

各位同学好,今天和大家分享一下如何使用 Tensorflow构建 DANet和 CBAM混合域注意力机制模型。在之前的文章中我介绍了CNN中的 通道注意力机制 SENet 和 ECANet,感兴趣的可以看一下:https://blog.csdn.net/dgvv4/article/details/123572065
1. 注意力机制介绍
注意力机制本质上是一种资源分配机制,它可以 根据关注目标的重要性程度改变资源分配方式,使资源更多的向attention的对象倾斜。在卷积神经网络中,注意力机制所要分配的资源就是权重参数。在模型训练过程中 对于attention的对象分配更多的权重参数,能够提高对于attention对象的特征提取能力。在目标检测任务中添加注意力机制, 可以提高模型的表征能力,有效减少无效目标的千扰,提升对关注目标的检测效果,进而提高模型的整体检测准确率。
2. CBAM 注意力机制
2.1 方法介绍
CBAM注意力机制是由通道注意力机制(channel)和空间注意力机制(spatial)组成。
CNAM注意力机制的优点:
(1)轻量化程度高:CBAM模块内部无大量卷积结构,少量池化层和特征融合操作,这种结构 避免了卷积乘法带来的大量计算,使得其模块复杂度低,计算量小。实验证明, 在轻量模型上添加CBAM模块能够带来稳定的性能提升,相较于其带来的少量的计算量的增加,CBAM的引入具有很局的性价比。
(2)通用性强:其结构特点决定了 CBAM的通用性强,可移植性高,主要体现在两方面:一方面, 基于池化操作的CBAM模块能够直接嵌入到卷积操作后,这意味着该模块可以添加到诸如VGG的传统神经网络中,同时也可以添加到包含基于shortcut连接的残差结构的网络中,如ResNet50、MobileNetV3;另一方面, CBAM同时适用于目标检测和分类任务,且对于不同数据特征的数据集,在检测或者分类精度上均能取得较好的性能提升。
(3)作用效果佳:传统基于卷积神经网络的注意力机制更多的是关注对通道域的分析,局限于考虑特征图通道之间的作用关系。 CBAM从 channel 和 spatial 两个作用域出发,引入空间注意力和通道注意力两个分析维度,实现从通道到空间的顺序注意力结构。 空间注意力可使神经网络更加关注图像中对分类起决定作用的像素区域而忽略无关紧要的区域, 通道注意力则用于处理特征图通道的分配关系,同时对两个维度进行注意力分配增强了注意力机制对模型性能的提升效果。
2.2 网络结构
(1)通道注意力机制
CBAM中的通道注意力机制模块流程图如下。先 将输入特征图分别进行全局最大池化和全局平均池化,对特征映射基于两个维度压缩,获得两张不同维度的特征描述。池化后的特征图共用一个多层感知器网络,先通过11卷积降维再11卷积升维。 将两张特征图叠加layers.add(),经过sigmoid激活函数归一化特征图的每个通道的权重。 将归一化后的权重和输入特征图相乘。


代码展示
#(1)通道注意力
def channel_attenstion(inputs, ratio=0.25):
'''ratio代表第一个全连接层下降通道数的倍数'''
channel = inputs.shape[-1] # 获取输入特征图的通道数
# 分别对输出特征图进行全局最大池化和全局平均池化
# [h,w,c]==>[None,c]
x_max = layers.GlobalMaxPooling2D()(inputs)
x_avg = layers.GlobalAveragePooling2D()(inputs)
# [None,c]==>[1,1,c]
x_max = layers.Reshape([1,1,-1])(x_max) # -1代表自动寻找通道维度的大小
x_avg = layers.Reshape([1,1,-1])(x_avg) # 也可以用变量channel代替-1
# 第一个全连接层通道数下降1/4, [1,1,c]==>[1,1,c//4]
x_max = layers.Dense(channel*ratio)(x_max)
x_avg = layers.Dense(channel*ratio)(x_avg)
# relu激活函数
x_max = layers.Activation('relu')(x_max)
x_avg = layers.Activation('relu')(x_avg)
# 第二个全连接层上升通道数, [1,1,c//4]==>[1,1,c]
x_max = layers.Dense(channel)(x_max)
x_avg = layers.Dense(channel)(x_avg)
# 结果在相叠加 [1,1,c]+[1,1,c]==>[1,1,c]
x = layers.Add()([x_max, x_avg])
# 经过sigmoid归一化权重
x = tf.nn.sigmoid(x)
# 输入特征图和权重向量相乘,给每个通道赋予权重
x = layers.Multiply()([inputs, x]) # [h,w,c]*[1,1,c]==>[h,w,c]
return x
(2)空间注意力机制
CBAM中的空间注意力机制模块如下。 对通道注意力机制的输出特征图进行空间域的处理。首先,特征图 分别经过基于通道维度的最大池化和平均池化, 将输出的两张特征图在通道维度堆叠 layers.concatenate()。然后使用11卷积调整通道数,最后 经过sigmoid函数归一化权重*。将归一化权重和输入特征度相乘。

代码展示
#(2)空间注意力机制
def spatial_attention(inputs):
# 在通道维度上做最大池化和平均池化[b,h,w,c]==>[b,h,w,1]
# keepdims=Fale那么[b,h,w,c]==>[b,h,w]
x_max = tf.reduce_max(inputs, axis=3, keepdims=True) # 在通道维度求最大值
x_avg = tf.reduce_mean(inputs, axis=3, keepdims=True) # axis也可以为-1
# 在通道维度上堆叠[b,h,w,2]
x = layers.concatenate([x_max, x_avg])
# 1*1卷积调整通道[b,h,w,1]
x = layers.Conv2D(filters=1, kernel_size=(1,1), strides=1, padding='same')(x)
# sigmoid函数权重归一化
x = tf.nn.sigmoid(x)
# 输入特征图和权重相乘
x = layers.Multiply()([inputs, x])
return x
(3)总体流程
CBAM的总体流程图如下。输入特征图想经过通道注意力机制,将权重和输入特征图相乘后再送入空间注意力机制,将归一化权重和空间注意力机制的输入特征图相乘,得到最终的特征图。
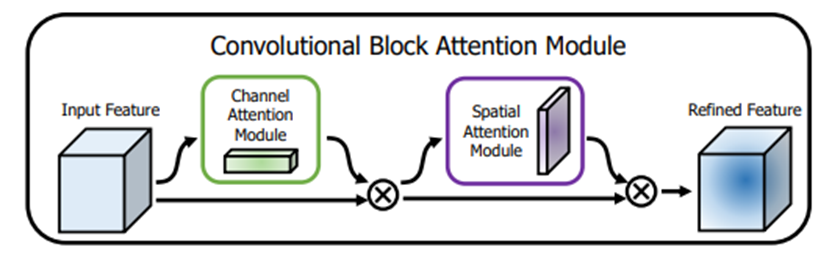
完整代码展示
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Model
#(1)通道注意力
def channel_attenstion(inputs, ratio=0.25):
'''ratio代表第一个全连接层下降通道数的倍数'''
channel = inputs.shape[-1] # 获取输入特征图的通道数
# 分别对输出特征图进行全局最大池化和全局平均池化
# [h,w,c]==>[None,c]
x_max = layers.GlobalMaxPooling2D()(inputs)
x_avg = layers.GlobalAveragePooling2D()(inputs)
# [None,c]==>[1,1,c]
x_max = layers.Reshape([1,1,-1])(x_max) # -1代表自动寻找通道维度的大小
x_avg = layers.Reshape([1,1,-1])(x_avg) # 也可以用变量channel代替-1
# 第一个全连接层通道数下降1/4, [1,1,c]==>[1,1,c//4]
x_max = layers.Dense(channel*ratio)(x_max)
x_avg = layers.Dense(channel*ratio)(x_avg)
# relu激活函数
x_max = layers.Activation('relu')(x_max)
x_avg = layers.Activation('relu')(x_avg)
# 第二个全连接层上升通道数, [1,1,c//4]==>[1,1,c]
x_max = layers.Dense(channel)(x_max)
x_avg = layers.Dense(channel)(x_avg)
# 结果在相叠加 [1,1,c]+[1,1,c]==>[1,1,c]
x = layers.Add()([x_max, x_avg])
# 经过sigmoid归一化权重
x = tf.nn.sigmoid(x)
# 输入特征图和权重向量相乘,给每个通道赋予权重
x = layers.Multiply()([inputs, x]) # [h,w,c]*[1,1,c]==>[h,w,c]
return x
#(2)空间注意力机制
def spatial_attention(inputs):
# 在通道维度上做最大池化和平均池化[b,h,w,c]==>[b,h,w,1]
# keepdims=Fale那么[b,h,w,c]==>[b,h,w]
x_max = tf.reduce_max(inputs, axis=3, keepdims=True) # 在通道维度求最大值
x_avg = tf.reduce_mean(inputs, axis=3, keepdims=True) # axis也可以为-1
# 在通道维度上堆叠[b,h,w,2]
x = layers.concatenate([x_max, x_avg])
# 1*1卷积调整通道[b,h,w,1]
x = layers.Conv2D(filters=1, kernel_size=(1,1), strides=1, padding='same')(x)
# sigmoid函数权重归一化
x = tf.nn.sigmoid(x)
# 输入特征图和权重相乘
x = layers.Multiply()([inputs, x])
return x
#(3)CBAM注意力
def CBAM_attention(inputs):
# 先经过通道注意力再经过空间注意力
x = channel_attenstion(inputs)
x = spatial_attention(x)
return x
#(4)构建模型结构
if __name__ == '__main__':
# 构建输入层
inputs = keras.Input(shape=[26,26,512])
# CBAM注意力机制
x = CBAM_attention(inputs)
# 构建模型
model = Model(inputs, x)
# 查看模型结构
model.summary()
参数量如下
Total params: 263,427
Trainable params: 263,427
Non-trainable params: 0
3. DANet 注意力机制
DANet 注意力机制由位置注意力机制(position)和通道注意力机制(channel)组合而成。
位置注意力机制负责 捕获特征图在任意两个位置的空间依赖关系,无论距离如何,类似的特征都会彼此相关。 通道注意力机制负责 整合所有通道映射之间的相关特征来选择性地强调存在相互依赖的通道映射。
3.1 位置注意力机制
位置注意力机制的流程图如下
(1)输入特征图A(C×H×W)首先分别通过3个卷积层得到3个特征图B,C,D,然后将B,C,D reshape为C×N,其中N=H×W
(2)然后将reshape后的特征图B的转置(NxC)与reshape后的特征图C(CxN)矩阵相乘 tf.multul(),再通过softmax得到归一化后的权重 S(N×N)
(3)接着在reshape后的特征图D(CxN)和权重S的转置(NxN)之间执行矩阵乘法 tf.multul(),再乘以尺度系数α,再reshape为原来形状,其中α初始化为0,并逐渐的学习得到更大的权重
(4)最后与输入特征图A相叠加layers.add()得到最后的输出E

代码展示
位置注意力
def position_attention(inputs):
# 定义可训练变量,反向传播可更新
gama = tf.Variable(tf.ones(1)) # 初始化1
# 获取输入特征图的shape
b, h, w, c = inputs.shape
# 深度可分离卷积[b,h,w,c]==>[b,h,w,c//8]
x1 = layers.SeparableConv2D(filters=c//8, kernel_size=(1,1), strides=1, padding='same')(inputs)
# 调整维度排序[b,h,w,c//8]==>[b,c//8,h,w]
x1_trans = tf.transpose(x1, perm=[0,3,1,2])
# 重塑特征图尺寸[b,c//8,h,w]==>[b,c//8,h*w]
x1_trans_reshape = tf.reshape(x1_trans, shape=[-1,c//8,h*w])
# 调整维度排序[b,c//8,h*w]==>[b,h*w,c//8]
x1_trans_reshape_trans = tf.transpose(x1_trans_reshape, perm=[0,2,1])
# 矩阵相乘
x1_mutmul = x1_trans_reshape_trans @ x1_trans_reshape
# 经过softmax归一化权重
x1_mutmul = tf.nn.softmax(x1_mutmul)
# 深度可分离卷积[b,h,w,c]==>[b,h,w,c]
x2 = layers.SeparableConv2D(filters=c, kernel_size=(1,1), strides=1, padding='same')(inputs)
# 调整维度排序[b,h,w,c]==>[b,c,h,w]
x2_trans = tf.transpose(x2, perm=[0,3,1,2])
# 重塑尺寸[b,c,h,w]==>[b,c,h*w]
x2_trans_reshape = tf.reshape(x2_trans, shape=[-1,c,h*w])
# 调整x1_mutmul的轴,和x2矩阵相乘
x1_mutmul_trans = tf.transpose(x1_mutmul, perm=[0,2,1])
x2_mutmul = x2_trans_reshape @ x1_mutmul_trans
# 重塑尺寸[b,c,h*w]==>[b,c,h,w]
x2_mutmul = tf.reshape(x2_mutmul, shape=[-1,c,h,w])
# 轴变换[b,c,h,w]==>[b,h,w,c]
x2_mutmul = tf.transpose(x2_mutmul, perm=[0,2,3,1])
# 结果乘以可训练变量
x2_mutmul = x2_mutmul * gama
# 输入和输出叠加
x = layers.add([x2_mutmul, inputs])
return x
3.2 通道注意力模块
通道注意力模块的流程图如下。
(1)分别对特征图A做reshape(CxN)以及reshape与transpose(NxC);
(2)将得到的两个特征图 矩阵相乘tf.multul(),再 通过softmax得到归一化后的权重X(C×C);
(3)接着把权重X的转置(CxC)与reshape后的特征图A(CxN)做矩阵乘法 tf.multul(),再乘以尺度系数β,再reshape为原来形状。其中β初始化为0,并逐渐的学习得到更大的权重
(4)最后与输入特征图A相叠加得到最后的输出特征图E
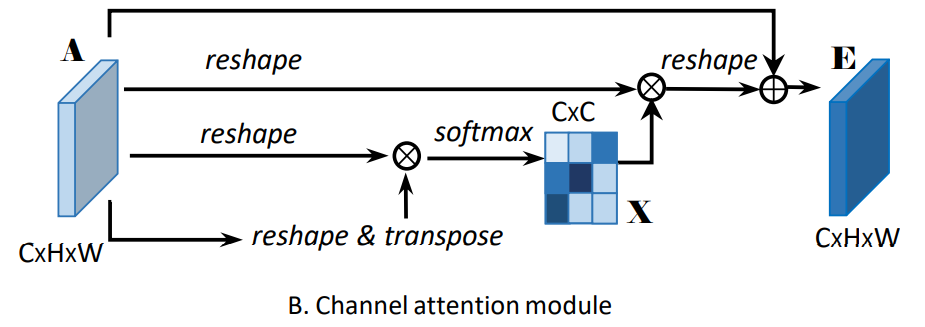
代码展示
通道注意力
def channel_attention(inputs):
# 定义可训练变量,反向传播可更新
gama = tf.Variable(tf.ones(1)) # 初始化1
# 获取输入特征图的shape
b, h, w, c = inputs.shape
# 重新排序维度[b,h,w,c]==>[b,c,h,w]
x = tf.transpose(inputs, perm=[0,3,1,2]) # perm代表重新排序的轴
# 重塑特征图尺寸[b,c,h,w]==>[b,c,h*w]
x_reshape = tf.reshape(x, shape=[-1,c,h*w])
# 重新排序维度[b,c,h*w]==>[b,h*w,c]
x_reshape_trans = tf.transpose(x_reshape, perm=[0,2,1]) # 指定需要交换的轴
# 矩阵相乘
x_mutmul = x_reshape_trans @ x_reshape
# 经过softmax归一化权重
x_mutmul = tf.nn.softmax(x_mutmul)
# reshape后的特征图与归一化权重矩阵相乘[b,x,h*w]
x = x_reshape @ x_mutmul
# 重塑形状[b,c,h*w]==>[b,c,h,w]
x = tf.reshape(x, shape=[-1,c,h,w])
# 重新排序维度[b,c,h,w]==>[b,h,w,c]
x = tf.transpose(x, perm=[0,2,3,1])
# 结果乘以可训练变量
x = x * gama
# 输入和输出特征图叠加
x = layers.add([x, inputs])
return x
3.3 总体流程
DANet的总体流程图如下,输入图像分别经过位置注意力机制和通道注意力机制,将输出的特征图叠加layers.add(),得到输出特征图。
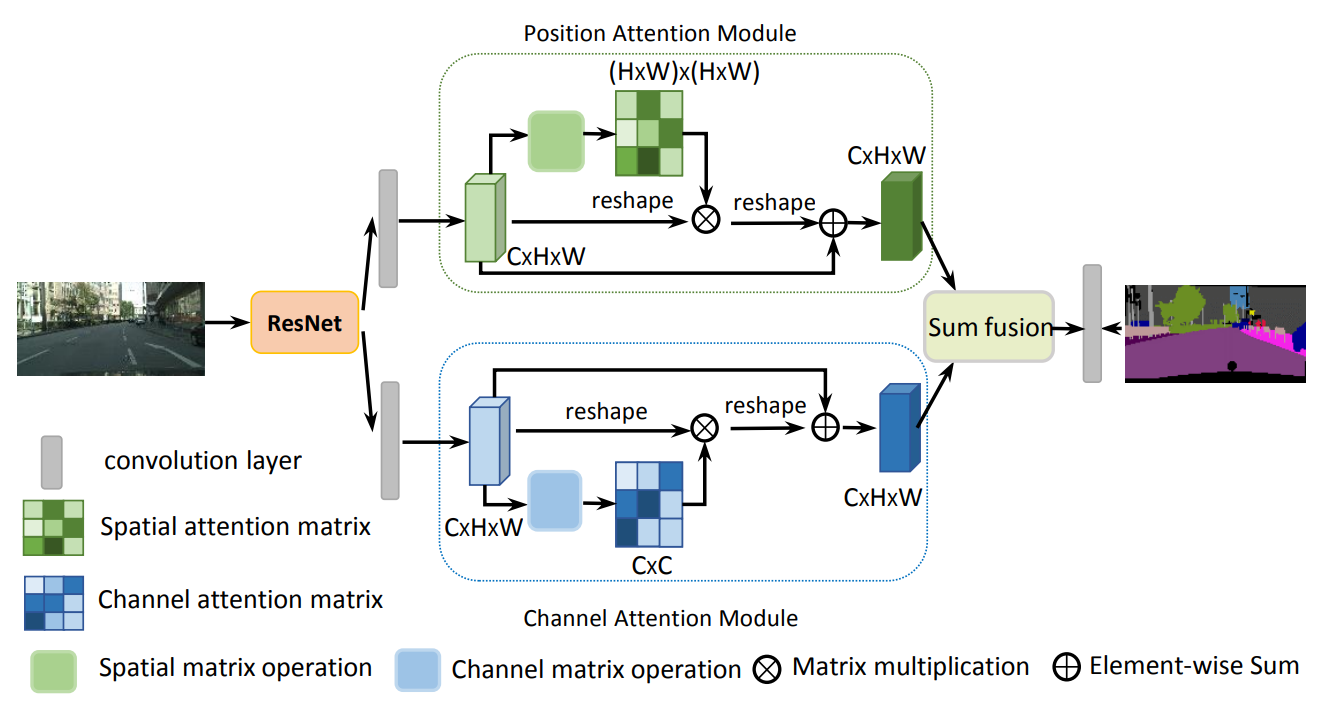
完整代码展示
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Model
#(1)通道注意力
def channel_attention(inputs):
# 定义可训练变量,反向传播可更新
gama = tf.Variable(tf.ones(1)) # 初始化1
# 获取输入特征图的shape
b, h, w, c = inputs.shape
# 重新排序维度[b,h,w,c]==>[b,c,h,w]
x = tf.transpose(inputs, perm=[0,3,1,2]) # perm代表重新排序的轴
# 重塑特征图尺寸[b,c,h,w]==>[b,c,h*w]
x_reshape = tf.reshape(x, shape=[-1,c,h*w])
# 重新排序维度[b,c,h*w]==>[b,h*w,c]
x_reshape_trans = tf.transpose(x_reshape, perm=[0,2,1]) # 指定需要交换的轴
# 矩阵相乘
x_mutmul = x_reshape_trans @ x_reshape
# 经过softmax归一化权重
x_mutmul = tf.nn.softmax(x_mutmul)
# reshape后的特征图与归一化权重矩阵相乘[b,x,h*w]
x = x_reshape @ x_mutmul
# 重塑形状[b,c,h*w]==>[b,c,h,w]
x = tf.reshape(x, shape=[-1,c,h,w])
# 重新排序维度[b,c,h,w]==>[b,h,w,c]
x = tf.transpose(x, perm=[0,2,3,1])
# 结果乘以可训练变量
x = x * gama
# 输入和输出特征图叠加
x = layers.add([x, inputs])
return x
#(2)位置注意力
def position_attention(inputs):
# 定义可训练变量,反向传播可更新
gama = tf.Variable(tf.ones(1)) # 初始化1
# 获取输入特征图的shape
b, h, w, c = inputs.shape
# 深度可分离卷积[b,h,w,c]==>[b,h,w,c//8]
x1 = layers.SeparableConv2D(filters=c//8, kernel_size=(1,1), strides=1, padding='same')(inputs)
# 调整维度排序[b,h,w,c//8]==>[b,c//8,h,w]
x1_trans = tf.transpose(x1, perm=[0,3,1,2])
# 重塑特征图尺寸[b,c//8,h,w]==>[b,c//8,h*w]
x1_trans_reshape = tf.reshape(x1_trans, shape=[-1,c//8,h*w])
# 调整维度排序[b,c//8,h*w]==>[b,h*w,c//8]
x1_trans_reshape_trans = tf.transpose(x1_trans_reshape, perm=[0,2,1])
# 矩阵相乘
x1_mutmul = x1_trans_reshape_trans @ x1_trans_reshape
# 经过softmax归一化权重
x1_mutmul = tf.nn.softmax(x1_mutmul)
# 深度可分离卷积[b,h,w,c]==>[b,h,w,c]
x2 = layers.SeparableConv2D(filters=c, kernel_size=(1,1), strides=1, padding='same')(inputs)
# 调整维度排序[b,h,w,c]==>[b,c,h,w]
x2_trans = tf.transpose(x2, perm=[0,3,1,2])
# 重塑尺寸[b,c,h,w]==>[b,c,h*w]
x2_trans_reshape = tf.reshape(x2_trans, shape=[-1,c,h*w])
# 调整x1_mutmul的轴,和x2矩阵相乘
x1_mutmul_trans = tf.transpose(x1_mutmul, perm=[0,2,1])
x2_mutmul = x2_trans_reshape @ x1_mutmul_trans
# 重塑尺寸[b,c,h*w]==>[b,c,h,w]
x2_mutmul = tf.reshape(x2_mutmul, shape=[-1,c,h,w])
# 轴变换[b,c,h,w]==>[b,h,w,c]
x2_mutmul = tf.transpose(x2_mutmul, perm=[0,2,3,1])
# 结果乘以可训练变量
x2_mutmul = x2_mutmul * gama
# 输入和输出叠加
x = layers.add([x2_mutmul, inputs])
return x
#(3)DANet网络架构
def danet(inputs):
# 输入分为两个分支
x1 = channel_attention(inputs) # 通道注意力
x2 = position_attention(inputs) # 位置注意力
# 叠加两个注意力的结果
x = layers.add([x1,x2])
return x
构建网络
if __name__ == '__main__':
# 构造输入层
inputs = keras.Input(shape=[26,26,512])
# 经过DANet注意力机制返回结果
outputs = danet(inputs)
# 构造模型
model = Model(inputs, outputs)
# 查看模型结构
model.summary()
查看网络参数量
Total params: 296,512
Trainable params: 296,512
Non-trainable params: 0
Original: https://blog.csdn.net/dgvv4/article/details/123888724
Author: 立Sir
Title: 【深度学习】(9) CNN中的混合域注意力机制(DANet,CBAM),附Tensorflow完整代码
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/522120/
转载文章受原作者版权保护。转载请注明原作者出处!