

语音信号处理
写作原因
知道了语音信号需要采样率和采样位数,知道了MFCC提取的整个流程,但是中间的幅值变化的细枝末节还是需要细究的,比如:
- matlab/python读取wav文件默认是浮点数,但是保存是整数?
- 调整音频幅度后,MFCC如何变化?
因为它是备忘录的属性,所以文本是口语化的,也就是废话很多,焦点模糊。
[En]
Because it is the attribute of the memo, the text is colloquial, that is, there is a lot of nonsense and the focus is vague.
wav文件读取
wav格式
- 标头;
- 第一块:通道数、采样率等信息
[En]
first block: information such as number of channels, sampling rate, etc.*
- 第二块:数据,按小端顺序存储。
[En]
the second block: data, stored in small end order.*
内容以区块(chunk)为最小单位,每一区块长度为4字节 ,从这可以看出,数据是 整数 还是 浮点数 ,取决于读取的方式。
读取wav文件(matlab/python)
养成读 matlab源代码的习惯:
open function_name
matlab audioread()
audioread(filename, range, datatype)
前两项不做解释。仅关注数据读出类型时,使用 AUDIOREAD(FILENAME, DATATYPE),当 DATATYPE='double'时,读出的数据为范围为 0.0~1.0的浮点数;当 DATATYPE='native'时,读出的数据是 采样位数 范围内的整数。
当不加 DATATYPE参数时,读出的数据是浮点数。
% [Y, FS]=AUDIOREAD(FILENAME, DATATYPE) specifies the data type format of
% Y used to represent samples read from the file.
% If DATATYPE='double', Y contains double-precision normalized samples.
% If DATATYPE='native', Y contains samples in the native data type
% found in the file. Interpretation of DATATYPE is case-insensitive and
% partial matching is supported.
% If omitted, DATATYPE='double'.
python
python读wav文件的方式很多,librosa默认是读成浮点数的,待查证。
写入wav文件(matlab/python)
matlab audiowrite()
audiowrite(filename,y,Fs,varargin)
保存语音数据时,不需要指定数据类型。数据类型信息被包括在数据中。基于该功能的评论如下:
[En]
When saving voice data, you do not need to specify the data type. The data type information is included in the data. The comments based on the function are as follows:
% Data Type of Y Valid Range for Y
% -----------------------------------
% uint8 0
所以如果想用整数保存数据时,一定要先将数据转为目标格式。比如 class(ones(1, 16000))查看数据类型, ones默认生成 double数据,给它乘上大于1的整型数据,得出的结果依然是 double类型,直接保存wav文件时,大于 1.0的部分被截断,得不到想要的结果。
python
待补充。
audition查看语音幅值
调出 振幅统计 窗口
导航栏 -> 窗口 -> 振幅统计


audition的振幅统计计算如最下面的小字所示,参考的国际电联推荐标准《ITU-R BS.1770-3》。
MFCC
教材上已经有许多MFCC特征提取的步骤了,回过神来,尽是《信号与系统》的基础知识。所以难怪都默认大家能够推导出来吗,真是一段艰难的路程。
还有,不觉得最后这个 C系数很难理解吗?每次教材里给出一堆三角形的Mel banks后,直接DCT然后就得出个系数,通常是一串向量/一个矩阵,真的很难理解。
看matlab一步一步计算,发现一个Mel bank对一帧频谱只得出一个结果,为什么是这样?然后刚才突然想到了:一帧频谱中,对每个刻度的频率只有一个系数来表示,那么一个Mel bank对应的就是一个刻度的频率,所以这个bank的系数就代表了能量,n 个Mel bank得出n个能量系数。所以多帧Mel bank的系数,就叫做Mel 频谱。
至于DCT系数,它对应的应该是傅里叶变换中的那个e − j ω n e^{-j \omega n }e −j ωn(写的是连续傅里叶变换的符号,不过都差不多啦),也就是它的n越多,恢复的信号和原信号的差别越小。
把一帧数目可能是512、1024、2048的频谱变成最多13个的mel频谱,再变回n个DCT系数的信号,语音真是大大压缩了啊。
话说偶尔也能想通这些事情,但是很快就会忘记,重复这样的循环,这次记下来应该就不会忘了吧。另外,突然卷积神经网络!每个卷积层,可以自行设定卷积核的数目,一个卷积核是3维的,宽、高和输入特征层的通道数。普通卷积,首先每个卷积核的通道和对应的特征通道进行计算,然后所有通道相加的结果,作为这个通道的输出。而深度可分离卷积中的depthwise层,只有 一个 卷积核,且每个通道与特征通道计算,但是最后 没有相加 。
与语音幅值的变化关系
参考赵力《语音信号处理实验教程》 C3_4_y_4.m相关程序。
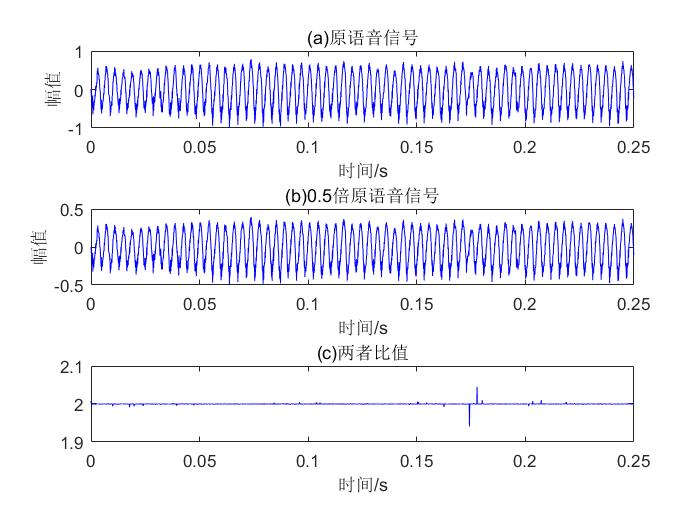
语音信号幅值比较
原语音简单乘以 0.5,用以比较。
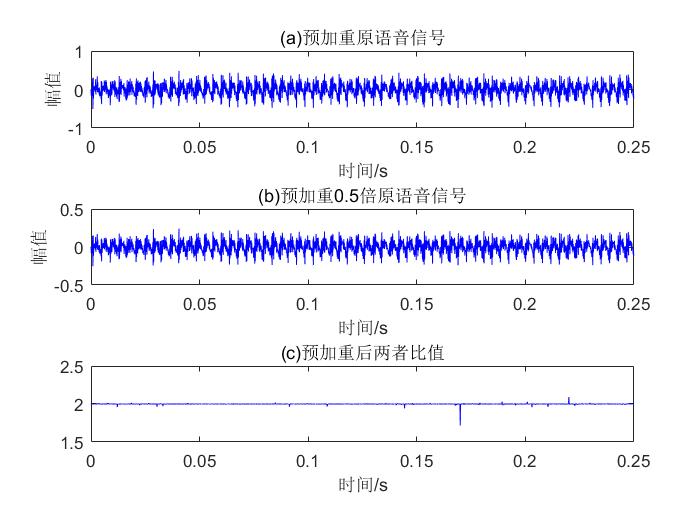
; 预加重
% 预加重滤波器
xx=double(x);
xx=filter([1 -0.9375],1,xx);
如果滤波器只在频域工作,难道不会减少时间域的信号量吗?虽然说增加了高频成分,但低频成分呢?
[En]
If the filter only works in the frequency domain, won’t the semaphore in the time domain be reduced? Although it is said to increase the high-frequency component, but what about the low-frequency component?
好了!我在一篇硕士毕业论文中看到,预加重的目的是增强高频部分,平坦化信号的频谱,使其保持在从低频到高频的整个频段,并在相同信噪比下计算频谱进行频谱分析。
[En]
! I saw in a master’s graduation thesis that the purpose of pre-emphasis is to enhance the high frequency part, flatten the frequency spectrum of the signal, keep it in the whole frequency band from low frequency to high frequency, and calculate the spectrum with the same signal-to-noise ratio for spectrum analysis.
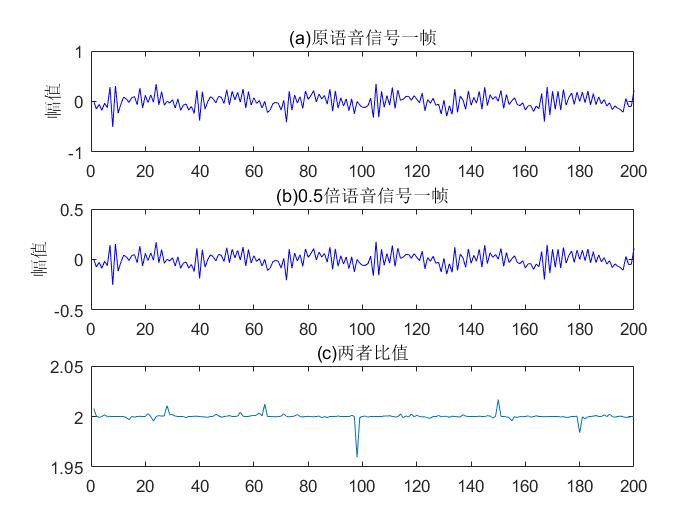
分帧
对输入数据的第一帧进行处理,并绘制一张图片来显示它。
[En]
Process the first frame of the input data and draw a picture to show it.
; 一帧MFCC特征提取
% fft后频谱对称,所以只取一半
n2=fix(frameSize/2)+1;
% 计算每帧的MFCC参数
for i=1:size(xx,1)
y = xx(i,:);
s = y' .* hamming(frameSize);
t = abs(fft(s));
t = t.^2;
c1=dctcoef * log(bank * t(1:n2));
c2 = c1.*w';
m(i,:)=c2';
end
每一步都将按照本程序进行绘制。
[En]
Each step will be plotted according to this procedure.
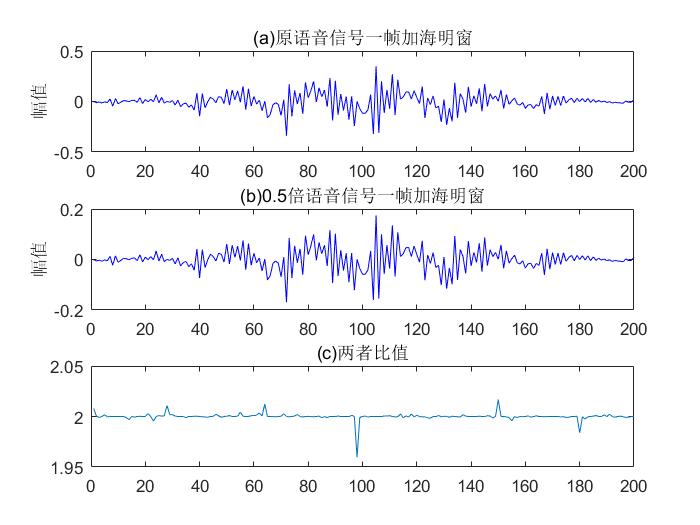
加海明窗
; 频谱取绝对值且平方
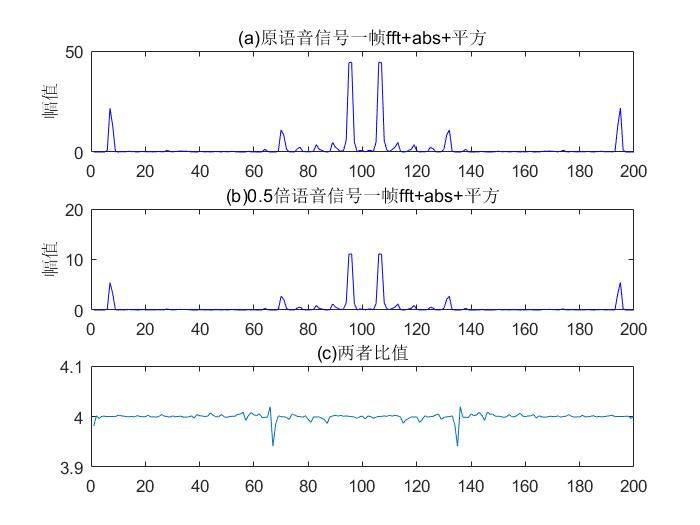
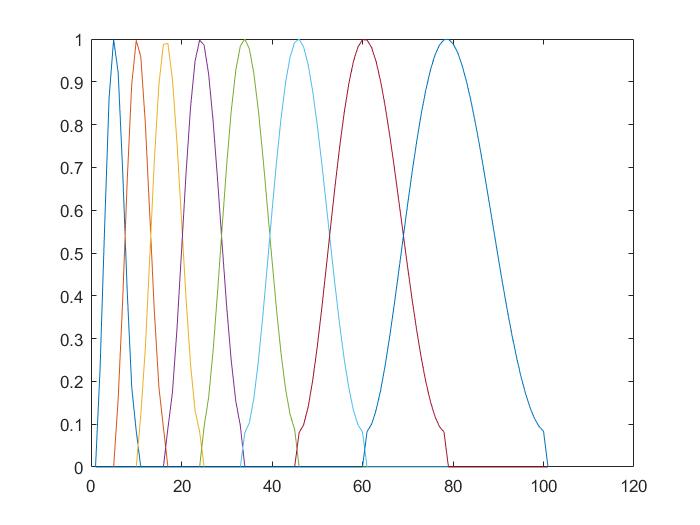
通过mel滤波器得到mel频谱
- 8个不同颜色绘制的mel滤波器
它看起来不像一个三角形,也许程序不使用三角形。
[En]
It doesn’t look like a triangle, maybe the program doesn’t use a triangle.
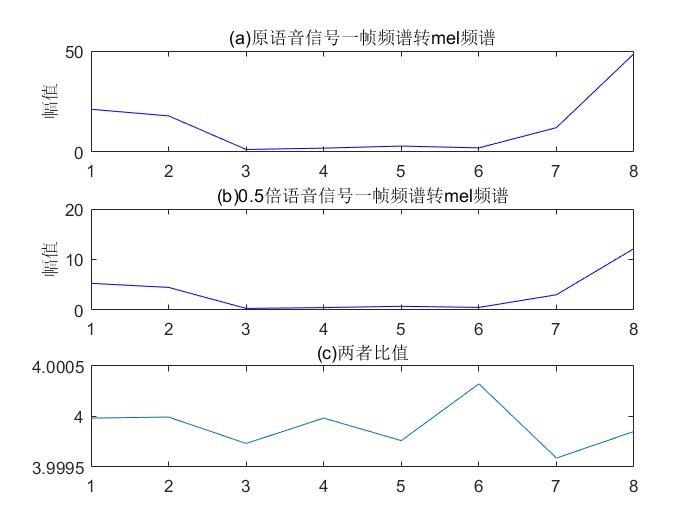
- 新生成的频谱系数
这是针对每个过滤器的,并且只生成一个系数值(为什么?)
[En]
This is for each filter, and only one coefficient value is generated (why? ).
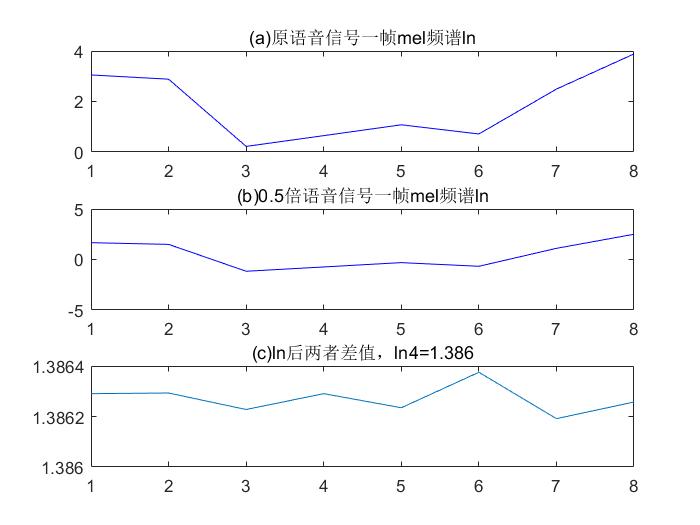
; mel系数log化
matlab里用的都是 log,但其实是 ln
DCT倒谱
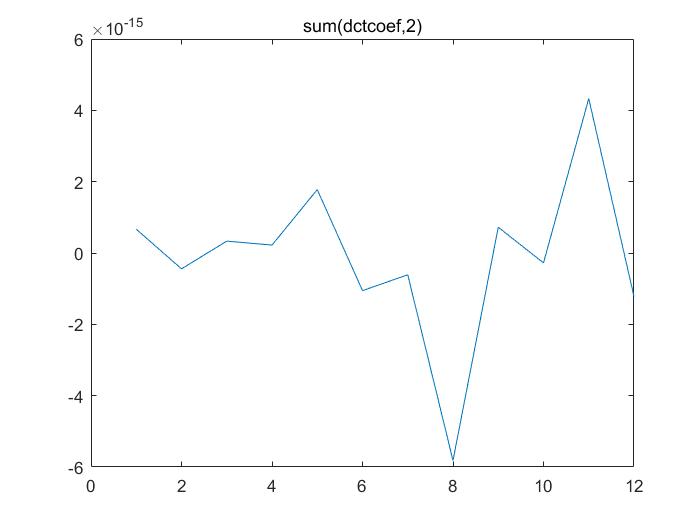
首先看一下DCT系数的样子,因为想输出12个MFCC系数,所以DCT有12行。显示的是第12行。
按行去对12行DCT系数相加,最后得到的结果都是约为0,所以!
d c t c o e f ∗ l o g _ s p e e c h 1 = d c t c o e f ∗ ( l o g _ s p e e c h 0.5 + l n 4 ) = d c t c o e f ∗ l o g _ s p e e c h 0.5 + d c t c o e f ∗ l n 4 ≈ d c t c o e f ∗ l o g _ s p e e c h 0.5 + 0 = d c t c o e f ∗ l o g _ s p e e c h 0.5 dctcoef * log_speech_{1} \ = dctcoef * (log_speech_{0.5} + ln4 ) \ = dctcoef * log_speech_{0.5} + dctcoef * ln4 \ \approx dctcoef * log_speech_{0.5} + 0 \=dctcoef * log_speech_{0.5}d c t c o e f ∗l o g _s p e e c h 1 =d c t c o e f ∗(l o g _s p e e c h 0 .5 +l n 4 )=d c t c o e f ∗l o g _s p e e c h 0 .5 +d c t c o e f ∗l n 4 ≈d c t c o e f ∗l o g _s p e e c h 0 .5 +0 =d c t c o e f ∗l o g _s p e e c h 0 .5
即原始语音无论乘以多少倍,在经过log,倍数变 加减数;加减数乘以 dctcoef后,数值约为0;因此语音的MFCC几乎无变化。
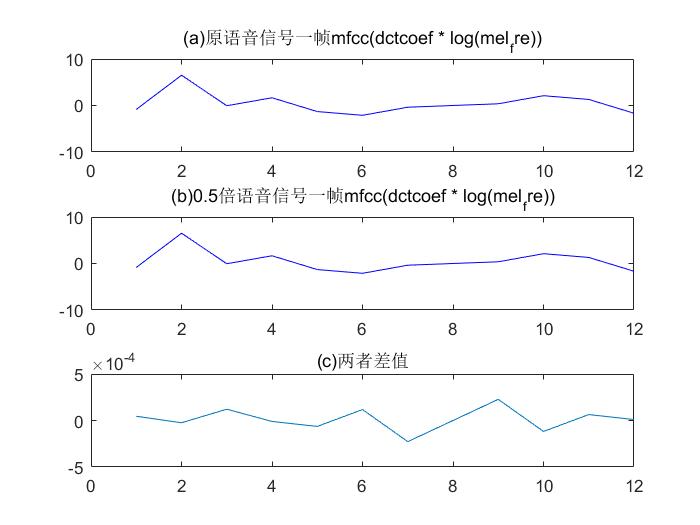
原本我以为频谱随着时域系数变化,体现了能量的变化,MFCC也一定随之变化。结果真是大大出乎我的意料。该试试,语音乘以2 倍 数 2^{倍数}2 倍数什么样子了。
语音乘以2 倍 数 2^{倍数}2 倍数,MFCC无改变。
Original: https://blog.csdn.net/joyjun_1/article/details/110855043
Author: 好像不对劲
Title: 语音信号处理-语音究竟要浮点还是整数?MFCC又是如何变化?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/526220/
转载文章受原作者版权保护。转载请注明原作者出处!