

前言
文章原创,出自 cv君,公众号:DeepAI 视界


gif 不能发出声音,大家脑补一下场景。算法找到视频中的打击乐器和钢琴正在发声

gif 不能发出声音,大家脑补一下场景。算法找到视频中的救护车正在滴度滴度~
视听分割是本周ECCV定会提出的全新任务,旨在: 找出画面中哪个位置正在发出声音,这是一份多模态工作,结合了视觉和语音。
这有啥用?
直播推荐领域:我们直播的推荐系统,可能需要给正在表演才艺的cv君多一些推荐力度,而一直抱着琴不弹的,只在闲聊的、并且放着BGM的,我们需要识别出来现在有没有进行才艺表演。有的朋友就说啦!用语音识别,分类出在唱歌和不唱歌不就行了? 反问:如何用语音识别分类区分BGM和唱歌?————视听分割、声源定位可以解决大家看下图。
智慧生活领域:场景1:禁止鸣笛的生活区的路边,安安静静,cv君躺在家里摆烂,哪个扑街突然鸣笛,抓!
场景2:校园午休静校期间,cv,你特么怎么还在吵、还打球、打个球
场景3:帮助视障人士
想法很简单,但实现起来很难,如何让这两种信息参与学习,发挥作用?让我们仔细看看它。
[En]
The idea is very simple, but the realization is very difficult, how to let these two kinds of information participate in the learning and play a role? Let’s take a closer look at it.
相似工作
近年来,对音频和视觉图像的表征学习(audio-visual learning)吸引了很多关注,也催生了很多任务,比如视听匹配、视听事件定位、声源定位(Sound Source Localization, SSL)等等。前两者作为一个分类任务,都可以归结于给定一张图像和一段音频,判断二者是否描述同一个事件/物体;声源定位想要定位到发声物体的大致区域,趋近于目标检测,但是是以热力图可视化的形式表示定位的结果。
这些任务虽然很有趣,但却不能很好地勾勒出物体的形状,距离对视听场景的精细理解似乎只有一步之遥。为此,音视频分割任务提出了对视频帧中发声对象的全景进行精确分割,即以音频为引导信号,确定要分割的对象,得到其完整的像素级掩模图像,如图1所示:
[En]
Although these tasks are very interesting, they can not well outline the shape of the object, and it seems to be just a step away from the fine understanding of the audio-visual scene. For this reason, the * audio-visual segmentation task proposes to accurately segment the whole picture of the sound-making object in the video frame, that is, using audio as the guiding signal to determine which object to segment and get its complete pixel-level mask image * , as shown in figure 1:

意思就是,以前的工作(第三行,SSL行)只能知道 哪里可能发出了声音, 现在(第四行AVS)可以端到端的对整个物体识别了,识别:哪个物体在哪里发出了这种声音。
作者公布了一份多声源地数据,和单声源的数据,单源子集包含4932个视频,共23个类别,涵盖人类、动物、交通工具和乐器等日常生活中典型的发声物体,详细的类别和视频数据分布如图2所示。对于多源子集,作者从单源子集的类别中选择有效的2-3个作为关键词组合,从YouTube平台人工检索视频,在约6000余视频中筛选出424个作为多源视频。

核心方法
本文作者提出了一个端到端的视听分割模型AVS,如图所示,其遵循编码器-解码器的网络架构,输入视频帧,最终直接输出分割掩码。

cv君看了代码,简单说就是:
1、使用Renset50或者使用更大更准的任何特征提取网络(作者还用了PVT-v2的transformer网络)做视觉表征的提取
2、使用VGGish提取音频梅尔图的表征信息
3、视觉特征与音频特征经过ASPP池化,维度合并送入作者提出的TPAVI模块,送入下一个编码层。
4、 特征解码器,输出原图像尺寸的预测mask图
5、引入多个BCE Loss 和作者提出的掩码视听匹配Loss
具体而言,在编码器中,视频帧的多层级特征图可以通过经典CNN或已经屠榜各大任务的Transformer网络提取(作者测试了ResNet50和PVT-v2两种结构);音频的特征可以通过VGGish,一种类似VGG的网络提取。其次,视频帧特征图被送入分割模型中常用的层级池化空洞卷积模块(ASPP)进行进一步编码。紧接着,编码的视频帧特征和音频特征被送入所提出的TPAVI模块,其考虑时序的音频和视频帧像素间的联系,引入音频信息指导分割。经过TPAVI模块的视频帧特征期望能够在与音频对应/匹配的区域被增强。最后,编码的特征被送入解码器进行分步解码,最终产生和原始输入分辨率相同大小的分割掩码图。
网络的优化目标分为两部分,一部分是基本交叉熵损失函数,它计算预测图和真实标签的损失。另一方面,提出了一种多源情况下的掩模视听匹配损失函数,用于约束预测掩模对应的视频帧特征(声音对象)和音频特征的分布,以保持特征空间中的相似分布。
[En]
The optimization goal of the network is divided into two parts, one is the basic cross-entropy loss function, which calculates the loss of the prediction graph and the real label. In the other part, the author proposes a mask audio-visual matching loss function for multi-source cases, which is used to constrain the video frame feature (sound object) and audio feature distribution corresponding to the prediction mask to maintain a similar distribution in the feature space.
与其他多模态方法相比的亮点:TPAVI模块加成较多,掩码视听匹配Loss有一定加成
亮点介绍
TPAVI模块

TPAVI模块将第i级视觉特征Vi和音频特征A作为输入。彩色框表示1×1×1卷积,而黄色框表示reshape操作。”符号”⊗” 和
“⊕” 分别表示矩阵乘法和元素加法。
虽然声源的听觉和视觉信号可能不会同时出现,但它们通常存在于多个视频帧中。因此对整个视频的音频和视频信号进行视觉分割应该是有益的。我们采用了编码时间像素级视听交互(TPAVI)。如上图所示,整个视频的当前视觉特征图Vi和音频特征A被发送到TPAVI模块中。具体而言,首先将音频特征A转换为与视觉特征Vi具有相同维度的特征空间通过线性层。然后,将其在空间上复制hi*wi次,并重新整形为与Vi相同的大小我们将这种处理后的音频特征表示为Aˆ。接下来,期望在整个视频中找到对音频对应物aˆ具有高响应的视觉特征图Vi的那些像素。这样的视听交互可以通过点积来测量,在第i阶段更新的特征图Zi可以计算为:
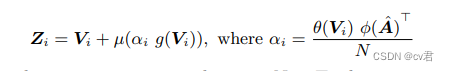
其中θ、ψ、g和µ是1×1×1卷积,N=T×hi×wi是归一化因子,αi表示视听相似性,Zi表示∈ R T×hi×wi×C。每个视觉像素通过TPAVI模块与所有音频交互。我们在图10后面提供了TPAVI中视听注意力的可视化,它显示了与SSL方法预测类似的”外观”,因为它构建了像素到音频的映射。
解码器:我们在这项工作中采用了全景FPN[19]的解码器,因为它具有灵活性和有效性,尽管可以使用任何有效的解码器架构。
简言之,在第j级,其中j=2、3、4,来自级Z5的两个输出−j和最后一级Z6−j用于解码过程。然后将解码的特征上采样到下一阶段。解码器的最终输出是M∈ rt×H×W,由乙状结肠激活。
掩码视听匹配Loss
目标函数:给定预测M和像素标记Y,我们采用二进制交叉熵(BCE)损失作为主要监督函数。
此外,我们还使用了一个额外的正则化项LAVM来强制进行视听映射。具体而言,我们使用Kullback–Leibler(KL)散度来确保掩蔽的视觉特征与相应的音频特征具有相似的分布。换句话说,如果某些帧的音频特征在特征空间中接近,则相应的发声对象在特征空间中将接近。总目标函数L可以如下计算:

其中λ是平衡重量,⊙ avg表示平均池运算。在每个阶段,我们通过平均池对预测M到Mi进行下采样,使其具有与Zi相同的形状
矢量Ai是与Zi具有相同特征维数的a的线性变换
对于半监督S4设置,我们发现视听正则化损失没有帮助,因此在此设置中设置λ=0。
实验结论

代码刚开源几天,cv君仔细看了代码,并且已经无压力运行了,大家有问题可以咨询我,免费。作者基于Resnet50做Backbone 在多声源数据中得到了 47.88分,cv君通过多次复现,得到了这个分数接近的分数,但是不稳定,有时候得到44分,又时候46分有时候47.2分, cv君通过自研的搜索框架,不增长任何Flops分数已经达到了49.70分,增加了2个点。(可见作者还是给出了baseline),不过最近作者又准备了10倍大的新模型。
可以发现,在PVT-v2的框架下,得分很高,说明了transformer很猛,不过Flops更高,没毛病。

你可以看到分割效果非常好,你可以看到我的视频分析,因为论文不能发送视频哈,上面的图片显示了其他方法和当前方法的比较。
[En]
You can see that the segmentation effect is very good, you can see my video analysis, because the paper can not send video, ha, the above picture shows the comparison between other methods and the current method.

上图为多声效,要看视频才知道:前两帧只有孩子在说话,后三帧孩子和狗都在说话。
[En]
The picture above shows the effect of multi-sound, and you have to watch the video to know: it means that only the child is talking in the first two frames, and both the child and the dog are talking in the last three frames.
而LGVT方法却无法分辨。

最后作者还比较了其他两阶段方法,和他的AVS方法的对比。远好于两阶段方法:该方法首先通过现成的掩码R-CNN生成实例分割图,然后结合音频信号进行最终探测对象分割。性能不受分割质量的制约(使用不同的掩码RCNN主干),但在很大程度上受音频信号的影响。

两行显示了有或没有TPAVI模块的拟议AVS方法,而”A”⊕V”表示直接将音频添加到视觉功能。应注意的是,将音频特征添加到视觉特征不会导致S4设置下的明显差异,但会导致MS3 14 J.Zhou等人的明显增益。
表5.音频信号和TPAVI的影响。带和不带TPAVI模块的AVS结果(mIoU)。中间一行表示直接添加音频和视频功能,这已经提高了MS3设置下的性能。TPAVI模块进一步增强了所有设置的结果

这是引入TPAVI的对比,可以看到倒数两行,开枪的声音分割,精确到了枪体,而非人体。

视听注意力的可视化。

Loss 的对比。
在未经训练的数据中进行测试,分割效果也很好。
[En]
Testing in untrained data, segmentation is also good.

总结
这是一份多模态工作,这两年多模态开始热门了,但工作还是出得很少,这是一篇比较优质的工作,已经被ECCV接受了,工作量给9分,创新程度给8分,有趣程度给10分,代码质量给7分。不足的是,其实可以直接搞成多类别分割。更精准。难度不大,cv君有空会做一下。
论文地址:
https://arxiv.org/abs/2207.05042
GitHub地址:
项目主页:
理论视频分析+代码解读+训练教程+视频教程+推理教程+优化教程见【下一篇文章】~https://blog.csdn.net/qq_46098574/article/details/126255334
Original: https://blog.csdn.net/qq_46098574/article/details/126255060
Author: cv君
Title: 【反内卷】开创全新AI多模态任务一视听分割:附原理、代码实践、优化教程(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/524633/
转载文章受原作者版权保护。转载请注明原作者出处!