

Title:END-TO-END CONTEXTUAL SPEECH RECOGNITION USING CLASS LANGUAGE MODELS AND A TOKEN PASSING DECODER
摘要:
自动语音识别(ASR)的端到端建模(E2E)将传统语音识别系统的所有组件融合到一个统一的模型中。尽管它简化了ASR系统,但在训练和测试数据不匹配时很难适应统一模型。在这项工作中,我们专注于上下文语音识别,这对E2E模型尤其具有挑战性,因为上下文信息仅在推理时间可用。为了在训练过程中在存在上下文信息的情况下提高性能,我们建议使用可以在推理过程中填充上下文相关信息的基于类的语言模型(CLM)。为了使这种方法能够扩展到大量的类成员并最大程度地减少搜索错误,我们为E2E系统提出了一种具有有效令牌重组的令牌传递算法。我们评估了针对一般和上下文ASR任务的拟议系统,并在不损害一般ASR任务的识别性能的情况下,将上下文ASR任务的词错误率(WER)降低了62%。我们还表明,所提出的方法在不修改跨任务的解码超参数的情况下表现良好,使其成为端到端ASR的理想解决方案 。
问题:传统的语言模型和相应的解码技术很难整合到E2E系统中。无法利用外部语言模型和词典中的知识尤其会阻碍E2E系统的适应性。 利用外部知识的能力对于上下文语音识别特别重要, 上下文信息可以提供关于用户可能说什么的附加信息,这些信息只能在推理阶段获得。该领域之前的工作受到了上下文复杂性和上下文短语数量的可伸缩性的限制 ,我们建议使用基于类的LM (CLM)来建模上下文特定的信息。 上下文知识是由一个n-gram LM建模的。上下文短语被动态地组合到基于CLM的WFST中。由于WFST是不确定的,如第3.2节所述,每个E2E推断假设都包括WFST中的备选路径。为了处理这些可选路径,我们首次提出了一种具有有效令牌重组的令牌传递解码器。
本文的主要贡献在于第三部分:
[En]
The main contribution of this paper is in the third part:
i)利用CLM解决上下文语音识别和唤醒词问题。
ii)提出了一种用于E2E推理的令牌传递解码器。
第二部分 上下文E2E语音识别
2.1 Attention-based End-to-end Modeling


本文使用基于注意力机制的编码器-解码器模型进行E2E建模。 编码器通常是单向或双向长短时记忆(LSTM)网络,而注意解码器是单向LSTM网络。
2.2 On-the-fly Rescoring with External WFST
上下文自动语音识别(ASR)系统动态地将实时上下文纳入语音识别系统的识别过程。上下文信息的典型示例是个人信息,例如用户的联系人。 方法的一个分支是生成一个动态上下文LM,并将其包含在识别过程中,以使第2.1节中的波束搜索产生偏差。[13] 介绍了浅层融合方法 。
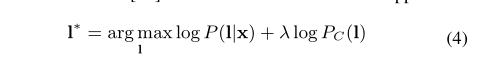
公式4的方法在有限数量的上下文短语中表现出良好的识别性能,但当上下文短语数量超过100个时,识别精度开始下降。一个可能的原因是它遵循了[16]中的WFST搜索思想,只在没有匹配符号的情况下遍历ε弧。这会在单词class中引入严重的搜索错误。我们将研究这个问题,并在第3.2节中提出缓解这个问题的方法。
2.3 Contextual E2E Modeling
另一种尝试将上下文信息集成到E2E建模中的方法称为CLAS[14]。这种技术首先将每个短语嵌入到一个固定的维度表示中,每个短语表示为一系列的字形。然后利用注意机制总结输出预测每一步的可用上下文。通过这种方式,CLAS显式地对看到给定音频和先前标签的特定短语的概率进行建模。为了扩大这一范式的规模并使之得到应用,需要考虑两个基本问题:i)建立大量上下文短语之间的相似性模型。尽管[14]提出了一种条件化机制来减少所考虑的短语数量,但一个更好、更统一的解决方案对于扩大规模非常重要[14]。ii)在AttentionDecoder(·)中的特定步骤限制上下文短语的搜索空间。上述注意机制是通过使用所有短语来实现的,而本文应用的一般CLM[15]只使用与当前预测步骤相关的上下文短语。
第三部分 提出的主要方法
3.1. Class-based Language Model and WFST
这项工作遵循第2.2节中浅层融合的范例和公式。为了解决复杂上下文建模中的可扩展性问题,我们首先使用CLM对模型进行了扩展[15]。CLM指的是在n-gram LM中引入单词等价类。在上下文语音识别中,上下文短语,例如用户最喜欢的歌曲和联系人,可以分组为多个单词等价类(类内)。会话的上下文由n-gram LM(类外)建模。
我们用词等效类(称为@name)以及每个词等效类的上下文短语(Tom Cruise,Lady Gaga)在单独的WFST图中编译n-gram上下文。然后,这些WFST图与” speller” WFST组成[13],以获得字素级WFST。我们将对上下文短语的WFST进行确定操作,以减少令牌的数量,这将在下一部分中讨论。在推论阶段,在WFST类的内部和外部之间进行了一种即时合成的形式[16],而无需对预编译的换能器进行任何更改[18]。图1显示了一个示例。

我们提出的框架还可以改善E2E系统中的唤醒词识别。我们在句子的开头添加一个特殊的单词类,并带有增强因子(关键词增强;根据开发集进行调整)。在推理阶段,唤醒词字素序列被组成类似于上下文短语的词等价类。
3.2. Token Passing Decoder
在[16]中,它假设匹配符号弧的权重总是低于回退弧。由于这个假设,n-gram LM WFST可以被视为确定性的,并且可以使用单个令牌解码器。
由于以下原因,字素级WFST是不确定的:
i)n-gram LM具有退避转换。
ii)两个单词对等类之间的短语重复。
iii)单词对等类和n-gram LM单词之间的短语重复。
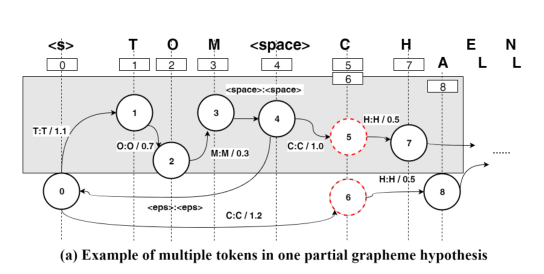
ii)和iii)只是由于动态组成而存在问题,因为我们从未确定整个WFST。图2(a)显示了一个示例。由于不确定的WFST,E2E推断的每个字素假设在WFST中可能具有多个路径。为了应对一个假设的多个令牌,我们在算法1中为E2E系统提出了一种令牌传递解码器,该令牌传递解码器具有高效的令牌重组功能。图2显示了如何在我们的算法中处理令牌的示例。

在算法1中,令牌集
H中的第k个令牌被定义为4元素元组(,,,),而是在等式(3)中的最后预测步骤处的第k解码器隐藏状态,是部分解码的序列;是输出序列为的WFST路径的最后一个状态。注意,如上所述,可能有多个与同一个I相关;是第k部分假设的得分。在每个解码步骤中,我们通过将与每个字素连接来扩展第k个令牌:首先在第9行和第10行中更新和。然后在第12行至第15行中扩展WFST状态:SearchFST(,l)返回所有通过偏离状态并消耗输入符号l可以达到的可能的WFST状态(和相应的成本);新的假设输出可以再次存在多个令牌。第16行提出了TokenRecombination函数,对于每对(,),只需要维护最佳令牌即可;对于相同的部分假设,我们最多只维护令牌。最后,在将所有当前标记扩展为H之后,我们在SelectTopN函数中选择最佳的B部分假设。对于相同的部分假设,我们需要在我们的算法中维护具有不同WFST状态的多个令牌,但其时间复杂度类似于标准波束搜索。对于相同的部分假设,我们需要在我们的算法中维护具有不同WFST状态的多个令牌但是它的时间复杂度类似于稍后讨论的标准波束搜索。与即时记录[13]相比,我们算法的一个重要区别是:
- 多个令牌。在WFST搜索(第12行)中,先前提出的即时记录[16]仅在不存在匹配符号的情况下才穿越ε跃迁。图2(a)显示了一个示例,其中可能会引入搜索错误。对于字素” C”,我们提出的方法将具有对应于状态5和6的两个标记。状态6从退避状态0扩展,可以从状态4遍历。在[13]中,由于状态0而没有遍历状态0 4已经具有与状态5匹配的弧线。这导致不探索状态6,从而引入了可能的搜索错误。在这项工作中,我们建议使用令牌传递方法从端到端推理为每个假设保留多个令牌。

所提方法不会改变端到端推理中标准波束搜索的计算复杂度。标准E2E推论的复杂度为
= O(B·L·D)+ O(F),其中B是假设的波束大小,L是序列的长度,D是E2E的解码器神经网络的复杂度,F是E2E的编码器神经网络的复杂度。令牌通过解码不会改变E2E推理中的波束搜索。令牌通过解码的复杂度为 = O(B·L··U),其中是每个假设中的WFST令牌束,U是字素的大小。由于D·U,我们有 +≈。
- RELATION TO PRIOR WORK
在E2E语音识别的推理阶段,诸如[20、21、22、23、10、24]之类的先前工作使用n-gram LM或NNLM来偏置搜索空间。在上下文E2E语音识别中,由于训练和测试话语之间的不匹配,因此整合外部知识资源以提高WER更为重要。 [13]提出使用动态组成的外部上下文LM来偏置E2E推理的波束搜索。方法的另一分支[14]尝试对给定音频和先前标签的情况下看到特定上下文短语的概率进行建模。该领域的现有工作在上下文复杂性和上下文短语数量方面都受到有限的可扩展性的困扰。这项工作的优点包括:i)通过使用CLM更好地概括复杂上下文。 ii)通过在1遍解码中重组使用多个令牌来分别保持E2E和WFST状态,从而减少搜索错误。
5. EXPERIMENTS
5.1. Setup
数据是在群众派遣工人的帮助下收集的。这些工人被要求写话说他们可以向AI助手求助。每种话语都可以属于一般性语音,也可以属于许多可能的领域之一。我们有1千万种话语用于培训。通用ASR测试集的大小为6万,而上下文ASR测试集的大小为1万。为了为上下文ASR测试集生成CLM的可能成员,我们首先从话语中提取真实实体,然后添加999个相同类型的伪实体。上下文ASR测试集的每个发音在开头都有唤醒词。
在训练中,以10ms的帧速率提取40维fiterbank特征。使用基于Espnet [26]的PyTorch [25]构建了带有字素单元的E2E模型。具有1400个节点的2层BLSTM用于编码器,具有700个节点的2层LSTM用于解码器。该模型通过连接者时间分类(CTC)和E2E标准进行了优化[19]。我们的n-gram LM是经过30万个单词的词汇训练的3 gram LM。对于B(假设波束大小)和
(WFST令牌波束大小),我们都使用10。字错误率(WER)用作评估指标。
5.2. Performance Comparison
我们比较了上下文ASR测试集和通用ASR测试集的E2E系统性能。表1中的每一行中,用于两个测试集的解码超参数均相同。第一行显示了在E2E系统中未使用任何LM的实验。通用ASR测试集的WER为5.9,而上下文ASR测试的WER为34。上下文语音识别的难度源于:i)训练集中缺乏唤醒词建模。这既影响了唤醒词的识别,也影响了其余词的历史模型。 ii)训练话语中缺少上下文短语。

第二行显示了针对E2E系统的外部3克LM的实验。由提出的令牌传递解码器执行解码。对于一般的ASR任务,WER从5.9%提高到5.6%。对于上下文ASR任务,WER从35.1%提高到31.4%。外部n-gram LM对通用ASR的改进与[23]中的结果一致。我们没有研究NNLM,因为这项工作的主要目的是改善上下文ASR。上下文ASR任务的改进来自3.1节末尾讨论的增强唤醒字。然而,仅仅提高唤醒词的分数只能帮助识别唤醒词,不能解决剩余词的历史状态不匹配的问题。对于相同的n-gram LM,使用交叉熵准则训练的传统LSTM-HMM系统在常规ASR测试集上获得5.6%的WER。
如第3.1节所述,n-gram LM可以轻松地与基于CLM的范例集成。提议的基于CLM的令牌传递解码器的说明在第三行中。对于通用ASR测试集,它的性能与n-gram LM相似,但是对于上下文ASR测试集,则实现了显着的改进(从31.4%到13.5%WER)。这些改进来自于1)使用CLM建模上下文,以及2)通过令牌传递解码器减少搜索错误。我们将在下一节中进行更多分析。 CLM在适应性方面也很出色,与一般ASR测试集的n-gram LM的可比结果表明。
5.3. Analysis
我们首先展示了与基于浅层融合[13]的系统相比所提出的方法的有效性。以前的基于浅层融合的系统的Btok(WFST令牌的光束大小)的值基本上为1。图3显示了WER与Btok之间的关系。如果
小于5,则系统的性能会明显下降7,这与[14]中使用1K短语以上的性能下降相一致。这显示了在WFST波束中使用多个令牌的重要性。

在图4中,我们显示了扩大上下文短语数量的实验。尽管增加上下文短语的数量会降低WER,但我们仍然可以接受最多5K短语的WER,这对于大多数实际应用而言是可以接受的。在大约8K短语之后,系统崩溃。

最后,当我们调整超参数以改善上下文ASR时,我们将展示对一般ASR的WER的影响。图5中的曲线大部分是平滑的,这表明一般的ASR性能对上下文ASR性能不敏感,反之亦然。

6. CONCLUSION
在这项工作中,我们建议(a)使用CLM通过(b)令牌传递解码器进行端到端推理来解决上下文语音识别。上下文ASR的结果实现了一致且显着的改进。未来的工作包括可扩展到大量上下文短语并结合NNLM [27,28]。
Original: https://blog.csdn.net/weixin_43587572/article/details/114637095
Author: 郑郑yay
Title: 基于类语言模型和令牌传递解码器的端到端上下文语音识别(论文翻译)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/526942/
转载文章受原作者版权保护。转载请注明原作者出处!