

总结
习题
第 141 题
假设你的训练样本是句子(单词序列),下面哪个选项指的是第i个训练样本中的第j个词?
A.x ( i ) < j > x^{(i)x (i )
B.x < i > ( j ) x^{(j)}_x (j )
C.x ( j ) < i > x^{(j)}_x (j )
D.x < j > ( i ) x^{x
第 142 题
看看下面的循环神经网络:
[En]
Take a look at the following cyclic neural network:
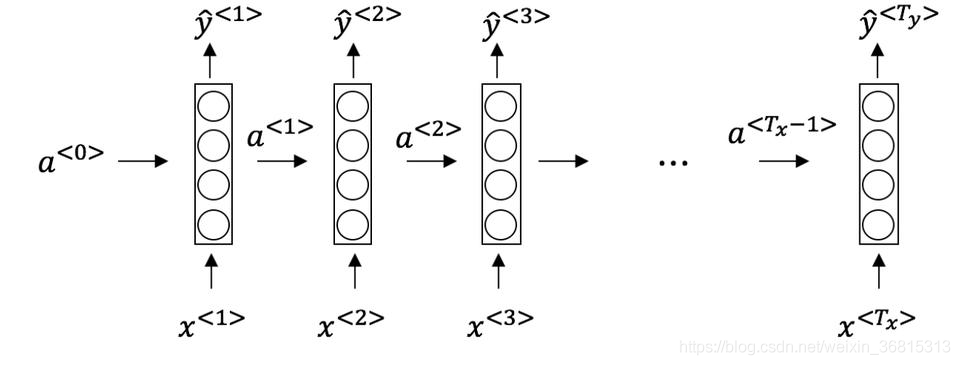

在以下情况下,满足上图所示网络结构的参数为:
[En]
In the following conditions, the parameters that satisfy the network structure in the figure above are:
A.T x = T y T_x=T_y T x =T y
B.T x < T y T_x
C.T x > T y T_x>T_y T x >T y
D.T x = 1 T_x=1 T x =1
; 第 143 题
这些任务中的哪一个会使用多对一的RNN体系结构?
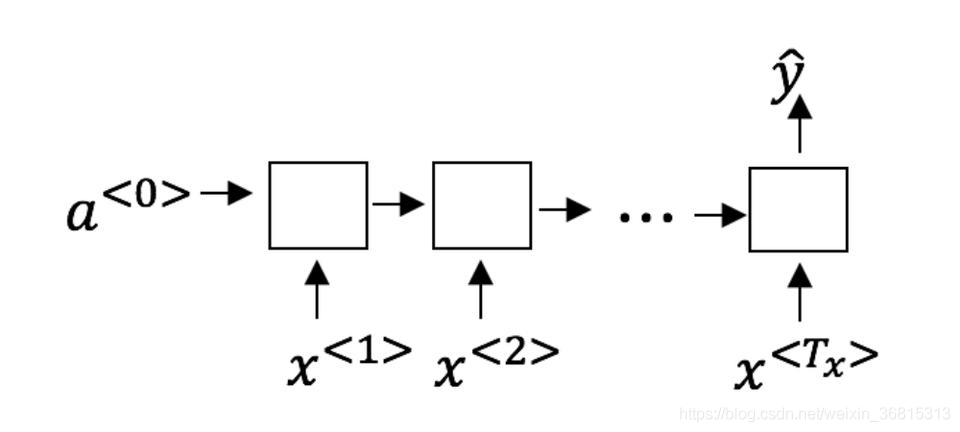
A.语音识别(输入语音,输出文本)
B.情感分类(输入一段文字,输出0或1表示正面或者负面的情绪)
C.图像分类(输入一张图片,输出对应的标签)
D.人声性别识别(输入语音,输出说话人的性别)
第 144 题
假设你现在正在训练下面这个RNN的语言模型:
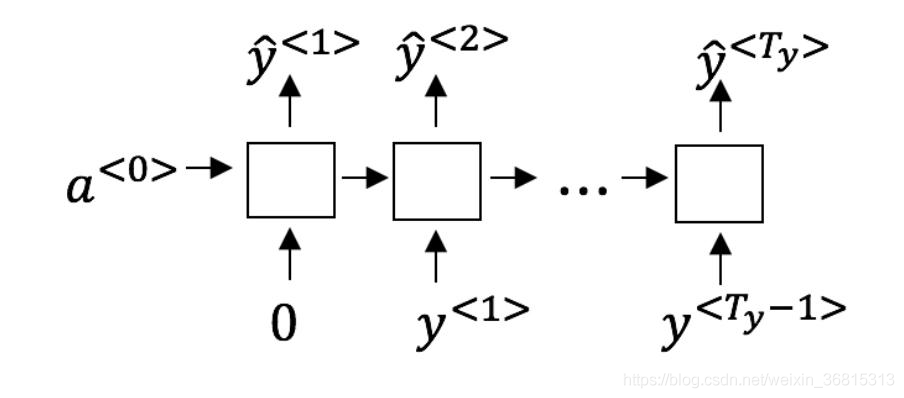
在 t t t时,这个RNN在做什么?
A.计算P ( y < 1 > , y < 2 > , … , y < t − 1 > ) P(y^{P (y <1 >,y <2 >,…,y
B.计算P ( y < t > ) P(y^{P (y
C.计算P ( y < t > ∣ y < 1 > , y < 2 > , … , y < t − 1 > ) P(y^{P (y
D.计算P ( y < t > ∣ y < 1 > , y < 2 > , … , y < t > ) P(y^{P (y
; 第 145 题
你已经完成了一个语言模型RNN的训练,并用它来对句子进行随机取样,如下图:
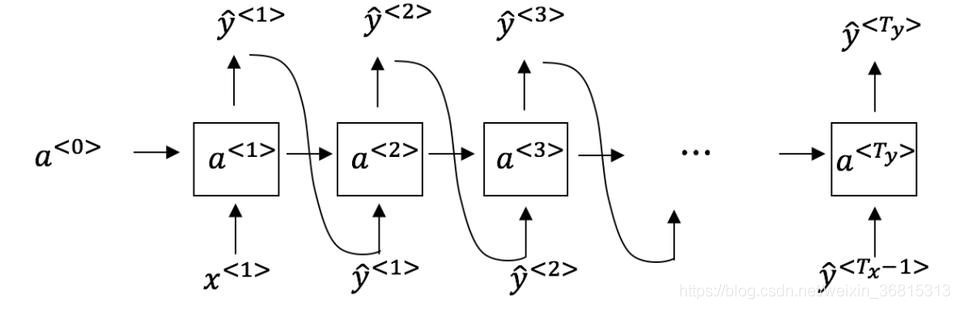
在每个时间步 t t t 都在做什么?
A.(1)使用RNN输出的概率,选择该时间步的最高概率单词作为y ^ < t > \hat{y}^{y ^
B.(1)使用由RNN输出的概率将该时间步的所选单词进行随机采样作为y ^ < t > \hat{y}^{y ^
C.(1)使用由RNN输出的概率来选择该时间步的最高概率词作为y ^ < t > \hat{y}^{y ^
D.(1)使用RNN该时间步输出的概率对单词随机抽样的结果作为y ^ < t > \hat{y}^{y ^
第 146 题
你正在训练一个RNN网络,你发现你的权重与激活值都是”NaN”,下列选项中,哪一个是导致这个问题的最有可能的原因?
A.梯度消失
B.梯度爆炸
C.ReLU函数作为激活函数g(.),在计算g(z)时,z的数值过大了
D.Sigmoid函数作为激活函数g(.),在计算g(z)时,z的数值过大了
第 147 题
假设你正在训练一个LSTM网络,你有一个10,000词的词汇表,并且使用一个激活值维度为100的LSTM块,在每一个时间步中, Γ u \Gamma_u Γu 的维度是多少?
A.1
B.100
C.300
D.10000
第 148 题
这里有一些GRU的更新方程:
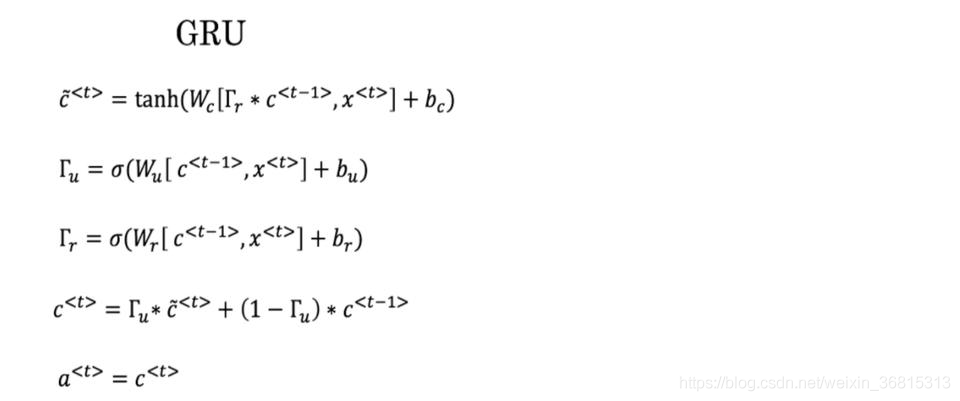
爱丽丝建议通过移除 Γ u \Gamma_u Γu 来简化GRU,即设置 Γ u = 1 \Gamma_u=1 Γu =1。贝蒂提出通过移除 Γ r \Gamma_r Γr 来简化GRU,即设置 Γ r = 1 \Gamma_r=1 Γr =1。哪种模型更容易在梯度不消失问题的情况下训练,即使在很长的输入序列上也可以进行训练?
A.爱丽丝的模型(即移除 Γ u \Gamma_u Γu ),因为对于一个时间步而言,如果 Γ r ≈ 0 \Gamma_r\approx0 Γr ≈0,梯度可以通过时间步反向传播而不会衰减。
B.爱丽丝的模型(即移除 Γ u \Gamma_u Γu ),因为对于一个时间步而言,如果 Γ r ≈ 1 \Gamma_r\approx1 Γr ≈1,梯度可以通过时间步反向传播而不会衰减。
C.贝蒂的模型(即移除 Γ r \Gamma_r Γr ),因为对于一个时间步而言,如果 Γ u ≈ 0 \Gamma_u\approx0 Γu ≈0,梯度可以通过时间步反向传播而不会衰减。
D.贝蒂的模型(即移除 Γ r \Gamma_r Γr ),因为对于一个时间步而言,如果 Γ u ≈ 1 \Gamma_u\approx1 Γu ≈1,梯度可以通过时间步反向传播而不会衰减。
; 第 149 题
这里有一些GRU和LSTM的方程:
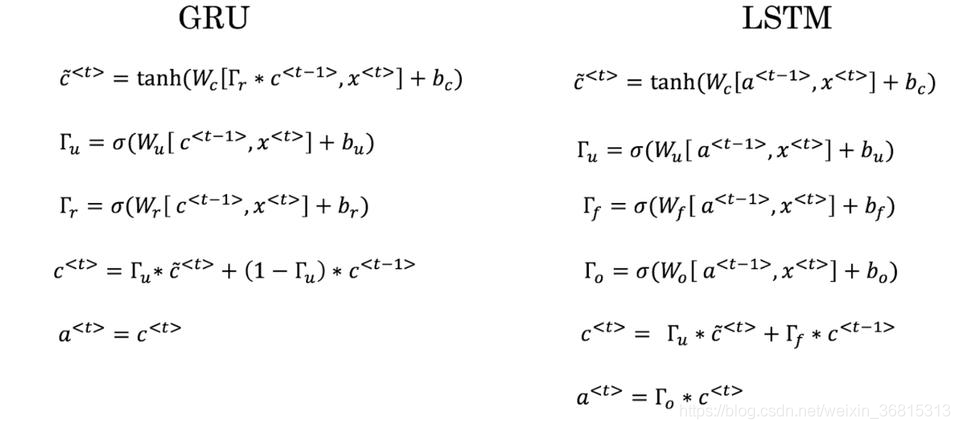
从这些我们可以看到,在LSTM中的更新门和遗忘门在GRU中扮演类似与的角色,空白处应该填什么?
A. Γ u \Gamma_u Γu 与 1 − Γ u 1-\Gamma_u 1 −Γu
B. Γ u \Gamma_u Γu 与 Γ r \Gamma_r Γr
C. 1 − Γ u 1-\Gamma_u 1 −Γu 与 Γ u \Gamma_u Γu
D. Γ r \Gamma_r Γr 与 Γ u \Gamma_u Γu
第 150 题
你有一只宠物狗,它的心情很大程度上取决于当前和过去几天的天气。你已经收集了过去365天的天气数据 x < 1 > , ⋯ , x < 365 > x^{x <1 >,⋯,x <3 6 5 >,这些数据是一个序列,你还收集了你的狗心情的数据 y < 1 > , ⋯ , y < 365 > y^{y <1 >,⋯,y <3 6 5 >,你想建立一个模型来从x到y进行映射,你应该使用单向RNN还是双向RNN来解决这个问题?
A.双向RNN,因为在 t t t 日的情绪预测中可以考虑到更多的信息。
B.双向RNN,因为这允许反向传播计算中有更精确的梯度。
C.单向RNN,因为y的值仅依赖于 x < 1 > , … , x x^{< 1 >} ,…,x x <1 >,…,x ,而不依赖于x , … , x < 365 > x ,…,x^{x ,…,x <3 6 5 >
D.单向RNN,因为y的值只取决于 x x x,而不是其他天的天气。
141-150题 答案
141.A 142.A 143.BD 144.C 145.D 146.B 147.B 148.C 149.A 150.C
Original: https://blog.csdn.net/qq_42994177/article/details/123233632
Author: why do not
Title: 【吴恩达deeplearning.ai】Course 5 – 序列模型 – 第一周测验
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/524601/
转载文章受原作者版权保护。转载请注明原作者出处!