

概要
在现有的交叉说话人风格转换任务中,需要多风格录音的源说话人为目标说话人提供风格。然而,一个人很难表达所有预期的风格。本文提出了一个更一般的任务,即通过组合来自多个说话人语料库的任何风格和音色来产生有表现力的语音,其中每个说话人都有独特的风格。
[En]
In the existing cross-speaker style conversion tasks, the source speaker with multi-style recording is needed to provide style for the target speaker. However, it is difficult for one to express all the expected styles. This paper proposes a more general task, that is, to produce expressive speech by combining any style and timbre from multiple speaker corpora, in which each speaker has a unique style.
介绍
尽管TTS在许多场景中都得到了成功的应用,但如何根据不同的说话风格和音色,创建富有表现力的合成语音,是更好的用户体验所需要的。
要创建一个能够合成各种表达性语音的TTS系统,一个简单的方法是用一个带有人工标记[7,8,9,10,11]的数据库来训练TTS模型,例如,一个带有人工标记的情绪类别[7,9]或说话风格[11]的数据库。然而,这些方法的局限性是明显的,即严重依赖训练数据,不能通过结合不同的说话人音色和说话风格来创造新的声音。
为了将一种风格移植到没有标记表情记录的目标说话人身上,交叉说话人风格迁移的任务引起了人们的广泛关注。
[En]
In order to transplant a style to the target speaker where there is no tagged expression recording, the task of cross-speaker style transfer has attracted much attention.
虽然这些跨说话人迁移方法可以成功地从语料库中没有这种说话风格的说话人那里产生具有特定说话风格和音色的表达性言语,但它们通常依赖于源说话人具有足够的人工标记的表达源。它要求源说话者是表达所有预期风格的专家,目的是产生具有各种风格的合成语音。无论如何,一个源说话者模仿所有可能的说话风格并录下足够的录音是不可能的。相比之下,获得一个表达性语料库要容易得多,在语料库中,每个说话者只说他或她擅长的一种特定的说话风格。有了这样的语料库,一个实际的任务就是构建一个能够结合不同说话人的不同音色和风格产生合成语音的TTS系统,称为与说话人相关的多风格多说话人TTS (SRM2TTS)。
与传统跨说话人风格迁移任务相比,SRM2TTS任务中音色与风格紧密纠缠,使得基于参考的方法很难在说话人之间进行风格迁移。本文借鉴(标签信息辅助内容 to 感知韵律预测模型在风格传递任务[15]上的成功),提出了一种用于SRM2TTS任务的新方法。
具体而言,基于典型的神经网络seq2seq框架,提出了一种基于内容感知的多尺度韵律建模模块,《《该模块可以根据风格标签和输入文本为TTS系统提供风格信息。该方法附加了一个说话人识别控制器,可以区分不同的风格和音色,从而可以实现SRM2TTS的任何扬声器和风格的组合。》》实验结果表明,该方法能很好地结合说话人的音色和说话风格来合成有表现力的语音。此外,得益于韵律特征的显式建模,该方法可以灵活地控制每一个韵律成分,如音高和能量,从而增加合成语音的多样性
本文的研究成果可概括为:
(1) 基于每个说话人都具有独特说话风格的多说话人数据库,首次提出了结合任何风格和音色来合成有表现力的说话人方法。
(2)提出了一种新的可实现任意风格和音色在表达语音合成中的组合和控制的方法。
(3)实验表明,基于细粒度文本的韵律建模模块可以明确地对韵律成分进行建模和灵活控制。

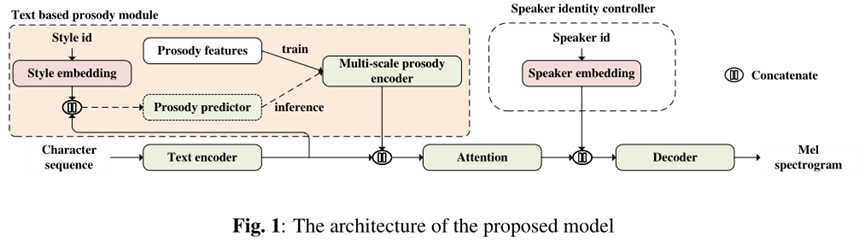
主干网络
在[9]之后,稍加修改的Tacotron2[4]版本被用作编码器-解码器骨干。
编码器由一个pre-net和CBHG模块[21]组成,pre-net由两个全连接的层组成。
该解码器由一个自回归神经网络(RNN)组成,并在每个解码器的时间步产生注意查询。这里使用GMM注意机制,在长序列语音建模中表现出良好的性能[22,23]。
为了控制合成语音的音色,在解码器中加入一个256维的附加扬声器嵌入到RNN输入中。采用了post-net, post-net是一个五层卷积网络。
该框架下的语音由mel-频谱图表示,并采用多波段WaveRNN[6]对预测的频谱图进行波形重构。
当说话风格和说话人身份之间存在精确对应时,从整体上看,说话人信息和说话人风格信息就会深度纠缠。因此,找出说话人信息和风格信息之间的本质区别是非常重要的。实际上,说话人的音色信息是全局信息,即与说话人身份相关的音色基本不会随着说话风格的变化而改变。相比之下,说话风格主要是局部信息,一般以细粒度的节奏呈现,并随发声单元的不同而不同。在我们的例子中,很难将韵律直接区分为全局嵌入和说话人嵌入。
[En]
When there is an exact correspondence between the speaking style and the speaker’s identity, from the overall point of view, the speaker information and the speaker style information will be deeply entangled. Therefore, it is very important to find the essential difference between speaker information and style information. In fact, the timbre information of the speaker is the global information, that is, the timbre related to the identity of the speaker basically does not change with the change of speech style. In contrast, the speaking style is mainly local information, which is generally presented in fine-grained rhythm and varies with different vocal units. * it is difficult to distinguish prosody directly as global embedding from speaker embedding in our example.*

提出了一种用于音素韵律建模的细粒度韵律编码器。在训练阶段,韵律特征通过音高、时长和能量来表达,都是在音素水平上的。
[En]
A fine-grained prosodic encoder is proposed to model phoneme prosody. * in the training stage, prosodic features are expressed by pitch, duration and energy, all at the phoneme level. *
韵律预测器的结构如图2所示。它由5个一维卷积层和1个线性变换层组成。每一个卷积层之后是层归一化,ReLu激活函数和dropout。考虑到韵律序列的时间特性,在输入中加入位置编码向量。为了优化韵律预测器,使用L1损失来计算预测的韵律与地面真实韵律特征之间的偏差
同时,利用文本编码器的输出和风格嵌入作为输入,对基于文本的韵律预测器进行了优化。在推理阶段,韵律预测器为语音合成提供语音风格信息。
[En]
At the same time, the text-based prosody predictor is optimized by using the output of the text encoder and style embedding as input. In the reasoning stage, prosodic predictors provide speech style information for speech synthesis.
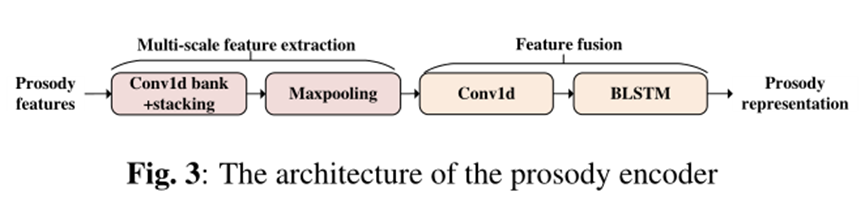
人类的说话风格即使在同一句话中也有丰富而微妙的变化。这些变化一般反映在不同的尺度上。为了更好地表示韵律特征,我们在框架中提出了一种多尺度编码器。输入的韵律特征首先与一维卷积滤波器组F = {f1,…, fm},其中fi的宽度为i。在实际中,提出的模型中m为8。将卷积组的输出叠加在一起,处理后的序列进一步传递到最大池化层和一维卷积层。然后我们使用一层双向LSTM (BLSTM)来提取前向和后向序列特征。 利用这种多尺度建模方法,我们可以明确地从韵律成分中获取局部和上下文特征
由于本文提出的方法是基于明确的韵律特征,它允许我们通过调整韵律特征的值来控制韵律特征。具体地说,通过将韵律特征乘以或除以一定的尺度,可以灵活地控制合成语音的韵律,从而进一步增强合成语音的表现力。
[En]
Because the method proposed in this paper is based on clear prosodic features, it allows us to control prosodic features by adjusting the values of prosodic features. Specifically, by multiplying or dividing the prosodic features by a scale, we can flexibly control the prosody of synthetic speech, thus further enhancing the expressiveness of synthetic speech.
数据集
实验中使用了一个内部的普通话多说话者语料库,每个说话者都有独特的说话风格。共有6位演讲者,每个人都有自己独特的风格,包括阅读、电台主播、讲故事、客户服务(CS)、诗歌和游戏角色。与前四种说话风格相比,后两种说话风格的表现力更强,分别由一个孩子和一个游戏角色记录下来。总时长为20小时,所有录音都被降采样至16kHz。随机抽取每个说话人的10句话作为测试集进行主观评价。
评判指标
风格相似性:风格相似性是比较自然语音和合成语音的预期说话风格之间的相似性。利用人类评分实验对这一相似性进行了均值评价(MOS)。在采用的数据库中,采用阅读风格的演讲者(DB11)是一个公共数据库。因此在评价中,采用DB1作为目标音色来表达不同的说话风格。邀请20名(性别平衡)母语普通话听众参与评估。
说话人相似度:说话人相似度是比较自然语音和合成语音的音质期望之间的相似度。与风格相似度的评价类似,在主观测试中进行MOS评价。
对比方法
为了评估所提出的模型在SRM2TTS任务上的性能,本工作比较了两种最先进的风格转换方法,即Multi-R[12]和PB[15]。Multi-R[12]是一种基于tacotron multi -reference的韵律转换方法。PB [15]是一种基于韵律瓶颈的跨说话人风格传递模型。为了公平的比较,被比较的Multi-R和PB采用与我们提出的模型相同的Tacotron骨干
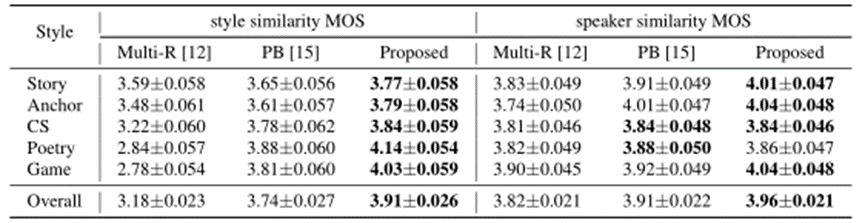
风格相似度和说话人相似度的MOS评价如表1所示。从表中可以看出,我们的模型在所有风格类别中表现最好。请注意,基于参考的方法Multi-R在所有说话风格中获得最低的MOS分数。这主要是因为当每个说话者都有独特的说话风格时,这种 基于参考的方法很难将说话者的音色和风格分离开来。因此,当模仿的口语风格与阅读风格(游戏和诗歌)显著不同时,这种基于参考的方法的表现就会差得多。
相比之下,基于标签的PB和我们的方法获得了更好的风格相似MOS分数,这可能是由于独特的说话风格使被试更容易判断,表明基于标签的方法在这个SRM2TTS任务上的有效性。与PB相比,我们提出的方法获得了4.5%相对较高的风格相似性MOS平均所有风格类别。
在说话人相似度方面,三种模型之间没有明显的MOS差异,说明PB中的风格转移和所提出的方法相比风格转移能力非常有限的Multi-R并没有给音色带来明显的负面影响。相反,所提方法甚至在除CS和Poetry之外的所有风格类别中都达到了最好的speaker similarity MOS,表明所提方法在SRM2TTS任务中表现良好。
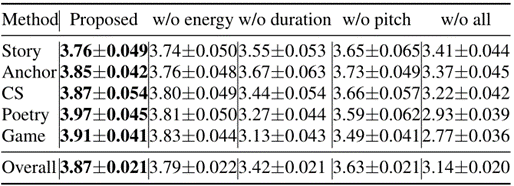
w/o all,模型退化为一个通用的多说话人模型
从这个表可以看出,去掉任何一个韵律成分都会导致风格相似性的性能显著下降。具体来说,持续时间的下降带来的降幅最大,其中风格相似度MOS比本文方法相对低11.7%。当没有采用韵律成分,即w/o all时,该模型无法执行风格转换任务。相反,它只是一个多说话人的TTS模型,只能产生音色和风格属于语料库中的同一说话人的合成语音。所有这些结果表明,每个韵律成分的重要性,在我们的韵律建模模块。这些韵律成分除了对风格相似性的影响外,在人工控制合成语音中的韵律方面也发挥着重要作用,这将在3.4节中展示
风格控制
由于我们在韵律预测模块中明确使用了韵律特征,即基音、时长和能量,所以我们可以很容易地通过调整韵律特征来控制韵律。
[En]
Because we clearly use the prosodic features in the prosodic prediction module, namely pitch, duration and energy, we can easily control the prosody by adjusting the prosodic features.
例如,我们可以简单地将持续时间乘以一个刻度来控制语速。图4-6分别显示了通过调整音调、能量和持续时间合成语音的不同音调、能量和Mel谱。可以看出,韵律特征的调整可以准确地控制合成语音对应的韵律,这表明我们的韵律编码器可以对最终合成语音中的显式独立韵律成分进行建模。即使音阶越大,对应的韵律成分变化越大,音阶也不可能是无限的。例如,太短的持续时间或太小的能量会影响可理解性。 在实验中,我们发现音高和能量可以有效控制在20%的范围内,持续时间可以成功控制在50%的范围内。
总结
本文提出了一种通用的程式化语音合成任务。这项任务被称为SRM2TTS,旨在通过将一个说话者的任何说话风格与另一个说话者的音色相结合,产生富有表现力的合成语音。
与现有的语体转换任务相比,它可以避免对源说话人的依赖,源说话人必须记录所有预期的语音风格。因此,在许多应用情况下,该任务的实施是有前景的。
[En]
Compared with the existing stylistic switching tasks, it can bypass the dependence on the source speaker, who must record all the expected speech styles. Therefore, in many application cases, the implementation of this task is promising.
为了实现这一任务,提出了一种基于显式韵律特征的风格建模方法。该方法基于Tacotron2的主干,带有细粒度文本韵律预测模块和扬声器控制器。
大量实验表明,该方法可以成功地利用一个说话人的音色来表达另一个说话人的风格。此外,韵律预测模块明确使用韵律特征,并可以手动控制韵律,以产生更具表现力的合成语音。
[En]
A large number of experiments show that this method can successfully use the timbre of one speaker to express the style of another speaker. In addition, the prosody prediction module clearly uses prosodic features and can manually control the prosody to produce more expressive synthetic speech.
Original: https://blog.csdn.net/qq_35668477/article/details/124426812
Author: ウルトラマン.
Title: 读《MULTI-SPEAKER MULTI-STYLE TEXT-TO-SPEECH SYNTHESIS WITH SINGLE-SPEAKER SINGLE-STYLE TRAINING DATA》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/524703/
转载文章受原作者版权保护。转载请注明原作者出处!