

第十章 隐马尔可夫模型(HMM)
- 摘要
- 隐马尔可夫模型的基本概念
* - 前言
- 生成模型和判别模型
- 马尔可夫过程
- 马尔可夫链
- 马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型的三个问题
* - 第一 概率计算
- 第二 学习问题
- 第三 预测问题
- 参考文献
摘要
隐马尔可夫模型(HMM)是可用于标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于 生成模型。隐马尔可夫模型在语音识别、自然语言处理、生物信息、模式识别等领域有着广泛的应用。
隐马尔可夫模型的基本概念
[En]
The basic concept of Hidden Markov Model
前言
隐马尔可夫模型(HMM)与回归、分类等处理相互独立的样本数据模型不同,用于处理时间序列数据,即隐马尔可夫模型用于处理样本之间有时间序列关系的数据。HMM和卡尔曼滤波算法的本质是一样的,区别在于HMM要假设隐藏变量是离散的,而卡尔曼滤波假设隐藏变量是连续的。隐藏变量是HMM中的关键概念,可以理解为无法直接观测到的变量。与隐变量相对的是观测变量,即可以直接观测到的变量。HMM的能力在于能够根据给出的观测变量序列,估计对应的隐藏变量序列是什么,并对未来的观测变量做预测。
比如语音识别,给你一段音频数据,需要识别出该音频数据对应的文字。这里音频数据就是观测变量,文字就是隐藏变量。我们知道,对单个文字而言,虽然在不同语境下有轻微变音,但大致发音是有统计规律的。另一方面,当我们说出一句话时,文字与文字之间也是有一些转移规律的。比如,当我们说出”比”这个字时,下一个大概率的字一般是”如””较”等。虽然文字千千万,但文字与文字之间的转移却是有章可循的。有了文字的发音特征,以及文字与文字之间的转移规律,那么从一段音频中推测出对应的文字也就可以一试了。插一句,在当前深度学习一统江湖的时代,已经很少有人还在用HMM做语音识别了。
如何判断一个问题是否适合使用HMM解决?
- 给定一组数据,您需要推断与其对应的另一组数据。例如,音频数据和字符序列是已知数据,对应的文本是需要推断的数据。
[En]
given a set of data, you need to infer another set of data corresponding to it. For example, audio data and character sequences are known data, and the corresponding text is data that needs to be inferred.*
- 要推断的数据是离散的,如语音识别中的文本,而对观测数据没有要求,可以是离散的,也可以是连续的。
[En]
the data to be inferred is discrete, such as text in speech recognition, while there is no requirement for observed data, which can be either discrete or continuous.*
- 对输入数据的顺序敏感,如音频数据和字符序列,如果打乱它们的顺序,结果将完全不同。对秩序敏感并不是一件坏事。秩序就是信息,只有有信息才能进行推理。
[En]
sensitive to the order of input data, such as audio data and character sequences, if you disrupt their order, the results will be completely different. Being sensitive to order is not a bad thing. Order is information, and inference can only be made if there is information.*
生成模型和判别模型
监督学习的任务就是学习一个模型,应用这一模型,对给定的输入预测相应的输出。这个模型的一般形式为决策函数Y = f ( x ) Y=f(x)Y =f (x )或者条件概率分布:P ( Y ∣ X ) P(Y|X)P (Y ∣X )。
监督学习方法可以分为生成方法(generative approach)和判别方法(discriminative approach),所学到的模型分别称为生成模型(generative model)和判别模型(discriminative model)。
生成方法由数据学习联合概率分布P ( X , Y ) P(X,Y)P (X ,Y ),然后求出条件概率分布P ( X ∣ Y ) P(X|Y)P (X ∣Y )作为预测的模型,即生成模型:P ( Y ∣ X ) = P ( X , Y ) P ( X ) P(Y|X)={{P(X,Y)}\over{P(X)}}P (Y ∣X )=P (X )P (X ,Y )这样的方法之所以称为生成方法,是因为模型表示了给定输入X产生Y的生成关系。典型的生成模型有朴素贝叶斯法和隐马尔可夫模型。
判别方法由数据直接学习决策函数f ( x ) f(x)f (x )或者条件概率分布P ( Y ∣ X ) P(Y|X)P (Y ∣X )作为预测的模型,即判别模型。判别方法关心的是对给定的输入X,应该预测什么样的输出Y。典型的判别模型包括:K近邻法、感知机、决策树、逻辑斯蒂回归模型、最大熵模型、支持向量机、提升方法和条件随机场等。
生成方法的特点生成方法可以还原出联合概率分布P ( X , Y ) P(X,Y)P (X ,Y ),而判别方法则不能。生成方法的学习收敛速度更快,当样本容量增加的时候,学到的模型可以更快的收敛于真实模型。当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用。
根据判别法的特点,判别法直接学习条件概率或决策函数。直接面对预测,学习的准确率往往更高。由于直接学习条件概率分布或决策函数,可以对数据进行不同程度的抽象、定义和使用,从而简化了学习问题。
[En]
The characteristic of the discriminant method the discriminant method directly learns the conditional probability or decision function. Facing the prediction directly, the accuracy of learning is often higher. Because learning the conditional probability distribution or decision function directly, the data can be abstracted, defined and used in various degrees, so the learning problem can be simplified.
马尔可夫过程
一种状态转换的随机过程,其中下一状态的概率仅与当前状态相关。
[En]
A random process of state transition in which the probability of the next state is only related to the current state.
马尔可夫链
时间过程和状态过程的值是离散的。
[En]
The values of time and state processes are discrete.
马尔可夫模型


; 隐马尔可夫模型
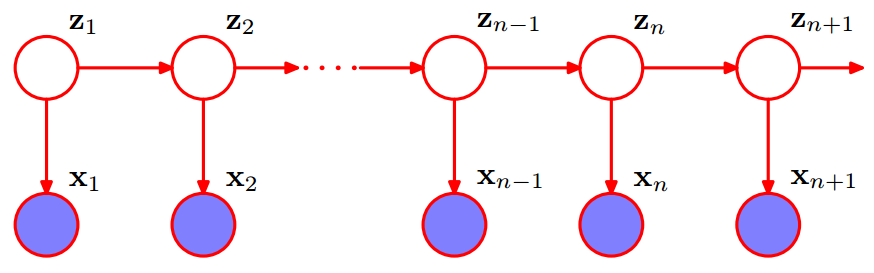
隐马尔可夫模型是一种关于时间序列的概率模型,它描述了从隐马尔可夫链中随机产生不可观测的随机状态序列,然后从每个状态产生一个观测值,从而产生一个随机观测值序列的过程。
[En]
Hidden Markov model is a probabilistic model about time series, which describes the process of randomly generating unobservable random sequence of states from a hidden Markov chain, and then generating an observation from each state, thus generating a random sequence of observations.
隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。序列的每一个位置又可以看作是一个时刻。
隐马尔可夫模型由初始状态概率向量π \pi π、状态转移概率矩阵A A A和观测概率矩阵B B B决定。π \pi π和A A A决定状态序列,B B B决定观测序列。因此,隐马尔可夫模型λ \lambda λ可以用三元符号表示,即:λ = ( A , B , π ) \lambda=(A,B,\pi)λ=(A ,B ,π).A:状态转移矩阵,B:观测概率矩阵,π \pi π初始状态概率。
状态转移概率矩阵A A A与初始状态概率向量π \pi π确定了隐藏的马尔可夫链,生成不可观测的状态序列。观测概率矩阵B B B确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
关于隐马尔可夫模型的三个问题
[En]
Three problems of Hidden Markov Model
第一 概率计算
前向算法、后向算法
第二 学习问题
极大似然估计、EM算法
第三 预测问题
维比特算法
参考文献
- https://zhuanlan.zhihu.com/p/32655097
- https://zhuanlan.zhihu.com/p/27907806
Original: https://blog.csdn.net/qq_40507857/article/details/109518753
Author: 紫芝
Title: 机器学习理论《统计学习方法》学习笔记:第十章 隐马尔可夫模型(HMM)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/526393/
转载文章受原作者版权保护。转载请注明原作者出处!