

这一周在kaldi下跑thchs30例程,做了些笔记,记录一下(黑体字是要运行的命令,实际上是从run.sh分离出来的)
如果自行下载语料的话,推荐一个openslr的镜像网址,速度快很多
http://openslr.magicdatatech.com/18/
因为服务器里有thchs30语料了,在/data/ASR/data_537h/路径下,直接将其解压到s5:
tar zxvf /data/ASR/data_537h/data_thchs30.tgz -C /work/kaldi/egs/thchs30/s5/thchs30
tar zxvf /data/ASR/data_537h/resource.tgz -C /work/kaldi/egs/thchs30/s5/thchs30
tar zxvf /data/ASR/data_537h/test-noise.tgz -C /work/kaldi/egs/thchs30/s5/thchs30
cmd.sh:运行配置目录,并行执行命令,通常分 run.pl, queue.pl 两种,运行环境,不 同的并行处理方案要调用不同的脚本
我们首先需要配置是在单机还是在Oracle GridEngine集群上训练,这可以通过cmd.sh 来配置。如果我们没有GridEngine(通常没有),那么需要把所有的queue.pl改成run.pl。
queue.ql: gridengine:多机运行,queue.pl为kaldi调用的gridengine,是一种多cpu (gpu)的一种并行处理的方案;run.ql: 本地多进程。
path.sh:环境变量相关脚本(kaldi公用的全局PATH变量的设置)
接下来逐行执行run.sh:
. ./cmd.sh# sh cmd.sh,因为是逐行运行,所以terminal一旦重启,记得再运行一遍
. ./path.sh
H=pwd#exp home
n=8#parallel jobs 原则上要小于0.7物理cpu数单cpu核数
thchs=/work/kaldi/egs/thchs30/s5/thchs30(根据解压路径修改)
local/thchs-30_data_prep.sh $H $thchs/data_thchs30 || exit 1
data preparation
generate text, wav.scp, utt2pk, spk2utt
上条命令处理后得到六个文件(在data/{train,dev,test}下都有):


wav.scp,每条语音的 ID 及其存储路径:

text(与word文件相同),每条语音的 ID 及其对应的词级别标注文本:

phone,每条语音的 ID 及其对应的音素级别标注文本:

utt2spk,每条语音的 ID 及其说话人 ID:

spk2utt,每个说话人的 ID 及其所有语音ID:

produce MFCC features 计算mfcc特征
rm -rf data/mfcc && mkdir -p data/mfcc && cp -R data/{train,dev,test,test_phone} data/mfcc || exit 1;
拷贝data下的四个文件夹到data/mfcc

for x in train dev test; do
make mfcc 正片开始
steps/make_mfcc.sh –nj $n –cmd “$train_cmd” data/mfcc/$x exp/make_mfcc/$x mfcc/$x || exit 1;
不知为何有三个参数,打开脚本进行查看

显然参数一是输入,二是log存储路径,三是存放mfcc结果的路径
compute cmvn
steps/data/mfcc/$x exp/mfcc_cmvn/$x mfcc/$x || exit 1;
done
CMVN(Cepstral Mean and Variance Normalization,倒谱均值方差归一化),该方法旨在提高声学特征对说话人、录音设备、环境、音量等因素的鲁棒性。 在实际情况下,受不同麦克风及音频通道的影响,会导致相同音素的特征差别比较大,通过CMVN可以得到均值为0,方差为1的标准特征。 “.ark”(archive,存档文件)和 “.scp”(script,前者的索引文件)格式同步存在,终将所有索引文件合并放入 feats.scp 和 cmvn.scp,(按理cmvn_train.ark文件也应该有8个,有点诧异,待会具体讲)

不清楚为何train索引只到8,故查看脚本:

make_mfcc脚本中默认nj是4,但run.sh中n=8(运行过了),这个nj代表parallel jobs
并行任务数,所以每个raw_mfcc_trainx.ark中不仅含有一段语音,所以scp索引很有#必要:

红框内数字代表ark文件中的偏移量,以字节为单位,并非转为txt后的”行”
/work/kaldi/src/featbin/copy-feats ark:mfcc/train/raw_mfcc_train.1.ark ark,t:1.txt
/work/kaldi/src/featbin/copy-feats ark:mfcc/train/cmvn_train.ark ark,t:2.txt
将ark转成txt,cat分别查看1.txt、2.txt,可以看到在1.txt中每段语音都对应一个二维矩阵,13列代表13维的特征向量

这儿回答上边遗留的一个问题,结合compute_cmvn_stats.sh的注释

cmvn_train.ark ark中每个矩阵的标识是说话者id,说明倒谱均值方差归一化的对象并非每句语音,而是每个说话人,可以看到每个说话者对应28维向量,其中前13维为所有帧(该说话者的所有语音)的均值,后13维为所有帧的方差,最后两维表示该说话者的总帧数,在后续训练过程中,所有特征按照说话人索引到对应的均值方差,再进行真正的cmvn(目前只是提取了cvmn的均值和方差而已,特征并未变化,这省去很多空间),因为按照说话人来划分的话,数据会小很多,也就不需要并行任务(即n=1),所以就只生成一个文件。
有一个问题,我们能不能直接提取所有帧的均值和方差?
[En]
There is a question, can we directly extract the mean and variance of all frames?
解决了,因为后续有做说话人自适应,操作对象就是每个说话人,所以此时最后按每个说话人来做cmvn,前后统一,保证特征对于各个说话人都是比较鲜明的。
copy feats and cmvn to test.phone, avoid duplicated mfcc & cmvn
cp data/mfcc/test/feats.scp data/mfcc/test_phone && cp data/mfcc/test/cmvn.scp data/mfcc/test_phone || exit 1;
prepare language stuff 和我上周的HCLG实验中数据准备(语言相关数据)一致,红字是即将生成的文件
build a large lexicon that invovles words in both the training and decoding.
(
echo “make word graph …”
*cd $H; mkdir -p data/{dict,lang,graph} && *
*cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict && *
*cat $thchs/resource/dict/lexicon.txt $thchs/data_thchs30/lm_word/lexicon.txt | *
grep -v ‘~~’ | grep -v ‘~~’ | sort -u > data/dict/lexicon.txt || exit 1;
utils/prepare_lang.sh –position_dependent_phones false data/dict “
gzip -c $thchs/data_thchs30/lm_word/word.3gram.lm > data/graph/word.3gram.lm.gz || exit 1; #转成gz格式便于format_lm
utils/format_lm.sh data/lang data/graph/word.3gram.lm.gz $thchs/data_thchs30/lm_word/lexicon.txt data/graph/lang || exit 1;
)


fstprint –isymbols=data/graph/lang/phones.txt –osymbols= data/graph/lang/words.txt data/graph/lang/L.fst
可视化失败,仍未找到原因,提示words.txt头部错误,不知道是不是这个#的问题,不过不影响后续的流程。


#make_phone_graph与word_graph类似,不过他的word.txt仍是音素,如下图:
(
echo “make phone graph …”
*cd $H; mkdir -p data/{dict_phone,graph_phone,lang_phone} && *
*cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict_phone && *
cat $thchs/data_thchs30/lm_phone/lexicon.txt | grep -v ‘
echo “
utils/prepare_lang.sh –position_dependent_phones false data/dict_phone “
gzip -c $thchs/data_thchs30/lm_phone/phone.3gram.lm > data/graph_phone/phone.3gram.lm.gz || exit 1;
*utils/format_lm.sh data/lang_phone data/graph_phone/phone.3gram.lm.gz $thchs/data_thchs30/lm_phone/lexicon.txt *
data/graph_phone/lang || exit 1;
)

monophone 训练单音素模型
steps/train_mono.sh –boost-silence 1.25 –nj $n –cmd “$train_cmd” data/mfcc/train data/lang exp/mono || exit 1;
steps/train_mono.sh: 单音素建模脚本,用来训练单音素模型,主要输出为final.mdl和tree。训练的核心流程就是迭代对齐-统计算GMM与HMM信息-更新参数,命令格式如下:
steps/train_mono.sh [options]
training-data-dir 是提前准备好的训练数据的路径。
lang-dir 是包含所有语言模型文件目录的路径,也可以提前准备。
expr-dir是训练存储其所有输出的路径。如果它不存在,它将被创建。
boost_silence在对齐时可以提高静音段的似然性( Factor by which to boost silence likelihoods in alignment)。默认为1.0
将mono其转为txt格式进行可视化:
gmm-copy –binary=false exp/mono/final.mdl final_txt.mdl

这和HTK生成的HMM模型不一样,HTK中以音素为单位进行状态描述,如下:

Kaldi这么处理的原因是为了生成WFST形式的状态网络,接下来对final.mdl进行分析:
是整个HMM的结构和初始参数(0.mdl和40.mdl这一部分的参数均相同)
共有656个,乍一看以为是三音子,其实表示transition-state(HCLG中的状态)

经过理解后,做了如下笔记(这儿有点错误,实际上要把pdf改成pdfclass):

LogProbs是和transition-id对应起来的,描述了转移概率,共有1321个数(18+3*217+1),其中的1表示初始转移概率,ln(100%)=0,就是矩阵的第一个数

说明这儿输入的MFCC特征为39维(13维加上一阶、二阶差分),需要求656个状态的概率密度函数,后续的一些值就是记录这656个状态具体的GMM描述的概率密度函数。
GMM包含以下参数:分量权重weights_,均值means_,方差vars_,不过为了方便计算,在里面记录了每一分量多维高斯分布里的常量部分取log后的数值gconsts_,方差每一元素求倒数后的inv_vars_、均值乘以inv_vars_后的means_invvars_。
每个transition-state的GMM中高斯函数个数不同,比如state1的weight数组大小为4.代表高斯函数个数为4,对应
文件里共描述656个GMM,刚好对应656个transition-state

此时,每个状态中的每个过渡圆弧都有一个相应值。
[En]
At this point, each transition arc in each state has a corresponding value.
实验进行到这,解决了上周一个疑问,就是相邻状态的transition-id未必需要递增,因为模型不是单按这个id去存储数值,还需要关联了hmmstate和phone,例如下图:这两个索引虽然id值一样,但是他所处的state不同,还是会被分别赋值的。

test monophone model
local/thchs-30_decode.sh –mono true –nj $n “steps/decode.sh” exp/mono data/mfcc &
在exp/mono下生成了decode_test_word和decode_test_phone两个文件夹,用于存放测试结果

decode_test_word下的wer开头文件即一次识别结果,至于为何从7到17,暂时存疑,网上说是声学模型的scale(比例),还有文件名的结尾0/0.5/1代表的penalty(难道是语言模型的比例?)

打开wer_10_1.0:
其中总语音(句子)数为2495,总词数为81139,词错误率WER(deletion、insertion,substitution)为51.58%,且没有完全识别正确的句子

查看最低的wer,等于50.89%:

copy-tree –binary=false exp/mono/tree tree.txt
draw-tree data/graph/lang/phones.txt exp/mono/tree | dot -Tsvg -o monotree.svg
可视化初始的mono决策树,可以看到每个音素的每个状态(pdfclass=state)直接对应一个独有的pdf,不共享:

monophone_ali
steps/align_si.sh –boost-silence 1.25 –nj $n –cmd “$train_cmd” data/mfcc/train data/lang exp/mono exp/mono_ali || exit 1;
copy-int-vector “ark:gunzip -c exp/mono_ali/ali.7.gz|” ark,t:ali7.txt
可视化对齐文件,如图,每一段语音都会有状态对齐序列,可以看到索引超出了transition-state的最大值656,所以这是对齐到transition-id,我们最终解码网络的输入也是transition-id,前后一致:

triphone
steps/train_deltas.sh –boost-silence 1.25 –cmd “$train_cmd” 2000 10000 data/mfcc/train data/lang exp/mono_ali exp/tri1 || exit 1;
steps/train_deltas.sh
num-leaves是叶子节点数目(要大于总pdf数:不考虑共享的话为656*3),tot-gauss是总高斯数目,data-dir是数据文件夹,lang-dir是存放语言的文件夹,alignment-dir是存放之前单音素对齐后结果的文件夹,exp-dir是存放三音子模型结果的文件夹。
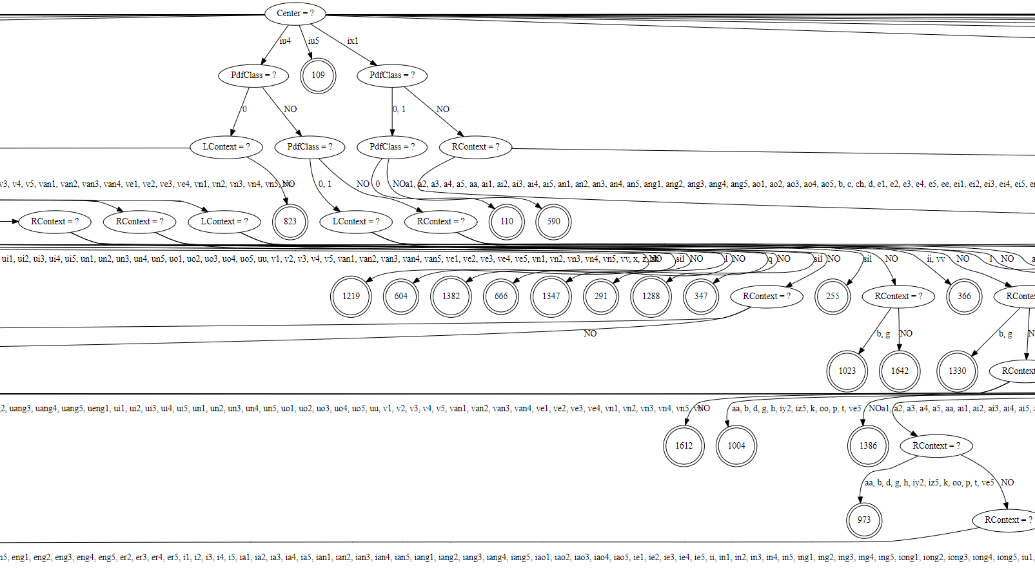
可视化tri1的决策树
draw-tree data/graph/lang/phones.txt exp/tri1/tree | dot -Tsvg -o tri1tree.svg
每个音素的每个状态会根据决策树(判断左右因素)绑定到一个pdf,实现pdf共享
test tri1 model
local/thchs-30_decode.sh –nj $n “steps/decode.sh” exp/tri1 data/mfcc &
运用三音子模型的best_wer降低到36.08%:

triphone_ali
steps/align_si.sh –nj $n –cmd “$train_cmd” data/mfcc/train data/lang exp/tri1 exp/tri1_ali || exit 1;
lda_mllt
steps/train_lda_mllt.sh –cmd “$train_cmd” –splice-opts “–left-context=3 –right-context=3” 2500 15000 data/mfcc/train data/lang exp/tri1_ali exp/tri2b || exit 1;
LDA线性判别分析(Linear Discriminant Analysis)它是一种监督学习的降维技术,也就是说它是有类别输出的。LDA的核心思想为投影后类内方差最小,类间的方差最大。简单来说就是同类的数据集聚集的紧一点,不同类的离得远一点。LDA+MLLR,使用Linear Discriminant Analysis(LDA)和Maximum Likelihood Linear Regression(MLLR)技术对声学特征进行线性变换,再根据新的特征来训练三音子模型,使其对不同音素更加具有区分性
该程序的执行流程为:
1.估计出LDA变换矩阵M,特征经过LDA转换。
2.用转换后的特征重新训练GMM。
3.计算MLLT的统计量。
4.更新MLLT矩阵T。
5.更新模型的均值μjm←Tμjm。
6.更新转换矩阵M←TM。
test tri2b model
local/thchs-30_decode.sh –nj $n “steps/decode.sh” exp/tri2b data/mfcc &
特征做lda_mllt变换后,模型best_wer降低到32.27%:

lda_mllt_ali 输入是ali对齐文件,根据它做特征的变换
steps/align_si.sh –nj $n –cmd “$train_cmd” –use-graphs true data/mfcc/train data/lang exp/tri2b exp/tri2b_ali || exit 1;
sat
steps/train_sat.sh –cmd “$train_cmd” 2500 15000 data/mfcc/train data/lang exp/tri2b_ali exp/tri3b || exit 1;
SAT,说话人自适应训练(Speaker Adaptive Training),具体采用了fMLLR(feature space MLLR)方法,目的是提高语音识别系统的说话人无关性,也是做特征变换。
补充:
自适应的作用是,补偿实际数据与已经训练的三音素模型中声学条件不匹配的问题,包括说话人特性(说话方式、口音等)及环境特性(如录音设备、房间混响等)。在GMM-HMM模型中,自适应方法有特征空间变换和模型空间变换。Kaldi中主要采用的是特征空间变换方法:LDA、MLLT和fMLLR,其本质都是 在训练过程中估计变换矩阵,然后构造变换后的特征,再迭代训练新的声学模型参数。LDA+MLLT针对环境特性,拼接上下文多帧数据,再通过特征变换进行降维处理,因为与说话人无关,所以估计的是全局矩阵。fMLLR针对说话人特性,基于每个说话人进行变换矩阵估计。在DNN-HMM模型中,由于DNN的鉴别特性,GMM下的自适应方法不能直接拿来用,DNN下的自适应方法主要有线性变换、正则项法、子空间法(i-vector)。
test tri3b model
local/thchs-30_decode.sh –nj $n “steps/decode_fmllr.sh” exp/tri3b data/mfcc &
特征做sat变换后,模型best_wer降低到29.48%:

sat_ali
steps/align_fmllr.sh –nj $n –cmd “$train_cmd” data/mfcc/train data/lang exp/tri3b exp/tri3b_ali || exit 1;
quick
steps/train_quick.sh –cmd “$train_cmd” 4200 40000 data/mfcc/train data/lang exp/tri3b_ali exp/tri4b || exit 1;
进行quick训练,train_quick.sh 用来在现有特征上再训练一个模型,且基于之前的模型做初始化。
test tri4b model
local/thchs-30_decode.sh –nj $n “steps/decode_fmllr.sh” exp/tri4b data/mfcc &
quick训练后,模型best_wer降低到27.92%:

quick_ali
steps/align_fmllr.sh –nj $n –cmd “$train_cmd” data/mfcc/train data/lang exp/tri4b exp/tri4b_ali || exit 1;
quick_ali_cv 训练出两个对齐文件,估计是增加数据,提高接下来训练中的dnn的泛化能力
steps/align_fmllr.sh –nj $n –cmd “$train_cmd” data/mfcc/dev data/lang exp/tri4b exp/tri4b_ali_cv || exit 1;
train dnn model
local/nnet/run_dnn.sh –stage 0 –nj $n exp/tri4b exp/tri4b_ali exp/tri4b_ali_cv || exit 1;
利用对齐的标签数据进行典型的DNN分类器训练,将GMM-HMM 中计算发射概率的 GMM 替换为 DNN。
众所周知,DNN的输入是fbank,故脚本中调用了make_fbank.sh,生成如下文件:

查看run_dnn.sh得到DNN的参数:四层,每层1024个神经元,学习率0.008,且训练完毕后会更新解码网络并进行decode测试,输出文件路径为exp/tri4b_dnn


补充:语音识别系统的最终衡量标准是 WER,是序列(Sequence)上的尺度上,而 GMM 以最大似然为目标,DNN 以最小化交叉熵(Cross Entropy,CE) 或均方误差(Mean Squared Error,MSE)等为损失函数,二者训练时的目标都在帧的尺度上,这会造成训练与推断(Reference)的不一致, 所以可以引入更靠近序列层面的训练准则,也就是序列判别训练(Sequence-Discriminative Training,SDT), 常用的准则有: MMI(Maximum Mutual Information)和 BMMI(Boosted MMI), MPE(Minimum Phone Error), sMBR(state Minimum Bayes Risk)。 SDT 始用于 GMM-HMM,后来移植到 DNN-HMM 上, Bookmark: discriminative training & decoding 使用了 MMI,由于模型本身结构不变,只改变了训练的准则,解码方式仍与之前相同。
简而言之,dnn训练不只是最小化交叉熵,使得输入特征简单地和对齐文件ali里地标签一致即可,更要考虑到系统根据这个结果解码后的序列错误率,将层面直接提升。
dnn-hmm模型下的best_wer降低到23.62%,音素级图下的best_wer降低至10.19%:


流程总结:
首先是录音相关数据的准备,然后依此提取mfcc 特征(存储13 维),并做cvmn ,存储每个说话人的均值、方差和帧数(注意在训练过程中才会根据这些参数做归一化的特征并且差分扩展到39 维);接着是语言相关数据的准备,并依此做词图(make word graph ),即构建解码网络(只缺H.fst ),那么缺啥补啥,接着要做HMM 训练,首先是单音素模型monophone ,其次三音素训练tri1 ,特征做lda_mllt 变换训练得到trib2 ,再进行sat 说话人适应得到trib3 ,再做quick 训练得trib4 ,根据两个对齐文件tri4b_ali 和tri4b_ali_cv 训练dnn,用于取代原发射概率的表征模型GMM ,得到tri4b_dnn ,上述所有得到的模型都可以做解码测试(decode ),事实上也对每个模型都进行了识别评分。
感悟:
dnn-hmm训练也太久了吧哈哈哈哈哈,总之这周收获很多,理论变现后大有感慨,学习这些模型的同时,也佩服人类的智慧!
感谢批评指正!
参考文章:
https://zhuanlan.zhihu.com/p/245167122
http://antkillerfarm.github.io/ai/2018/06/04/kaldi.html
kaldi入门详解–aishell步骤解释_ferb的语音识别学习小站-CSDN博客
Kaldi学习笔记(四)–thchs30中文在线识别_snowdroptulip的博客-CSDN博客
kaldi中文语音识别_基于thchs30(5)_dqxiaoxiao的博客-CSDN博客
Original: https://blog.csdn.net/qq_16324149/article/details/108814963
Author: 语音识别菜鸟
Title: 语音识别实践、Kaldi下跑清华30小时例程(thchs30)笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/526815/
转载文章受原作者版权保护。转载请注明原作者出处!