

嗨,大家我,欢迎来到AI+语音专栏,本专栏长期更新,每篇文章必备干货,文章附带大量的算法原理+代码实现教学,欢迎关注,一起AI。
语音识别原理
首先是语音识别和语音唤醒的任务。一听到,你就会想到科大讯飞、中国、百度等平台,因为
[En]
The first is the tasks of speech recognition and voice awakening. As soon as you hear it, you will think of iFLYTEK, China Baidu and other platforms, because
这两家企业在中国语音领域占用80+市场,所以他们做得很优秀,不过由于高精技术无法开源,其他企业只得花费大量的金钱去购买其API,而无法研究语音识别等应用,导致民间语音识别发展较慢,今天我们来一饱眼福吧!


; 信号处理,声学特征提取
我们都知道声音信号是连续的模拟信号,要让计算机处理首先要转换成离散的数字信号,进行采样处理。正常人听觉的频率范围大约在20Hz~20KHz之间,为了保证音频不失真影响识别,同时数据又不会太大,通常的采样率为16KHz。

语音采样
在数字化的过程中,首先要判断语音的结尾,确定语音的开头和结尾,然后再进行降噪滤波(除了人的语音之外,还有很多噪声)。确保计算机能够识别过滤后的语音信息。在获得离散数字信号后,需要对音频信号进行成帧处理。由于离散信号本身计算的数据量太大,逐点处理容易产生毛刺。同时,从微观上看,人的语音信号在一段时间内一般是比较稳定的,这称为短期平稳性,因此需要对其进行成帧处理。
[En]
In the process of digitization, we should first judge the end, determine the beginning and end of the voice, and then carry out noise reduction and filtering (in addition to the human voice, there is a lot of noise). Make sure that the filtered speech information is recognized by the computer. After obtaining the discrete digital signal, we need to frame the audio signal for further processing. Because the discrete signal alone calculates too much data, the point-by-point processing is prone to burr. At the same time, from a microscopic point of view, the human voice signal is generally relatively stable over a period of time, which is called short-term stationarity, so it will need to be framed to facilitate processing.
我们的每个发音,称为音素,是最小的语音单位。
[En]
Each of our pronunciation, called a phoneme, is the smallest unit of speech.
比如普通话发音中的元音和辅音。不同的发音变化是由人群口腔肌肉的变化引起的。
[En]
Such as vowels and consonants in Putonghua pronunciation. Different pronunciation changes are caused by changes in the oral muscles of the population.
这种口腔肌肉的运动相对于语音频率很慢,所以为了保证信号的短期平稳性。
[En]
This kind of oral muscle movement is very slow relative to the speech frequency, so in order to ensure the short-term stationarity of the signal.
框架的长度应该小于音素的长度,当然也不能太小,否则框架就没有意义。
[En]
The length of the frame should be less than the length of a phoneme, and certainly not too small, otherwise the frame is meaningless.
通常一帧为20~50毫秒,同时帧与帧之间有交叠冗余,避免一帧的信号在两个端头被削弱了影响识别精度。常见的比如 帧长为25毫秒,两帧之间交叠15毫秒,也就是说每隔25-15=10毫秒取一帧,帧移为10毫秒,分帧完成之后,信号处理部分算是完结了。
随后进行的就是整个过程中极为关键的特征提取。将原始波形进行识别并不能取得很好的识别效果,而需要进行频域变换后提取的特征参数用于识别。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。
实际应用中,这一步有很多细节,声学特征也不止有MFCC这一种,具体这里不讲,但是各种特征提取方法的核心目的都是统一的:尽量描述语音的根本特征,尽量对数据进行压缩。
比如下图示例中,每一帧f1,f2,f3…转换为了14维的特征向量,然后整个语音转换为了14*N(N为帧数)的向量矩阵。
如果逐帧向量不是很直观,语音也可以用下图的频谱来表示,每列从左到右是一个25毫秒的块,从原始声波中寻找模式要容易得多。
[En]
If the frame-by-frame vector is not very intuitive, the speech can also be represented by the frequency spectrum of the following picture, and each column is a 25-millisecond block from left to right, which is much easier to find patterns from the original sound waves.
然而,频谱图主要用于语音研究,语音识别仍然需要使用逐帧特征向量。
[En]
However, the spectral map is mainly used for speech research, and speech recognition still needs to use a frame-by-frame feature vector.
识别字符,组成文本
特征提取完成后,进入特征识别和字符生成过程。这一部分的核心工作是从每一帧中找出当前所说的音素,然后由多个音素组成词,然后以词为单位形成文本句子。当然,最难的是从每一帧中找到当前音素,因为每一帧都不到一个音素,多个帧就可以形成一个音素,如果一开始就错了,以后就很难改正了。
[En]
After the completion of feature extraction, it enters the process of feature recognition and character generation. The core work of this part is to find out the currently spoken phonemes from each frame, then form words by multiple phonemes, and then form text sentences by words. Of course, the most difficult thing is to find the current phoneme from each frame, because each frame is less than one phoneme, multiple frames can form a phoneme, and if you are wrong at the beginning, it is difficult to correct later.
怎么判断每一个帧属于哪个音素了?最容易实现的办法就是概率,看哪个音素的概率最大,则这个帧就属于哪个音素。那如果每一帧有多个音素的概率相同怎么办,毕竟这是可能的,每个人口音、语速、语气都不同,人也很难听清楚你说的到底是Hello还是Hallo。而我们语音识别的文本结果只有一个,不可能还让人参与选择进行纠正。
此时,多个音素组成一个词的统计决策起到了作用,它们也是基于概率:当音素概率相同时,比较词的概率,然后比较词形成后的句子的概率。
[En]
At this time, the statistical decision of multiple phonemes to form a word plays a role, and they are also based on probability: when the phoneme probability is the same, compare the probability of the word, and then compare the probability of the sentence after the word is formed.
写——「Hello」、「Hullo」和「Aullo」,最终根据单词概率我们会发现Hello是最可能的,所以输出Hello的文本。上面的例子很明确的描述怎么从帧到音素,再从音素到单词,概率决定一切,那这些概率是怎么获得的了?难道为了识别一种语言我们把人类几千上百年说过的所有音素,单词,句子都统计出来,然后再计算概率?傻子都知道这是不可能的,那怎么办,这时我们就需要模型:
声学模型
基本的音素状态和发音概率,试图获得不同人、不同年龄、不同性别、不同口音和语速的语音语料库,同时收集各种安静、嘈杂、远距离的语音语料来生成声学模型。为了达到更好的效果,不同的方言会针对不同的语言使用不同的声学模型,这样可以提高精度,减少计算量。
[En]
The basic phoneme state and probability of articulation, try to obtain the vocal corpus of different people, different ages, genders, accents and speech speed, and at the same time collect a variety of quiet, noisy, long-distance vocal corpus to generate acoustic models. In order to achieve better results, different dialects will use different acoustic models for different languages, which can improve the accuracy and reduce the amount of calculation.
语言模型
使用大量的文本来训练单词和句子的概率。如果模型中只有两个句子,今天星期一和明天星期二,那么我们只能识别这两个句子,如果我们想识别更多,我们只需要覆盖足够的语料库,但随后模型增加,计算量增加。因此,在我们的实际应用中,模型通常局限于智能家居、导航、智能音箱、个人助理、医疗等应用领域,可以在减少计算量的同时提高精度。
[En]
The probability of words and sentences is trained using a large number of texts. If there are only two sentences in the model, “Today Monday” and “tomorrow Tuesday”, then we can only recognize these two sentences, and if we want to identify more, we only need to cover enough corpus, but then the model increases and the amount of calculation increases. Therefore, the models in our practical applications are usually limited to the application domain, such as smart home, navigation, smart speakers, personal assistant, medical and so on, which can reduce the amount of computation and improve the accuracy at the same time.
词汇模型
用于补充语言模型、语言词典和不同的发音标签。比如,定期更新地名、人名、歌名、热词、某些领域的专题词等。
[En]
For the supplement of the language model, language dictionaries and different pronunciation tags. For example, regularly updated place names, names of people, names of songs, hot words, special words in some fields, and so on.
语言模型和声学模型可以说是语音识别中最重要的两个部分。语音识别中一个非常重要的任务就是对模型进行训练。如果有句子没有被识别,我们会添加它们并重新训练它们。
[En]
Language model and acoustic model can be said to be the two most important parts of speech recognition. A very important task in speech recognition is to train the model. If there are sentences that are not recognized, we will add them and retrain them.
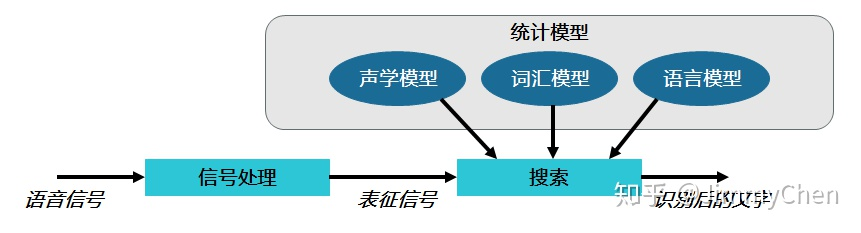
这时我们有很多简化但是有效的方法进行计算,比如说HMM隐马尔科夫模型Hidden Markov Model。
这样,语音识别的整个过程就清晰了,下面我们来回顾一下以下步骤:
[En]
In this way, the whole process of speech recognition is clear, and let’s review the following steps:
信号处理:模数转换、识别终端、降噪等。信号表征:信号成帧、特征提取、矢量化等。
[En]
Signal processing: analog-to-digital conversion, identification terminal, noise reduction and so on. Signal characterization: signal framing, feature extraction, vectorization and so on.
模式识别:找到最佳概率路径,声学模型识别音素,词汇模型和语言模型识别单词和句子。
[En]
Pattern recognition: find the optimal probability path, acoustic models recognize phonemes, lexical models and language models recognize words and sentences.
; 中国顶级语音技术是怎么样的?
现在演示的是识别音频文件的内容。
[En]
Now the demonstration is to identify the contents of the audio file.
token获取见官网,这边调包没什么含金量。
Python 技术篇-百度语音API鉴权认证获取Access Token
注:下面的 token 是我自己申请的,建议按照我的文章自己来申请专属的。
import requests
import os
import base64
import json
apiUrl='http://vop.baidu.com/server_api'
filename = "16k.pcm"
size = os.path.getsize(filename)
file1 = open(filename, "rb").read()
text = base64.b64encode(file1).decode("utf-8")
data = {
"format":"pcm",
"rate":16000,
"dev_pid":1536,
"channel":1,
"token":"24.0c828682d414bf79b08f89c4c7dcd83a.2592000.1562739150.282335-16470175",
"cuid":"DC-85-DE-F9-08-59",
"len":size,
"speech":text,
}
try:
r = requests.post(apiUrl, data = json.dumps(data)).json()
print(r)
print(r.get("result")[0])
except Exception as e:
print(e)
第二的话,我们还可以体验一下百度的接口,下面,cv君给你们找了一个好东西,大家可以体验一下百度的水平。
URL,你可以申请,然后进入有很多界面,申请,最后你可以得到想要的程序,比如:
[En]
URL, you can apply, and then enter there are many interfaces, apply, and finally you can get the desired program, such as:
https://console.bce.baidu.com/ai/?_=1624804122867&fromai=1#/ai/speech/overview/index
分为 在线识别: 通过调用百度在Web端部署好的语音模型及其服务 ,来返回结果。
离线命令词识别: 通过在百度上配置离线的服务,可以实现在这款APP上实现离线的语音识别,cv君后期也会发布离线语音的算法,毕竟离线的会更有优势和通用。
其中,唤醒词:通过百度界面实现唤醒词的准备和训练,然后通过官方指导即可进行唤醒词的部署。
[En]
Among them, wake-up words: the preparation and training of wake-up words are realized through Baidu interface, and then the deployment of wake-up words can be carried out through official guidance.
接下来,大家可以通过上方链接,找到教学以及成功部署一个自己的离线在线语音识别项目,比如我们在安卓中实现,安装好APP, 打开APP就能看到这主界面,每个环节都是不同的算法,大家可以添加或者删减任务项。

接下来,看看在线识别模块,在 在线识别项目中,我们的语音流 ,一般情况下会转换成base64等的web流,传输至服务器,服务器会解析,将base64等流解码转换成语音流,然后就可以通过服务器的识别算法(封装成了服务),对语音流识别,然后 就可以成功得到语音识别结果,并且能返回到APP中了。
大家可以看到下面我的演示中,语音识别,我讲述了一句话”我爱语音识别” 当我说到我爱的时候,他CTC解码后使用隐马尔可夫链等方式能够实现识别结果从TOP K 中找到TOP 1 的识别结果,他在前后语序的连贯性中发挥了强大的作用。

用离线指挥语来说,我们应该知道什么是离线,即语音识别完全可以离线完成,也就是说,在正常情况下,我们可以完成识别任务,并将其反馈到前台和后台。
[En]
In the offline command words, we should know what is meant by offline, that is, speech recognition can be completed completely offline, that is to say, under normal circumstances, we can achieve the recognition task and feed it back to the front and rear.
不过,大家都知道,真正意义上的离线识别,就是需要全部模块,从初始到最后,都不需要网络的,但是,百度这款,首次使用是需要联网下载文件的,所以并不意味真正的离线,而且离线模式远差于在线的模式,因为他们的在线模式的模型部署在服务器中,能支持大型模型,而大型模型往往很大,不适合在APK中部署。

在在线识别部分,它们提供了识别界面。
[En]
In the online identification section, they provide an identification interface.

到了唤醒词部分,大家应该知道,在唤醒词中,我么应该知道,唤醒词的目的是,我们需要像小爱同学,siri那样的唤醒词,唤醒词通过大量逻辑和相关算法,实现:既能识别关键唤醒词,又能省电,不是时时刻刻都在执行项目和算法,需要极限省电,cv君后续会给大家带来唤醒词的识别和教学,欢迎关注~

链接:https://pan.baidu.com/s/12utb69Nkqb_G4I8T1r4-0Q
提取码:deep
我给大家分享上面的模型和apk,欢迎安卓和鸿蒙等设备安装使用~
; 总结
今天,我们分享语音识别的基本知识和简单的应用。欢迎您学习和跟随。本栏目将长期更新。我们将与您一起学习语音技术,实现入门级和升华。
[En]
Today, we share the basic knowledge and simple application of speech recognition. You are welcome to learn and follow. This column will be updated for a long time. We will work with you to learn voice technology and achieve entry-level and sublimation.
Original: https://blog.csdn.net/qq_46098574/article/details/118659426
Author: cv君
Title: 语音识别 从入门到进阶 一 文末附项目/源码
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527005/
转载文章受原作者版权保护。转载请注明原作者出处!