

目录
- 背景
- 基本概念
- 一般流程
- 预处理常用方法
- 声学模型
* - (一)多样性问题
- (二)语音识别任务的指标
- 语言模型
- 解码器
- 工作原理
* - (一)分析声音
- (二)提取特征
- (三)识别音素和状态(声学模型)
- 识别文字(语言模型+ 解码器)
- 深度学习方法
* - 发展
- 基于transfomer的语音识别模型
- 语音数据集
背景
语音识别 ( Automatic Speech Recognition, ASR ) 技术是语音交互领域中发展最快,同时是语音相关任务中最有挑战也是最重要的技术之一。
基本概念
语音识别的主要任务是将语音转换为相应的文本,输入信号为一段音频信号,输出为相应的文本序列。
[En]
The main task of speech recognition is to convert the speech into the corresponding text, the input signal is a section of audio signal, and the output is the corresponding text sequence.

ASR可以认为是一个搜索过程,给定输入特征X的情况下,搜索出最有可能的词序列W。
; 一般流程
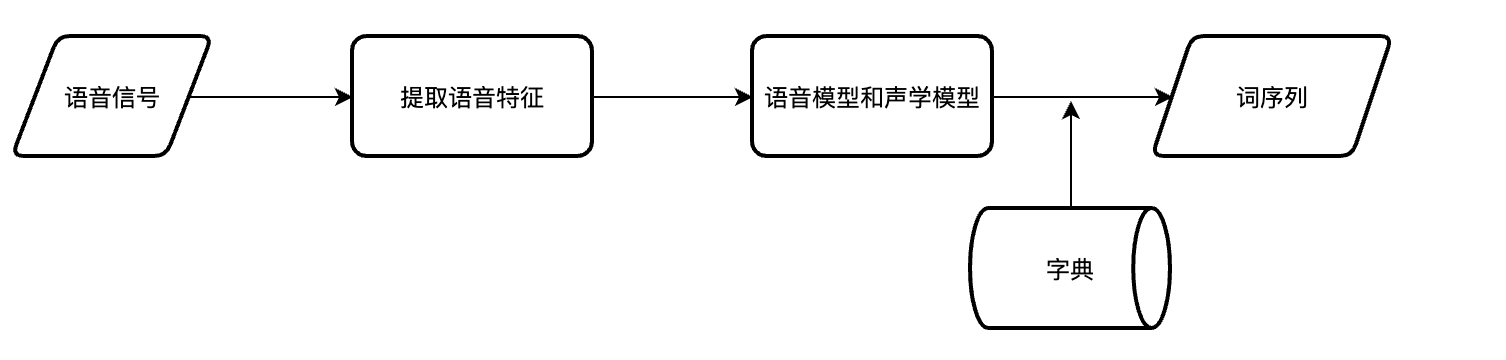
该系统主要由四个部分组成:特征提取、声学模型、语言模型、词典和解码。
[En]
The system mainly consists of four parts: feature extraction, acoustic model, language model, dictionary and decoding.
- 为了更有效地提取特征,通常需要对采集的声音信号进行预处理,并从原始信号中提取待分析的信号。
[En]
in order to extract features more effectively, it is generally necessary to preprocess the collected sound signal and extract the signal to be analyzed from the original signal.*
- 特征提取:将声音信号从时域转换到频域,为声学模型提供特征向量
[En]
feature extraction: convert sound signals from time domain to frequency domain to provide feature vectors for acoustic models*
- 声学模型:声学特征计算每个特征向量在声学特征上的得分
[En]
Acoustic model: acoustic characteristics calculate the score of each feature vector on acoustic features*
- 语言模型:根据语言学的相关理论,计算声音信号与可能的短语序列对应的概率。
[En]
language model: according to the relevant theories of linguistics, calculate the probability of the sound signal corresponding to the possible phrase sequence.*
- 词典:对短语序列进行解码,以获得最终可能的文本表示。
[En]
Dictionary: decode the sequence of phrases to get the final possible text representation.*
预处理常用方法
- AEC(回声消除):如果用于识别的设备,在识别语音时本身在播放音乐或者音频,此时对于识别的语音输入就有回声的存在,需要使用回声消除,得到纯净的输入语音
- De-reverb(去混响):在相对小一点的房间中录音,会有混响的存在,混响严重时会影响语音识别的效果
- Beamforming:多通道信号合并
- NS(降噪):降噪可以看成滤波的一种。降噪的目的在于突出信号本身而抑制噪声影响
- AGC(音频自动增益):声音信号幅度的自动变化,如声音远近的不同
- WF(滤波):将信号中特定波段频率滤除的操作,是抑制和防止干扰的一项重要措施
- Framing(分帧):为了程序能够进行批量处理,会根据指定的长度(时间段或者采样数)进行分段
声学模型
(一)多样性问题
- 语境多样性:同一个词在不同的语境中有不同的含义。
[En]
contextual diversity: the same word has different meanings in different contexts.*
- 风格多元化:同一演讲者有时会有不同的说话风格,比如演讲和与朋友聊天。
[En]
style diversity: the same speaker sometimes has different speaking styles, such as when giving a speech and chatting with friends.*
- 说话人多样性:在语音识别任务中,一项任务是识别演讲的具体内容,无论说话人是谁,说的是相同的文本内容;反向任务是说话人识别,即无论说话人说什么,我们都要识别说话人。同一个语音信号包含了很多不同的信息,这也导致了不同的声学信号。
[En]
Speaker diversity: in the speech recognition task, one task is to identify the specific content of the speech no matter who the speaker is and said the same text content; the reverse task is speaker recognition, that is, no matter what the speaker says, we have to identify the speaker. The same speech signal contains a lot of different information, which also leads to different acoustic signals.*
- 设备多样性:我们知道,相同的语音内容通过不同的语音设备(如手机、音响、麦克风等)也是不同的。同时,不同的设备质量也会引入大量的噪声,产生不同的声学信号。
[En]
device diversity: we know that the same speech content is also different through different voice devices (such as mobile phones, stereos, microphones, etc.). At the same time, different equipment quality will also introduce a lot of noise, resulting in different acoustic signals.
这些多样性问题增加了声学模型处理的难度和挑战性。
[En]
These diversity problems increase the difficulty and challenge of acoustic model processing.*
(二)语音识别任务的指标
- STOA和标准可以参考:
https://chimechallenge.github.io/ - 简单任务识别的错误率很快达到4%以下,但对于复杂场景下的识别任务,当时的错误率约为50%。
[En]
the error rate for simple task recognition quickly reached less than 4%, but for recognition tasks in complex scenarios, the error rate was about 50% at that time.*
- 此外,这里还可以看到,一般来说,当涉及到语音识别准确率(或错误率)时,需要与其对应的任务相关联。
[En]
in addition, it can also be seen here that, in general, when it comes to speech recognition accuracy (or error rate), it needs to be associated with its corresponding task.*
语言模型
在语音识别的语言模型中,语言模型是最常用的,换言之,用来计算序列(句子)出现的概率。
[En]
In the language model of speech recognition, the language model is the most commonly used, in other words, to calculate the probability of the occurrence of a sequence (sentence).
语言模型主要用于确定哪个单词序列更有可能,或者根据前一个单词或几个单词预测最有可能的下一个单词。
[En]
The language model is mainly used to determine which word sequence is more probable, or to predict the most likely next word based on the previous word or several words.
解码器
采用维特比算法(Viterbi),综合声学模型与语言模型的结果,给定输入特征序列,找出最有可能的词序列,利用起始概率、转移概率、发射概率寻找全局最优的词序列。
工作原理
- 第一步是将帧识别为状态。
[En]
the first step is to identify the frame as a state.*
- 第二步是将状态组合成音素。
[En]
the second step is to combine the state into phonemes.*
- 第三步是将音素组合成单词。
[En]
the third step is to combine phonemes into words.
首先,我们知道声音实际上是波。
[En]
First of all, we know that sound is actually a wave.*
常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。

; (一)分析声音

图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。分帧后,语音就变成了很多小段。
(二)提取特征
波形在时间域上几乎没有描述能力,因此必须对波形进行变换。
[En]
The waveform has almost no description ability in the time domain, so the waveform must be transformed.
将每一帧的波形变换为多维向量,简单地理解为该向量包含帧语音的内容信息。
[En]
The waveform of each frame is transformed into a multi-dimensional vector, which is simply understood as that the vector contains the content information of the frame speech.
这一过程称为声学特征提取。
[En]
This process is called acoustic feature extraction.
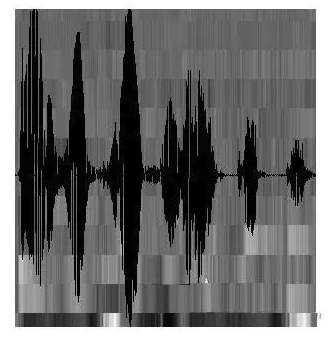
至此,声音就成了一个12行、N列的一个矩阵,这里N为总帧数。图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
; (三)识别音素和状态(声学模型)
音素:一个词的发音是由音素组成的。对于英语,常用的音素集是卡内基梅隆大学的39个音素集。汉语一般直接使用所有声母和韵母作为音素集,汉语识别也分为声调和非声调,不作详细说明。
[En]
Phoneme: the pronunciation of a word is made up of phonemes. For English, a commonly used phoneme set is a set of 39 phonemes from Carnegie Mellon University. Chinese generally directly uses all initial consonants and vowels as phoneme sets, and Chinese recognition is also divided into tonal and non-tonal, which is not detailed.
状态:比音素更详细的语音单位。音素通常分为三种状态。
[En]
Status: a phonetic unit that is more detailed than a phoneme. A phoneme is usually divided into three states.
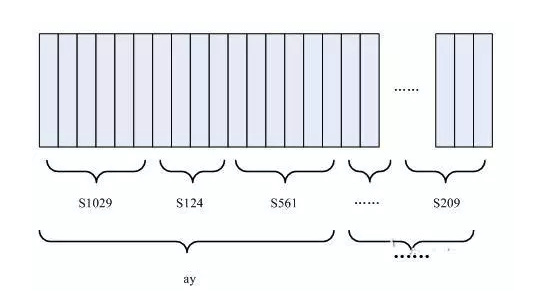
每个小竖条代表一个帧,几个语音帧对应一个状态,每三个状态组合成一个音素,几个音素组合成一个词。换句话说,只要你知道每个语音帧对应的是哪一种状态。
[En]
Each small vertical bar represents a frame, several frames of speech correspond to a state, every three states are combined into a phoneme, and several phonemes are combined into a word. In other words, as long as you know which state each frame of speech corresponds to.
识别文字(语言模型+ 解码器)
在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为”解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。
比如:我和你、我河你。
深度学习方法
发展
语音识别本质上是一个序列识别问题,如果模型中的所有组件都能够联合优化,很可能会获取更好的识别准确度,所以我们需要一种端到端(End2End)的语音识别处理系统。
先前的模型包括了特征提取、声学模型,语言模型等模块,是一个pipeline的系统,而end-to-end从输入到输出只用一个算法模型,输入是语音信号,输出就是最终的词序列的结果。
常用的端到端的语音识别模型为基于CTC ( Connectionist Temporal Classification ) 和基于attention机制的模型。
一个基于CTC的语音识别的典型例子:深度学习语音识别框架DEEPSPEECH(2016年)。
基于attention机制的端到端训练语音识别模型也逐渐成为了主流。
Attention机制最早应用在机器翻译领域,实现了从一种语言序列变化到另一种语言序列。
语音识别领域与机器翻译领域非常相似,前者是从语音信号序列到输出文本序列,而后者是从一种语言序列到另一种语言序列。
[En]
The field of speech recognition is very similar to the field of machine translation, the former is from the sequence of speech signal to the sequence of output text, while the latter is from the sequence of one language to another.
语音识别中使用attention机制的算法模型被称为Listen-Attend-Spell(LAS)模型。Listen部分是一个encoder,把声学信号转换成embedding向量, Attend为转换后向量的权重,Spell部分是一个decoder,把向量转换成对应的文字序列。
Attention模型和CTC模型最主要的区别是,基于神经网络对输出序列的历史信息做了显式的建模。
基于transfomer的语音识别模型
在NLP领域,输入是一段文字,通常的做法会把输入的文字通过embedding的方式转换成连续的向量。
在语音识别中,如果引入Transformer模型,通过会使用几个卷积层来实现downsampling,然后通过transformer模型映射到输出的文字序列,从而加入模型的收敛。
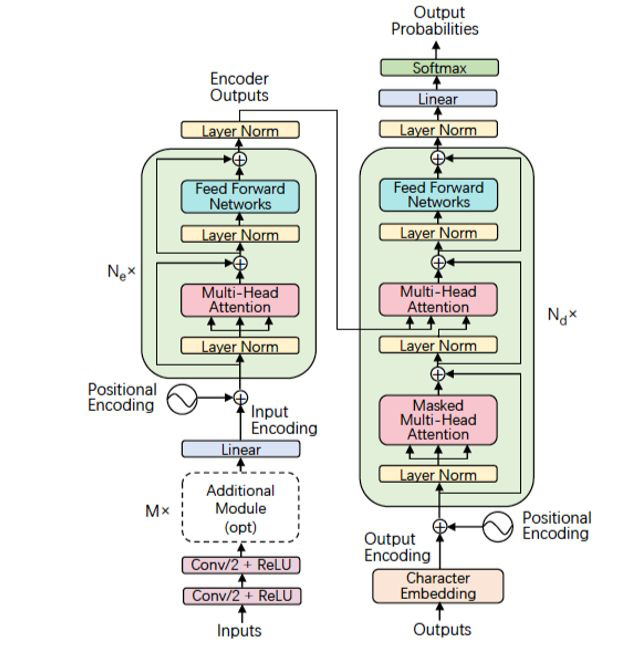
; 语音数据集
- 2000 HUB5 English:最近在 Deep Speech 论文中使用的英语语音数据,从百度获取。
地址:https://catalog.ldc.upenn.edu/LDC2002T43 - LibriSpeech:包含文本和语音的有声读物数据集。由多个朗读者阅读的近 500 小时的各种有声读物演讲内容组成,包含带有文本和语音的章节。
地址:http://www.openslr.org/12/ - VoxForge:带口音的清晰英语语音数据集。适用于提升不同口音或语调鲁棒性的案例。
地址:http://www.voxforge.org/ - TIMIT:英语语音识别数据集。
地址:https://catalog.ldc.upenn.edu/LDC93S1 - CHIME:嘈杂的语音识别挑战数据集。数据集包含真实、仿真和干净的录音。真实录音由 4 个扬声器在 4 个嘈杂位置的近 9000 个录音构成,仿真录音由多个语音环境和清晰的无噪声录音结合而成。
地址:http://spandh.dcs.shef.ac.uk/chime_challenge/data.html - TED-LIUM:TED 演讲的音频转录。1495 个 TED 演讲录音以及这些录音的文字转录。
地址:http://www-lium.univ-lemans.fr/en/content/ted-lium-corpus
Original: https://blog.csdn.net/weixin_45114252/article/details/110742455
Author: 心伽玛
Title: 语音识别技术介绍
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/525861/
转载文章受原作者版权保护。转载请注明原作者出处!