residual2DCNN(nn.Module):
"""Residual CNN inspired by https://arxiv.org/pdf/1603.05027.pdf
except with layer norm instead of batch norm
"""
def __init__(self, in_channels, out_channels, kernel, stride, dropout, n_feats):
super(Residual2DCNN, self).__init__()
self.cnn1 = nn.Conv2d(in_channels, out_channels, kernel, stride, padding=kernel // 2)
self.cnn2 = nn.Conv2d(out_channels, out_channels, kernel, stride, padding=kernel // 2)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.layer_norm1 = CNNLayerNorm(n_feats)
self.layer_norm2 = CNNLayerNorm(n_feats)
def forward(self, x):
residual = x # (batch, channel, feature, time)
x = self.layer_norm1(x)
x = F.gelu(x)
x = self.dropout1(x)
x = self.cnn1(x)
x = self.layer_norm2(x)
x = F.gelu(x)
x = self.dropout2(x)
x = self.cnn2(x)
x += residual
return x # (batch, channel, feature, time)
class CNNLayerNorm(nn.Module):
"""Layer normalization built for cnns input"""
def __init__(self, n_feats):
super(CNNLayerNorm, self).__init__()
self.layer_norm = nn.LayerNorm(n_feats)
def forward(self, x):
# x (batch, channel, feature, time)
x = x.transpose(2, 3).contiguous() # (batch, channel, time, feature)
x = self.layer_norm(x)
return x.transpose(2, 3).contiguous() # (batch, channel, feature, time)
2、频域信号+2DCNN
由于上述方案中的模型比较复杂,训练和推理速度有点慢,又尝试了一维卷积+残差卷积的组合,不采用lstm。
- Fbank+CNN+resCNN
- 当然语音信号的前期处理,分帧VAD等操作都是需要的,另外一个就是调整帧数,到底需要采取多少帧,这个和线上业务以及性能要求有关系。
- Test_acc: 0.944560 Test_recal: 0.937778 Test_f1: *0.840637
模型代码如下:
class GenderReco1DCnnModel(nn.Module):
def __init__(self,n_class=2,n_feats=128,dropout=0.2):
super(GenderReco1DCnnModel,self).__init__()
self.layerNorm = nn.LayerNorm(n_feats)
self.cnn = nn.Sequential(
nn.Conv1d(in_channels=n_feats,out_channels=64,kernel_size=8,stride=4,padding=2),
nn.ReLU(),
nn.Conv1d(in_channels=64,out_channels=32,kernel_size=4,stride=2,padding=2),
nn.ReLU(),
nn.Conv1d(in_channels=32, out_channels=16, kernel_size=2, stride=1,padding=2),
nn.ReLU(),
)
def forward(self,embeddings,mask):
x = embeddings[:, 0:100, :] # embeddings [B,n,D]
x = self.layerNorm(x)
x = x.permute(0,2,1)
x = self.cnn(x) # []
x = x.view(x.shape[0],-1,x.shape[1])
x = torch.mean(x, dim=1)
out = self.classifier(x)
out = torch.softmax(out, dim=-1)
return out
3、时域信号+1DCNN
实验的过程中发现,在上线的过程中,语音信号是流式的传输且需要单机支持并发5000路,在提取MFCC或者Fbank特征的时候CPU瓶颈是支持不了的。方案应该采取消耗资源更低的提取特征的方案,可以尝试时域信号,也就是直接把语音信号波形图经过处理后作为模型输入,同样是需要对信号进行分帧,vad检测等。分帧以后,可以把一帧一帧看做一个语音单位,那么就有点类型TextCNN的情形,可以借鉴一维卷积网络来做。
- 时域信号+CNN+resCNN(一维卷积)
模型网络很简单,如下
class GenderRecoTimeDomainVoiceModel(nn.Module):
def __init__(self, n_class=2, rescnn_layers=10, n_feats=128, dropout=0.1):
super(GenderRecoTimeDomainVoiceModel, self).__init__()
self.layerNorm = nn.LayerNorm(n_feats)
self.cnn = nn.Conv1d(in_channels=n_feats,out_channels=64,kernel_size=8,stride=4,padding=2)
# n residual cnn layers with filter size of 32
self.rescnn_layers = nn.Sequential(*[
Residual1DCNN(64, 64, kernel=3, stride=1, dropout=dropout, n_feats=25)
for _ in range(rescnn_layers)
])
self.classifier = nn.Sequential(
nn.Linear(64, 64), # birnn returns rnn_dim*2
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(64, n_class)
)
def forward(self, embeddings):
# embeddings [B,L,D]
x = embeddings[:, 0:100, :] # embeddings [B,n,D]
x = x.view(x.shape[0],-1,480)
x = self.layerNorm(x)
x = x.permute(0, 2, 1)
x = self.cnn(x) # []
x = self.rescnn_layers(x)
x = x.permute(0, 2, 1)
x = torch.mean(x, dim=1)
out = self.classifier(x)
return out
最后的结果

该方案在基本满足在线精度要求的同时,经过工程优化,实现了单机5000个通道的并发。
[En]
Basically meet the online accuracy requirements, at the same time, this scheme, after engineering optimization, has achieved the concurrency of 5000 channels on a single machine.
以上就是本人第一个语音项目的探索,很简单,学习到了一定的语音领域的知识,后面再接再厉,好好学习ASR和TTS相关知识,争取成为NLP和语音算法工程师!
Original: https://blog.csdn.net/HUSTHY/article/details/123075954
Author: colourmind
Title: 说话人性别识别——语音检测初探
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527237/
转载文章受原作者版权保护。转载请注明原作者出处!