

orangepi 4B利用python3使用snowboy实现语音唤醒以及使用腾讯AI api实现语音识别、回复以及合成
- 一个月来经历无数个坑,终于完成教程,整理不易,转载请注明出处,谢谢
- 准备工作
* - 基本知识与储备
- 硬件方面准备
– - 软件方面准备
– - 正式开始操作
* - 登录以及环境配置
– - python3安装及snowboy编译
– - 利用腾讯AI api完成语音识别,回复,以及语音合成
– - 测试snowboy以及修改demo
– - 后续延伸
* - 语音控制智能机器人
- 语音控制家庭智能家居中心
在过去的一个月里,经历了无数的坑,我终于完成了教程,整理起来并不容易。请注明转载的来源。谢谢。
[En]
After going through countless pits in the past month, I finally completed the tutorial, and it is not easy to sort it out. Please indicate the source of the reprint. Thank you.
准备工作
基本知识与储备
1.python基本语法、模块库的调用、常用模块熟练调用
2.Linux环境的使用,熟悉apt,pip,git下载,python3环境配置
3.一颗能坚持下来的耐心
4.遇到问题能主动去找百度,而不是放弃
硬件方面准备
准备材料
一张16Gclass10SD卡、一个USB2.0或3.0的读卡器、一个orangepi4B主板、一个USB麦克风(淘宝10块还包邮那种)、一个支持AUX音响(没有可以用耳机代替)、一个支持HDMI的显示器、一个键盘、一个鼠标以及一个USB扩展坞
下面是我准备的SD卡以及读卡器


; 镜像下载地址
我使用的是香橙派官方ubuntu-npu镜像地址:香橙派官网.
选择下载用户手册和原理图在文件中找到这个文件OrangePi_4_ubuntu_bionic_desktop_linux4.4.179_npu_v1.3.tar.gz
也可以直接在这个链接下载: https://pan.baidu.com/s/17549ZGbNTLuJANoiJAA7JQ 提取码: sja5
同时下载官方工具包找到Win32DiskImager以及SDFormatter或者百度自行下载
; 镜像安装方法
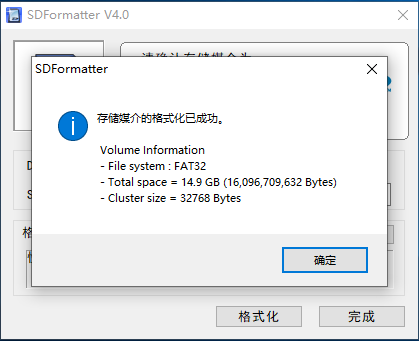
首先使用SDFormatter将SD卡格式化(这里请备份好自己的数据)

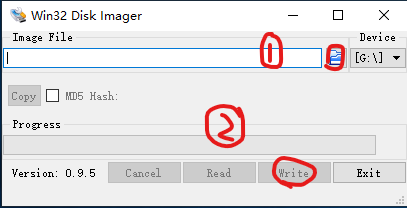
接下来使用Win32DiskImager写入镜像到SD卡
打开LX终端
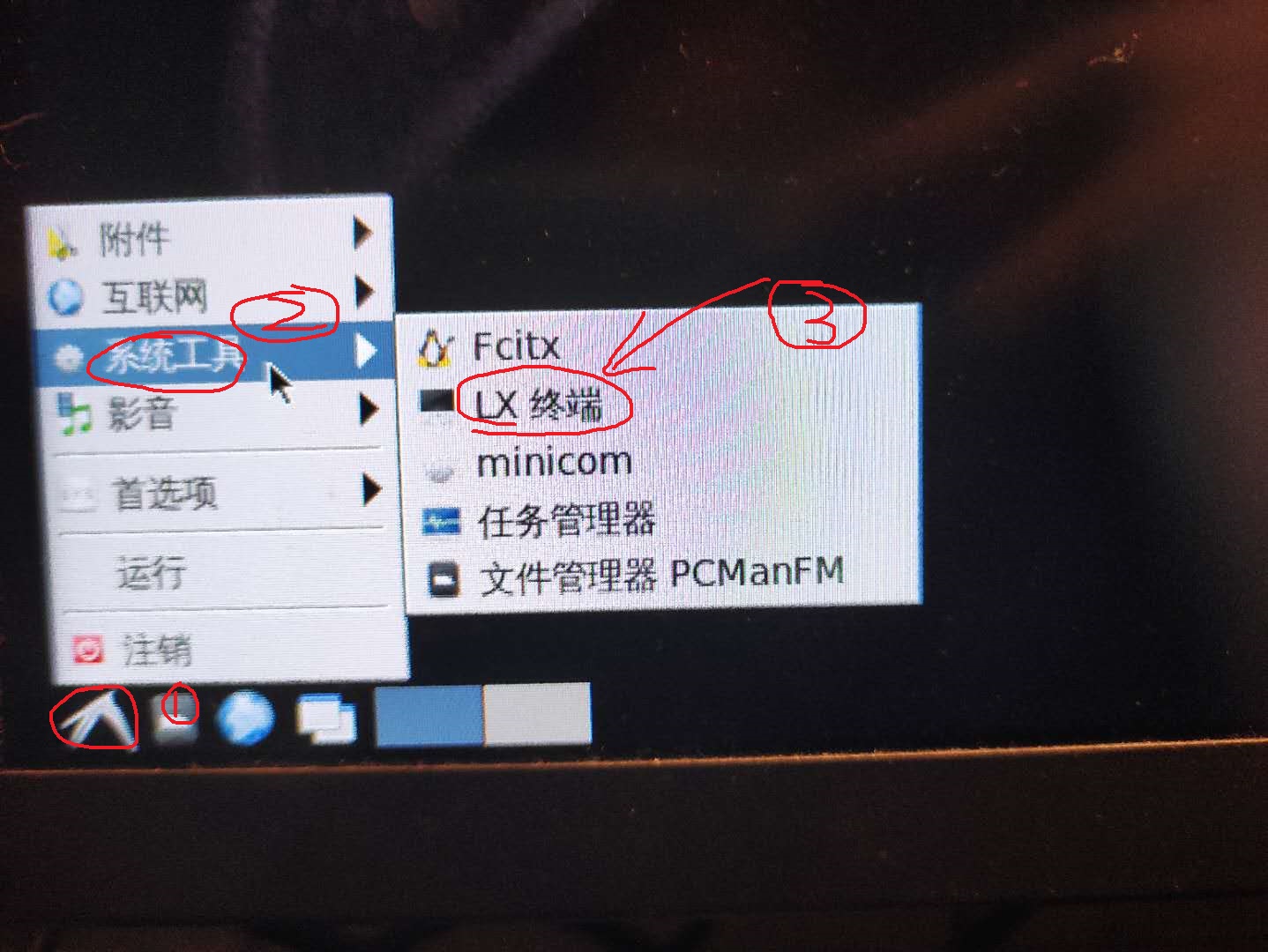
使用install_to_emmc命令将镜像烧录至emmc(期间会提示输入一次Y)
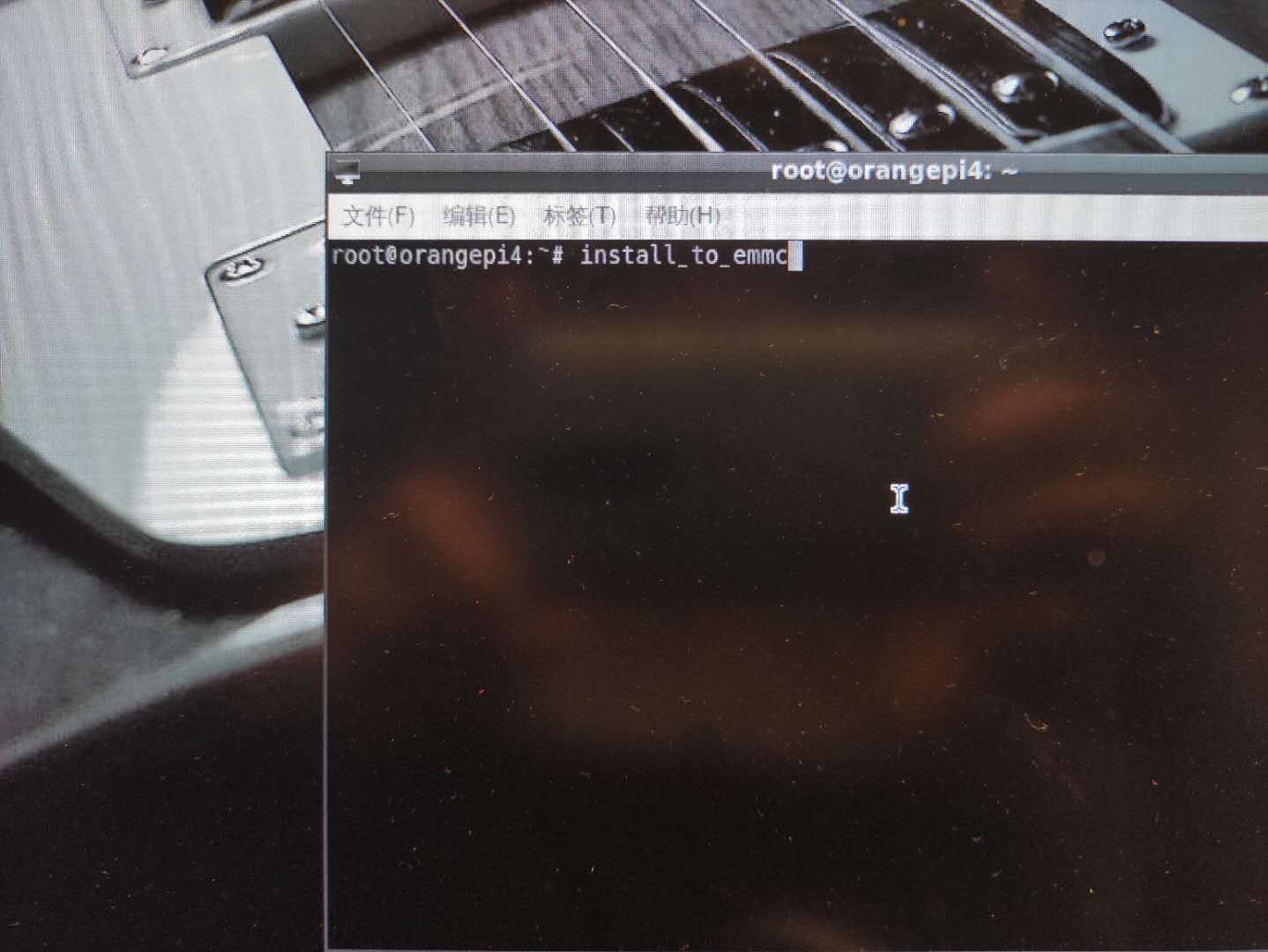
提示烧录完成执行reboot命令重启香橙派,同时拔出SD卡
至此,图像刻录和准备工作已经完成。
[En]
At this point, the image burning and preparation work have been completed.
软件方面准备
腾讯AI开放平台注册开发者
很简单,百度里面有很多,大家也可以自己去探索,这里就不重复了。
[En]
It’s very simple, Baidu has a lot of it, and you can also explore it yourself, so I won’t repeat it here.
仔细查看开发文档以及完成应用创建
正式开始操作
登录以及环境配置
切换中文环境以及安装中文输入法
打开LX终端执行sudo apt-get install ttf-wqy-zenhei安装中文字库
执行sudo apt-get install fcitx fcitx-googlepinyin fcitx-module-cloudpinyin fcitx-sunpinyin
安装中文输入法
然后重新启动,可以看到输入法安装完成(中英文切换为)
[En]
Then restart and you can see that the installation of the input method is complete (the switch between Chinese and English is)
时区设置与中文支持
在LX终端设置上海时间
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
中文环境设置, 打开终端, 输入以下命令
sudo dpkg-reconfigure locales
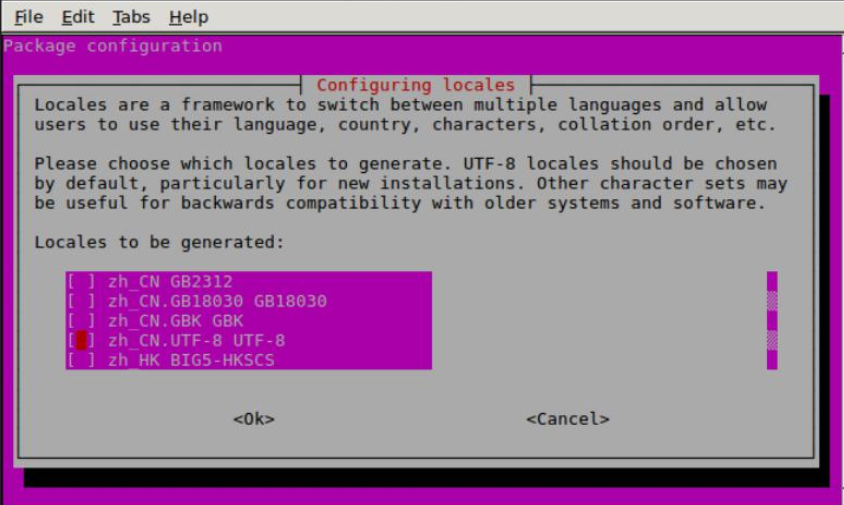
然后往下找(键盘-按下键) , 在较后面, 找到 en_US.UTF-8 UTF-8,zh_CN.UTF-8 UTF-8,zh_CN.GBK GBK 如上图所示,按空格选中, 按回车确定。
然后来到如下界面, 选择 zh_CN.UTF-8, 确定, 按下回车键。
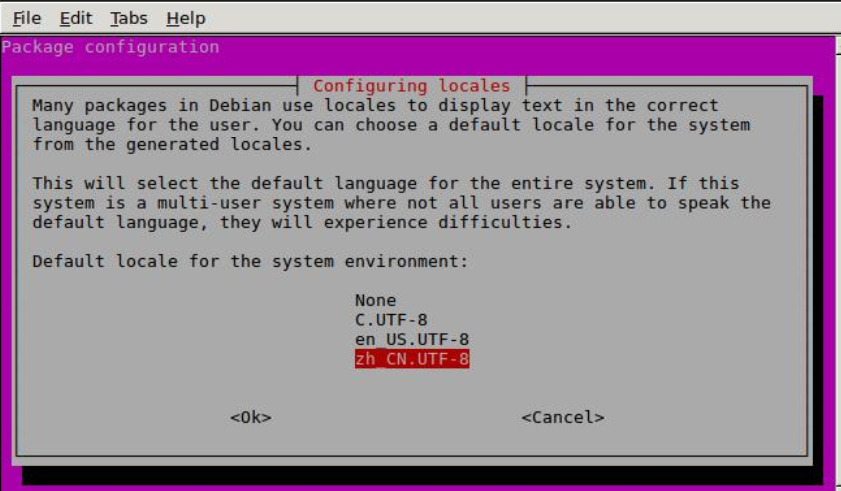
出现如下信息, 配置完成,重启系统即可。

; python3安装及snowboy编译
安装python3以及pip3
终端执行
sudo apt-get install python3 python3-pip3
安装portaudio、pyaudio以及其他python3的支持包(重点,不安装无法使用pyaudio,更无法使用语音识别)
终端执行
sudo apt-get install portaudio19-dev python-all-dev python3-all-dev jackd1 portaudio19-doc jack-tools meterbridge liblo-dev
sudo apt-get install pyaudio
安装swig以及ATLAS依赖
终端执行
sudo apt-get install swig
sudo apt-get install libatlas-base-dev
获取snowboySDK以及snowboy的编译(注:4B需要修改的地方是重点否则无法完成编译)
终端执行
git clone https://github.com/Kitt-AI/snowboy.git
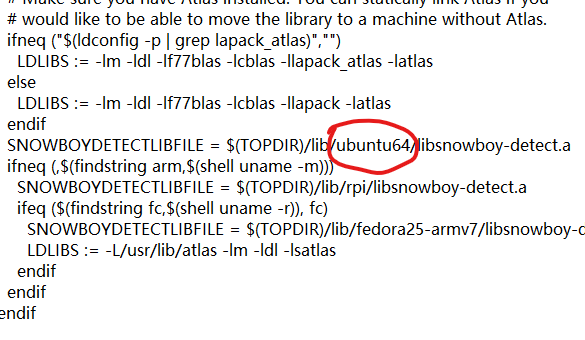
需要修改的地方①在snowboy/swig/Python3中的makefile
找到下图中位置将ubuntu64替换为aarch64-ubuntu1604
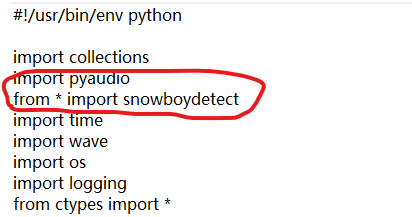
地方②在snowboy/examples/Python3中的snowboydecoder.py文件
将from * import snowboydetect 修改为import snowboydetect
在snowboy/swig/Python3文件夹打开终端执行make
至此snowboy编译完成。
利用腾讯AI api完成语音识别,回复,以及语音合成
用到的python模块以及参数设置
import base64
import json
import operator
import random
import time
import wave
from urllib import parse
import hashlib
import snowboydecoder
import signal
from contextlib import contextmanager
import requests
from pyaudio import PyAudio, paInt16
CHUNK = 1024 # wav文件是由若干个CHUNK组成的,CHUNK我们就理解成数据包或者数据片段。
FORMAT = paInt16 # 表示我们使用量化位数 64位来进行录音
CHANNELS = 1 # 代表的是声道,1是单声道,2是双声道。
RATE = 16000 # 采样率 一秒内对声音信号的采集次数,常用的有8kHz, 16kHz, 32kHz, 48kHz,11.025kHz, 22.05kHz, 44.1kHz。
RECORD_SECONDS = 5 # 录制时间这里设定了5秒
app_id = '你的appid' # 从开发者平台得到
appkey = '你的appkey ' # 从开发者平台得到
用来生成需要位数的随机字符
def roda(num):
a = ''
for i in range(0, num):
a = a + random.choice('abcdefghijklmnopqrstuvwxyz123456789')
return a
接口鉴权编写
官方解释
用于计算签名的参数可能会因接口而异,但算法过程固定为以下四个步骤。
[En]
The parameters used to calculate the signature may vary from interface to interface, but the algorithm process is fixed in the following four steps.
1…将
def sortDict(data):
return dict(sorted(data.items(), key=operator.itemgetter(0), reverse=False))
def getReqSign(params, appkey):
# 1. 字典升序排序
params1=sortDict(params)
# 2. 拼按URL键值对
str1 = parse.urlencode(params1)
# 3. 拼接app_key
str1 = str1 + '&' + 'app_key=' + appkey
# 4. MD5运算并转换大写,返回请求签名
m = hashlib.md5()
m.update(str1.encode())
str_md5 = m.hexdigest()
return str_md5.upper()
利用wave模块保存录音
def save_wave_file(pa, filename, data):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(pa.get_sample_size(paInt16))
wf.setframerate(16000)
print(type(data))
wf.writeframes(b"".join(data))
wf.close()
使用pyaudio录音
def get_audio(filepath): # 录音实现
print("请开始说话:") # 提示文本
pa = PyAudio()
stream = pa.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK)
print("*" * 10, "开始录音:请在5秒内输入语音")
frames = [] # 定义一个列表
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 循环,采样率 44100 / 1024 * 5
data = stream.read(CHUNK) # 读取chunk个字节 保存到data中
frames.append(data) # 向列表frames中添加数据data吃
print("*" * 10, "录音结束\n")
stream.stop_stream()
stream.close() # 关闭
pa.terminate() # 终结
save_wave_file(pa, filepath, frames)
使用pyaudio播放
def play(fname):
ding_wav = wave.open(fname, 'rb')
ding_data = ding_wav.readframes(ding_wav.getnframes())
with no_alsa_error():
audio = PyAudio()
stream_out = audio.open(
format=audio.get_format_from_width(ding_wav.getsampwidth()),
channels=ding_wav.getnchannels(),
rate=ding_wav.getframerate(), input=False, output=True)
stream_out.start_stream()
stream_out.write(ding_data)
time.sleep(0.2)
stream_out.stop_stream()
stream_out.close()
audio.terminate()
语音识别
1.请求参数
参数名称是否必选数据类型数据约束示例数据描述app_id是int正整数1000001应用标识(AppId)time_stamp是int正整数1493468759请求时间戳(秒级)nonce_str是string非空且长度上限32字节fa577ce340859f9fe随机字符串sign是string非空且长度固定32字节签名信息,详见接口鉴权format 是int正整数2语音压缩格式编码,定义见下文描述speech是string语音数据的Base64编码,非空且长度上限8MB待识别语音(时长上限15s)rate否int正整数16000语音采样率编码,定义见下文描述,(不传)默认即16KHz
语音压缩格式编码
格式名称格式编码PCM1WAV2AMR3SILK4
语音采样率编码
采样率编码8KHz800016KHz16000
2. 响应参数
参数名称是否必选数据类型描述ret是int返回码; 0表示成功,非0表示出错msg是string返回信息;ret非0时表示出错时错误原因data是object返回数据;ret为0时有意义+ format是intAPI请求中的格式编码+ rate是intAPI请求中的采样率编码+ text是string语音识别结果(UTF-8编码)
编写示例
def get_text():
get_audio('ceshi.wav') # 录音
fwave = open('ceshi.wav', mode='rb').read() # 打开录音文件
base64Wav = base64.b64encode(fwave).decode('utf8') # 进行编码(腾讯api要求base64编码)
params = {'app_id': app_id,
'format': '2',
'rate': '16000',
'speech': base64Wav, # base64编码的语音数据
'time_stamp': int(time.time()), # 时间戳
'nonce_str': roda(10)}
params['sign'] = getReqSign(params, appkey) # 得到接口鉴权
# print(params)
url = 'https://api.ai.qq.com/fcgi-bin/aai/aai_asr'
resp = requests.post(url, params) # post请求
return json.loads(resp.text).get('data').get('text') #返回识别到的文本
得到回答
1. 请求参数
参数名称是否必选数据类型数据约束示例数据描述app_id是int正整数1000001应用标识(AppId)time_stamp是int正整数1493468759请求时间戳(秒级)nonce_str是string非空且长度上限32字节fa577ce340859f9fe随机字符串sign是string非空且长度固定32字节签名信息,详见接口鉴权session是stringUTF-8编码,非空且长度上限32字节10000会话标识(应用内唯一)question是stringUTF-8编码,非空且长度上限300字节你叫啥用户输入的聊天内容
2. 响应参数
参数名称是否必选数据类型描述ret是int返回码; 0表示成功,非0表示出错msg是string返回信息;ret非0时表示出错时错误原因data是object返回数据;ret为0时有意义session是stringUTF-8编码,非空且长度上限32字节answer是stringUTF-8编码,非空
编写示例
def get_chat_text(text): # 得到回答
paramsd = {
'app_id': app_id,
'session': '10000',
'question': text, # 问题文本
'time_stamp': int(time.time()),
'nonce_str': roda(17),
}
paramsd['sign'] = getReqSign(paramsd, appkey)
urld = 'https://api.ai.qq.com/fcgi-bin/nlp/nlp_textchat'
respd = requests.post(urld, paramsd)
return json.loads(respd.text).get('data').get('answer') # 返回回答文本
语音合成
1. 请求参数
参数名称是否必选数据类型数据约束示例数据描述app_id是int正整数1000001应用标识(AppId)time_stamp是int正整数1493468759请求时间戳(秒级)nonce_str是string非空且长度上限32字节fa577ce340859f9fe随机字符串sign是string非空且长度固定32字节签名信息,详见接口鉴权speaker是int正整数1语音发音人编码,定义见下文描述format是int正整数2合成语音格式编码,定义见下文描述volume是int[-10, 10]0合成语音音量,取值范围[-10, 10],如-10表示音量相对默认值小10dB,0表示默认音量,10表示音量相对默认值大10dBspeed是int[50, 200]100合成语音语速,默认100text是stringUTF-8编码,非空且长度上限150字节腾讯,你好!待合成文本aht是int[-24, 24]0合成语音降低/升高半音个数,即改变音高,默认0apc是int[0, 100]58控制频谱翘曲的程度,改变说话人的音色,默认58
语音发音人编码
发音人编码普通话男声1静琪女声5欢馨女声6碧萱女声7
合成语音格式编码
格式名称编码PCM1WAV2MP33
2. 响应参数
参数名称是否必选数据类型描述ret是int返回码;msg是string返回信息;ret非0时表示出错时错误原因data是object返回数据;ret为0时有意义+ format是intAPI请求中的格式编码+ speech是string合成语音的base64编码数据+ md5sum是string合成语音的md5摘要(base64编码之前)
base64解码及写入文件
def ToFile(voicex, file):
base64_data = voicex
ori_image_data = base64.b64decode(base64_data)
fout = open(file, 'wb')
fout.write(ori_image_data)
fout.close()
编写示例
def get_voice(text):
test = {
'app_id': app_id,
'speaker': '6',
'format': '2',
'volume': '0',
'speed': '100',
'text': text,
'aht': '0',
'apc': '58',
'time_stamp': int(time.time()),
'nonce_str': roda(17),
}
test['sign'] = getReqSign(test, appkey)
url2 = 'https://api.ai.qq.com/fcgi-bin/aai/aai_tts'
resp2 = requests.post(url2, test)
voicex=json.loads(resp2.text).get('data').get('speech')
ToFile(str(voicex), 'audio.txt')
ToFile(voicex, 'audio.mp3')
return 'audio.mp3'
测试snowboy以及修改demo
测试snowboy热词唤醒功能
终端打开目录 snowboy/examples/Python3
cd snowboy/examples/Python3
开始运行,喊一声snowboy就可以听到叮的一声
python3 demo.py resources/models/snowboy.umdl
修改Demo
interrupted = False
def signal_handler(signal, frame):
global interrupted
interrupted = True
def interrupt_callback():
global interrupted
return interrupted
回调函数,这里实现语音识别,修改也在这里。<details><summary>*<font color='gray'>[En]</font>*</summary>*<font color='gray'>Callback function, speech recognition is implemented here, and modification is also here.</font>*</details>
def callbacks():
global detector
time.sleep(0.2)
your_text=['哎,我在,你说','我来啦,我来啦,我来啦~','我是你的语音助手小贝']
a=random.randint(1,3)
print('小贝'+your_text[a])
play('huda/xiaobeihuida'+ str(a) +'.wav') # 为唤醒词事先准备好的回答
time.sleep(0.2)
try:
a = get_text()
if a =='嗯' or '':
continue
print('你:'+a)
b =get_chat_text(a)
print('小贝:'+b)
c = get_voice(b)
play(c)
except Exception:
print('exception happened...')
@contextmanager
def no_alsa_error():
try:
asound = cdll.LoadLibrary('libasound.so')
asound.snd_lib_error_set_handler(c_error_handler)
yield
asound.snd_lib_error_set_handler(None)
except:
yield
pass
def wake_up():
global detector
model = 'xiaobeixiaobei.pmdl' # 我的唤醒词为 小贝小贝
# 终止方法为ctrl+c
signal.signal(signal.SIGINT, signal_handler)
# 唤醒词检测函数,调整sensitivity参数可修改唤醒词检测的准确性
detector = snowboydecoder.HotwordDetector(model, sensitivity=0.5)
print('正在聆听... 请说唤醒词:小贝小贝')
# main loop
# 回调函数 detected_callback=snowboydecoder.play_audio_file
# 修改回调函数可实现我们想要的功能
detector.start(detected_callback=callbacks, # 自定义回调函数
interrupt_check=interrupt_callback,
sleep_time=0.03)
# 释放资源
detector.terminate()
#程序入口
if __name__ == "__main__":
wake_up()
后续延伸
通过修改回调函数可以完成更多工作
[En]
More work can be done by modifying the callback function
语音控制智能机器人
与arduino使用uart通信可实现智能控制机器人
等待后续更新
已经更新传送门
语音控制家庭智能家居中心
加入mqtt可以作为语音控制家庭智能家居中心
等待后续更新
Original: https://blog.csdn.net/q310139033/article/details/108873825
Author: q310139033
Title: orangepi 4B利用python3使用snowboy实现语音唤醒以及使用腾讯AI api实现语音识别、回复以及合成
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/526811/
转载文章受原作者版权保护。转载请注明原作者出处!