

本文来自公众号”AI大道理”。
这里既有AI,又有生活大道理,无数渺小的思考填满了一生。
基于GMM的0-9孤立词识别系统以词为训练单位,添加新词汇需要重新进行训练,若要涵盖所以
词,差不多6万个词,训练量极大,预测时也要计算6万个模型的似然,哪个大预测出哪个,在实际应用中有局限性,只能应用于小词汇量场合。
孤立词识别系统识别了0-9的数字的英文单词,但是假如有人用英文报电话号码,是识别不了整个号码的,甚至识别不了其中的one。
孤立词识别这个模型无法从一连串英文号码(里面包含了one two等多个数字)中准确识别出one,关键点在于连续语音中不知道哪些语音信号是one,哪些是two,或者说不知道哪些帧是one哪些帧是two。
所以若要识别连续的0123456789的语音就需要Viterbi在HMM中进行对齐,这就是GMM-HMM模型了。
1 识别流程
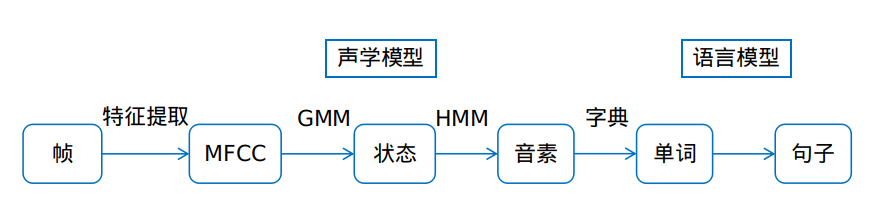

在GMM独立词识别中以单词为单位建模,在GMM-HMM中以音素为单位进行建模。对连续语音提取MFCC特征,将特征对应到状态这个最小单位,通过状态获得音素,音素再组合成单词,单词串起来变成句子。
其中,若干帧对应一个状态,三个状态组成一个音素,若干音素组成一个单词,若干单词连成一个句子。难点并在于若干帧到底是多少帧对应一个状态了,这就使用到了viterbi对齐。 为了提高识别率,在三音子GMM-HMM模型基础上,又用DNN模型取代GMM模型,达到了识别率明显的提升。
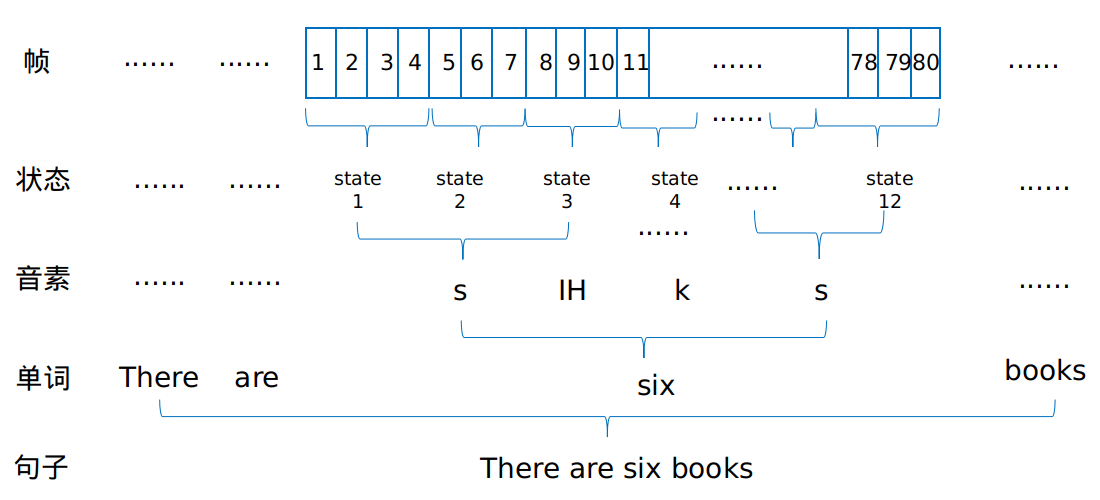
将特征用混合高斯模型进行模拟,把均值和方差输入到HMM的模型里。GMM描述了状态的发射概率,拟合状态的输出分布。
虽然单音素模型可以完成大词汇量连续语音识别的基本任务,但它也存在一些不足。
[En]
Although the single-phoneme model can complete the basic task of continuous speech recognition with large vocabulary, it has some shortcomings.
- 建模单位数量较少。一般来说,英语系统中的音素数量约为3060个,而汉语系统中的音素数量约为100个。由于建模单元较少,难以实现精细建模,因此识别率不高。
[En]
the number of modeling units is small. Generally speaking, the number of phonemes in English systems is about 3060, while that in Chinese systems is about 100. So few modeling units are difficult to achieve fine modeling, so the recognition rate is not high.*
- 音素发音受其语境影响,同一音素在不同语境中的数据特征有明显差异。
[En]
phoneme pronunciation is affected by its context, and the data features of the same phoneme are obviously differentiated in different contexts.*
所以就考虑音素所在的上下文(context)进行建模,一般的,考虑当前音素的前一个(左边)音素和后一个(右边)音素,称之为三音素,并表示为A-B+C的形式,其中B表示当前音素,A表示B的前一个音素,C表示B的后一个音素。
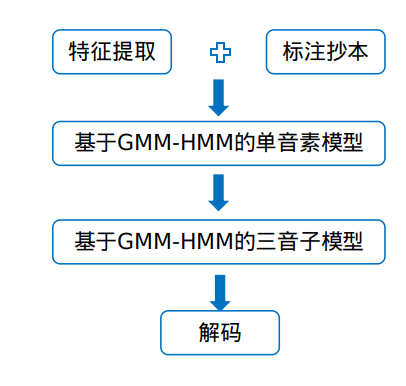
2 单音素模型
训练问题
一段2秒的音频信号,经过【分帧-预加重-加窗-fft-mel滤波器组-DCT】,得到MFCC特征作为输入信号,此处若以帧长为25ms,帧移为25ms为例,可以得到80帧的输入信号,这80帧特征序列就是观察序列:
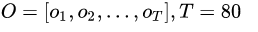
给定观察序列O,估计GMM-HMM模型的参数,这就是训练问题。

A是转移概率,B是观察概率,也就是发射概率。我们使用GMM模型对观察概率建模,所以实际参数就是高斯分布中的均值和方差。模型参数就是转移概率、高斯分布的均值、方差(单高斯的情况)。单音素GMM-HMM模型的训练是无监督训练。
(灵魂的拷问:我们对语音进行了标注,也就是给了输入语音的label,为什么这个训练还是无监督的呢?
AI大语音:模型的训练并不是直接输入语音,给出这个语音是什么,然后和标注label求loss。模型的训练是输入特征到音素的状态的训练,即我们并不知道哪一帧输入特征对应哪个音素的哪一个状态。训练的目的就是找到帧对应状态的情况,并更新状态的gmm参数。把每一帧都归到某个状态上,本质上是进行聚类,是无监督训练。)
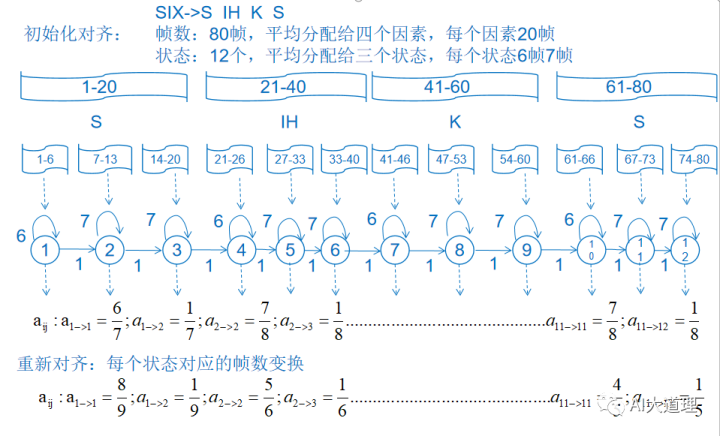
单音素GMM-HMM模型的训练通过Viterbi训练(嵌入式训练),把”S IH K S”对应的GMM模型嵌入到整段音频中去训练。
训练步骤:
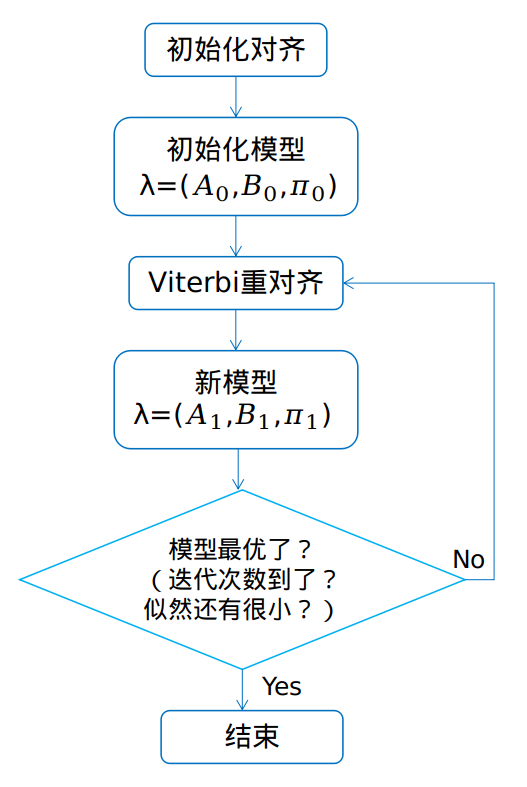
步骤一:初始化对齐
为什么要初始化对齐?
为viterbi提供初始参数A、B。
一开始不知道一段语音的哪些帧对应哪些状态,我们就进行平均分配。比如两秒的” six”语音一共80帧,分成四个因素”S IH K S”,每个音素分配到20帧,每个音素又有三个状态组成,每个状态分配6或者7帧。这样就初始化了每个状态对应的输入数据。
什么意思?
就是假设前0-20帧数据都是”S”这个音素的发音,20-40帧数据都是”IH”这个音素的发音,40-60帧是”K”这个音素的发音,60-80是”S”这个音素的发音。但这只是一个假设,事实到底如此我们还不知道。我们可以在这个初始对齐下进一步优化。
步骤二:初始化模型
HMM模型λ=(A,B,Π)。我们对初始对齐的模型进行count。count什么呢?
在初始化对齐后就可以count状态1->状态1的次数,状态1->状态2的次数,这就是转移次数,转移次数/总转移次数=转移概率。转移初始转移概率A(aij)就得出了。
Π就是[1,0,0,0…],一开始在状态一的概率是100%。在语音识别应用中由于HMM是从左到右的模型,第一个必然是状态一,即P(q0=1)=1。所以没有pi这个参数了。
还有B(bj(ot))参数怎么办?
一个状态对应一个gmm模型,一个状态对应若干帧数据,也就是若干帧数据对应一个gmm模型。一开始我们不知道哪些帧对应哪个状态,所以gmm模型的输入数据就无从得知。现在初始化后,状态1对应前6帧数据,我们就拿这六帧数据来计算状态1的gmm模型(单高斯,只有一个分量的gmm),得到初始均值 和方差 。
(完美的假想:假设我们初始化分配帧恰恰就是真实的样子,那么我们的gmm参数也是真实的样子,这个模型就已经训练好了。)
步骤三:重新对齐(viterbi硬对齐,Baum-welch软对齐)
假想想想就好了,现在得到的GMM-HMM模型就是个胚芽,还有待成长,懂事,这就需要重新对齐,向真实情况逼近的重新对齐。如何逼近真实情况?viterbi算法根据初始化模型λ=(A,B,Π)来计算。它记录每个时刻的每个可能状态的之前最优路径概率,同时记录最优路径的前一个状态,不断向后迭代,找出最后一个时间点的最大概率值对应的状态,如何向前回溯,得到最优路径。得到最优路径就得到最优的状态转移情况,哪些帧对应哪些状态就变了。转移概率A就变了。
哪些帧对应哪些状态变了导致状态对应的gmm参数自然就变了,也可以跟着更新均值 和方差,即发射概率B变了。
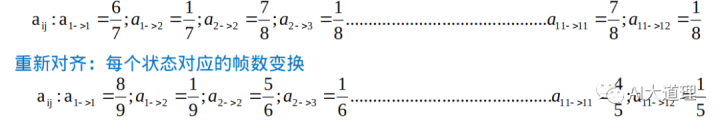
步骤四:迭代
新的A和新的B又可以进行下一次的Viterbi算法,寻找新的最优路径,得到新的对齐,新的对齐继续改变着参数A、B。如此循环迭代直到收敛,则GMM-HMM模型训练完成。
《灵魂的折磨:迭代什么时候结束?
[En]
(torture of the Soul: when does iteration end?
AI大语音:一般是设置固定轮数,也可以看一下对齐之后似然的变化,如果变化不大了,基本就是收敛了。)
3 三音子模型
决策树
考虑音素所在的上下文(context)进行建模,一般的,考虑当前音素的前一个(左边)音素和后一个(右边)音素,称之为三音素,并表示为A-B+C的形式,其中B表示当前音素,A表示B的前一个音素,C表示B的后一个音素。
在用三个音素建模后,引入了一个新的问题:
[En]
After modeling with three phonemes, a new problem is introduced:
- N个音素,则共有N^3 个三音素,若N=100,则建模单元又太多了,每个音素有三个状态,每个状态对应的GMM参数,参数就太多了。
- 数据稀疏问题,有的三音素数据量很少
- unseen data问题。有的三音素在训练数据没有出现,如K-K+K,但识别时却有可能出现,这时如何描述未被训练的三音素及其概率。
所以通常我们会根据数据特征对triphone的状态进行绑定,常见的状态绑定方法有数据驱动聚类和决策树聚类,现在基本上是使用决策树聚类的方式。
三音素GMM-HMM模型是在单音素GMM-HMM模型的基础上训练的。
为什么要先进行单音素GMM-HMM训练?
通过在单音素GMM-HMM模型上viterbi算法得到与输入 对应的最佳状态链,就是得到对齐的结果。
对每个音素的每个state建立一颗属于他们自己的决策树,从而达到状态绑定的目的。
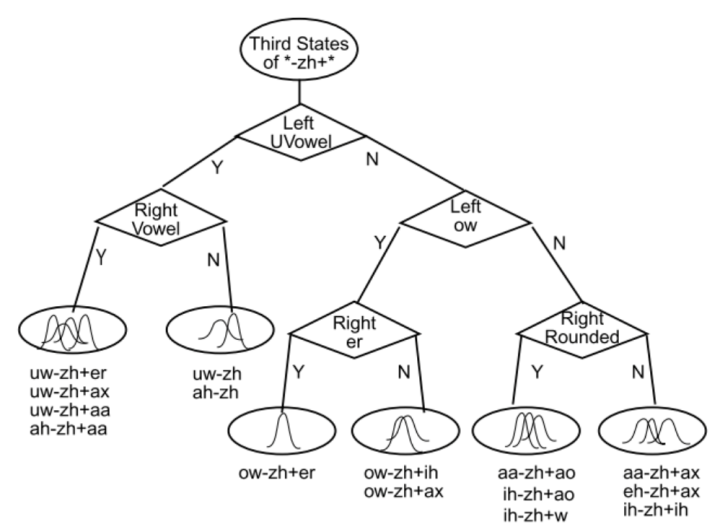
- 从根节点经过一系列问题,相似(高相似度)的三音节到达同一叶节点。
[En]
passing through a series of problems from the root node, the similar (high similarity) triphonemes arrive at the same leaf node.*
- 决策树建立的基本单元是状态,对每个三音子的每个state建立一颗属于他们自己的决策树。
- 每个三音素对于该问题都会有一个Yes或No的的答案,那么对所有的三音素来讲,该问题会把所有三音素分成Yes集合和No集合。
- 根节点是说这是以zh为中心音素的三音素的第三个状态的决策树,第一个状态和第二个状态也都有各自独立的决策树
- 即使zh-zh+zh从未在训练语料中出现过,通过决策树,我们最终将它绑定到一个与之相近的叶子节点上。
通过单音系统,我们可以得到单音素每种状态对应的所有特征集。通过扩展上下文,我们可以得到三个音素每种状态对应的所有特征集。这样,我们就可以将训练数据上所有单音节数据的对齐转化为三个音素的对齐。
[En]
Through the monophone system, we can get all the corresponding feature sets of each state of the single phoneme. By extending the context, we can get all the corresponding feature sets of each state of the three phonemes. In this way, we can change the alignment of all the monosyllabic data on the training data into the alignment of three phonemes.
决策树的生成流程:
- 初始条件(单音素系统对齐,一个根节点)
- 选择当前所有待分裂的节点、计算所有问题的似然增益,选择使似然增益最大的节点和问题对该节点进行分裂。
- 直至算法满足一定条件终止。
4 总结
从单音素GMM-HMM到三音子GMM-HMM的过程就是发现问题,解决当前问题又引入了新问题,再解决新问题的过程。 单音素建模单元少,难以做到精细化建模,识别率不高,单音素发音受上下文影响。 为了优化或者说解决这些问题,引进三音子模型,导致建模单元又太多,所谓过犹不及。同时还出现数据稀疏问题,unseen data问题。 为了解决这些问题,引入带决策树的GMM-HMM模型,解决了上面问题。 为了提高识别率,在三音子GMM-HMM模型基础上,又用DNN模型取代GMM模型,达到了识别率明显的提升。
——————
浅谈则止,细致入微AI大道理
扫描下方”AI大道理”,选择”关注”公众号
–
[En]
–

–
[En]
–
▼下期预告▼
AI大语音(九)——基于GMM-HMM的连续语音识别系统
▼往期精彩回顾▼
AI大语音(一)——语音识别基础
AI大语音(二)——语音预处理
AI大语音(三)——傅里叶变换家族
AI大语音(四)——MFCC特征提取
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(六)——混合高斯模型(GMM)
AI大语音(七)——基于GMM的0-9语音识别系统
Original: https://blog.csdn.net/qq_42734492/article/details/108773933
Author: AI大道理
Title: AI大语音(八)——GMM-HMM声学模型(深度解析)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/526946/
转载文章受原作者版权保护。转载请注明原作者出处!